文献調査: 「TAID: Temporally Adaptive Interpolated Distillation」
1. はじめに
お疲れ様です!社員の中岸が投稿します!
今回は、知識蒸留によるモデル圧縮について興味深い議論がされている Sakana AIの文献(タイトルに全部入らなかった… )を調査してみたのでその内容を自分なりにまとめてみました!(なお、「➡」に続いている文章は、読んでいる際に自分が感じたことであり、論文の内容ではないのでご注意下さい。また、誤字や間違って理解しているところも多々あるかもしれませんがご了承ください。)
今回の記事は、下記文献(URL)の内容を自分が読んでまとめた結果になります。また、図や表などはこの文献やプロジェクトブログなどから引用しています(Blog, Github)。
Makoto Shing and Kou Misaki and Han Bao and Sho Yokoi and Takuya Akiba. TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models. arXiv preprint, 2025
2. 要約(Abstruct)~イントロ(Introduction)
近年、Causal language models (LMs)は様々な分野で重要なツールとなっている。LMsにおいて、データサイズ、モデルサイズ、トレーニングステップのスケーリングは、LMsのパフォーマンスを向上させるための主なアプローチであるが、巨大なLMs(LLMs)には次のような課題があるため(paradox of scale)、潜在的かつ需要が高いにもかかわらず、広く導入・使用されることが妨げられているとのこと。
- モデルサイズの課題(大きすぎてエッジデバイスに展開できない)
- リアルタイム性の課題(デコード時間が大きすぎる)
- エネルギー消費の課題(学習や推論に大量のエネルギーが必要)
(➡DeepSeekR1とかも出てきて、このあたりは結構インパクトあるところやったと思う)
これに対処する有望なアプローチとして、知識蒸留によるモデル圧縮が挙げられている。知識蒸留はコンパクトでありながら高性能なモデルを開発するための有望なアプローチの1つであり、十分に訓練された高キャパシティの教師モデルからよりコンパクトな生徒モデルに知識、特に予測分布を移転することを目的としており、単独で訓練された小さなモデルよりも優れたパフォーマンスを達成することが知られている。LLMにおいても、主流のアプローチとなりつつあり、多くの手法が積極的に開発されるようになっている。
一方で、知識蒸留には、教師モデルと生徒モデルの違いに起因する2つの重要な課題(The formidable, unresolved challenge of teacher-student differences.)が存在する。
- キャパシティギャップ - 大規模な教師モデルとコンパクトな生徒モデルの間では大きな性能のギャップがあり、これが効果的な知識移転を難しくしている(能力差)。LMのサイズと複雑さが増すにつれ、このキャパシティギャップはますます顕著になってしまう。
-
モードアベレージングとモードコラプス(Mode Averaging & Mode Collapse) - モデルキャパシティの不均衡によってこれらの問題に直面してしまう。
