はじめに
お疲れ様です。STARAI社員の中岸です!今回は、画像内オブジェクトのセグメンテーションを行うモデルであるSAM(Segment Anything Model) のバージョン2が公開されたとのことですので、その文献調査という形で投稿してみようと思います!
今回紹介する文献(URL)は、下記に示すものとなります。
Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and Rádle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Alwala, Kalyan Vasudev and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Dollár, Piotr and Feichtenhofer, Christoph. SAM2: Segment Anything in Images and Videos. arXiv preprint, 2024
下記文中にて、論文の内容ではない読んでいる際に自分が感じたことや、間違ったの記述が混ざっているところもあるかもしれないのでご注意下さい。また、本記事で掲載している図や表は論文から引用したものとなります。
1. Introduction
画像におけるプロンプト可能なセグメンテーションモデルとして提案された SAM(Segment Anything Model)は、静止画像のセグメンテーションにおいて優れたパフォーマンスを示したが、ビデオデータの複雑な動き(変形、隠れ、照明条件の変化)やブレや低解像度による低品質なフレームの処理には課題が残っている(なお、ここではモデルだけでなくデータセットについても、「ビデオ内のあらゆるものをセグメントする」能力を提供する点で不足していると述べられている)。本論文では、これらの課題を克服し、画像とビデオのプロンプト可能な視覚的セグメンテーションのためのベースモデルとなるSegment Anything Model 2(SAM2)が紹介されている。
下記に、イントロダクションにある本論文のポイントをまとめた。(モデルとしてのポイントはmasklet, ストリーミングメモリ。あとは、データエンジン、SA-Vデータセット、実験についてのもの。タスクの全体像は図1にまとめられている。)
-
タスクを画像セグメンテーションをビデオ領域に一般化するプロンプト可能な視覚的セグメンテーション(Promptable Visual Segmentation)と定義。このタスクは、ビデオの任意のフレームの点、ボックス、またはマスクを入力として注目セグメントの時空間マスク(masklet)を予測するというもの。なお、このマスクレットは予測後、追加のフレームにプロンプトとして提供することで、反復的に精度を向上させることができる。
-
SAM2は、オブジェクトと以前のインタラクションに関する情報を記憶するメモリ(ストリーミングメモリ)を持っている。これにより、ビデオ全体でmasklet予測を生成し、以前のフレームからオブジェクトの保存されたメモリコンテキストに基づいて、これらを効果的に修正することができる。(動画適用のための自然な拡張、なお、画像1枚への適用の場合はメモリは空となり、通常のSAMのようにふるまうとのこと。)
-
本論文では、データエンジンを使用して、アノテーターとループ内でインタラクティブに新しい挑戦的なデータにアノテーションを付けることで、トレーニングデータを生成している。このデータエンジンは、特定のカテゴリに限定されず、様々なオブジェクトのセグメンテーションデータを提供することを目指しているとのこと。既存のモデル支援アプローチと比較して、SAM2をループ内で使用した私たちのデータエンジンは、同等の品質で8.4倍高速になった。最終的なSegment Anything Video(SA-V)データセットは、50.9Kのビデオに35.5Mのマスクを含み、従来のデータセットよりも53倍多くのマスクが含まれている。SA-Vデータセットは、ビデオ全体で隠れたり再出現したりする小さなオブジェクトを含むため挑戦的なものとなっている。また、地理的に多様であり、公平性評価では性別や年齢に基づくパフォーマンス差異が最小限であることが示されている(➡多様なデータセットになっているということか)。
-
実験では、SAM2がビデオセグメンテーションにおいてstate-of-the-artな結果を残していることを示している。SAM2は、従来のアプローチと比較して3倍少ないインタラクションでより良いセグメンテーション精度を実現。さらに、画像セグメンテーションのベンチマークでもSAMよりも優れたパフォーマンスを示し、6倍速かったと報告されている。SAM2は、他様々なベンチマーク(ビデオおよび画像セグメンテーションベンチマーク)においても効果的であることも示されている。
-
オープンライセンスの下でデータセット(CC by 4.0)、モデル(Apache 2.0)、オンラインデモ(https://sam2.metademolab.com)も公開されている。(➡リポジトリも公開されているので、そのうち遊んでみたい。windowsでpip installしたらおま環食らったのでまたこの記事書き終わったらトライする予定)

