
こんにちは!
スターフェスティバルでインフラ/データ基盤エンジニアをしております山﨑です。
今年に入っていくつかSnowflakeのブログを書いていますが、今年からデータ基盤としてSnowflakeを活用しています。
Snowflake周りの情報キャッチアップのために、先日Snowflake主催のイベント「Snowflake DATA CLOUD WORLD TOUR」に参加してきたので参加レポートを書いてみます。
資料とか公開されていたら追記します!
Snoweflake DATA CLOUD WORLD TOUR とは
Snowflake主催の1年に一度のカンファレンスです。
年1のイベントなのでSnowflake社もかなり力をいれており、多くの企業やパートナーが参加されおり、熱気あふれるイベントでした。
ビジネスにイノベーションをもたらす、すべてのデータプロフェッショナルのためのSnowflake主催イベント。
DATA CLOUD WORLD TOUR 開催!
顧客行動の多様性や、急速な市場変化やニーズの多様性に対応するために、SnowflakeのDATA CLOUDは次のステージへ。
データクラウドを活用して、新たなデータドリブン経営の一歩を踏み出した企業のビジネスリーダーや、専門家が一堂に会するDATA CLOUD WORLD TOUR TOKYOで自社のビジネスに革新をもたらす一日を体験してください!
- AIが企業のデータ革新に与えるインパクトの最新情報
- グローバルクラスでのデータ活用と収益化の最前線
- データサイロを解消し、組織の垣根を超えたデータコラボレーションの世界の展望
- Data Cloudを活用している企業のリアルな活用事例の紹介
- 20を超えるパートナー展示!
- データドリブンを加速させるための専門家が紐解くData Cloud 活用例
- データの民主化を実現しているData Heroが集結!コミュニティMeet up!