- モードアベレージング: 生徒モデルが教師モデルの複数の出力モード(分布のピーク)を過剰に平均化してしまう現象。これにより、出力分布が不自然に平坦(スムーズ)になり、教師モデルが持つ重要な特徴が失われてしまうことがある。
- モードコラプス: 生徒モデルが教師モデルの出力分布の一部のモード(特定のパターン)に過度に集中してしまう現象。これにより、生徒モデルは限られたパターンだけを強調し、多様性が失われる結果となってしまう。
教師モデルと生徒モデルの違いという根本的な問題を克服するために、本文献中において、TAID(Temporally Adaptive Interpolated Distillation) という新しい知識蒸留アプローチが提案されている。TAIDは、教師モデルと生徒モデルを補間して適度な能力を持つターゲット分布を提供する中間教師を動的に導入することで、トレーニングプロセス全体を通じて教師モデルと生徒モデル間のギャップを低減させることを目的としている (図1参照)。このシンプルな手法により、大きなキャパシティギャップがある場合でもそのギャップの影響を軽減し、モードアベレージングとモードコラプスの問題についても理論的および経験的に抑制することができる高品質な生徒モデルが学習できるとこのと。
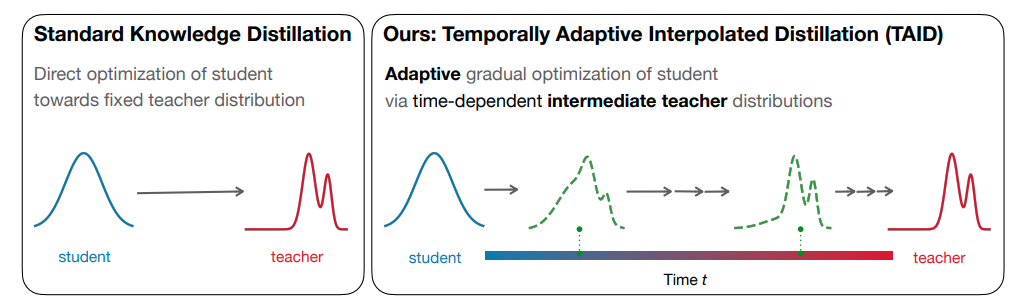
左図(Standard KD):生徒モデルが直接教師モデルの出力を模倣しにいく。学習の柔軟性が低く、キャパシティギャップの影響を強く受ける。右図(TAID):中間分布(緑色の破線) を経由することで、知識の移転を段階的に行う(tが小さいと生徒モデルの分布に近く、tが大きくなると教師モデルの分布に近づいていく)。生徒モデルは、自分の能力に応じて徐々に教師モデルに適応することができるようになる。
以降の構成は下記の通り。
- TAID (Section 3) :蒸留プロセスを、生徒分布から教師分布への動的で適応的な知識転送として再定義。これにより、大規模な言語モデルを蒸留する際の一般的な課題に対処。
- TAID の理論的分析 (Section 4):回帰モデルを用いて、蒸留プロセスでモード崩壊を防ぐ能力を実証。これにより、TAIDが、モード崩壊の影響を受ける可能性のある従来の自己蒸留方法と一線を画している点を説明。
- さまざまなモデルサイズとアーキテクチャにわたる広範囲な実験 (Section 6):インストラクションチューニングと事前学習の両方のシナリオで TAIDが既存のKD手法に対して優れていることを実証。さらに、TAIDのキャパシティギャップに対する頑健性(Section 6.3.2)と、モードアベレージングとモードコラプスのバランスをとる能力 (Section 6.3.3) を検証。
- TAIDの実証(Section 7):2つの最先端のコンパクトモデルを開発し性能を検証。これによりさまざまなドメインにわたるTAIDの有効性が実証された(TAID-LLM-1.5Bは、2Bパラメータ未満の言語モデルとして最高性能を達成。TAID-VLM-2Bは4Bパラメータ未満のビジョン・ランゲージモデルで最先端の性能を示したとのこと)。
以下は、本文献を読むにあてっての事前知識:
言語モデル蒸留の問題設定(Problem setting for language model distillation.)