図1 タスクの全体像:データエンジン(c)を通じて収集された大規模なSA-VデータセットでトレーニングされたSAM2モデル(b)を導入しプロンプト可能な視覚セグメンテーションタスク(a)を解決する。SAM2は、以前のプロンプトと予測結果を保存するストリーミングメモリを利用して、1つまたは複数のビデオフレーム上のプロンプト (クリック(点)、ボックス、またはマスク) を通して、領域をインタラクティブにセグメンテーションできる。
3. Task: promptable visual segmentation (プロンプト可能な視覚的セグメンテーション(PVS))
プロンプト可能な視覚的セグメンテーション(PVS)タスクでは、ビデオの任意のフレームにモデルへのプロンプトを提供する。プロンプトは、オブジェクトをセグメント化するため、またはモデルが予測したものを改良するために、ポジティブ/ネガティブのクリック、バウンディングボックス、またはマスクの形で提供される。モデルはプロンプトを受け取るとすぐにそのフレームのセグメンテーションマスクを生成し、初期プロンプトを伝播してビデオ全体のセグメント(マスクレット)を取得する(追加のプロンプトでセグメントを改良することも可能、図2)。SAM2はこのタスク(PVSタスク)に適用され、SA-Vデータセットの構築とインタラクティブなビデオセグメンテーションシナリオで評価に用いられる。

図2 SAM2によるインタラクティブなセグメンテーション。ステップ1(選択):フレーム1でSAM 2にプロンプトを提供し、ターゲットオブジェクト(舌)のセグメントを取得。緑色/赤色の点はそれぞれ正のプロンプト/負のプロンプトを示す。SAM2は、セグメントを次のフレームに自動的に伝播させ(青い矢印)、maskletを作成する。SAM2がオブジェクトを見失った場合(フレーム2の後)、新しいフレームに追加のプロンプトを提供することでmaskletを修正できる(赤い矢印)。ステップ2(改良):フレーム3での1回のクリックで、オブジェクトをリカバーし、それを伝播して正しいmaskletを取得することができる。(分離されたSAM+ビデオトラッカーアプローチでは、オブジェクトを正しく再アノテーションするために、フレーム3で複数回のクリック(フレーム1のように)が必要となるが、SAM2のメモリを使用することで、1回のクリックで舌をリカバー可能。)
4. Model
SAM2は、SAMをビデオ(および画像)のドメインに一般化したモデルであるとみなせる。SAM2(図3)は、ビデオ全体でセグメンテーションされるオブジェクトの空間的範囲を定義するために、個々のフレームにポイント、ボックス、およびマスクのプロンプトをサポートしている。プロンプト可能で軽量なマスクデコーダは、フレーム埋め込み(画像特徴)と現在フレームのプロンプト(ある場合)を受け入れ、フレームのセグメンテーションマスクを出力する。プロンプトはフレーム上で反復的に追加され、マスクを改良することができる。
SAMとは異なり、SAM2デコーダで使用されるフレーム埋め込みは画像エンコーダから直接取得されるものではなく、過去の予測とプロンプトされたフレームのメモリに基づいて条件付けられている。プロンプトされたフレームは、現在のフレームに対して「未来」から来ることも可能であるとのこと。フレームのメモリは、現在の予測に基づいてメモリエンコーダによって作成され、メモリバンクに配置され、後続のフレームで使用される。メモリアテンション操作(memory attention operation)では、画像エンコーダからのフレームごとの埋め込みを取得し、メモリバンク(memory attention)に基づいて、マスクデコーダに渡される埋め込みを生成する。(➡SAMとは異なり、画像特徴(embedding)はimage encoderから直接得られるものでなく、memory attentionレイヤーを通して得られた特徴➡現在の画像特徴に過去のマスク情報などを反映した特徴がmask decoderに投げられる)

図3 SAM2のアーキテクチャでは、各フレームのセグメンテーション予測は現在のプロンプトや以前のメモリに基づいている。ビデオはストリーミング方式で処理され、画像エンコーダがフレームを一度に1つずつ処理し、前のフレームからのターゲットオブジェクトのメモリにクロスアテンション(cross-attended)する。マスクデコーダは入力プロンプトを受け取り、セグメンテーションマスクを予測する。メモリエンコーダは予測と画像エンコーダの埋め込みを変換し(ここは図中には示されていない)、次のフレームで使用する。
Image encoder
任意の長さのビデオをリアルタイムで処理するために、ストリーミングアプローチでビデオフレームを処理する。画像エンコーダは、インタラクション全体で1度だけ実行され、各フレームを表す特徴埋め込みを作成する(画像エンコーダには、MAE(Masked autoencoder, He et al., 2022)で事前訓練されたHiera(Ryali et al., 2023; Bolya et al., 2023)画像エンコーダが使用される)。
