速攻レビュー!Google の新フレームワーク ADK で書類分類・データ抽出エージェントを作ってみた
はじめに
こんにちは!最近、Google から新しい AI エージェントフレームワーク「Agent Development Kit (ADK)」がリリースされたのをご存知でしょうか? AI エージェント開発の分野は日々進化しており、Google がどのようなアプローチを取るのか、個人的にとても注目していました。
ADK は、Gemini モデル(もちろんマルチモデルでも可!)との緊密な連携を特徴とし、シンプルなエージェントから複雑なマルチエージェントシステムまで、柔軟に構築できることを目指しているようです。
「これは試してみるしかない!」と思い立ち、早速 ADK を使って、画像の内容に応じて自動で分類・情報抽出を行うエージェント のプロトタイプを作成してみました。
この記事では、
- Google ADK の簡単な紹介
- 実際に画像分類・抽出エージェントを作ってみた手順
- ADK を使ってみたリアルな感想(手軽さ、機能面での発見)
- 開発中に遭遇したちょっと困った課題(再現性について)
などを、触ってみたばかりの ファーストインプレッション として共有します。
ADK に興味がある方、AI エージェント開発をこれから始めたいと考えている方の参考になれば幸いです!
Google ADK とは?
Agent Development Kit (ADK) は、Google が提供するオープンソースの AI エージェント開発フレームワークです。公式ドキュメントによると、「AI エージェントの構築、管理、評価、デプロイをシームレスに行う」ことを目的として設計されています。
シンプルなエージェントから、複数のエージェントが連携する複雑なシステムまで、柔軟に開発できるのが特徴のようです。
ADK が提供する主な機能やコンセプトの中から、特に重要だと思われるものをいくつかピックアップしてみます。
- マルチエージェントシステム設計 (Multi-Agent System Design): 専門的なタスクを持つ複数のエージェントを階層的に組み合わせて、アプリケーションを構築できます。エージェント同士が連携し、タスクを分担することで、より複雑な処理を実現します。今回の実装では、まさにこのマルチエージェントの考え方を利用しました。
-
豊富なツールエコシステム (Rich Tool Ecosystem): エージェントに様々な能力(ツール)を与えることができます。自分で作成した関数 (
FunctionTool) や、他のエージェント自体をツール (AgentTool) として利用したり、Google 検索やデータベース連携などの外部 API と連携したりできます。 -
柔軟なオーケストレーション (Flexible Orchestration): 事前に定義されたワークフロー(逐次実行
SequentialAgent、並列実行ParallelAgentなど)と、LLM による動的な処理(指示に基づいたエージェントの切り替えなど)を組み合わせて、エージェントの実行フローを制御できます。 - 統合された開発ツール: ローカルでの開発とイテレーションを容易にするための CLI や Developer UI が提供されており、エージェントの実行、デバッグ、状態の確認などが可能です。
その他にも、ストリーミング対応、評価機能、状態管理、アーティファクト管理など、エージェント開発に必要な様々な機能が提供されています。
今回はこれらの機能のうち、特にマルチエージェントシステム設計 の手軽さを体験することになりました。次のセクションでは、実際にどのようにエージェントを構築したかを見ていきましょう。
画像分類・抽出エージェントを作ってみる
ADK の概要を掴んだところで、早速エージェントを作成してみましょう。
目的
今回目指したのは、ユーザーから 画像 と 指示 (クエリ) を受け取り、その指示に応じて以下のいずれかのアクションを実行するエージェントです。
- 分類: 画像が何の書類か (請求書、見積書など) を判断する。
- 抽出: 画像内の情報 (請求番号、合計金額、日付など) を抜き出す。
- 分類と抽出: 上記の両方を行う。
例えば、「この書類は何?データも抽出して」といった指示に対応できることを目指します。
エージェント構成:役割分担で処理を分ける
この目的を達成するために、ADK のマルチエージェントシステムの考え方を採用し、以下のような役割分担を持つ3つのエージェントを定義しました。
-
root_agent(ルートエージェント):- ユーザーからの指示 (クエリ) と画像を最初に受け取る。
- 指示内容を解釈し、「分類」が必要か、「抽出」が必要か、あるいは「両方」が必要かを判断する。
- 判断結果に基づき、適切なサブエージェントを呼び出す。
- 最終的な応答をユーザーに返す。
-
document_classifier(サブエージェント):-
root_agentから呼び出される。 - 入力された画像が何の種類のドキュメントかを分類することに特化。
- 例:「請求書」「見積書」「メモ」など。
-
-
data_extractor(サブエージェント):-
root_agentから呼び出される。 - 入力された画像から具体的なデータを抽出することに特化。
- 例:「請求番号」「合計金額」「日付」など。
-