言語モデルは、トークン列
-
y_{<s} = ( y_{1} , y_{ 2 } ,..., y_{s-1} ) y_s
従来の知識蒸留手法(Traditional Knowledge Distillation Approaches)
知識蒸留の目的は、十分に学習された教師モデル
-
p( y_s , y_{<s} ) -
q_{\theta}( y_s , y_{<s} ) - 上記の損失関数が最適化されることにより、生徒モデルが教師モデルの予測に近づくようになる。
逆KLダイバージェンス(Reverse KL Divergence, RKL)
モードアベレージングの問題に対処するために提案。
標準的なKLでは教師分布
キャパシティギャップの呪い(Curse of Capacity Gap)
教師モデルが非常に大規模である場合、その知識を小型の生徒モデルに効果的に移転することが困難になってしまう問題。
3. TAID(提案手法)
このセクションでは、TAID(Temporally Adaptive Interpolated Distillation) という新しい知識蒸留(Knowledge Distillation, KD)手法について説明されている。
簡単な特徴は以下の通り。
TAIDの特徴
- 中間分布の導入: 生徒モデルと教師モデルの間に時間依存型の中間分布
p_t - 時間適依存的な補間パラメータ:補間パラメータ
t - モードアベレージングとモードコラプスの緩和:中間分布を活用することで、モードアベレージング(過剰な平滑化) と モードコラプス(特定の出力への偏り) の問題を抑制。
3.1 TEMPORALLY INTERPOLATED DISTRIBUTION
TAID の重要なアイデアは、時間依存型の中間教師(中間分布)を導入して、生徒モデルと教師モデル間のギャップを埋めることにある。任意の入力シーケンス
-
t \in [0,1] -
\text{logit}_{q^{\prime}_{\theta}} -
\text{logit}_{p}
これらの補完はロジットレベルで行われる。補間パラメータ
-
TAIDでは、トレーニング中に補間パラメータ
t p_t - 初期学習(
t \approx 0 - 中間学習(
0 < t < 1 - 最終学習(
t \approx 1
- 初期学習(
-
q_t q^{\prime}_{\theta} q^{\prime}_{\theta} p_t q_{\theta} p_t t
(➡式(1), (2)がこの論文の核心、一気に学習させるのではなく、目的関数(KLダイバージェンス)の片方の分布を適応的に複雑なものにしていくというアプローチをとることで、小さなモデルでも徐々に複雑なモデルに適用できるようになる、ということか。考え方はシンプルだが、小さなモデルをいきなり複雑なモデルへ適用しに行くよりもよい結果を期待できそうなアプローチだというのは直感的にも理解できる。)
3.2 ADAPTIVE INTERPOLATION PARAMETER UPDATE
TAIDでは、補間パラメータ
目的関数の相対的な変化量の計算する。
-
\delta_n - 大きい場合(トレーニング初期段階)
→学習が順調に進んでいるため、補完パラメータt - 小さい場合(生徒モデルが教師モデルに近づいた段階)
→学習が停滞しているため、慎重にt
- 大きい場合(トレーニング初期段階)
-
J_{\text{TAID}}^{(t_n)} n -
\epsilon
変化量に対して、短期的な変動を抑えるために、モーメンタムを適用して平滑化。
-
m_n -
\beta \beta=0.99
モーメンタムで平滑化された変化量
-
t_n -
\alpha \alpha = 5e−4 -
t_{\text{linear}} t - 柔軟な初期化を可能にするために、
t t_{start}
- 柔軟な初期化を可能にするために、
-
\sigma(m_n) - min演算 :
t
完全なTAIDトレーニング手順は、Appendix Aのアルゴリズム1にまとめられている。

(➡
4. THEORETICAL ANALYSIS
ここでは、TAIDにおけるモード崩壊についての理論的分析が述べられてる。TAIDは、中間分布
