スターフェスティバルの山崎です。
データ基盤チームとしてSnowflakeを導入してから、1年と少しが経ちました。この機会に、導入から現在までの変遷を振り返りたいと思います。どのようにSnowflakeがデータ基盤の成長を支えてきたのか、その過程をお伝えします。
Snowflakeの導入を検討している方にとって、少しでも参考になれば幸いです!
Snowflake導入のきっかけ
データ基盤チームでは、データドリブンな文化を醸成するために、データの整備や社内向けのデータ提供を進めてきました。弊社は今年で16期目を迎え、各システムも大きくなったことで様々なデータソースが存在し、そのデータ連携やクレンジングには多くの時間がかかっていました。また、データ基盤専任のメンバーがいないため、データ基盤の整備に割けるリソースが不足している状況でした。
そんな中、マーケティングチームがSnowflake社と接点を持っており、「話を聞いてみる?」という誘いがありました。そこで話を伺ったところ、インフラのメンテナンスフリーかつセキュリティ機能も充実している点、Snowparkをはじめとしたアナリティクス機能がSnowflake上で簡単に活用できる点、そして既存のBIツール(Tableau)との親和性が高い点が分かりました。これにより、今後のデータ基盤として事業と共に成長できると確信し、Snowflakeの導入を決定したのがざっくりとした導入のきっかけです。
もし、より深い話を聞きたい方がいたらコミュニティイベントなどでお話しましょう!
データ基盤のBefore/After
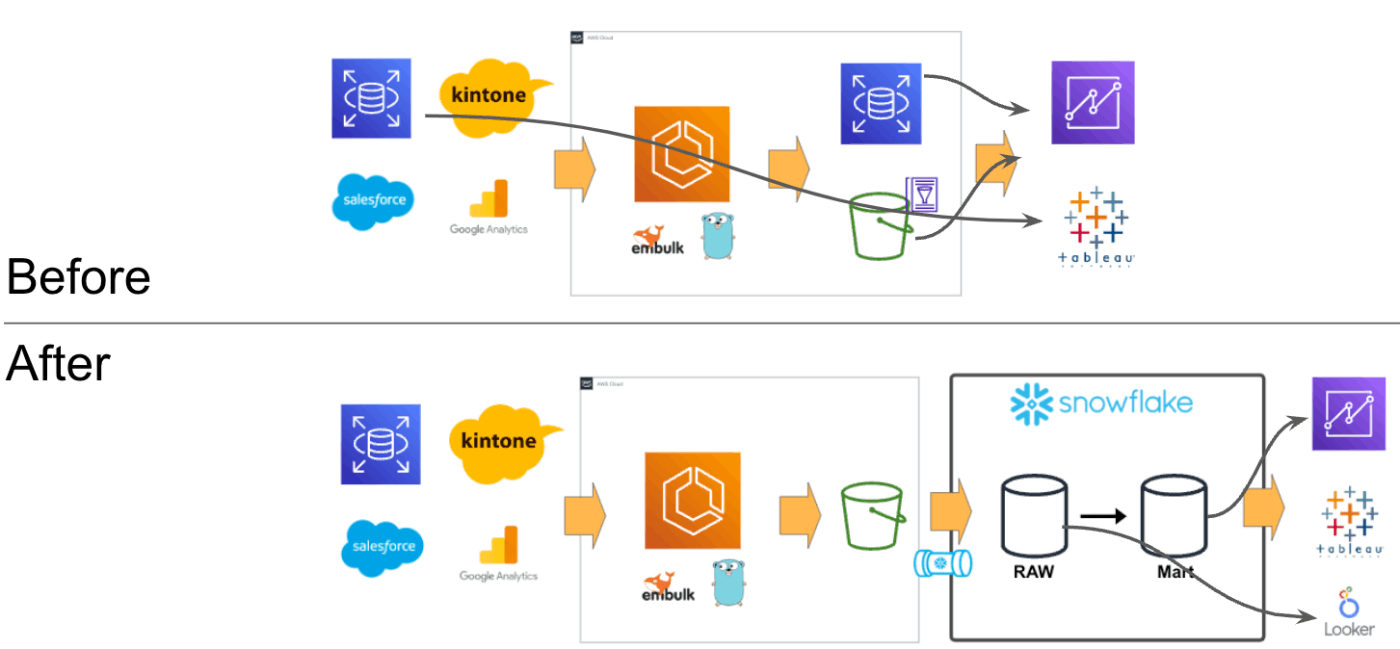
最初に、Snowflake導入前後でデータ利用者視点でどのようにデータ構成が変わったかイメージを持っていただくために、簡易的な構成図を載せます。
これまでは、データが一箇所に集約されていないため、BIツールや分析者によって参照するデータソースが異なっていたり、ローカルでデータを結合してからBIに連携する必要がありました。このような状況では、データ利用者にとって、データの活用が難しいものでした。なかなかデータ活用も進まないという状況です。
しかし、Snowflakeにデータを集約してからは、集計や分析の際にSnowflakeを見るだけで必要なデータが揃うようになり、チーム間で異なるデータを参照する問題が解消されつつあります。また、Snowflakeにアクセスすれば基本的に必要なデータが揃っているため、分析を実施したい方にとってのハードルも下がり、データ活用がよりスムーズに進むようになりました。
データ基盤の変遷