セッション
以下レポートです
① 私たちの旅路の始まりー組織全体でデータドリブンを高めるために
データに意味を見出す能力は、データリテラシーと呼ばれています。
データドリブンを徹底し、すべての従業員がデータに基づいたビジネス上の意思決定を行えるようにしたいと考えている組織にとって、ますます重要になってきています。しかし、それは長い旅路でもあります。
データから意味のあるインサイトを抽出するために、適切なツールとスキルが必要と考えていらっしゃる方に向けて、私たちのここまでの道のりと、そしてこれからをお話しします。
セッション内容
データリテラシーの話
-
データリテラシー
- データに意味を出す能力
- データがたくさんあるからといって、自動的にビジネス価値高まらない
- データから意味のあるインサイトを抽出するために
- データがあれば、ビジネス価値が高まるわけではない
- 数値やレポートを深掘りし、解釈する
-
レポーティングとアナリティクスの違い
- レポート:問題/事象に気がつく
- アナリティクス: データを読み解き、データに基づいて意思決定をする
-
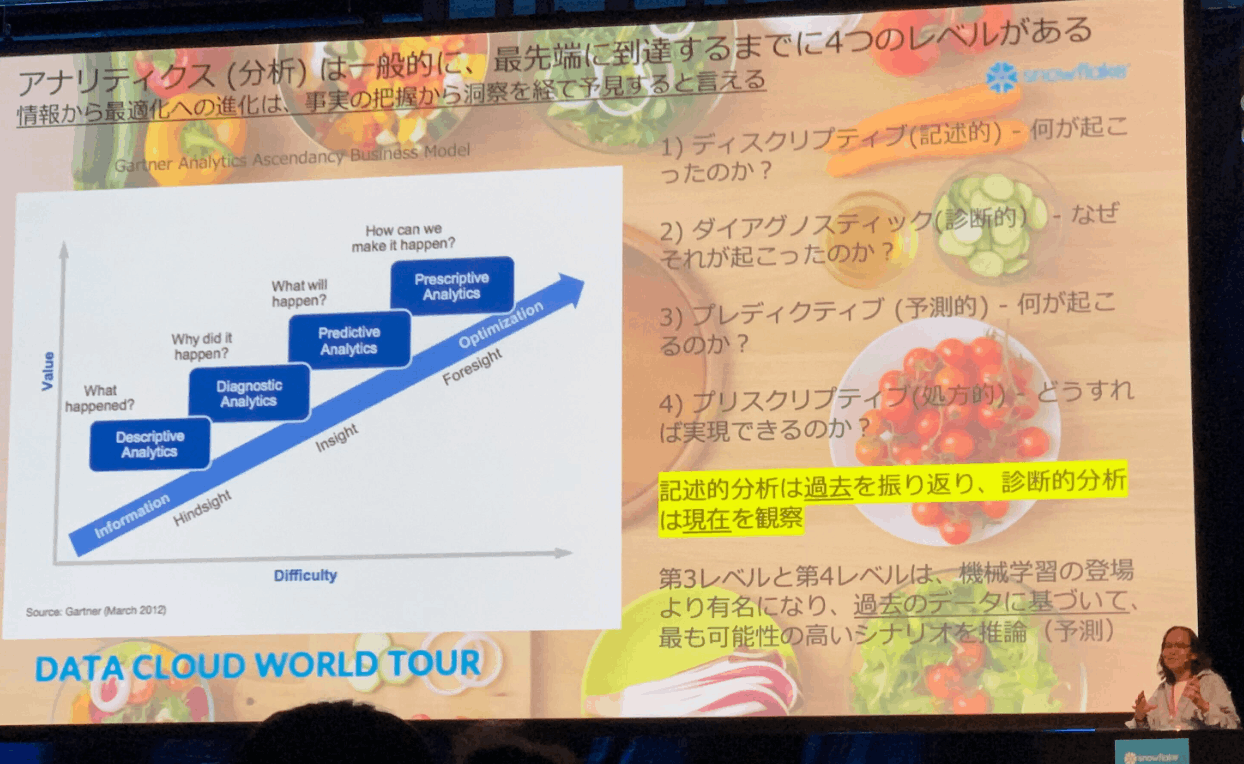
アナリティクス成熟度のモデル
- 4つのレベル
- ディスクリプティブ(記述的): なにがおこったのか?
- ダイアグノスティック(診断的): なぜおこったのか?
- プレディクティブ(予測的): 次になにが起こるのか?
- プリスクリプティブ(処方的): どうすれば実現できるか?
- 段階を追うごとに難易度が上がる
- 多くの企業が第一段階(記述的)で止まっている
- 参考資料: https://jinji-labo.com/gartner-model/
- 4つのレベル
-
なぜを問いかけることは、データ時代の重要案スキル(データリテラシー)
- 目の前の数字を理解し、深掘りし、問題の根源を理解し、ビジネスの意思決定を効率的に行うスキル