この分析には、Mobahiら(2020)の枠組みを借り、言語モデリングの代替として最小二乗回帰(least-square regression) を用いる。各トレーニングステップでは、生徒モデルは次の補間ラベルにフィッティングすることで更新:
Theorem 4.1 (Non-collapse Nature (Informally)):
蒸留を合計
(➡どういうことか?→モード崩壊しないためには、ある学習ステップ(Tが大きくなるとより教師信号の強度が重要)において、教師モデルが十分に強い信号(ラベルといっているがノルムと言い換えられると思う)を持っている必要がある(自己蒸留では、上で言及しているようにモデルが同一+再帰的な過程で生徒モデルのモード(局所的な極大値)が繰り返し強化されることで崩壊が発生してしまう)→TAIDは、学習に中間分布を用いており、全ステップを通して中間分布とその適応的な更新によって、安定的に十分な教師信号強度を維持できる→ゆえにモード崩壊を回避できる、というふうに解釈できるか。)
(➡また、付録Bにおいては、モード崩壊(Mode Collapse) の発生メカニズムを、最小二乗回帰の最適化問題(言語モデリング問題の代理)に基づいて理論的に検証、正式な定理と詳細な議論が記載されており、中間分布とその適応更新の利点を裏付けている。)
5. RELATE DWORKS
ここでは、知識蒸留(Knowledge Distillation)の既存手法と、TAID(Temporally Adaptive Interpolated Distillation)との比較を行い、TAIDがどのようにして既存の課題を克服しているかが解説されている。
目的関数の改良(Improving objective functions)
従来のKLダイバージェンス(KL Divergence) ベースの手法(Section2参照)は、モードアベレージング(Mode Averaging) や モード崩壊(Mode Collapse) といった課題がある。これらの課題を克服するために、これまでにさまざまな代替的な目的関数(Alternative Objective Functions) が提案されているが、これらの手法は、通常、固定された教師分布に基づいて学習を行うため、生徒モデルとの能力差(キャパシティギャップ) が大きい場合、知識移転が効果的に行えないという課題がある。一方で、TAIDでは、時間依存型の中間分布(Time-Dependent Intermediate Distribution) を導入し、生徒モデルの初期分布から教師モデルの分布へと段階的にシフトすることで、キャパシティギャップの影響を低減し安定した知識移転が可能となっている。
生徒モデル生成データの活用(Utilizing student-generated outputs, SGOs)
Student-Generated Outputs(SGOs)は、生徒モデル自身が生成したデータを学習に活用するアプローチとのこと。固定データセットで学習する場合の自己回帰モデル(Autoregressive Models) の特性上、トレーニングデータと推論データの分布の不一致(Distribution Mismatch) の解決に有望とされているが、大規模モデルでの計算コストが非常に高い。一方で、TAIDでは、シンプルな設計でありながら、ポリシーなしのデータや SGOsに依存せずに優れた性能と計算効率を実現。さらに今後、TAIDとOn-Policyアプローチの組み合わせにより、さらなる性能向上の可能性も示唆されている。
画像分類からのKD手法の応用(KD methods from image classification)
画像分類(Image Classification) において開発された知識蒸留手法の一部は、言語モデル蒸留(Language Model Distillation) にも応用可能とされているが、言語ドメインの固有特性により、言語モデリングでは効果は十分ではない。一方で、TAIDは、適応的な補間を通じて教師の分布のみを変更するため、生徒が学習した情報をより多く保持できる可能性があり、言語モデル特有の課題にも柔軟に対応可能(6.3.4 で実験的に検証。TAIDは、適応補間によってこれらの問題に対処しながら、より単純なタスクでは別の方法と組み合わせられるほど柔軟性も発揮しているとのこと)。
6. EMPIRICAL ANALYSIS