振り返ってみるといくつかのフェーズがあったと感じています。それぞれのフェーズは、おおよそ3ヶ月程度の期間で進行しました。これから、その4つのフェーズについて説明します。
①データ基盤構築
②データの取り込み拡大
③アプリチームとの協業
④経営との協業
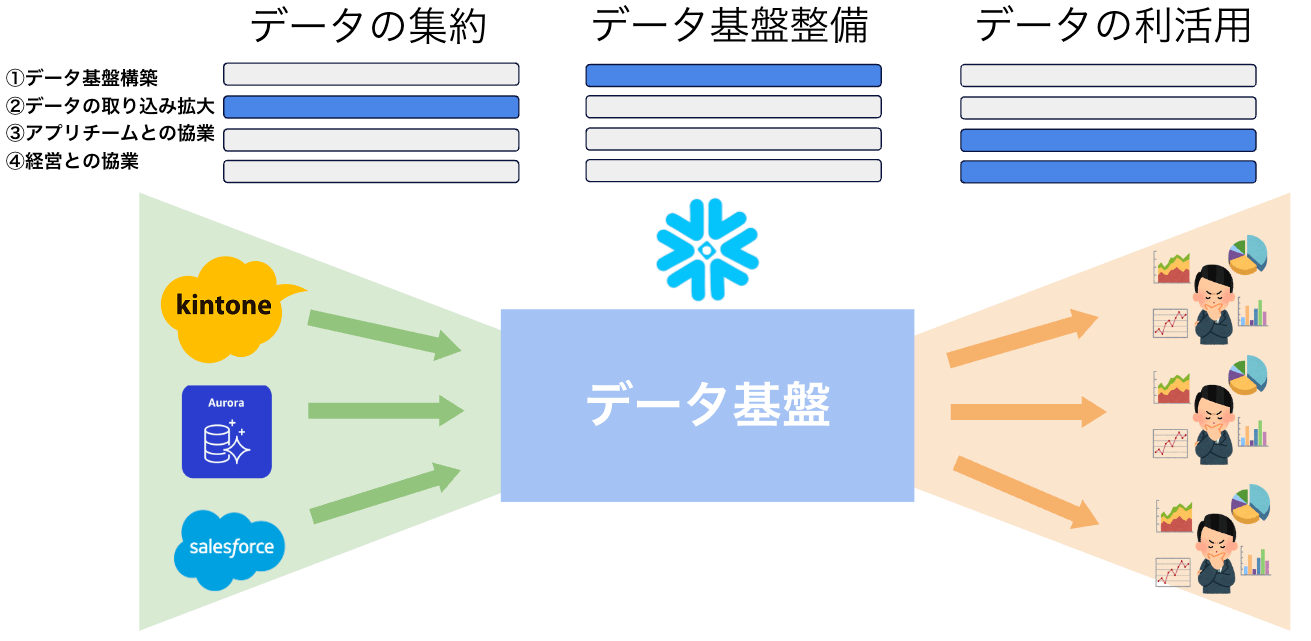
データの集約/データ基盤整備/データの利活用の3つを大きな区分と考えて、各ステップで注力した部分の色を濃くしています。
(リボン型のこの図はゆずたそさんの資料を参考にさせていただきました。)
①データ基盤構築
導入当初は、Snowflakeのナレッジが社内にないため、ひたすらドキュメントを読み込んだり、手を動かして試行錯誤を繰り返していました。特に参考になったのは、クラスメソッドさんのSnowflakeの記事 や 公式ドキュメントのチュートリアルでした。
ある程度のナレッジが蓄積された段階で、以下の項目の設計を行い、GA4のデータを取り込み、一部のアプリチームに実際に使用してもらうことで、Snowflakeの歴史が始まりました。
- データベース/スキーマ設計
- 共通DBの各スキーマ詳細
- ウェアハウス(WH)設計
- ロール設計
- 各プロジェクトのロール 階層詳細
- データ連携設計
- 命名規則
その頃にSnowflakeのユーザー会のイベントがあることがわかったので、とりあえずLTをやってきました。コミュニティ自体がすごいWelcomeな雰囲気があり、導入の相談や各社の利用状況などが聞けて、最初に行っておいてよかったなという気持ちがあります。
■ 登壇資料
②データ取り込み拡大
これまでのレポートの作成や各チームで実施していた分析をSnowflake上のデータで行えるように、各アプリのデータベースやSalesforce、kintoneからデータをRAW層にひたすら取り込む作業を進めました。連携元が100以上に及んだため、少ないデータ基盤チームメンバーだけでこの作業を進めるのは非常に困難な状況で、データ基盤チームがボトルネックになるという状況でした。そこで、データ連携の作業手順をドキュメント化し、アプリチームのメンバーにも自分たちでパイプラインを構築してもらうように協力をお願いしました。(協力してくれるアプリチームの皆さんに感謝...!
これにより、スピードを落とさずにデータの利用を進められる体制を整えることができました。
■ この頃にイベントでその時の課題などを発表したスライド
③アプリチームとの協業
データがある程度集まってきたタイミングで、アプリケーションへの反映を進め始めました。アプリチームとテーマを決めてそこに向けて役割分担して機能開発を行いました。