- まだまだデータリテラシーを理解している人材は少ない
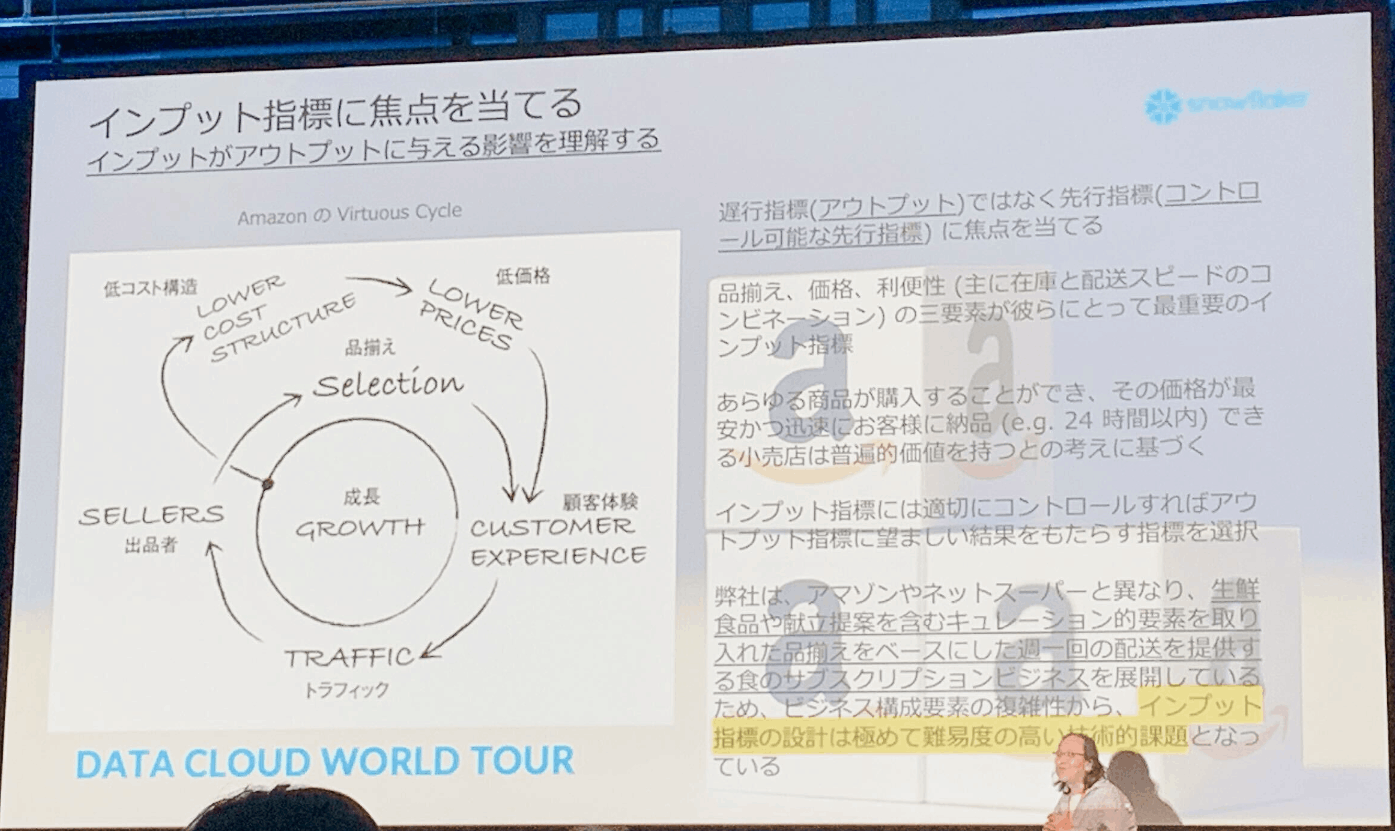
- インプット指標に焦点を当てる
- インプットがアウトプットに与える影響を理解する。
- アウトプットはコントロールできないため、インプット(先行指標)にフォーカスすることが大事。
- Amazonインプット指標
- 品揃え
- 価格
- 利便性(在庫、納品スピード)
- ビジネス複雑すぎるとインプットメトリクスを見つけるのが難しい。ただし、見つけていくことに意味がある。
- 意思決定にはアウトプットにとらわれない。アウトプットはコントロールできない。
- 参考: https://gentosha-go.com/articles/-/25501
プロジェクト立案と遂行のアプローチの話
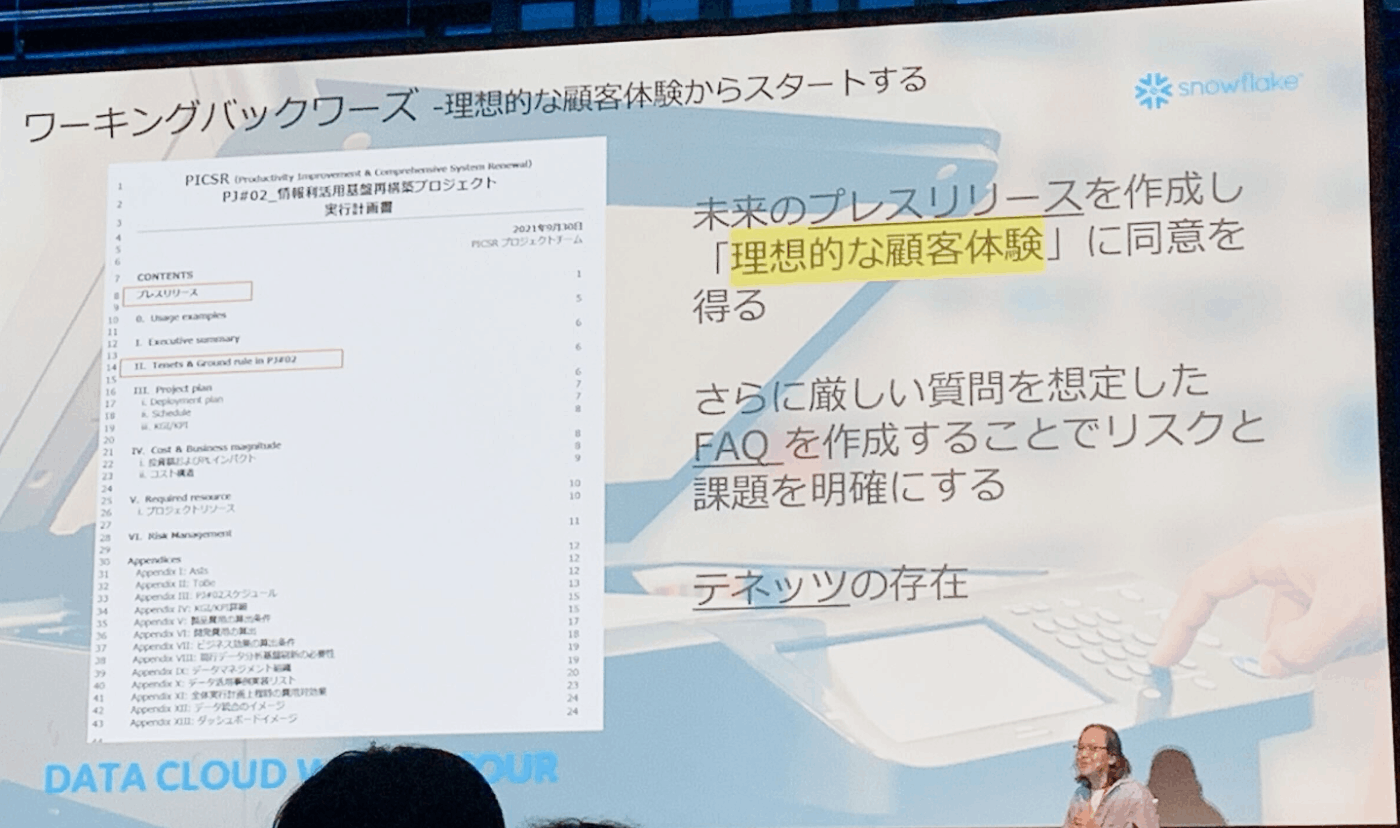
- ワーキングバックワーズ(利用的な顧客体験からスタートする)
- 未来のプレスリリースを作成し、理想的な顧客体験の同意を得る
- 厳しめのFAQを予め自分たちで想定する
- 役員や幹部もこの未来のプレスリリースを読めば理解できる
- 参考: https://cxclip.karte.io/cxstory/experience_insights/amazon-aws/

- テネッツ
- プロジェクトの信条を内外に示す
- メンバーが迷わず自立して行動できるようなルール
- 参考: https://145magazine.jp/retail/2020/01/amazon16/
技術構成

レポートとアナリティクスの用途ごとにDBを分けている使い分けている
OBT: 大福帳テーブル
- レポート: ユーザーと決めた結果指標(売上やKGI)
- アナリティクス: ユーザーが切り口を切り替えて自由分析できるように。