ここでは、さまざまなモデルサイズとアーキテクチャを使用し、INSTRUCTION TUNINGとPRE-TRAININGのシナリオを通してTAIDを評価している。実験では、TAIDを最先端の方法と比較し、その優れたパフォーマンスと効率性を実証するとともに、さまざまなキャパシティギャップでのその動作と、モードアベレージングとモード崩壊問題のバランス調整能力について考察されている。
主な評価ポイント:
- モデルサイズやアーキテクチャの異なる条件での性能比較
- キャパシティギャップの影響に対する頑健性
- モードアベレージングとモード崩壊問題のバランス調整能力
6.1 INSTRUCTION TUNING
実験のセットアップ:
Instruction-following taskでは、UltraChat 200k データセット (Ding et al., 2023) をトレーニングに使用。パフォーマンスは、モデルの指示に従う能力を評価するために設計されたベンチマークである MT-Bench (Zheng et al.,2023) を使用して評価され、スコアリングは GPT-4 によって実施さたとのこと。実験では、以下の教師と生徒の3つのペアを使用。
- 教師: Phi-3-mini-4k-instruct、生徒: TinyLlama、
- 教師: Llama-2-7b-chat、生徒: TinyLlama
- 教師: StableLM Zephyr 3B、生徒: Pythia-410M
また、TAIDの純粋な有効性を評価するために、蒸留前に教師あり微調整 (SFT) を実行したりはせず、指示データ(instruction data)を使用した蒸留のみに焦点を当てて行われている。また、より実践的なシナリオをシミュレートするために、社内データで学習された強力な教師モデル(オープンな)を使用し、より小型の生徒モデルへの蒸留を行っているとのこと。
比較手法(従来の主要研究):
- KLダイバージェンス(KL Divergence)
- 逆KLダイバージェンス(RKL)
- Total Variation Distance(TVD)
- 適応型KL(Adaptive KL)
- SGO(Student-Generated Outputs)ベースの手法
- Generalized KD(GKD)
- DistiLLM
-画像分類用のKD手法 - CTKD(Curriculum Teacher KD)
- DKD(Decoupled Knowledge Distillation)
- 教師ありファインチューニング(Supervised Fine-Tuning, SFT)
- ベースラインとして使用とのこと

表1:LLM instruction tuningにおける各蒸留方法の評価結果。TAIDはどのベンチマークよりも優れたパフォーマンスを出していることが分かる。
実験結果:
適応更新メカニズムの影響を確認するために、この機能の有無の両方でもTAIDは評価されている。適応更新なしのTAIDでは、結果に関して補間パラメータの線形増加が使用される。表1は、3つの教師と生徒のペアにわたるすべての方法のMT-Benchスコアが示されている。表1からTAIDすべてのベースライン手法よりも一貫して優れていることが確認できる。さらに、トレーニング時間についても優位性が示されており(DistiLLMの約2倍、GKDの約10倍)、リッチな手法を用いなくても優れた性能を実現かつ計算効率も兼ね備えた手法であることが分かる。TAID を適応更新ありとなしのものと比較したアブレーション研究では、さまざまな教師と生徒のペアで 2.2% から 17.7% の範囲の改善が見られ、適応メカニズムの重要性も示されている。
6.2 PRE-TRAINING
実験のセットアップ:
ここでは、リソースが限られているため、Continued Pre-training(継続的事前学習)を行っている(既に事前学習(Pre-trained)されたモデルをベースとして、追加の事前学習を行うプロセス(ここでは蒸留による追加事前学習))。データセットは、SmolLM-Corpusデータセットの最初の10%(約200億トークン)を使用。教師モデルとして Phi-3-medium-4k-instruct、生徒モデルとしてTinyLlamaが使用されている。上の実験と同様に、追加のSFTなどを使用せず、純粋に知識蒸留の効果に焦点を当てている。大規模事前学習においては、生徒モデルからのサンプリングが高コストであり、さらにプロンプトが存在しないため、ベースライン手法はSGOを使用せず、評価関数のみを利用して評価する形に調整されている(➡つまり、教師モデルと生徒モデルの出力分布を直接比較し、損失関数に基づいて最適化されていくみたいな感じか)。
