


Hackathon開催🚀
みなさん、こんにちは。スターフェスティバル株式会社の@koga1020_です。
桜前線とともにChat GPTをはじめとしてAI関連の話題が飛び交っておりますが、いかがお過ごしでしょうか。
そんな最中、3/27(月)、スターフェスティバルでは Open AI Hackathon#1 と題して、ハッカソンが開催されました🏃
次のようなコンテンツです。
- 1日フルで業務時間を充て、Open AIおよび周辺のエコシステムに触れ、事業、業務に使えるアイデアを見つける
- 言語、テーマは自由。自由な発想で!
- お客様向けの機能でもよし、社内向けの運用改善のツールでもよし
- チームを組むもよし、個人でやるもよし
ということで、私はElixirを使ってプロトタイプを作ってみました。1日という短い時間でしたが、どのようにプロトタイピングを進めたかをまとめてみます。Livebookでのプロトタイプが感触よかったので、その雰囲気を伝えられたらと思います。
作ろうとしたもの・大方針
GitHubの openai/openai-cookbook にOpenAI APIを利用した事例集がJupyter Notebook形式で公開されています。
この例の中に Question Answering using Embeddings という、Embeddings APIとCompletions APIを利用し、事前に用意したテキストを参照しつつGPT-3が回答できるようにする事例が掲載されています。
今回はこれを参照しながらElixirでEmbeddings API, Completions APIを利用し、社内のデータソースを加工したらどんなものができそうか、プロトタイピングを進めました。
環境構築
Elixir, Phoenixのインストーラー、Livebookのバージョンは次の通りです。Livebookを利用しているのがポイントで、このようなHackathonやプロトタイプ実装ではLivebookのようなnotebookを活用すると非常に快適です。
$ elixir -v
Erlang/OTP 25 [erts-13.2] [source] [64-bit] [smp:10:10] [ds:10:10:10] [async-threads:1] [jit] [dtrace]
Elixir 1.14.3 (compiled with Erlang/OTP 25)
$ mix phx.new --version
Phoenix installer v1.7.1
$ livebook --version
Erlang/OTP 25 [erts-13.2] [source] [64-bit] [smp:10:10] [ds:10:10:10] [async-threads:1] [jit] [dtrace]
Elixir 1.14.3 (compiled with Erlang/OTP 25)
Livebook 0.8.1
ベース構築
トライアンドエラーを回せる環境をまずは作ってしまいます。プロジェクトを適当な名前で作成します。
$ mix phx.new sample
Phoenixプロジェクトが作成できたら、DBコンテナを用意します。この程度のymlだとChatGPTに頼んだら一瞬で生成してくれるので、手元にない方はChatGPTにお願いしてしまいましょう。
# docker-compose.yml
version: "3"
services:
db:
image: postgres:latest
restart: always
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: secret
POSTGRES_DB: sample_dev
ports:
- "5432:5432"
volumes:
- db_data:/var/lib/postgresql/data
volumes:
db_data:
$ docker compose up -d
DBコンテナを起動したら、config/dev.exs を修正してDBの設定を済ませてしまいます。
# Configure your database
config :sample, Sample.Repo,
username: "postgres",
password: "secret",
hostname: "localhost",
database: "sample_dev",
stacktrace: true,
show_sensitive_data_on_connection_error: true,
pool_size: 10
config修正後、ectoのセットアップタスクを実行します。これがエラーなく通ればDBの設定までOKです。
$ mix ecto.setup
Phoenixをノード名、cookie名を指定して起動します。このノード名、cookie名はLivebookからの接続で利用します。
$ elixir --sname sample@localhost --cookie sample -S mix phx.server
Livebookからの接続
別でターミナルを開き、先ほど指定したノード名、cookie名を指定してLivebookを起動します。
$ LIVEBOOK_DEFAULT_RUNTIME=attached:sample@localhost:sample livebook server --home .
適当なパスで新規ノートブックを作成すると、Runtimeが Attached となっており、起動しているPhoenixアプリケーションに接続されています。これですぐにPhoenixアプリケーション内のコードをLivebookで即試すことができます。便利です!!