- コストとダッシュボードの性能がかかる
最後に
- レポートとアナリティクスは同じではない
- データリテラシーをトレーニングしないとアナリティクスはできない
- データは、4つの段階になるが
- 現在は過去のレポート(記述的)までしかできない企業が多い
- 次のなぜ(診断的)を理解できる段階までいけていない
- データリテラシが足りない
- インプットメトリクスにフォーカスする
- コントロール可能なインプットメトリクスを定義する。ビジネスモデルによってはかなり難しい。
- ワーキングバックワーズによって
- 最高の顧客体験からスタートする
コメント💬
ワーキングバックワーズという考え方は斬新で面白みを感じました。アウトプットイメージをチームだけでなく、経営層と合意するのにも有効な手段だなと思いました。
また、テネッツという言葉も今回始めて聞きましたが、データ利活用を進めていくチームメンバーが迷いなく自走できる指標として自分もあると嬉しいと思えるものでした。これはうちのチームでも考えてみよう。
ワーキングバックワーズとテネッツに関して参考になりそうなAmazonの記事があったのでこちらに
- https://cxclip.karte.io/cxstory/experience_insights/amazon-aws/
- https://145magazine.jp/retail/2020/01/amazon16/
② 最新情報:Streamlit in Snowflake
SnowflakeとStreamlitの統合に対する最新の機能とPythonを使用して迅速にアプリケーションを構築する方法をデモンストレーションを交えてご紹介します。
セッション内容
- streamlitはオープンソースのpython用UIライブラリ
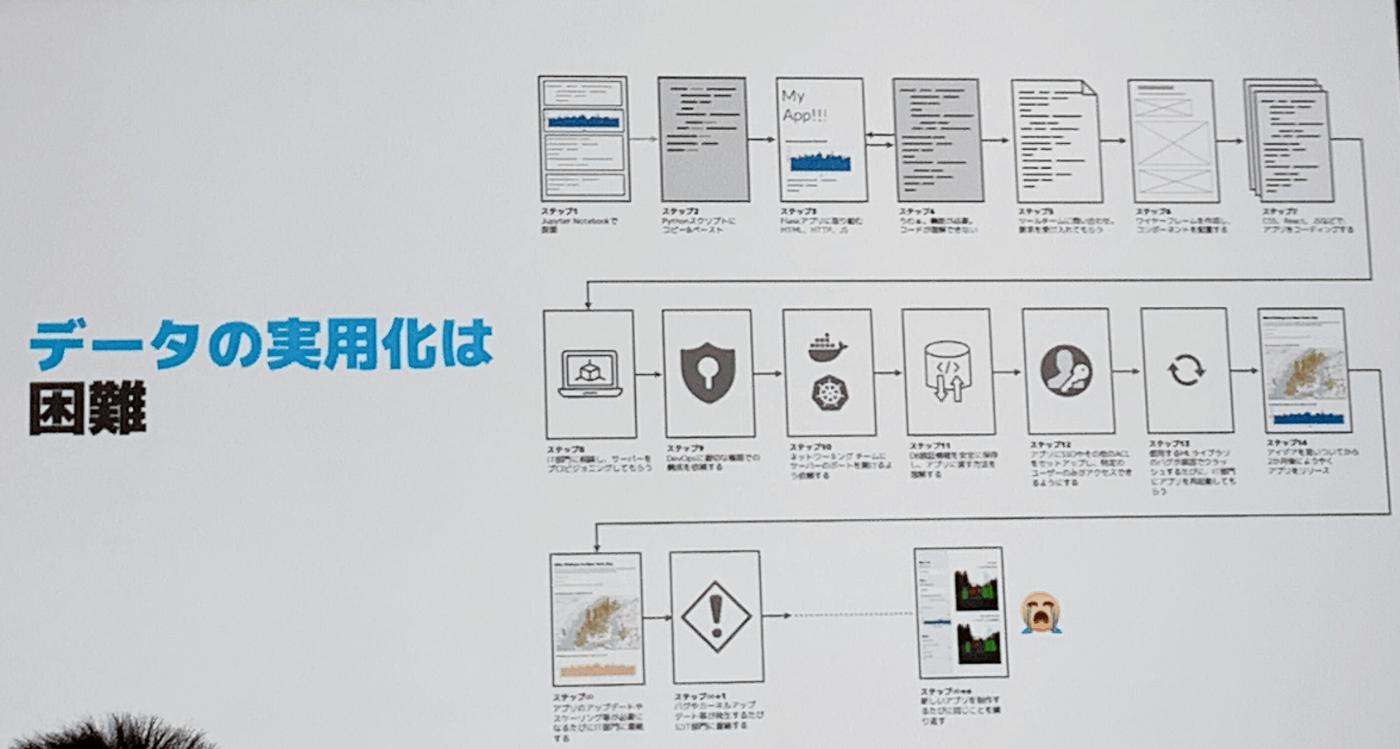
- データの実用化は困難