比較手法
- KLダイバージェンス(KL Divergence)
- Total Variation Distance(TVD)
- 適応型KL(Adaptive KL)
- Generalized Jensen–Shannon Divergence(GJS) - GKDで使用
- Skew KL / Reverse KL(RKL)
詳細なハイパーパラメータと実装の詳細は、付録D.2.に記載とのこと。
評価方法
事前トレーニング済みモデルを評価するために、Open LLM Leaderboardの方法論(評価方法、評価基準)に従ったとある。
- 少数ショット評価(Few-Shot Evaluation) に基づき、モデルの基礎能力をテスト。
- Open LLM Leaderboard標準に準拠した評価設定とメトリックを備えた6つの異なるタスクを含む評価セットを使用し、タスクごとのスコアおよび平均スコアを報告(表2)。
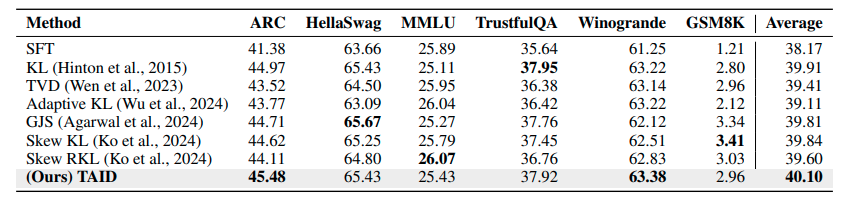
表2: LLM continued pre-trainingについての各蒸留方法の評価結果。
表2に、事前トレーニング実験の結果が示されている。TAIDは、6つのタスクの平均スコアですべてのベンチマークを上回る最高のパフォーマンスを達成していることが分かる。これは、TAIDが、さまざまなタスクで教師から生徒モデルに知識を転送する際の有効性が示されているということができると思われる。TAIDは、タスク全体で一貫して優れたパフォーマンス(2つのタスク (ARC と Winogrande) では最高スコアを達成)と最高の平均スコアは、大規模な言語モデルの知識蒸留における TAID の頑健性と有効性が強調されているものとなっている。
6.3 ANALYSIS
このセクションでは、TAID(Temporally Adaptive Interpolated Distillation) の学習時の挙動、キャパシティギャップへのロバスト性、そして知識蒸留の安定性に関する詳細な解析の結果が報告されている。
6.3.1 ANALYSIS OF INTERPOLATION PARAMETER AND TRAINING STABILITY
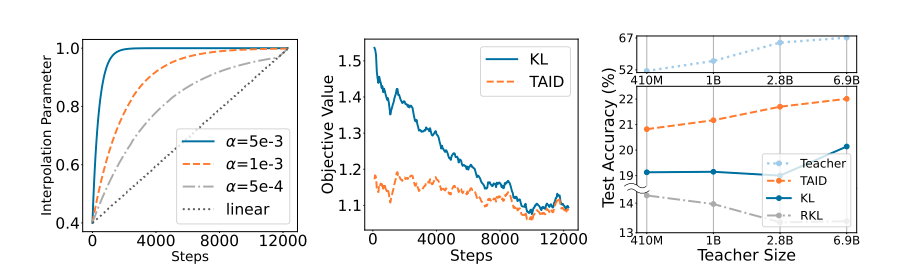
図2: TAID の動作とパフォーマンスの分析結果。(左):補間パラメータ
ここでは、TAIDの補間パラメータ
- 図2(左)は、
t_{start} \alpha t t \alpha t - 図2(中央) は、トレーニング中の教師モデルと生徒モデル間の標準KLダイバージェンスとTAID (中間分布を使用) の Objective value(損失、損失値) を比較。
- 標準KL:損失値が大きく変動し、不安定な挙動を示す。
- 学習プロセス全体を通じて、低い分散で一定の損失値を維持できていることが確認。
この損失値の安定性は、TAIDの適応型補間のメカニズムが学習タスクを生徒の現在の能力に合わせて一貫した難易度に維持していることを示している(➡最初から難しかったら、出力を合わせられずにロスが大きくなるとうのは確かにそう)。これまでの実験結果も踏まえると、この安定した学習環境は、より効率的で安定した知識移転に寄与しているということができると考えられる。
6.3.2 PERFORMANCE ACROSS VARIOUS CAPACITY GAPS
教師モデルから知識を徐々に転送するTAIDの設計は、キャパシティギャップの呪いに対処することが期待されており、ここではこの評価が行われている。
教師モデル: Pythia Suiteのさまざまな容量 (410M から 6.9B)
生徒モデル: 固定サイズの生徒モデル (70m) を使用
トレーニングデータ: SmolLM-Corpus からランダムに選んだ10億トークンを使用。1エポックのみ学習(計算コストの制約のため)。