ここまでの手順をコンテナ環境で実現する流れも以前記事にしてますので、興味のある方は是非こちらも参照してみてください。
これで、Mixプロジェクトにdepsを追加して、Livebookで検証し、うまくできたものをPhoenixに載せていく というサイクルが回せるようになりました⚙
開発に必要な依存の追加
openai, nx, explorerを依存に追加します。OpenAIのAPIを利用するだけならばnx, explorerは不要ですが、前述のcookbookにあるようにembeddingの計算をするような場面ではnx, explorerがあると良いです。
defp deps do
[
{:phoenix, "~> 1.7.1"},
{:phoenix_ecto, "~> 4.4"},
{:ecto_sql, "~> 3.6"},
{:postgrex, ">= 0.0.0"},
{:phoenix_html, "~> 3.3"},
{:phoenix_live_reload, "~> 1.2", only: :dev},
{:phoenix_live_view, "~> 0.18.16"},
{:floki, ">= 0.30.0", only: :test},
{:phoenix_live_dashboard, "~> 0.7.2"},
{:esbuild, "~> 0.5", runtime: Mix.env() == :dev},
{:tailwind, "~> 0.1.8", runtime: Mix.env() == :dev},
{:swoosh, "~> 1.3"},
{:finch, "~> 0.13"},
{:telemetry_metrics, "~> 0.6"},
{:telemetry_poller, "~> 1.0"},
{:gettext, "~> 0.20"},
{:jason, "~> 1.2"},
{:plug_cowboy, "~> 2.5"},
+ {:openai, "~> 0.4.0"},
+ {:nx, "~> 0.5.2"},
+ {:explorer, "~> 0.5.6"}
]
end
mix deps.get で依存を取得したら、config/dev.exs にopenaiの設定を追加しておきます。環境変数も合わせてセットしておきます。
config :openai,
api_key: System.fetch_env!("OPENAI_API_KEY"),
organization_key: System.fetch_env!("OPENAI_ORG_KEY"),
http_options: [recv_timeout: 60_000]
Livebookを軸にプロトタイプを進める
ここからは楽しくも難しい、プロトタイピングの時間です。Livebook上で意図した結果が得られるか、試行錯誤を進めます。
レコードの値をもとにpromptを作成、Completions APIを呼び出す
Catalog コンテキストモジュールで Product スキーマを扱うという、公式ガイドにもあるような構成を作りました。mix phx.gen.context で気軽に作っては壊しが出来ます。
- DBのレコードでループ
- レコードの中身を用いてpromptを生成
- chat completion APIを実行する
- 実行結果をカラムに保存する
という処理は次のように書けます。本来ならばDBのロックやレコードの総量を考えたりする必要がありますが、ここでは目を瞑りましょう。
import Ecto.Query
alias Sample.Catalog.Product
alias Sample.Repo
Product
|> order_by([p], desc: p.id)
|> Repo.all()