- データ活用まで相当なステップがある
- ビジネスチームのデータに関する疑問やアイデアについて、組織の壁や人的リソースの問題などがあり、ビジネス部門がデータの恩恵をうけれていあい場合がある

- streamlit in Snowflake
- アプリの実行環境としてSnowflake
- Streamlitの実行環境を瞬時に構築できる
- 実行環境はウェアハウス上なので、スケーリングもすぐに可能
-
エディタとプレビューを同時に閲覧することができる
-
デモ
- sreamlitの基本的な機能の紹介
- 需要予測計算のデモ
-
streamlit.ioというサイトにデモがある
-
プレイベートプレビューに参加したユーザーのデモアプリ
- NTT DATA: ウェアハウスチェックアプリ
- appfolio: 収益への影響(What-if分析)
- 某社: ジョブアラートパス(SnowflakeのCRUD操作)
- appfolio: 製造実験追跡(ワークフロー モニタリング)
-
streamlitの有効なポイント
- アプリコンポーネントがSnowflakeで稼働
- アプリは社内専用(外部配信は現時点ではできない)
- Pythonのみでアプリ開発可能
-
ロードマップ

コメント💬
待ちに待ったstreamlit in snowflakeがそろそろパブリックプレビューに!
streamlitの環境を楽に構築できるようになるのはめっちゃ嬉しい。ロードマップの中にあったsteramli LLMについては気になる。自然言語からSQLを自動で構築してくれる機能っぽい?
開発から本番デプロイまで一貫してSnowflake上でできるのは最高すぎる〜。権限管理もSnowflakeのアカウント管理に紐づいているからこれまでの権限設計踏襲できるし良き。
③ SHIONOGI データサイエンス部が取り組む仮説検証サイクルの思考と実践