開発テーマですが、delyさんのパーソナライズされたフィード をSnowflakeのデータからリバースETLをして構築されているのが印象に残っており、ちょうどアプリチームの方でもレコメンドというキーワードがでていたので商品レコメンドを一緒にやることになりました。
レコメンドに必要な購買情報やWebの行動情報はすでにSnowflakeに集約されていたため、リバースETLを実行するだけで必要なデータを簡単に準備できました。Amazon Personalizeを使ったモデル作成と推論もスムーズに進み、あとはパラメータチューニングとアプリケーション側の開発を協力して進めました。そして、2024年4月にSnowflakeのデータを活用したレコメンド機能を無事にリリースすることができました🎉
■ このころにFindyにSnowflake導入事例として寄稿した
④経営との協業
商品レコメンド機能のリリースが無事に終わった後、経営メンバーやアプリのリーダーと共に次期予算の策定に参加させてもらいました。Snowflakeに各アプリケーションのデータが集約されたことで、ユーザーベースでより深く数値を分解できるようになり、各チームの数値目標を明確化することができました。
また、数値分解を行う際には、一緒にロジックツリーを作成したり、数値の解釈を行ったり、データの提供などを行っていました。この活動を通じて、より精緻な予算を作成できただけでなく、これまで関わりの少なかった経営層やアプリチームとのつながりも築くことができました。データドリブンなアプローチを進める上で非常に有意義な活動だったと感じています。
直近の活動になりますが、Looker StudioとSnowflakeを連携させ、今回作成した数値や予算の進捗を全社員がいつでも確認できるようなダッシュボードを構築しました。これまで一部の人しかリアルタイムで状況を把握できなかった状態から、誰でも最新の予算や進捗を確認できる環境に移行し、全社のデータに対する感度を高める取り組みを進めました。
さいごに
ここまで、導入から現在までのSnowflakeの状況について読んでいただきまして、ありがとうございます。
今後の活動についてですが、各チームがSnowflakeのデータにアクセスする機会やユースケースが増えたことで、マート層のテーブル数が増加し、大規模な結合が必要な状況になってきているので、見えてきた分析や利用ユースケースを再整理し、データモデリングを進めていきたいと考えています。また、まだdbtなどのモダンデータスタックを十分に活用できていない部分もあるため、今後の活動を効率化するために、この辺りのキャッチアップも進めていく予定です。
Snowflakeの活用状況については、データモデリングが完了した後に、またブログでご報告しようと思います。

Discussion