|> Enum.each(fn p ->
# Rate limit対策
:timer.sleep(1000)
prompt = """
promptをProductsの値を参照して作る
"""
{:ok, %{choices: [%{"message" => %{"content" => content}}]}} =
OpenAI.chat_completion(
model: "gpt-3.5-turbo",
messages: [
%{role: "system", content: "<systemの文言埋める>"},
%{role: "user", content: prompt}
]
)
p
|> Product.changeset(%{keywords: content})
|> Repo.update()
end)
APIを叩く部分だけを切り取ってはLivebookの別のセルで試し、うまくいったら別のセルに移してつなげたり、、といった具合に検証を進めました。

embeddingsを取得、内積の計算
Embeddings APIの挙動確認と、元のJupyter Notebookでの np.dot している箇所の実装方法を確認していきました。このような小さなコード片で動きを見ていけるのはnotebookの醍醐味です。
model = "text-embedding-ada-002"
{:ok, %{data: [%{"embedding" => embedding1}]}} =
OpenAI.embeddings(
model: model,
input: "this is some text"
)
{:ok, %{data: [%{"embedding" => embedding2}]}} =
OpenAI.embeddings(
model: model,
input: "this is some text"
)
tensor1 = Nx.tensor(embedding1, type: :f64)
tensor2 = Nx.tensor(embedding1, type: :f64)
# 同じ値なら1になるはず
relevant = Nx.dot(tensor1, tensor2)
dbg()
dbg/2 を使えば変数の中身も確認できます。
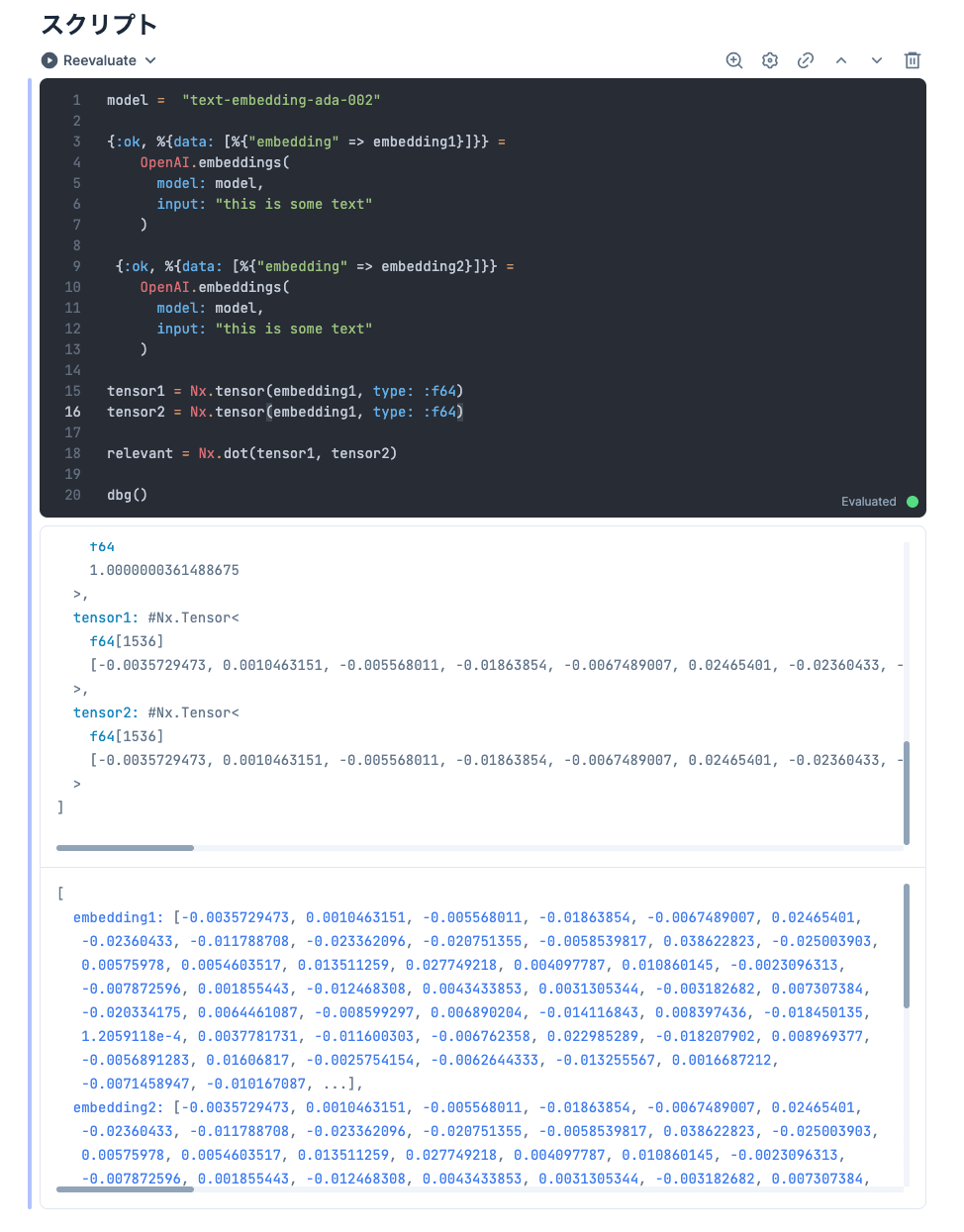
これ以降の実装は割愛しますが、あとは DataFrame.new(Nx.tensor(embedding, type: :f64)) のようにexplorerを使ったりと、元のcookbookのpandasと近いイメージでデータ操作できました。
CompletionsAPIを利用したフリーワード検索を実装しながらpromptを試行錯誤したり、それをPhoenixのLiveViewで提供してみるなどして過ごしたのち、ハッカソン終了となりました。
成果発表
最後はmeetで繋いで成果発表です。
- コードレビューやスクラム開発でのレトロスペクティブで使えるようなツール
- ごちクルで提供できそうな新機能のプロトタイプ
などなど、多種多様な成果物が発表されました。「これもう早々にプロダクション出せそう!」みたいな成果物も多々あり、盛り上がりました🎉
まとめ
どっぷりと新しい技術に取り組めて、大変有意義な時間となりました。変化の激しい時代ですが、お客様や社内のユーザーに喜んでもらえるような機能まで昇華させて、新しい体験を提供していきたいものです。
p.s. データ設計・活用勉強会を開催します!
4/6(木)19:00~ オンラインにてデータ設計・活用に関する勉強会を開催します!このAI時代、データの利活用はマストとなってきました。興味のある方は以下のconnpass URLよりぜひご参加ください!

Discussion