評価データ: LAMBADA データセットを選択(文章の最後の単語を予測するモデルの能力をテストし、特定の知識に頼ることなく言語モデリング能力を直接評価するため、小規模なトレーニングでモデルを比較するのに適したベンチマーク)。
図2(右) において、TAID がすべての教師モデルサイズで KL および RKLの両方を一貫して上回るパフォーマンスを達成。特に、TAIDは、教師モデルのサイズが大きくなるにつれてパフォーマンスも安定して向上していることが分かる(が、一方で他の手法はパフォーマンスの傾向が一貫していないことも確認できる→教師モデルのサイズが大きくなると、必ずしも生徒モデルの性能が向上しない現象(=キャパシティギャップの呪い)が観察されたといえる)。これらの結果から、TAID は教師が大きくなっても一貫して改善が見られることから、さまざまなキャパシティギャップにおいてロバスト性があると言え、最先端の大規模言語モデルから知識を抽出して、よりコンパクトでデプロイ可能な生徒モデルにするのに特に適しているということができると思われる。
6.3.3 BALANCING MODE AVERAGING AND MODE COLLAPSE
ここでは、TAID(Temporally Adaptive Interpolated Distillation)が、モードアベレージング(Mode Averaging) と モードコラプス(Mode Collapse) の課題にどのように対処できるかを示すために、KL ダイバージェンス、RKL ダイバージェンス、および TAID を使用してトレーニングされた生徒モデルの分布を分析が行われている。
使用モデル: Phi-3-mini-4k-instruct (教師) と TinyLlama (生徒) ペアのトレーニング済みモデルを使用。
デーアセット: 分布は UltraChat 200k トレーニング セットから計算。
表3に、教師モデルによってランク付けされた語彙(Vocabulary)の先頭(ヘッド、出現頻度が高い単語)と末尾(テール、出現頻度が低い単語)における確率質量分布(Probability Mass Distribution) が掲載され比較されている。
- ヘッド領域(頻出単語)
- KLよりも多くの確率質量を捉えており、モードアベレージングの問題を効果的に回避していると解釈できる。
- TAIDよりもさらに支配的な語彙を強調するが(ヘッドの値が大きいため)、これは多様性の喪失につながる可能性あると考察されている。
- テール領域(低頻出単語)
- RKL: 低頻度語彙の捉え方が不十分であり(値が大きくこのあたりを雑に捉えていると考えられる)、モードコラプスの兆候であると考察できる。
- TAID: 適切な確率質量を維持しており、モードコラプスを防止していると考察できる。
これらの結果は、TAIDがモードアベレージングとモード崩壊の間のトレードオフをうまく乗り越えていることを示しており、バランスのとれたアプローチであるといえる。(➡つまるところ、小さいサイズのモデルでも頻出単語と低頻出単語の分布を適切に表現できる(いいところどりができる)蒸留手法ということ)
6.3.4 COMPARISON WITH IMAGE CLASSIFICATION TASKS
これまでの実験により、CTKDやDKDなど、画像分類で開発されたKD手法が、言語モデル蒸留において十分な性能を発揮しないことが判明。
→これは、言語モデリングタスクと画像分類タスクの分布の根本的な違いに起因すると考察。
分布の違い: 2つの代表的なモデルで比較(ResNet-56(画像分類モデル)、GPT-2(言語モデル))。
- 画像分類タスク:
- ターゲットクラス確率が高くエントロピーが低いワンホット分布を予測。
- 学習が単一の正解ラベルに収束しやすい。
- 言語タスク:
- 多様な確率分布(Diverse Probability Distribution) を予測。
- ターゲットクラス確率が低く、エントロピーが高い。
- 蒸留の際はモードコラプスのリスクが高く、低頻度クラスの予測が特に難しい(→Zipfの法則により、さらに複雑になる)。
(➡そもそも予測しにいく対象の数がタスク間で全然違うから。。普通にやってもまあうまくはいかないだとうなというのは理解しやすい)