Memory attention
過去のフレームの特徴と予測、新しいプロンプトに基づいて現在のフレーム特徴を調整する。L個のトランスフォーマーブロックを使用し、セルフアテンション(最初は画像の特徴埋め込みを受け取る)とクロスアテンション((プロンプトされた/されていない)フレームのメモリとオブジェクトポインタに対して実行)を実行する。これらの後、メモリバンクに保存し、MLPを実行する。
Prompt encoder and mask decoder
SAMに基づきプロンプトを受け取りセグメンテーションマスクを予測する(プロンプトエンコーダはSAMと同様)。複数の互換性のあるターゲットマスクが存在する可能性のある曖昧なプロンプト(単一のクリックなど)に対しては、複数のマスクを予測する。後続のプロンプトが曖昧さを解消しない場合、モデルは現在のフレームの最高予測IoUを持つマスクのみを伝播するようになっている。
SAMとは異なり、正のプロンプトが与えられた場合に、常に有効なオブジェクトが存在するわけではないPVSタスクでは、いくつかのフレームでは有効なオブジェクトが存在しない可能性がある(例えば、オクルージョンのため)。この新しい出力モードに対応するために、対象オブジェクトが現在のフレームに存在するかどうかを予測するadditional headが追加されているとのこと。
Memory encoder
出力マスクを畳み込みモジュールを用いてダウンサンプリングし、unconditionalなフレーム埋め込みと合計してメモリを生成する。
Memory bank
メモリバンクは、ビデオ内のターゲットオブジェクトに関する過去の予測情報を保持し、最大Nフレームの最近のメモリと最大Mフレームのプロンプト情報をFIFOキューで管理する。空間メモリ特徴に加え、オブジェクトポインタのリストを軽量ベクトルとして保存し、空間メモリ特徴とオブジェクトポインタにクロスアテンションを行う(➡空間メモリ特徴とオブジェクトポインタ間の関係性を見ていると解釈できるか)。
直近のNフレームのメモリに時間的な位置情報を埋め込むことで、モデルが短期間のオブジェクトの動きを表現できるようにするが、プロンプトされたフレームには埋め込まないとのこと(➡様々な時間間隔で学習、もといプロンプトフレームが来るから、これへの柔軟な対応が難しいということか)。
training
モデルは画像とビデオデータで共同訓練され、以前の研究と同様にインタラクティブなプロンプトをシミュレート。8フレームのシーケンスから最大2フレームをランダムに選択してプロンプトを提供、トレーニング中に正解maskletとモデル予測を使用してサンプルされた修正クリックを確率的に受け取る。初期プロンプトは正解マスク(確率0.5)、正解マスクからサンプルされた正のクリック(確率0.25)、またはバウンディングボックス入力(確率0.25)のいずれかとなる。
5. Data
ビデオ内の「何でもセグメントする」能力を開発するために、大規模で多様なビデオセグメンテーションデータセットを収集するデータエンジンを構築。SAM2では、人間のアノテーターとインタラクティブなモデルをループ内で使用するアプローチが採用されている。データエンジンは3つのフェーズを経ており、各フェーズはアノテーターに提供されるモデルアシスタントのレベルに基づいて分類されているとのこと。以下では、各データエンジンのフェーズとSA-Vデータセットについて説明がされている。
5.1. Data engine
フェーズ1: SAM per frame
初期フェーズでは、画像ベースのインタラクティブなSAM(Kirillov et al., 2023)を使用して人間のアノテーションをアシスト。アノテーターは、6フレーム毎秒(FPS)のビデオの各フレームでターゲットオブジェクトのマスクをSAMと「ブラシ」や「消しゴム」などのピクセル精度の手動編集ツールを使用してアノテートする任務を負う。
このフェーズでは、他のフレームへのマスクの時間的伝播を支援する追跡モデルは関与しておらず、この方法はフレームごとの方法であり、すべてのフレームは最初からマスクアノテーションを必要とするため、プロセスは遅く、実験ではフレームごとの平均アノテーション時間は37.8秒と時間はかかるが、これによりフレームごとの高品質な空間アノテーションが取得可能。このフェーズでは、1.4Kビデオにわたって16Kのmaskletを収集。さらに、このアプローチを使用してSA-Vの評価セットとテストセットをアノテートし、評価中のSAM2の潜在的なバイアスを軽減する。(➡ここは1フレームごとにしっかりやっていく感じ)
フェーズ2: SAM + SAM2 Mask
