はじめに
こんにちは、スターフェスティバルの山崎です。アドベントカレンダーの11日目の記事を担当させていただきます。
最近の空き時間を活用して、生成AIを使ったSlackチャットボット「おりひめ」を作りました。この記事では、開発の背景からアーキテクチャ、実装時のハマりポイントまでを書いて行こうと思います。
AWSサービスで完結する構成にしているので、AWS環境でチャットボットの構築を検討されている方の参考になれば幸いです。
めちゃくちゃ余談ですが、「おりひめ」という名前は、弊社名のスターフェスティバル(七夕)から連想される言葉の中から、個人的に一番親しみやすい表現として選びました。ひらがな表記にしたのも、柔らかな印象があるなぁと。
なぜチャットボットを作ったのか
生成AIの活用については、単にエンジニアだけでなく、将来のことを考えると組織全体で取り組むべき重要なテーマだと考えています。
-
まずは組織全体の生成AIの利用に慣れる
- エンジニアに限らず、様々な部署の方が気軽に生成AIを気軽に体験できるようにする
- とりあえず生成AIに触ってもらって、生成AIを利用する感覚を養ってもらう
-
将来的にはビジネス課題や業務課題解決のための手段として生成AIも入るように
- 各部署が業務的な課題の解決策を模索する際に、生成AIでの解決というのも選択肢の一つとして入れれるようにする
今後どんどん生成AIの分野の進化は加速していくと考えており、組織としてそのメリットを享受する土壌を育てるための手段として、「おりひめ」が担っていけたらいいなと考えていました。
おりひめの主な機能
そこまで高度の機能は作ってないです。学習済みモデルのClaude 3 Haikuでの回答をベースとして、そのインプット周りで社内のコンフルやWEBページ情報の取得や音声の文字起こし情報を利用できるようにしています。
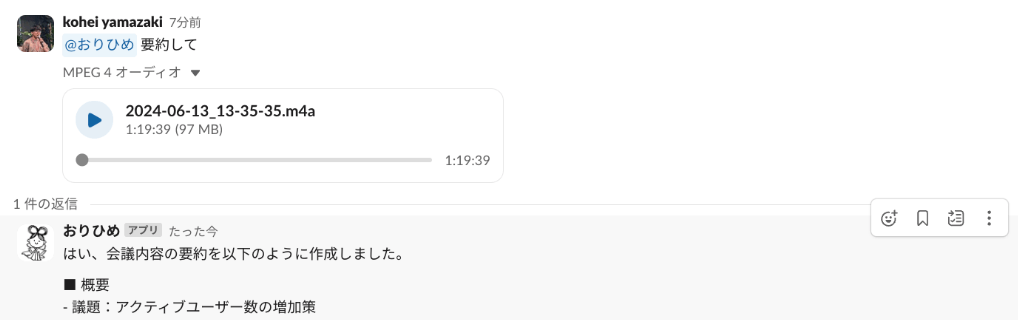
個人的には音声の文字起こしは結構使える機能で、会議録音しておいて、おりひめにslack上で渡せば議事録としてまとめてくれるので助かっていたりします。
1. 基本的なLLM機能(Claude 3 Haiku活用)
- テキスト要約
- アイデア出し
- 質問応答
- slackのスレッド情報
2. 外部情報の参照機能
- 一般的なWebページのURL解析と内容理解
- 社内Confluenceページの内容参照(URLベース)
3. 音声データ処理
- 添付された音声ファイルの自動文字起こし
- 文字起こし内容を基にした回答生成
利用例
その1(スレッド要約)

その2(WEBページ情報取得)

その3(文字起こし)
システムアーキテクチャ

主要なコンポーネントの役割
-
Lambda(応答)
- Slackからのリクエスト受付
- SQSへのメッセージキューイング
- 即時レスポンス返却(3秒ルール対応)
-
SQS
- メッセージのバッファリング
- 処理の非同期化
-
Lambda(処理)
- スレッド内容の解析とプロンプト生成
- 外部URLのクローリング(Beautiful Soup使用)
- 音声データの文字起こし(Amazon Transcribe利用)
- Bedrockを用いたLLM処理
- ガードレール機能による不適切な出力のブロック
実装時のハマりポイント
1. Slackのタイムアウト対策
- 問題: Slackは3秒以内のレスポンスしないとタイムアウトでリトライする
-
解決策: 3秒以内に応答だけしておいて、処理は別途行う。応答と処理のLambdaを分けている理由がこれ。
- 参考: Serverworks技術ブログ
2. Slack APIの重複実行への対応
- 問題: 3秒以内にレスポンスしても複数回実行される場合がある気がする
-
解決策: X-Slack-Retry-Numヘッダーによるリトライ制御。とりあえず、リトライされた呼び出しは応答しないようにロジック組んでおく。
- 参考: Qiita記事
改善ポイント
音声処理の最適化
- 現状: Lambdaでポーリング処理
- 改善案: Step Functionsを使用した待機処理の実装
文字起こしが長い音声データだと時間がかかってLambdaの実行時間が伸びてしまうので、処理の終了チェックはStepFunctionsとLambdaでやるのが効率的かなと思います。
LLMへのプロンプトのガードレールの強化
- 現状: Bedrock ガードレール
- 改善案: Bedrock ガードレール + 個別の除外ロジック or プロンプトを英訳する
Bedrock ガードレール良い機能ではあるのですが、日本語だとまだ改善の余地ありって感じです。例えば名前をマスクする設定にしても、日本語だと中々マスクしてくれなかったりするので、性能を出すなら英訳する もしくは、Lambda側の個別ロジックとして個人情報はLLMにインプットしたくないデータを除外する処理が必要だとと思います。
社内展開時の注意点
一応個人的に始めたものではあるのですが、セキュリティ的なリスクもあるのでCTOや情報セキュリティの意思決定をされる方とは認識合わせしておくの大事。
うちの場合だと、少し前にCTOと生成AI利用ガイドラインの合意をしていたので、それを基にチャットボットの利用ガイドラインを作って公開するようにしました。
- 生成AI利用ガイドライン
- チャットボット(おりひめ)利用ガイドライン
生成AI利用ガイドラインの作成にあたっては、日本ディープラーニング協会の資料を参考にして、社内の状況に合わせて作りました。
今後の展開
機能面では、密かに検証しているのですがRAGを追加しようと思っています。Amazon Aurora PostgreSQLを使うことで結構安価にRAG機能提供できることがわかったので、必要なデータ揃えてBedrockに組み込みます。re:InventでAmazon Novaというマルチモーダルなモデルも出たのでつかって行けたらいいなと思っています..!可能性は無限大!
全社的に生成AIに慣れてもらうためにおりひめを作ったんだ!みたいなことを最初に書きましたが、一部の方にこそっと教えて使ってもらっているのが現状なので、本格的に全社的に利用してもらえるようにユースケースや社内啓蒙活動をやっていきたいなと思っております...!
以上です。読んでいただいてありがとうございます!

Discussion