このように、全体を管理するエージェント (root_agent) と、特定のタスクに特化したエージェント (document_classifier, data_extractor) を組み合わせることで、複雑な要求にも対応しやすく、かつ各エージェントの役割が明確になることを期待しました。
実装のポイント
実際のコードから、ADK の特徴が表れている部分をいくつか見てみましょう。
1. ルートエージェントとサブエージェントの定義 (agents/root_agent.py)
root_agent の定義時に、sub_agents パラメータに使用するサブエージェントのインスタンスをリストで渡すだけで、階層構造を表現できます。
# agents/root_agent.py
from google.adk.agents import Agent
from agents.sub_agents import create_classifier, create_extractor
import logging
logging.basicConfig(level=logging.ERROR)
def create_root_agent(callback=None):
root_agent = Agent(
name="root_agent",
description="A root agent that uses the classifier and extractor agents to classify the type of document input and extract the data from the document input.",
# ↓ 指示内容に応じてサブエージェントを呼び出すように指示
instruction="You are a document worker agent. Please call the appropriate agent based on the input instructions and images to complete the task.",
model="gemini-2.0-flash", # LLMモデルを指定
tools=[], # 今回は外部ツールは未使用
generate_content_config=types.GenerateContentConfig(
temperature=0.0, # 再現性を期待して 0.0 に
# seed=18, # seed も試したが効果は見られず...
),
# ↓ ここでサブエージェントを指定
sub_agents=[create_classifier(callback), create_extractor(callback)],
before_model_callback=callback,
)
return root_agent
root_agent の instruction で「指示に応じて適切なエージェントを呼び出すように」と指示することで、LLM が文脈を判断して document_classifier や data_extractor を使い分けてくれることを期待します。
2. サブエージェントの定義 (agents/sub_agents/classifier.py, agents/sub_agents/extractor.py)
サブエージェントも Agent クラスで定義します。それぞれの役割に特化した instruction を設定します。
# agents/sub_agents/classifier.py (抜粋)
def create_classifier(callback=None):
classifier = Agent(
name="document_classifier",
description="A document classifier agent that classifies the type of document input. For example, invoices, quotations, surveys, memos, etc.",
# ↓ 分類タスクに特化した指示
instruction="You are a document classifier agent that classifies the type of document input. For example, invoices, quotations, surveys, memos, etc.",
model="gemini-2.0-flash",
# ... (省略) ...
)
return classifier
# agents/sub_agents/extractor.py (抜粋)
def create_extractor(callback=None):
extractor = Agent(
name="data_extractor",
description="A data extractor agent that extracts data from the document input. For example, the invoice number, the total amount, the date, etc.",
# ↓ 抽出タスクに特化した指示
instruction="You are a data extractor agent that extracts data from the document input. For example, the invoice number, the total amount, the date, etc.",