第2フェーズでは、SAM2をループに追加し、SAM2はマスクのみをプロンプトとして受け入れる(このバージョンをSAM2マスクと呼ぶ)。アノテーターはフェーズ1と同様にSAMやその他のツールを使用して最初のフレームで空間マスクを生成し、次にSAM 2マスクを使用してアノテートされたマスクを他のフレームに時間的に伝播させ、完全な時空間maskletを取得する。その後のビデオフレームでは、アノテーターはSAM、ブラシ、消しゴムを使用してSAM2マスクによって行われた予測を修正し、再度SAM2マスクで伝播させ、このプロセスを繰り返してmaskletを修正していく。
SAM2マスクは、最初にフェーズ1のデータと公開データセットでトレーニングされた。フェーズ2では、収集されたデータを使用して、アノテーションループでSAM2マスクを2回再トレーニングして更新したとのこと。
フェーズ2では63.5Kのmaskletを収集。アノテーション時間は1フレームあたり7.4秒に減少し、フェーズ1に比べて約5.1倍の速度向上が見られたが、この分離されたアプローチでは、前のメモリなしで中間フレームのマスクを最初からアノテートする必要がある(➡そこで、インタラクティブな画像セグメンテーションとマスク伝播の両方を統一モデルで実行できるSAM2の出番というわけですね)。
フェーズ3: SAM 2
最終フェーズでは、ポイントやマスクを含むさまざまなタイプのプロンプトを受け入れる完全機能のSAM2を使用した。SAM2は時間的次元を超えたオブジェクトのメモリから利益を得てマスク予測を生成する。これは、アノテーターが中間フレームで予測されたmaskletを編集するために時折修正クリックを提供するだけで済み、spatial SAMのように最初からアノテーションを行う必要がないことを意味している。フェーズ3では、収集されたアノテーションを使用して5回再訓練および更新を行ったとのこと。SAM2がループ内にあることで、1フレームあたりのアノテーション時間は4.5秒に減少し、フェーズ1に比べて約8.4倍の速度向上が見られ、197.0Kのmaskletが収集された。
Quality verification
アノテーションの高い基準を維持するために、検証ステップが導入されている。別のアノテーターたちが、各アノテートされたmaskletの品質を「満足」(全フレームにわたってターゲットオブジェクトを正確かつ一貫して追跡している)または「不満足」(ターゲットオブジェクトが明確に定義されているが、maskletが正確または一貫していない)として検証。不満足なmaskletは精査のためにアノテーションパイプラインに戻される。明確に定義されていないオブジェクトを追跡するmaskletは拒否されるとのこと。(➡アノテーションした人とは別のアノテーターたちがしっかりと検証に入っている)
Auto masklet generation
アノテーションの多様性を確保するために、自動生成されたmaskletを使用しアノテーションを補強する(SAM2の最初のフレームに規則的なグリッドポイントでプロンプトし、maskletを生成、これらは検証ステップに送られて「満足」であればデータセットに追加、「不満足」、つまり失敗のケースであれば、サンプリングされてフェーズ3のループ内でアノテーターに精査される)。これによりアノテーションのカバレッジを増やし(大きな目立つ中央のオブジェクトだけでなく、背景のさまざまなサイズと位置のオブジェクトもカバーできるようになる)、モデルの失敗ケースを特定することが可能となる。
Analysis
表1は、各データエンジンのアノテーションプロトコルの比較したもの。フレームあたりの平均アノテーション時間、maskletあたりの手動編集フレームの平均割合、クリックされたフレームあたりの平均クリック数を比較が比較されている。品質評価のために、フェーズ1のマスクアライメントスコア(高品質なフェーズ1のマスクとのIoUが0.75以上ある割合)も算出されている。フェーズ3では、効率が向上し(フェーズ1より8.4倍高速、編集フレームの割合とフレームあたりのクリック数が最も少ない)、品質も担保されていることがわかる。
表2では、各フェーズの終了時に利用可能なデータで訓練されたSAM2の性能比較を示している(追加データの影響のみを測定するために、イテレーション数を固定)。MetaのSA-V検証セットと9つのゼロショットベンチマークを用いて、標準的なJ&F metric(➡Jは領域類似度、予測マスクのIoU。Fは輪郭精度、マスク領域範囲を区切る閉じた輪郭間の類似度であり、正解マスクの輪郭と予測マスクの輪郭において計算できるPrecisionとRecallの調和平均(F-score))で評価している(最初のフレームで3クリックでプロンプトするときで評価している)。表2から、各フェーズのデータを逐次的に含めることで、SA-V検証セットだけでなく、9つのゼロショットベンチマークでも一貫した改善が確認できる。

表1 各データエンジンのアノテーションプロトコルの比較結果。フェーズ3のデータエンジンは品質と効率の両方を備えていることがわかる。
5.2. SA-V dataset