塩野義製薬 データサイエンス部では、データに基づく仮説検証サイクルを如何に高速かつ高品質に回すか、に重きを置いて活動している。本講演のポイントは以下の3点であり、事例を交えて解説する
①データ駆動型ビジネスの実行には、解析結果に基づく戦略・戦術の実行状況を迅速に把握し、課題抽出・対応できる仕組みが重要である
②意思決定に必要なデータ可視化はデータ活用の初手としては有用である
③データ活用組織の専門性向上だけでなく、業務部門のデータリテラシー向上も必須である
セッション内容
SNS投稿NGとのことなので公開されているセッション概要のみ
コメント💬
個人的に刺さったのは③の文脈の話ですが、データドリブン人材強化する中で各データドリブン人材の技術レイヤーへの期待値や役割をマネージャーが理解し、できる人材に業務が偏ることが無いようにマネージャーの教育にも力を入れているという点でした。できる人に取り敢えず投げておこうみたいなのってありがちなので、組織として体系化して対処しているのはとても参考になりました。
④ Snowflake と AWS で始めるデータ活用の高度化 〜ローコードでの機械学習の導入から生成 AI の活用まで〜
デジタルトランスフォーメーション (DX) への取り組みが加速する中、機械学習や AI を活用し、ビジネス価値の創出を目指す企業や組織が増えつつあります。本セッションでは、機械学習のライフサイクルをトータルに支援する Amazon SageMaker と Snowflake を連携させ、機械学習の民主化や、生成 AI の活用を促進する方法についてご紹介します。
セッション内容
- 機械学習が価値生成するまでの道のりは長い
- ビジネス要件定義
- データ準備/特徴量エンジニアリング
- モデル開発/トレーニング
- モデルデプロイ & モニタリング
ー 数週間から数ヶ月かかるのが課題
- 機械学習を広めるには
- ①ML開発チームの拡張
- ただし、需要が高いため、採用が難しい