model="gemini-2.0-flash",
# ... (省略) ...
)
return extractor
このように、各エージェントに明確な役割と指示を与えることで、システム全体の挙動を制御しようと試みました。
3. エージェントの実行 (main.py)
エージェントを実行するには Runner を使用します。Runner に root_agent を渡し、ユーザーからの入力 (テキストクエリと画像データ) を Content オブジェクトとして渡して run_async を呼び出します。
# main.py (抜粋)
import asyncio
from google.adk.runners import Runner
from google.genai import types # Content作成用
from google.adk.sessions import InMemorySessionService # セッション管理
from PIL import Image
from io import BytesIO
from agents import create_root_agent
async def call_agent_async(query: str, image_bytes: bytes, runner: Runner, user_id: str, session_id: str):
# テキストと画像を Part として Content を作成
content = types.UserContent(
parts=[
types.Part.from_text(text=query),
types.Part.from_bytes(data=image_bytes, mime_type="image/jpeg")
]
)
final_response_text = "default response"
# run_async でエージェントを実行し、イベントを非同期に処理
async for event in runner.run_async(user_id=user_id, session_id=session_id, new_message=content):
if event.is_final_response(): # 最終応答イベントかチェック
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
# ... (エラーハンドリングなど省略) ...
break
return final_response_text
async def main():
session_service = InMemorySessionService() # インメモリのセッションサービス
# ... (セッション作成処理) ...
runner = Runner(
agent=create_root_agent(callback), # ルートエージェントを指定
app_name=APP_NAME,
session_service=session_service
)
# 画像読み込み
image = Image.open("data/test.jpg")
img_byte_arr = BytesIO()
image.save(img_byte_arr, format='JPEG')
img_byte_arr = img_byte_arr.getvalue()
# テスト実行 (分類、抽出、分類と抽出)
queries = [
"これは何の書類ですか?",
"この書類のデータを抽出してください。",
"これは何の書類ですか? そして、そのデータを抽出してください。",
]
for i, query in enumerate(queries):
print(f"--- テスト{i+1} ---")
response = await call_agent_async(query, img_byte_arr, runner, USER_ID, SESSION_ID)
print(f"response{i+1}: {response}")
if __name__ == "__main__":
asyncio.run(main())
Runner がエージェントの実行ループや状態管理などを担当してくれるため、アプリケーション側は比較的シンプルに入出力の処理に集中できます。
4. コールバックによる動作観察 (callback.py)
ADK では、モデル呼び出しの前後などに独自の処理を挟むことができるコールバック機能があります。今回は、どのエージェントのモデルが呼び出され、どのようなプロンプトが生成されているかを確認するために、簡単なログ出力を行うコールバックを設定しました。
# callback.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
# ...
def callback(
callback_context: CallbackContext, llm_request: LlmRequest
) -> Optional[LlmResponse]:
agent_name = callback_context.agent_name # エージェント名を取得
print(f"--- Callback: running for agent: {agent_name}")
# LLMへのリクエスト内容 (プロンプト) を表示
print(f"--- Callback: llm_request: {[(content.parts[0].text, content.role) for content in llm_request.contents]}")
return None # ここでレスポンスを加工することも可能
これにより、root_agent が期待通りにサブエージェントを呼び出そうとしているかなどをデバッグ時に確認できました。
動作確認
それでは動作確認してみましょう!