SA-Vデータセットは、50.9Kのビデオと642.6Kのmaskletで構成されており、既存のVOSデータセットよりもはるかに多くのアノテーションを含んでいる(詳細な比較は表3に掲載されている)。このデータセットは、将来の研究に対する重要なリソースを提供し、許容的なライセンスの下で公開される。ビデオは、クラウドワーカーによって撮影されたものを収集。54%が屋内シーン、46%が屋外シーン、平均時間は14秒、ビデオは「in-the-wild」の多様な環境を特徴とし、さまざまな日常のシナリオをカバーしている。このデータセットは既存のVOSデータセットよりも多くのビデオを含み、図5に示すように、ビデオは47か国にわたり、多様な参加者によって撮影されたとのこと)。
masklet
アノテーションは、データエンジンを使用して収集された190.9Kの手動maskletアノテーションと451.7Kの自動maskletで構成されている。maskletを重ね合わせたビデオの例(手動および自動)が図4に示されている。SA-Vは、最大のVOSデータセットよりも53倍(自動アノテーションを除くと15倍)のマスクを含んでいる。
SA-V Manualにおける消失率(少なくとも1フレームで消失し、その後再出現するアノテートされたmaskletの割合とのこと)は42.5%で、既存のデータセットの中でも優位性がある。図5(a)は、DAVIS、MOSE、およびYouTube VOSと比較したマスクサイズ分布(ビデオ解像度で正規化)が示されている。SA-Vのマスクの88%以上が正規化されたマスク面積が0.1未満となっている(➡マスクが予測しにくい小さいものもしっかり含まれている、ということが言いたいのだろうと思う)。

図4 SA-V datasetのmaskletの例
SA-Vのトレーニング、検証、テストの分割
SA-Vは、ビデオの作成者(およびその地理的位置)に基づいて分割し、類似したオブジェクトの重複を最小限に抑えるようにしている。SA-Vの検証セット(val)およびテストセット(test)を作成するために、ビデオを選択する際に挑戦的なシナリオに焦点を当て、アノテーターに対して、速く動く、他のオブジェクトによる複雑なオクルージョンを持つ、および消失/再出現パターンを持つターゲットを特定するように依頼したとのこと。これらは、5.1.のデータエンジンフェーズ1のセットアップを使用して6FPSでアノテートされた。SA-Vの検証セットには293のmaskletと155のビデオが、テストセットには278のmaskletと150のビデオが含まれているとのこと。
内部データセット
さらにトレーニングセットを増強するために、内部で利用可能なライセンスビデオデータも使用。
内部データセットは、トレーニングのためにフェーズ2およびフェーズ3(5.1.)でアノテートされた62.9Kのビデオと69.6Kのmasklet、およびテストのためにフェーズ1でアノテートされた96のビデオと189のmasklet(Internal-test)で構成されているとのこと。
6. Zero-shot experiments
ここでは、ゼロショットビデオタスク(6.1.)および画像タスク(6.2.)におけるSAM2と以前の研究が比較されている。ビデオタスクでは標準のJ&Fメトリック(Pont-Tuset et al., 2017)を、画像タスクではmIoUメトリックで評価されている。(特に記載がない限り、このセクションで報告されている結果は、Hiera-B+画像エンコーダを使用し、解像度1024で、データセットの完全な組み合わせでトレーニングされたデフォルトセットアップに従うとのこと)。
6.1. Video tasks
Promptable video segmentation
ここでは、プロンプト可能なビデオセグメンテーションタスクについてオフライン評価とオンライン評価の2つの設定で評価を行っている(以下付録に詳細があったのでまとめる)。
オフライン評価: ビデオ全体を複数回処理。最初のフレームでクリックプロンプトを開始し、各パスで最もセグメンテーション精度が低いフレームを新しいプロンプト用フレームとして選択。これを最大Nフレームのパスに達するまで繰り返す。
オンライン評価: ビデオ全体を1回のみ処理。最初のフレームでクリックプロンプトを開始し、品質が低いフレームに遭遇した際に一時停止し、追加のクリックプロンプトで修正する。これを繰り返し、プロンプトされたフレームの数が最大Nフレームに達するまで続ける。新しいプロンプトは一時停止したフレーム以降にのみ影響する。
(➡オフライン評価は複数回のパスを行うため、繰り返すことで全体的な精度向上が期待できる一方で、オンライン評価はリアルタイム性を重視し、一度のパスで効率的にセグメンテーションを行っていくという感じみたい。)
これらの評価は、N_{click} = フレームあたり3クリックを使用して、9つの密なアノテーション付きゼロショットビデオデータセットで実行される。また、2つのベースラインモデル(XMem++およびCutieを使用したSAM+XMem++とSAM+Cutieの2つ)との比較が行われている。結果から、SAM2は、少ないクリック数で高品質なビデオセグメンテーションを生成し、さらにプロンプトを追加することでさらに結果を改良することが可能であることが示されている。SAM2は、オフラインおよびオンライン評価の両方でベースラインモデルを上回り、3倍少ないインタラクションでより高い精度を達成したことが示されている(図6)。

