こんにちは。スターフェスティバル株式会社の ikkitang です。
先日、自分が所属するエンジニアチームにて、障害対応の振り返りを実施した所、チーム全体で学びを得る事が出来たので、それについてブログを書いてみたいと思います。
発生した障害について
アーキテクチャの前提共有
ある程度、障害について把握した上で読み進めてもらう方が良いように思いますので、同じような障害が発生する例を出しておきたいと思います。(弊社のアプリケーションの話をすると、コンテキストを色々説明する必要があるので、抽象化します。)
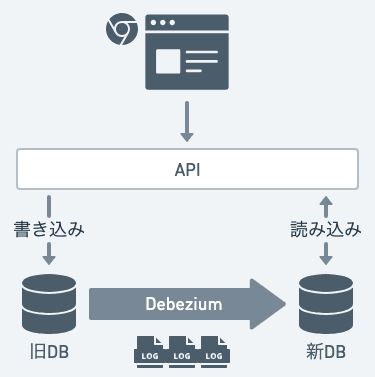
今回障害が発生したアーキテクチャの例が上図です。
自分達のチームは今、既存のシステムのリプレースを進めています。 ( 参考: DBリファクタリングのデータリモデリング勘所)
ある課題解決の対応で、旧DBへの書き込みをし、それを Debeziumというアプリケーションを使い、旧DBのInsert/Update/Deleteを検知し、新しいリファクタリング後のDBへ整形してデータ登録する、という実装を行いました。
旧DBはまだまだ既存システムから利用されている為、そこを切り離す事は難しいので、新システムからAPI経由で書き込みは旧DB、読み込みは新DBへ行うというアーキテクチャを選定しました。(これ、厳密では無いんですが、一旦言及はここまでとさせて頂きますね。)
発生した障害
今回の障害は、旧DBへの書き込みがユニーク制約違反で失敗した事をエラー検知した事から発覚しました。
新DBに既にデータがある場合は、Validationによってそもそも書き込み出来ないように実装されている事、また、旧DBから新DBへのDebeziumによるコピーのレイテンシーはほぼ無視できるぐらい高速である事から、何かおかしい事が発生していると思い、調査を進めた所、新DBへデータ登録がされていない事が発覚しました。
Debeziumに何かしら障害が発生しているだろう、と当たりを付けログを確認した所、Debeziumを動かしているサーバーがスタックしており何も処理出来ていない状況で、そこからなんとかDebeziumを復旧させて(紆余曲折あって8時間ぐらい掛かりました)復旧となりました。
チームでの課題感
私達のチームでは、2週間に一度チームの振り返りを Good/More という振り返り手法で実践しています。
障害対応のあった週のMoreポイントで「どういう原因切り分けでDebeziumが止まっているかに至ったのか把握出来なかった」とか「障害対応時、結局何やってるか分からなかった」といったMoreポイントが出てきました。
そこでチームのTryとして、「障害対応振り返りを行う。障害対応を実践した人はどう考えてどのように復旧へと至ったかを会話する。」というTryを定めて、翌週に実施する事としました。(念のため補足ですが、障害発生の翌日にこの問題に対する再発防止策の議論は終わってる、という前提です。)
障害対応振り返りの進め方
自分達のチームでは障害時に、障害対応が発生した時に 障害対応の全体指示をする人、バグ修正対応をする人、調査対応をする人、調査状況のサマリをドキュメントにまとめる人 という即席チームを組んで障害対応を進めています。なので、障害対応後は 障害対応の時に作ったドキュメントを読む事で障害発覚から修正対応までの時系列や暫定対応・恒久対応を知る事が出来る状態になっています。
ドキュメントを読むことで後から障害対応に関わってくれた方はそれを見れば現状を把握する事が出来ますし、調査対応・バグ修正対応をする人は コミュニケーションを全体指示の人に任せる事によって自分の作業にしっかり集中してもらう事が出来ます。
全体指示の人がいる事で障害の復旧に向けて即席チームの方が皆何かしらの障害復旧に向けて作業出来る状態を作る事も出来る体制というのが意図です。
振り返りはこのドキュメントをチームで読む所から始めました。振り返りで出ていた課題としては、バグ修正や全体指示を出している人がどういう思考回路でバグの特定に至ったかどうかが把握する事が難しかったという課題があったので、 どういう風に考えればこの結論を得る事が出来るか を可能な限り言語化しながら進めていきました。
例えば、「エラーが発生したら A, B, C, D の原因が考えられそう、このテーブルにSQLを投げてデータがなければ、少なくともDの選択肢は消える」といった具合です。特に障害対応時は「仮説を立てて、それを証明出来るような事実を集めていき、原因の確度を高めていくと良い」といったような障害対応全般的に使えるようなノウハウも議論の中で得る事も出来ました。
最後に、実際にエラーが発生したと仮定して、CLIでDebezium周りの設定をいじってみるペア作業をやったりなどして、チーム全体で多少アーキテクチャの理解を深めたとして振り返りを追えました。
まとめ
勿論、システム全体のアーキテクチャを一度の振り返りで完全に理解するのは難しく、「今回のエラー理由とか原因切り分けは把握出来たけど、次また発生した時に調査出来るかは不安ではある」という言葉もメンバーから得られました。
とはいえ、一つの具体的な障害対応を振り返ることで、システム全体のアーキテクチャに対する理解は少しでも深まり、具体的な問題解決手法だったり全般的な障害対応の方法について再確認する機会となった事は非常に貴重だったように思います。
また、ペア作業によって対応方法の一部をスキトラする事が出来たり、テスト環境などで障害が発生した時にモブ作業・ペア作業で解決しながらアーキテクチャの理解を深めていこうといった議論もあり、チーム全体でより安定したプロダクトを提供していく意識合わせが出来た所は良かったです。

Discussion