行動認識について調べてみた
1. はじめに
STARAIインターンの橋詰です!
行動認識について調べる機会があったので、モデルのアーキテクチャについて簡単にまとめてみました。
1.1. 行動認識とは?
行動認識(Human Action Recognition)とは、動画内の人物が取る行動(e.g. 静止、手を振る、走る)を分類するタスクです。

行動認識タスクの例[1]
1.2. 行動認識モデルの特徴
あるフレームにおける行動を分類するとき、そのフレーム(静止画)だけでなく前後の情報も活用する方が性能が上がることが期待されます。そのため、動画の情報を余すところなく活用するためには、空間的な特徴だけでなく、時系列的な特徴も捉えられる必要があります。
実際、今回紹介するモデルは全て時系列的な情報をうまくモデルに入れ込んでいます。
動画そのものだけでなく、動画を加工して新たな特徴量を作成し、それをモデルに加えることもあります。代表的なものは、
- 物体の移動軌跡(Optical Flow)
- 深度マップ(Depth Estimation)
- スケルトン(Human Pose Estimation)
の三つです。()内は特徴量を作成するための代表的な手法です。
移動軌跡と深度マップは動画と同じwidth,heightで得られるため動画と一緒にCNNに突っ込める一方で、スケルトンは高々十数程度の点群なのでかなり性質が異なります。
そのため、動画をメインに、補助的に移動軌跡・深度マップを用いるモデルはRGB-basedモデル、スケルトンを用いるモデルはSkeleton-basedモデルと呼ばれています。
1.3. 近年の傾向
Optical Flow等を用いないEnd-to-endなRGB-basedモデルがKineticなどのデータセットでSOTAを達成しているようです。
しかし、タスクによってはSkeleton-basedモデルが使われています。
例えばボクシングの行動認識では、パンチとキックを区別するだけでなくパンチの種類まで区別する必要があります。このような細かい違いはスケルトンの方が捉えやすいようです。
Skeleton-based methods have been a popular approach for fine-grained action recognition in sports[2]
2. RGB-basedモデル(登場順)
2.1. Two-stream[3]
two-streamはその名の通り、Spatial streamとTemporal streamの二つのstreamからなります。
大雑把には以下の流れです。
- Spatial streamに動画の1フレームだけを入力し、予測を出力
- Temporal streamにdense optical flowを複数フレームに適用して生成した特徴量を入力し、予測を出力
- 二つの予測結果を平均を取るなどして統合、最終的な予測を出力

two-streamのアーキテクチャ概念図
2.2. Two-Stream Inflated 3D ConvNet (I3D)[4]
上記と同様にtwo-streamの構造を持っています。異なる点は多層に重ねたConv3Dを用いている点で、これによりSpatial streamに相当する部分でも時系列を考慮していることになります。
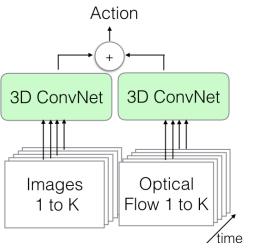
two-stream I3Dのアーキテクチャ概念図
2.3. SlowFast以降のモデル
SlowFastは上記二つとは異なり、Optical Flow等を用いないEnd-to-Endモデルです。
以降SOTAを達成しているモデルは3D CNNやVision Transformerベースのモデルとなっており、違いを細かく書くと非常に長くなってしまうため、簡単にいくつかモデルをまとめます。
- SlowFast[5]: 空間的な特徴に特化したSlow Pathwayと時間的な特徴に特化したFast Pathwayに分けている。どちらも3D CNNベース
- MViTv2[6]: 階層的なアーキテクチャのViT。時間方向に対しても階層を入れており、従来のViTよりも時間的な特徴を捉えられていると報告されている
- MSQNet[7]: ViTがベース。CLIPを用いて画像とラベルをエンコーディングし、デコーダーに入力するQueryを作成することで、動画の埋め込みとテキストの埋め込みを組み合わせている。
3. Skeleton-basedモデル
Skeleton-basedモデルは上述した通り、特定のスポーツなどのデータセットに対して用いられている例が多いです。一方で、RGB-basedモデルにSkeleton-basedモデルで抽出した特徴量を加えることで精度が向上したという報告もあります[8]。
また、動画全体と比較してデータとモデルが非常に軽量なため、RGB-basedモデルより扱いやすいという利点もありそうです。
Skeleton-basedモデルは基本的にはスケルトンをグラフとして扱い、GNN系列のモデルが用いています。
一例としてSpatial Temporal GCN[9]は次のような流れで推論を行います。
- 前後のフレームのスケルトンの同じ部位とグラフを結合
- 結合したグラフに対してGCNを用いて分類
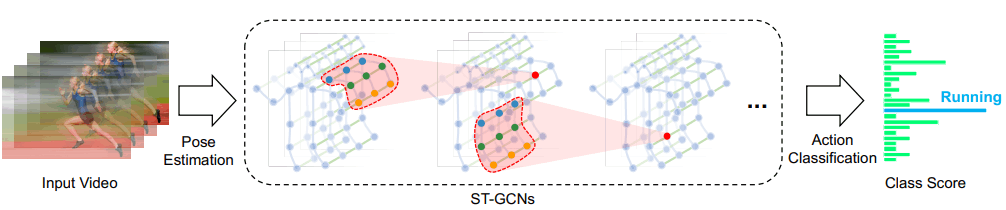
Spatial Tempoeal GCNの推論過程
4. PySlowFastで行動認識してみた
MetaがSlowFast, MViTなどの学習済みモデルをPySlowFastというライブラリとして公開しています。
Kinetic[10]データセットで学習されたSlowFastモデルを用いて、UCF101[11]というデータセットのを予測できるかを試してみました。
(両方ともYoutube上の動画を使用しているため、学習データに含まれている可能性はあります・・・)