以下の画像に対して、テスト1「これは何の書類ですか?」、テスト2「この書類のデータを抽出してください。」、テスト3「"これは何の書類ですか? そして、そのデータを抽出してください。"」を行います。
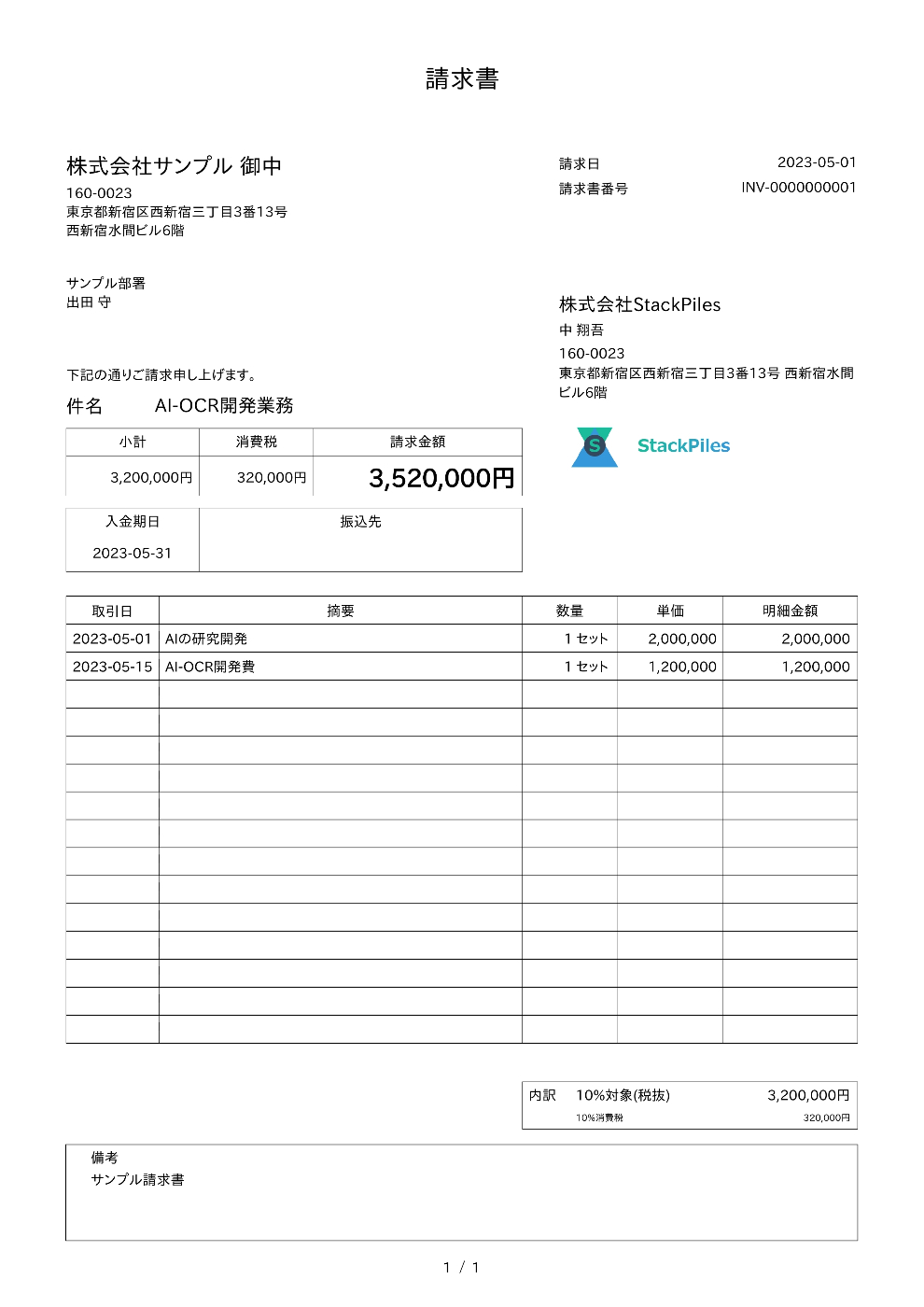
main.py を実行すると、用意したテスト画像 (data/test.jpg) と各クエリに対して、エージェントが応答を返します。期待通りであれば、
- 「これは何の書類ですか?」→ 分類結果 (例: 「これは請求書です。」)
- 「この書類のデータを抽出してください。」→ 抽出結果 (例: 「請求番号: INV001、合計金額: ¥10,000、...」)
- 「これは何の書類ですか? そして、そのデータを抽出してください。」→ 分類と抽出の両方の結果
が返ってくるはずです。
--- テスト1 分類 ---
--- Callback: running for agent: root_agent
--- Callback: llm_request: [('これは何の書類ですか?', 'user')]
response1: これは請求書です。
--- テスト2 抽出 ---
--- Callback: running for agent: root_agent
--- Callback: llm_request: [('これは何の書類ですか?', 'user'), ('これは請求書です。\n', 'model'), ('この書類のデータを抽出してください。', 'user')]
--- Callback: running for agent: data_extractor
--- Callback: llm_request: [('これは何の書類ですか?', 'user'), ('For context:', 'user'), ('この書類のデータを抽出してください。', 'user'), ('For context:', 'user'), ('For context:', 'user')]
response2: OK. I will extract the data from the document.