図6
Semi-supervised video object segmentation
ここでは、半教師付きビデオオブジェクトセグメンテーション(VOS)設定(最初のフレームにのみ、クリック、ボックス、またはマスクプロンプトを使用する設定)で評価している。クリックプロンプトの場合、最初のフレームに1、3、または5クリックをサンプリングし、これらに基づいてオブジェクトを追跡する。クリックとボックスプロンプトにはSAM、マスクプロンプトにはXMem++およびCutieのデフォルト設定を使用して比較(すなわち、前節と同様にSAM2と、SAM+XMem++、SAM+Cutieの2つのモデルを比較する)。結果から、SAM2は、17のデータセットでクリック、ボックス、マスクプロンプトを使用して両方のベースラインを上回っていることが確認され、SAM2が非インタラクティブなVOSタスクでも優れていることが示されている(表4)。

表4
Fairness evaluation
ここでは、SAM2の人口統計グループ間の公平性について評価している。EgoExo4D (Grauman et al., 2023) データセットの人物カテゴリのアノテーションを収集。(このデータセットには、ビデオの被写体が提供した自己申告の人口統計情報が含まれている。)SA-V valおよびtestセットと同じアノテーション設定を使用し、これを三人称 (exo) ビデオの20秒のクリップに適用、このデータで、最初のフレームで1クリック、3クリック、および正解マスクを使用してSAM2を評価した。
表5は、性別と年齢で人物をセグメント化するSAM2のJ&Fメトリックの精度比較を示している。
3クリックと正解マスクプロンプトを使用すると、差異は最小限になる。1クリックの予測を手動で検査すると、モデルが人物ではなくパーツのマスクを頻繁に予測していることが確認されたとのこと。(➡様々な年齢、性別の人物にセグメンテーションが適用できるかを確かめたかったということか)
6.2. Image tasks
ここでは、画像タスクの評価について述べられている(表6)。37のゼロショットデータセットでSAM2を評価しており、1クリックと5クリックの場合におけるmIoUがまとめられている。SAM2はSAM(1クリックで58.1 mIoU➡1クリックで58.9 mIoUへ向上)よりも高い精度を達成し、処理速度も6倍速くなっている(➡SAM2の小型で効果的なHiera画像エンコーダに起因しているとのこと、ここはもう少し調べてみたい)。さらに、SA-1Bおよびビデオデータのミックスでトレーニングすることで、23のデータセットでの精度が平均61.4%に向上することが示されている。SA-23のビデオベンチマーク(ビデオデータセットは(Kirillov et al., 2023)と同様に画像として評価される)および追加した14の新しいビデオデータセットでも大幅な精度向上が確認できた。

表6
7. Comparison to state-of-the-art in semi-supervised VOS
SAM2はPVSタスクに加えて、歴史的に一般的な半教師付きVOS設定(プロンプトが最初のフレームの正解マスクであるという設定)にも対応しており、ここでは、既存の最先端技術との精度比較も行っている(異なる画像エンコーダサイズ(Hiera-B+/-L)の2つのバージョンを評価)。表7から、SAM2は、精度と推論速度の両方で既存の方法よりも優れており、特に大きな画像エンコーダを使用すると全体的な精度が大幅に向上することが示された。
8. Data and model ablations
このセクションでは、SAM2の設計の決定に影響を与えたアブレーション(➡人工知能(AI)や機械学習におけるアブレーション(ablation)は、特定のコンポーネントやデータの部分を意図的に削除して、その削除が全体のシステムの性能や動作に与える影響を評価することを目的として行われるもの、要は様々な実験設定でモデルの性能がどのように変化するかというところを調査している部分)について紹介されている。
評価は、MOSE開発セット(「MOSE dev」、MOSEトレーニングスプリットからランダムにサンプリングされた200のビデオが含まれており、アブレーションのトレーニングデータから除外されている)、SA-V val、9つのゼロショットビデオデータセットを用いて行われる。比較指標として、1クリックとVOSスタイルのマスクプロンプトの中間である、最初のフレームでの3クリック入力に基づくJ&Fと、SAMが画像タスクのために使用した23データセットベンチマークでの1クリックmIoUの平均がまとめられている(特に指定がない限り、解像度512でSA-V ManualとSA-1Bの10%サブセットを使用してアブレーションを実行)。

表7
8.1. Data ablations
Data mix ablation.
