🐊
【R】群逐次デザインの理論と実装
臨床試験デザインに関する学習記事です。群逐次デザイン(Group Sequential Desig、GSD)の枠組みを数式と実装から理解することが目標です。
1. 理論
1-1. 概要
群逐次デザインは、臨床試験の途中で複数回の中間解析を計画的に行い、早期終了(有効性、無益性、安全性)やサンプルサイズ再設定を可能にするデザインです。中間解析を複数回行うと、第一種の誤り(
1-2. \alpha
-
t_k -
I_k k -
I_{\text{max}}
-
\alpha(t) t \alpha -
\alpha(t_k) k \alpha -
\alpha(t_{k-1}) \alpha -
\Delta\alpha_k k \alpha
1-3. 代表的な\alpha
1-3-1. O'Brien-Fleming型
-
\Phi(\cdot) -
z_{1-\alpha/2} \alpha/2
1-3-2. Pocock型
1-4. 停止境界
-
b_k k Z_k -
z_{1-\alpha/2} \alpha_k
2. R実装
2-1. \alpha
obrien_fleming_alpha <- function(t, alpha = 0.05) {
z <- qnorm(1 - alpha / 2)
2 * (1 - pnorm(z / sqrt(t)))
}
pocock_alpha <- function(t, alpha = 0.05){
alpha * log(1 + (exp(1) - 1) * t)
}
2-2. \alpha
info_frac <- seq(0.1, 1, by = 0.01)
df_alpha <- bind_rows(
tibble(
info_frac = info_frac,
alpha_spent = obrien_fleming_alpha(info_frac),
method = "O'Brien_Fleming"
),
tibble(info_frac = info_frac,
alpha_spent = pocock_alpha(info_frac),
method = "Pocock"
)
)
2-3. \alpha
ggplot(df_alpha, aes(x = info_frac, y = alpha_spent, color = method)) +
geom_line() +
labs(title = " alpha spending function",
x = "information rate",
y = "cumulative alpha spent",
color = "method") +
theme_minimal()
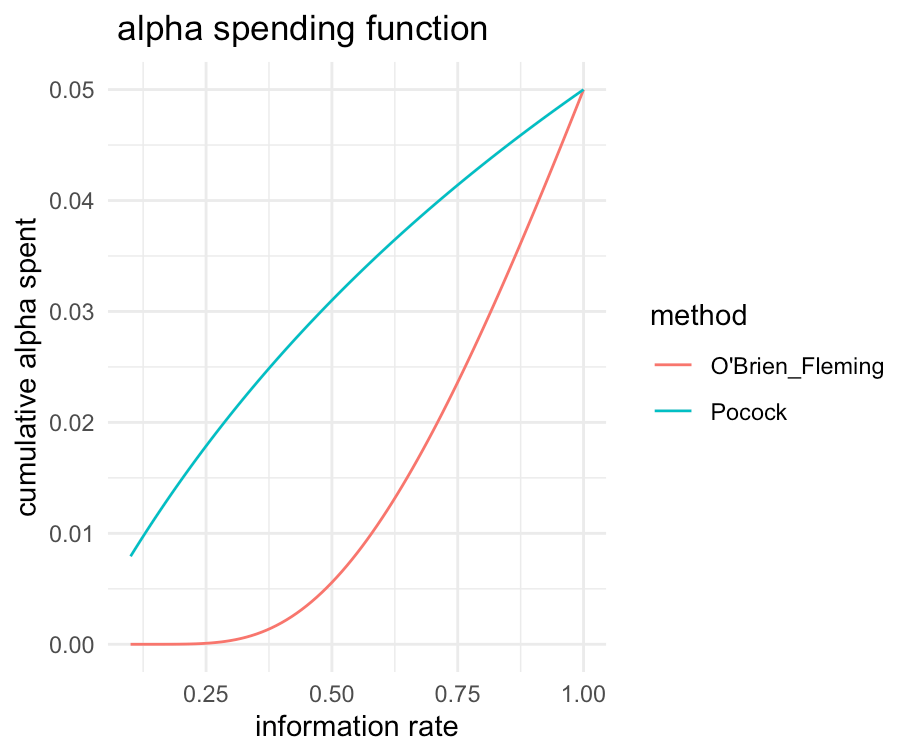
- O'Brien-Fleming法は、初期の情報割合でほとんど
\alpha \alpha - Pocock法は、各解析で均等に
\alpha
2-4. 停止境界の計算と可視化
info_points <- c(1/3, 2/3, 1)
alpha_obf_points <- obrien_fleming_alpha(info_points)
alpha_pocock_points <- pocock_alpha(info_points)
z_obf <- qnorm (1 - alpha_obf_points)
z_pocock <- qnorm(1 - alpha_pocock_points)
df_boundary <- tibble(
interim = rep(1:3, 2),
info_flaction = rep(info_points, 2),
z_bound = c(z_obf, z_pocock),
method = rep(c("O'Brien-Fleming", "Pocock"), each = 3)
)
ggplot(df_boundary, aes(x = info_flaction, y = z_bound, color= method)) +
geom_point() +
geom_line() +
scale_x_continuous(breaks = info_points) +
labs(title = "stopping boundary",
x = "information rate",
y = "stopping boundary",
color = "method") +
theme_minimal()

-
\alpha -
Z \alpha - O'Brien-Fleming法は「初期解析で厳しい判定」、Pocock法は「どの回も同じ判定基準」。
2-5. 感度分析:\alpha \alpha
alpha_levels <- c(0.01, 0.05, 0.1)
df_alpha_sensitivity <- map_dfr(alpha_levels, function(a){
tibble(
info_frac = info_frac,
alpha_spent = obrien_fleming_alpha(info_frac, alpha = a),
alpha_level = paste("alpha =", a)
)
})
ggplot(df_alpha_sensitivity, aes(x = info_frac, y = alpha_spent, color = alpha_level)) +
geom_line() +
labs(title = "O'Brien-Fleming(alpha sentivive analysis)",
x = "information rate",
y = "cumulative alpha spent",
color = "alpha levels") +
theme_minimal()

3. 終わりに
間違いなどありましたら遠慮なくご指摘いただけますと幸いです。
Discussion