- ②ML開発チームの生産性向上
- ③MLイノベーションの民主化
- ②③をAWSが注力している
- ①ML開発チームの拡張
- ②③を解決するAWSソリューション sagemaker
- ノーコードMLツール
- 専用のデータ準備ツール(データモデリング準備の簡易化)
- 単一のインターフェース内のMLツール
- 組み込みMLOPs機能
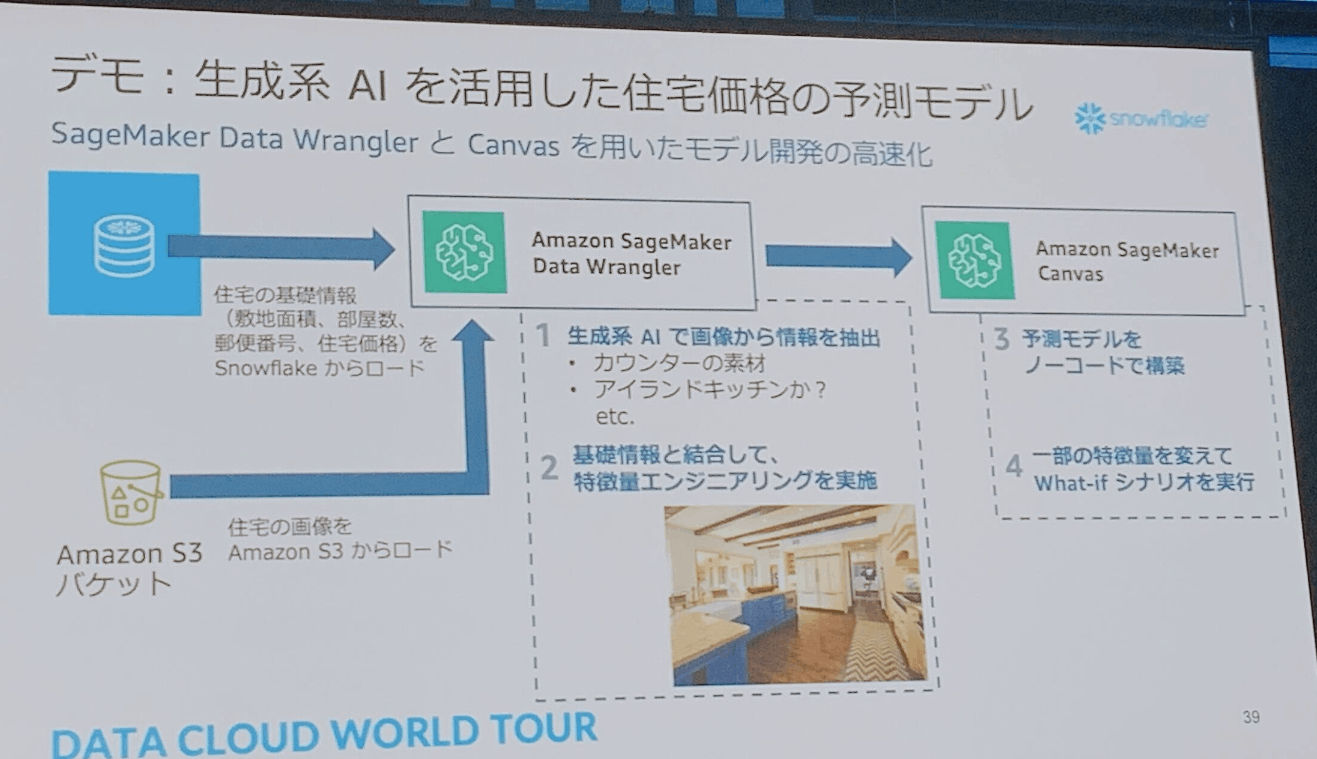
- Snowflakeのデータ連携は、Sagemaker Data Wrangler(ローコードツール)を使う
- データソースにsnowflakeのコネクターが存在している
- Oauthベースの認証をサポート
- Data WranglerからSnowflakeの外部ステージを経由しないで直接アクセスできるように最近なった
- Snowflakeで取り込んだデータにローコードで以下のようなことができる
- データ品質評価
- データバイアス検出/権限
- モデル精度の推定
- データ準備
- カスタマイズしたい場合は、pysparkを使うことが実現できる
- 取り込んでデータ準備したものをSageMaker Canpasでモデル構成
- モデル構築・評価・予測・デプロイまでローコードで実施できる
- 実施可能な分析
- 分類、回帰、時系列分析、NLP、CV
- モデルを作成したら、Canpas上でWhat-if分析が可能
- 作ったモデルを本番環境も簡単に実施できる
- 作成したモデルは、Sage Maker Model Registory
- データを準備する: Sagemaker Data Wrangler
- モデルを楽に: SageMaker Canpas

- 生成系AIのビジネス価値
- AWS生成系AIサービス
- Amazon Bedrock(プレビュー)
- 基盤モデルをサーバーレス形式で提供