表8には、異なるデータミックスで訓練されたSAM2の精度が比較されている。SA-1Bで事前訓練し、各設定ごとに別々のモデルを訓練する。イテレーション数(200k)とバッチサイズ(128)は固定し、実験間で変更されるのはトレーニングデータのみとなっている。SA-V val、MOSE、9つのゼロショットビデオベンチマーク、およびSA-23タスクでの精度がまとめられている。1行目は、VOSデータセット(Davis、MOSE、YouTubeVOS)のみで訓練されたモデルが、インドメインであるMOSE devでは良好に動作するが、他のすべてのデータセットでパフォーマンスが悪かったことが示されている。
トレーニングミックスにデータエンジンデータを追加することで、9つのゼロショットデータセットでの平均パフォーマンスが+12.1%改善するという結果が見られた(表8. 行11 vs 1)。これはVOSデータセットのカバレッジとサイズが限られているためと考えられる(➡要はバリエーションが足りてない)。さらに、SA-1B画像を追加すると、VOS能力を低下させることなく画像セグメンテーションタスクのパフォーマンスが向上していることが確認できる(表8. 行3 vs 4、5 vs 6、9 vs 10、11 vs 12)。SA-VとSA-1Bのみで訓練すること(表8. 行4)で、MOSE devを除くすべてのベンチマークで強力なパフォーマンスが得られている。全体としては、すべてのデータセット(VOS、SA-1B、およびデータエンジンデータ)を混ぜると、最良の結果が得られた(表8. 行12)。
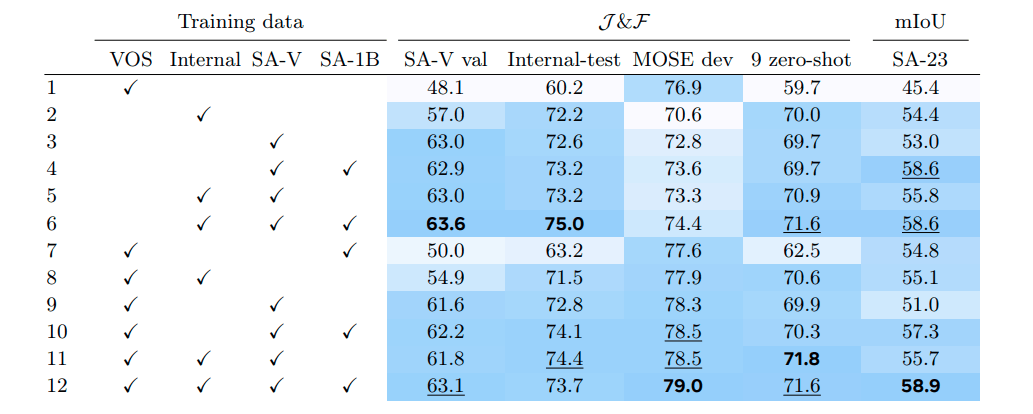
表8
Data quantity ablation.
ここでは、トレーニングデータのスケーリング効果を調査した。SAM2はSA-1Bで事前訓練された後、さまざまなサイズのSA-Vで訓練される。3つのベンチマーク(SA-V検証、ゼロショット、およびMOSE devセット)にわたって、最初のフレームで3クリックのプロンプトを使用した場合の平均J&Fスコアが報告されている。図7では、トレーニングデータの量とビデオセグメンテーション精度の間の一貫したべき乗則の関係があることを示している。(➡要はデータ量大事、ということ)
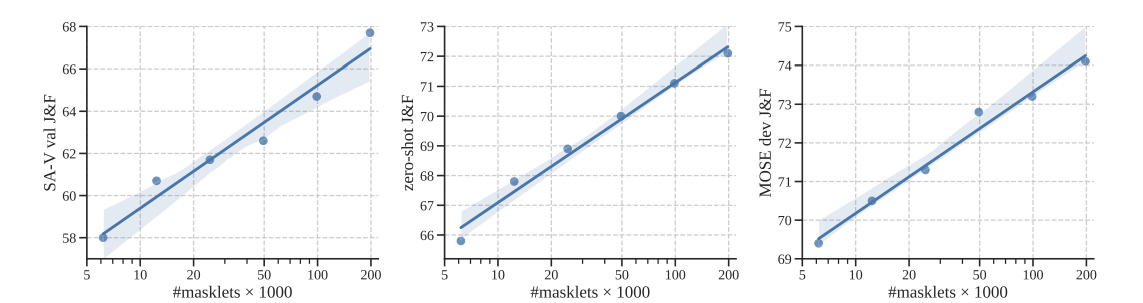
図7
Data quality ablation.