UCF101の予測結果[正解:クリケット]
予測対象の動画はクリケットを行っている様子です。
上記の通り、最初の一瞬は playing cricketが0.37と予測していますが、それ以外はほぼhitting baseballであると予測しています。
野球とクリケットの動作には類似性があるため、ある程度ちゃんと予測出来てると言えそうです。

UCF101の予測結果[正解:テニス]
次はテニスを行っている動画です。読みにくいですが、playing tennisと予測できています。
5. 終わりに
行動認識モデルについてざっくりまとめました。
行動認識に入門する方、行動認識の概略を把握したい方の一助になれば幸いです。
参考文献
- M. Karim, S. Khalid, A. Aleryani, J. Khan, I. Ullah and Z. Ali, "Human Action Recognition Systems: A Review of the Trends and State-of-the-Art," in IEEE Access, vol. 12, pp. 36372-36390, 2024, doi: 10.1109/ACCESS.2024.3373199.
-
Gu, Chunhui, et al. "Ava: A video dataset of spatio-temporally localized atomic visual actions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. ↩︎
-
Zhu, Kevin, Alexander Wong, and John McPhee. "Fencenet: Fine-grained footwork recognition in fencing." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. ↩︎
-
Simonyan, Karen, and Andrew Zisserman. "Two-stream convolutional networks for action recognition in videos." Advances in neural information processing systems 27 (2014). ↩︎
-
Carreira, Joao, and Andrew Zisserman. "Quo vadis, action recognition? a new model and the kinetics dataset." proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017. ↩︎
-
Feichtenhofer, Christoph, et al. "Slowfast networks for video recognition." Proceedings of the IEEE/CVF international conference on computer vision. 2019. ↩︎
-
Li, Yanghao, et al. "Mvitv2: Improved multiscale vision transformers for classification and detection." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022. ↩︎
-
Mondal, Anindya, et al. "MSQNet: Actor-agnostic Action Recognition with Multi-modal Query." arXiv preprint arXiv:2307.10763 (2023). ↩︎
-
Duan, Haodong, et al. "Revisiting skeleton-based action recognition." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022. ↩︎
-
Yan, Sijie, Yuanjun Xiong, and Dahua Lin. "Spatial temporal graph convolutional networks for skeleton-based action recognition." Proceedings of the AAAI conference on artificial intelligence. Vol. 32. No. 1. 2018. ↩︎
-
Kay, Will, et al. "The kinetics human action video dataset." arXiv preprint arXiv:1705.06950 (2017). ↩︎
-
Soomro, K. "UCF101: A dataset of 101 human actions classes from videos in the wild." arXiv preprint arXiv:1212.0402 (2012). ↩︎
Discussion