- Amazon SageMaker Jumostart
- モデルが公開されていて生成系AIもふくまれている。SageMaker上で起動する。
- モデルが公開されていて生成系AIもふくまれている。SageMaker上で起動する。
- Amazon Bedrock(プレビュー)
- 生成系AIの活用デモ(住宅価格予測モデル)
コメント💬
SageMakerの動向を最近追ってなかったのですがデータ準備からモデル作成デプロイまでにローコードでできる環境が揃ってきていたのに驚きました。データ準備やモデル作成、レビュー、デプロイなどなど機械学習を進めていくことで避けれない工程って実際Pythonとかでゴリゴリ作ったり、レビュー資料作ったり、コンテナで環境作ったりと結構大変な作業になると思いますが、そこをAWS側でカバーしてくれるのはありがたいですね。機械学習に対するハードルも下がりますし、活用が進むのではと感じました。SageMakerData WranglerとCanpas触ってみよう〜。
この後も面白いセッションはあったのですが、子供のお迎えがあったのでここで後ろ髪引かれながら帰路につきました。
最後に
各企業のSnowflakeの技術的な活用部分ももちろん参考になったのですが、データをどのようにビジネスに活かしていくか、ビジネスに活かすためにどのような組織をどうやって作っていくかみたいな話はこれからデータを活用を広げていこうと思っているので実際に自社で試してみようという気持ちになりました。
データ界隈のカンファレンスには初めて参加したのですが、技術にフォーカスしたカンファレンスとは異なってビジネス的な観点で話する方が多くそういう意味でも新鮮でした。
Snowflakeを活用することでエンジニアリング部分はかなり楽になっているので、データを活用できる組織づくりやビジネスにどのように貢献していけるか考えていきたいなと思います!
楽しかった〜!

Discussion