Here's the extracted data:
* **請求日(Invoice Date):** 2023-05-01
* **請求書番号(Invoice Number):** INV-000000001
* **合計金額(Total Amount):** 3,520,000円
* **入金期日(Due Date):** 2023-05-31
* **件名(Subject):** AI-OCR開発業務
* **会社名(Company Name):** 株式会社StackPiles
--- テスト3 分類と抽出 ---
--- Callback: running for agent: data_extractor
--- Callback: llm_request: [('これは何の書類ですか?', 'user'), ('For context:', 'user'), ('この書類のデータを抽出してください。', 'user'), ('For context:', 'user'), ('For context:', 'user'), ("OK. I will extract the data from the document.\n\nHere's the extracted data:\n\n* **請求日(Invoice Date):** 2023-05-01\n* **請求書番号(Invoice Number):** INV-000000001\n* **合計金額(Total Amount):** 3,520,000円\n* **入金期日(Due Date):** 2023-05-31\n* **件名(Subject):** AI-OCR開発業務\n* ** 会社名(Company Name):** 株式会社StackPiles\n", 'model'), ('これは何の書類ですか? そして、そのデータを抽出してください。', 'user')]
--- Callback: running for agent: root_agent
--- Callback: llm_request: [('これは何の書類ですか?', 'user'), ('これは請求書です。\n', 'model'), ('この書類のデータを抽出してください。', 'user'), (None, 'model'), (None, 'user'), ('For context:', 'user'), ('これは何の書類ですか? そして、そのデータを抽出してください。', 'user'), ('For context:', 'user'), ('For context:', 'user')]
--- Callback: running for agent: root_agent
--- Callback: llm_request: [('これは何の書類ですか?', 'user'), ('これは請求書です。\n', 'model'), ('この書類のデータを抽出してください。', 'user'), (None, 'model'), (None, 'user'), ('For context:', 'user'), ('これは何の書類ですか? そして、そのデータを抽出してください。', 'user'), ('For context:', 'user'), ('For context:', 'user'), (None, 'model'), (None, 'user')]
response3: これは請求書です。
* **請求日(Invoice Date):** 2023-05-01
* **請求書番号(Invoice Number):** INV-000000001
* **合計金額(Total Amount):** 3,520,000円
* **入金期日(Due Date):** 2023-05-31
* **件名(Subject):** AI-OCR開発業務
* **会社名(Company Name):** 株式会社StackPiles
連続でテストしているため会話セッションを切断せずにタスクが実行されているのが分かります。つまり過去に会話した内容から参照して回答してくれます。
このように、ADK の基本的な機能を使うことで、比較的少ないコードでマルチエージェント構成のアプリケーションの骨組みを作ることができました。次のセクションでは、実際に使ってみて感じた Good Point をまとめてみます。
👍ADK を使ってみた感想(Good Point)
今回、ADK を使って簡単なマルチエージェントシステムを構築してみて、いくつかの良い点を感じました。
1. マルチエージェント構成の手軽さ
最も印象的だったのは、マルチエージェントの構成を手軽に実現できる点です。
前述の agents/root_agent.py のコードのように、Agent クラスの sub_agents パラメータに他のエージェントのインスタンスをリストで渡すだけで、基本的な階層構造を定義できました。
# 再掲: agents/root_agent.py 抜粋
def create_root_agent(callback=None):