ここでは、フィルタリング戦略を実験し、アノテーターによって編集されたフレームの数に基づいてフィルタリングすることで、ランダムサンプリングよりも良好なパフォーマンスを発揮するが、すべてのmasklet(190K)を使用するよりは劣るという結果となった。(➡アノテーターによって多く編集されているフレームの(クオリティが高い)maskletを使用すると少ないサンプルでもある程度の結果が示せたといういこと、データ品質に対する示唆が与えられている)
8.2. Model architecture ablations
ここでは、設計の決定を導いたモデルアブレーションが紹介されている。ビデオ(J&F)および画像(mIoU)タスクのセグメンテーション精度とビデオセグメンテーション速度(FPS)が報告されている。ここでの実験により、画像とビデオのコンポーネントに対する設計選択は大部分が分離されていることが判明したとのこと。
8.2.1 Capacity ablations
Input size.
解像度を高くすることで画像およびビデオタスク全体で大幅な改善をもたすことができた(表10(a)、10(b))。また、フレーム数を増やすことでビデオベンチマークで顕著な精度向上が見られた。(なお、実際には、速度と精度のバランスをとるためにデフォルトで8が使用されている)
Memory size.
メモリ数(最大値)を増やすことで一般的に性能が向上するが、ばらつきがあることも確認された(表10(c))。実際には、過去6フレームをデフォルトとして使用し、時間的コンテキストの長さと計算コストのバランスとっているとのこと。メモリ用のチャンネル数を減らすことは、ストレージに必要なメモリを4倍小さくしながらも、性能の低下をほとんど引き起こさなかったことが確認された(表10(d))。
Model size.
バックボーン(Image encoder size)とメモリアテンションの容量を増やすことで結果が向上し(表10(e)、10(f))、特にB+バックボーンを使用すると速度と精度のバランスが取れ、この時点で、SAM ViT-Hを大幅に上回る性能を発揮している。
バックボーン(Image encoder size)またはメモリアテンションの容量を増やすことで一般的に結果が向上することが確認された。バックボーンをスケーリングすると画像およびビデオメトリクスの両方で向上が見られるが、メモリアテンションをスケーリングするとビデオメトリクスのみが向上しているという結果となった。実際には、B+バックボーンの使用をデフォルトとし、速度と精度のバランスがとられている。なお、B+バックボーンでも、SAM2はすでにSAM ViT-Hの精度を大幅に上回っていることが確認できた(表6を参照)。

表10
8.2.2 Relative positional encoding
デフォルトでは、画像エンコーダおよびメモリアテンションの両方で絶対的な位置エンコーディングが使用されている。このセクションでは、相対的な位置エンコーディングについての調査が行われている。ここでは、バックボーンからすべての相対位置バイアス(RPB)を削除し、性能を維持しつつ速度を向上できることが報告されている。また、メモリアテンションで2d-RoPE(Su et al., 2021; Heo et al., 2024)を使用することが有益であることも報告されている(表11)。
8.2.3 Memory architecture ablations
Recurrent memory.
メモリ特徴をメモリバンクに追加する前にGRUに供給する効果が調査されているが、表12の結果はこのアプローチが改善を提供しないことを示唆している(LVOSv2ではわずかに改善)。メモリ特徴を直接メモリバンクに保存するだけで十分であり、これがシンプルかつ効率的であることが確認された。
Object pointers.
オブジェクトポインタへのクロスアテンションは、SA-V valおよびLVOSv2ベンチマークで性能を大幅に向上させることが確認されたため、デフォルト設定として採用されている。
9. Conclusion + さいごに(所感)
本論文は、Segment Anything Modelをビデオドメインに拡張し、
3つの主要な側面に基づいてこれを実現したという内容。
(i) プロンプト可能なセグメンテーションタスクをビデオに拡張
(ii) ビデオに適用する際に、メモリ機能が使用できるようにSAMアーキテクチャを拡張
(iii) トレーニングおよびベンチマーキングのための大規模かつ多様なSA-Vデータセットの構築
ここから所感
画像において高品質なセグメンテーションができていたSAMを、動画にも(自然な形で)拡張という内容。読み応えのある論文だった(全部理解したとは言っていない、色々と参考文献が追えてないところもあったので、また読み直したい…)。
動画ドメインへの拡張、メモリアーキテクチャの導入なども、十分素晴らしいが、個人的には、データエンジンやSA-Vデータセットの部分を読み込めたのが良かった。やはり大規模かつクオリティの高いデータセットを作る枠組みをしっかり構築している点、また、そのループ(データ収集→アノテーション作成・改善→モデル学習→実証)をしっかり回せている点については、見習うべき点が多い(少しでも真似したり取り組んでいけるところは取り組まねば…!)。
運用の中でどんどんデータを集めて、かつそれをきちんとデータセットに組み込んでいく枠組みは
しっかりと整備していおきたいと感じている今日この頃(現場だと、結局人手で収集もアノテーションもやって圧倒的にリソース足りない、みたいなケースが散見されるんだよなぁ)…。

Discussion