この仮説をテストし、TAIDの柔軟性を評価するために、複数の画像分類タスクでTAIDが評価されている (結果は付録D.3)。テストの結果、TAIDは、CIFAR-100ではわずかな改善を示すにとどまったが、より複雑なImageNetタスクで一貫してCTKDおよびDKDを上回るパフォーマンスを発揮したことが確認された(ImageNetのほうが分布が複雑だから→言語モデリングの固有の課題に近い分布になっているということ)。これらの結果から、TAIDは、複雑な分布やロングテール構造を持つ多様なタスクにも適用可能な、汎用性の高いアプローチだということができると思う。
7. APPLICATION TO STATE-OF-THE-ART MODEL DEVELOPMENT
ここでは、TAID(Temporally Adaptive Interpolated Distillation) の実用的な効果を示すため、TAIDを用いて開発された2つの最先端モデルが紹介されている。なおこれらの結果により(表4,5)、TAIDが大きな容量ギャップを克服かつマルチモーダルな知識を転送する能力を示すものとなっている。
TAID-LLM-1.5B:
パラメータ数1.5Bの大規模言語モデル(LLM)。2Bパラメータ未満のモデルで新たな最先端性能を達成。
TAID-VLM-2B:
パラメータ数2Bのビジョン・ランゲージモデル(VLM)。4Bパラメータ未満のVLMの中で最高性能を記録し、より大規模なモデル(例: Phi-3-Vision 4.2B)を超える成果を達成。
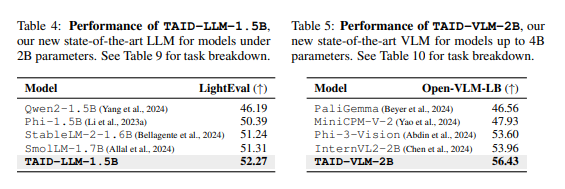
表4: TAID-LLM-1.5B のパフォーマンス(左)。表 5: TAID-VLM-2B のパフォーマンス(右)。
8. CONCLUSION
本文献で紹介された、Temporally Adaptive Interpolated Distillation(TAID) という新しい知識蒸留(Knowledge Distillation)手法は、大規模言語モデル(Large Language Models, LLMs) の圧縮に伴う課題(キャパシティギャップ、モードアベレージング、モード崩壊)を効果的に解決することともにその優れたパフォーマンスについても示された。さらに、実証のためのモデル、TAID-LLM-1.5B と TAID-VLM-2Bについても、その結果からTAIDの実用性を強調しており、TAIDが、リソースが限られた環境で高度な言語テクノロジーをよりアクセスしやすい形でデプロイすることに貢献しているということは十分しめされていると見れる(➡今後、より需要が増えていくとこのあたりはますます重要になってくるだろうなぁ)。FutureWorkとして、TAIDを他の距離メトリックへの拡張、非線形補間の研究、マルチ教師蒸留、分類以外の他のモダリティやタスクへの応用など適応が挙げられていた(➡今後に期待)。
おわりに
LLMの一般化みたいなところを考えたら今後必須になってくるような技術だったと思います。ターゲットに中間の分布をおいて、それを教師分布を徐々に変化させるという形で元のモデルの持つ複雑さを適切に学習していくアプローチというのは、イメージとしては非常にわかりやすいものだと感じた(いきなり難しいものとか全部をやらずに、まずは簡単なものから徐々にというのは人間が学習していく過程の観点からも理にかなっている)。あとデモについても出張用の貧弱ノートPCでもローカルで動いてくれたのは結構良かった(モデルが小さいのでクオリティは大きいものと比べたら…とかはあるかもだが、閉じた環境でここまで動いてくれるのは良き)。
あと、知識蒸留って実際触ったのは結構前になるけど(あのときはRNNを3層MLPとかでやってたっけ)、利活用の観点もあって最近特に勢いを増してきてるなあと感じる。あとLLMが広がりを見せる中で結構、前に出てたけど再利用できそうな技術ってのが以外と転がってそうだなあとも感じた。SakanaAIさんの前の論文(URL、これは弊社の別メンバーがまとめてみんなに共有してくれてた。そのうちこのブログでもみれるかもしれないかもしれない)も特異値分解して、効率よく学習してたし、以前から知られてたor古典的なアプローチがLLMの中に使われて結構いいものがでてくるみたいな流れはありそう。
Discussion