root_agent = Agent(
# ... (省略) ...
# サブエージェントを指定するだけで連携の準備ができる
sub_agents=[create_classifier(callback), create_extractor(callback)],
# ... (省略) ...
)
return root_agent
root_agent の instruction に「適切なエージェントを呼び出して」と自然言語で指示するだけで、LLM が文脈を判断してサブエージェントを呼び出す、という基本的な連携フローが実現できるのは非常に直感的だと感じました。他のフレームワークではもう少し定型的なコードが必要になるケースもあるため、このシンプルさは ADK の魅力の一つだと思います。
2. AI エージェントに必要な基本機能の充実
ADK は、AI エージェントを開発する上で必要となる基本的な要素をフレームワークレベルで提供してくれていると感じました。
-
LLM との連携:
Agentクラスでmodelを指定するだけで、Gemini のような LLM を簡単に利用開始できます。 -
実行管理 (
Runner): エージェントの実行ループやイベント処理、セッション管理 (SessionService) との連携などをRunnerが担当してくれるため、開発者はエージェントのロジックやアプリケーション固有の処理に集中しやすいです。 -
デバッグ支援 (
Callback): コールバック機能を使うことで、エージェント内部の動作(どのモデルが呼ばれたか、どんなプロンプトが生成されたかなど)を確認しやすく、デバッグの助けになりました。
今回は試していませんが、公式ドキュメントを見る限り、ツール連携 (Tool)、より複雑なワークフロー制御 (SequentialAgent, ParallelAgent)、評価機能なども用意されており、エージェント開発のエコシステム全体をサポートしようとしている意欲を感じます。
3. チュートリアルやドキュメント
公式のチュートリアルがシンプルで分かりやすく、最初のとっかかりとして非常に役立ちました。
全体として、ADK は AI エージェント開発、特にマルチエージェントシステムの構築を迅速かつ直感的に始めるための良い基盤を提供してくれるフレームワークだと感じました。
しかし、手軽さの一方で、少し「おや?」と思った点もありました。次のセクションでは、開発中に遭遇した課題について触れたいと思います。
🤔 ADK の課題? 再現性問題との遭遇
ADK の手軽さや機能性に好印象を持った一方で、今回の試作を通じて少し気になる点にも遭遇しました。それは、LLM の応答の再現性についてです。
同じ入力でも結果が変わる?
AI エージェント、特に LLM を利用するシステムでは、応答にある程度の「ゆらぎ」があることは一般的です。しかし、デバッグやテスト、あるいは本番環境での安定した動作のためには、可能な限り挙動を固定したい場面もあります。
そこで、Agent の定義時に generate_content_config で temperature=0.0 を指定し、応答のランダム性を最小限に抑えようと試みました。
# 再掲: agents/root_agent.py 抜粋
def create_root_agent(callback=None):
root_agent = Agent(
# ... (省略) ...
generate_content_config=types.GenerateContentConfig(
temperature=0.0, # 応答の多様性を抑制
# seed=18, # seed も試したが効果は見られず...
),
# ... (省略) ...
)
return root_agent
temperature=0.0 は、モデルが最も確率の高い単語を選択しやすくなる設定で、一般的には応答が固定されやすくなります。さらに、seed パラメータ(乱数生成の初期値)も指定してみましたが、同じ画像と同じクエリ (main.py のテストケース) を繰り返し実行しても、root_agent がどのサブエージェントを呼び出すか、あるいは最終的な応答内容が変化する という現象が見られました。
例えば、「これは何の書類ですか? そして、そのデータを抽出してください。」というクエリに対して、ある時は document_classifier と data_extractor の両方を適切に呼び出すのに、別の時には data_extractor しか呼び出さない、といった具合です(これは callback.py でのログ出力で確認できました。)。あるいは、データ抽出された結果が前回と全く違うなど。
原因の考察(推測)
temperature=0.0 と seed を指定しても結果が完全には固定されなかった原因について、現時点では断定できませんが、いくつかの可能性が考えられます。
-
モデル (Gemini) 側の挙動:
temperature=0.0でも、モデル内部の計算やアーキテクチャによっては、わずかな非決定性が残る可能性があります。特にマルチモーダルな入力(テキスト+画像)を扱う場合、その複雑さが増すのかもしれません。 - ADK フレームワーク側の要因: ADK が内部的に状態を管理したり、LLM へのリクエストを構築したりする過程で、何らかの非決定的な要素が影響している可能性も考えられます。(ただし、これはあくまで推測です。)
- API レベルの変動: Google の API バックエンド側で、負荷状況などによりわずかな応答の差異が生じている可能性もゼロではないかもしれません。
- 実装の問題: ADKについてまだ深くまで知っているわけではないので、何かしらの設定方法があるのかもしれません。
対策案
ADKには構造化オプションがあるので、そちらを使うとスキーマの固定はできそうです。書類のデータ抽出などはこちらで十分かと思われます。
影響と所感
この再現性の問題は、特に以下のような場合に影響が出る可能性があります。
- 自動テスト: 期待される応答と完全に一致するかどうかを検証するテストが不安定になる。
- デバッグ: 問題が発生した際の状況再現が難しくなる。
- プロダクション環境: ユーザーに対して常に一貫した挙動を提供したい場合に課題となる。
もちろん、AI エージェントの性質上、ある程度の柔軟性や適応性は重要ですが、開発プロセスや特定のユースケースにおいては、より厳密な再現性が求められることもあります。
今回の現象は、あくまで ADK のごく一部の機能を短時間試した範囲での観察結果です。今後、ADK のバージョンアップやドキュメントの更新、あるいはコミュニティでの情報共有を通じて、このあたりの挙動がより明確になることを期待しています。
さて、良い点も少し気になる点も見えてきましたが、最後に全体のまとめと、今後試してみたいことについて触れて終わりたいと思います。
まとめと今後の展望
今回、Google がリリースした新しい AI エージェントフレームワーク Agent Development Kit (ADK) を使い、簡単な画像分類・抽出を行うマルチエージェントシステムのプロトタイプを構築してみました。
ADK のファーストインプレッション:
- 👍 Good: マルチエージェント構成を非常に手軽に実現できる。
Agentクラスとsub_agentsパラメータだけで基本的な連携が可能。 - 👍 Good: エージェント実行 (
Runner)、デバッグ支援 (Callback) など、AI エージェント開発に必要な基本機能が揃っている。 - 🤔 Challenge:
temperature=0.0やseedを指定しても、LLM (Gemini) の応答やエージェントの挙動(サブエージェント選択など)が完全に固定されず、再現性に課題が見られた。
全体として、ADK は特にマルチエージェントシステムの構築において、迅速なプロトタイピングを可能にするポテンシャルを秘めていると感じました。少ないコード量でエージェント間の連携を試せるのは大きな魅力です。
一方で、現状では応答の再現性など、まだ発展途上な部分もあるのかもしれません。このあたりは、今後のバージョンアップやコミュニティでの知見共有に期待したいところです。
今後試してみたいこと
ADK はまだ触り始めたばかりで、多くの機能を試せていません。今後、時間を見つけて以下のような点を探求してみたいと考えています。
-
ツール連携 (
Tool):- 自作関数やMCPをツールとしてエージェントに組み込む (
FunctionTool,MCPTool)。 - 外部 API (例えば Google Drive や Spreadsheet など) を操作するツールを作成・利用する。
- 自作関数やMCPをツールとしてエージェントに組み込む (
-
ワークフローエージェント:
-
SequentialAgentやParallelAgentを使って、より複雑な処理フローを定義・制御する。
-
-
評価機能:
- ADK が提供する評価ツールを使って、作成したエージェントの性能を定量的に測定する。
-
状態管理とメモリ:
-
InMemorySessionService以外の永続的なセッション管理方法を試す。 - 複数セッションをまたいで情報を記憶する
Memory機能を探る。
-
-
再現性問題の深掘り:
- 異なるモデルや設定、ADK の新しいバージョンで再現性の挙動がどう変わるか検証する。
最後に
この記事が、Google ADK に興味を持った方や、これから AI エージェント開発を始めようとしている方にとって、少しでも参考になれば嬉しいです。
ADK はまだ新しいフレームワークですが、Google が力を入れている分野でもあり、今後の進化が非常に楽しみです。ぜひ皆さんも実際に触ってみて、その可能性を体験してみてください!
参考資料:
- Google Agent Development Kit Documentation: https://google.github.io/adk-docs/
- 今回作成したコードリポジトリ: 後日公開予定
Discussion