ComfyUI で画像を生成してみる
環境
- Windows 11 Pro
- ComfyUI v0.3.44
- ComfyUI Manager V3.30.4
- ComfyUI Impact Pack 8.20.0
- ComfyUI Impact Subpack 1.3.4
ComfyUI
ComfyUI は、Stable Diffusion などの画像生成 AI モデルを直感的なノードベースのインターフェースで操作できるオープンソースのツールです。ワークフローを視覚的に構築できるため、複雑な画像生成処理も簡単に管理・カスタマイズできます。拡張性が高く、さまざまな追加パックやモデルにも対応しているため、初心者から上級者まで幅広く利用されています。
ComfyUI の導入手順
-
ComfyUI Desktop のインストーラーをダウンロードします。
-
インストーラーを実行します。
-
はじめるをクリックしてインストールを開始します。 -
GPU を選択して
次へをクリックします。 -
インストール先を選択して
次へをクリックします。 -
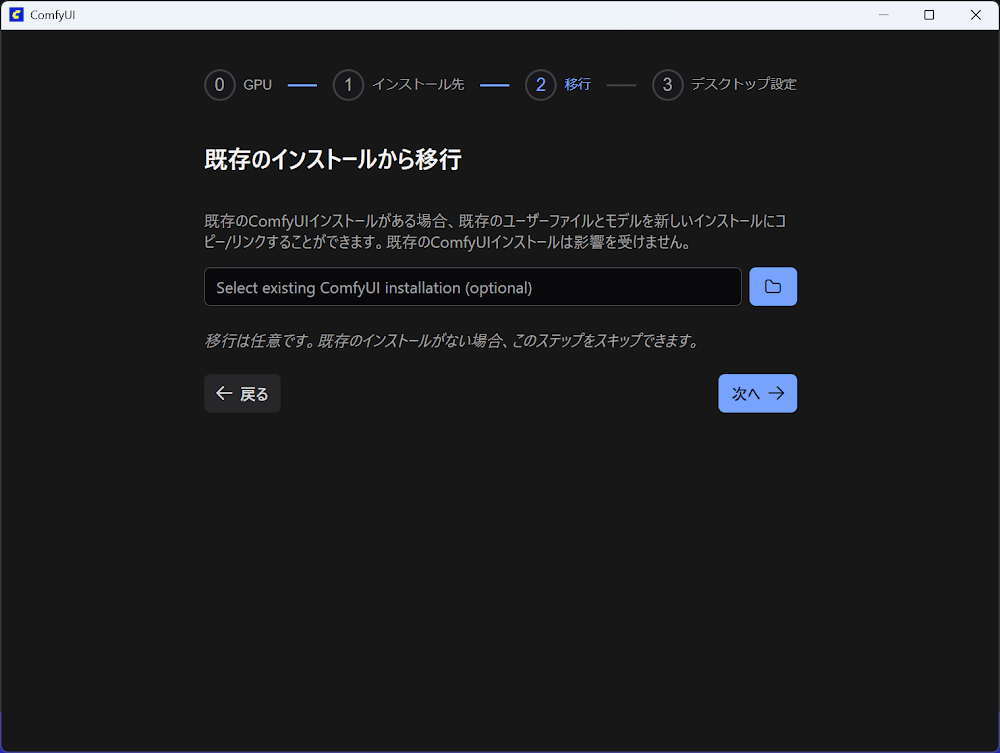
既存のインストールから移行する場合は、インストール先を選択して
次へをクリックします。 -
アプリの設定をおこない
インストールをクリックします。 -
インストールが開始されます。
-
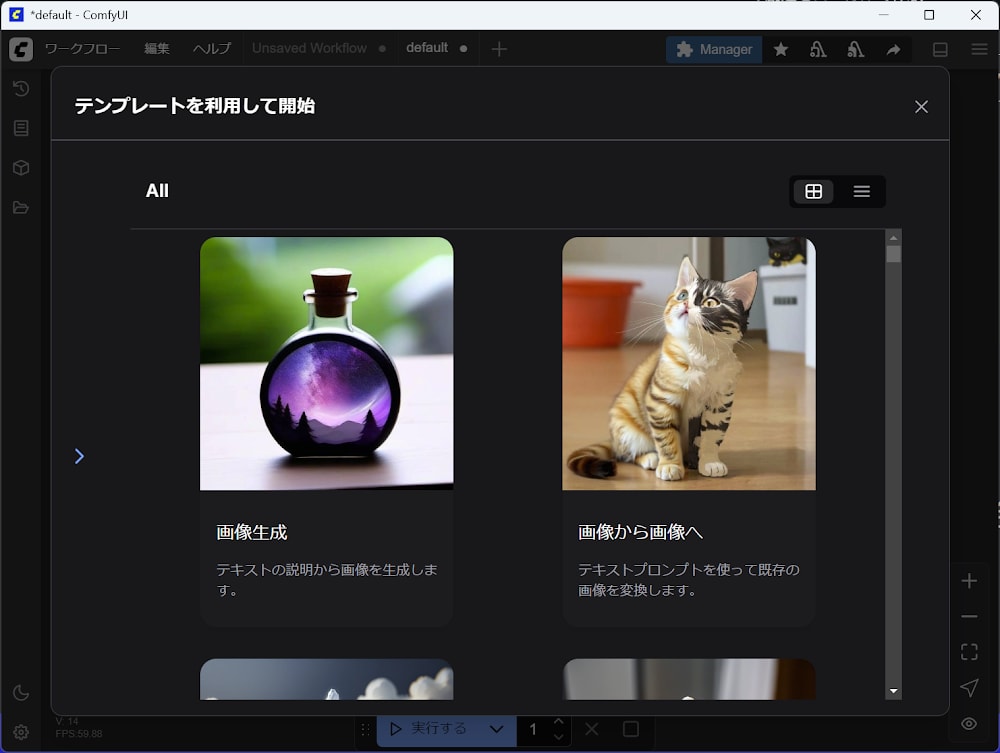
インストールが完了したら Workflow のテンプレートを選択します。今回は「画像生成」を選択します。
-
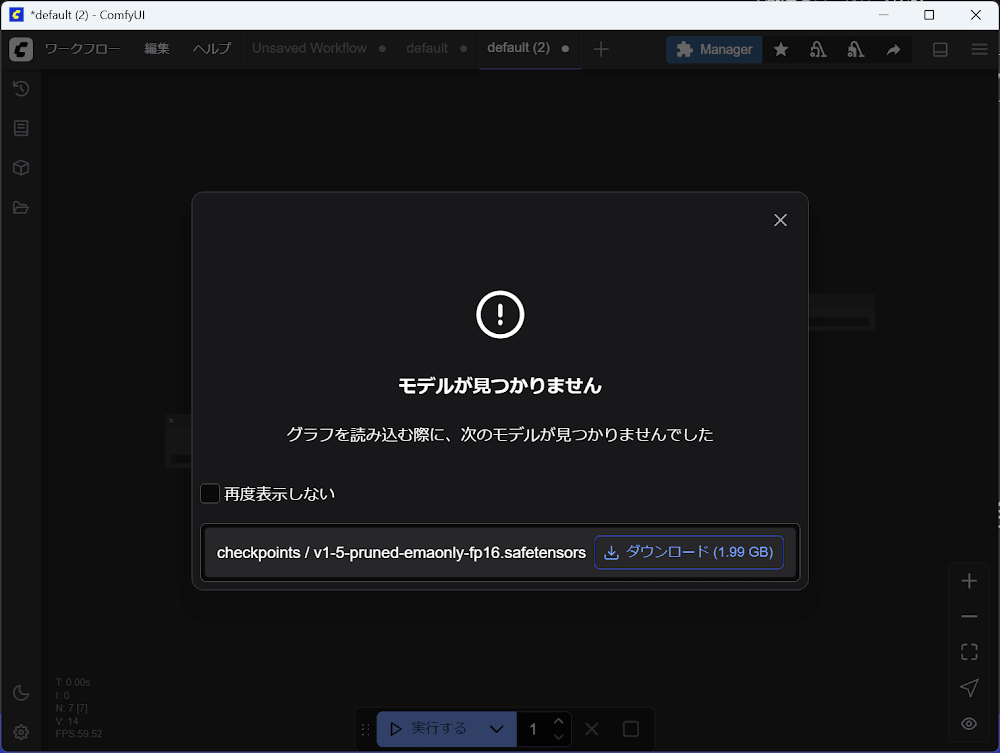
初回起動はモデルが存在しないためモデルのダウンロードするモーダル画面が表示されるので
ダウンロードをクリックします。 -
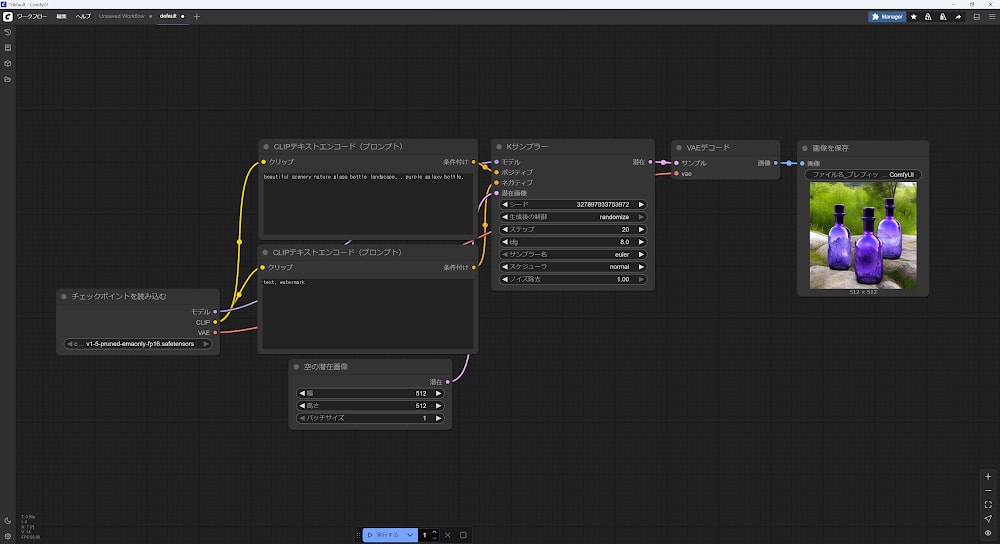
モデルのダウンロードが完了するとテンプレートの Workflow が開きます。
実行するをクリックして画像を生成することができます。




ComfyUI Manager
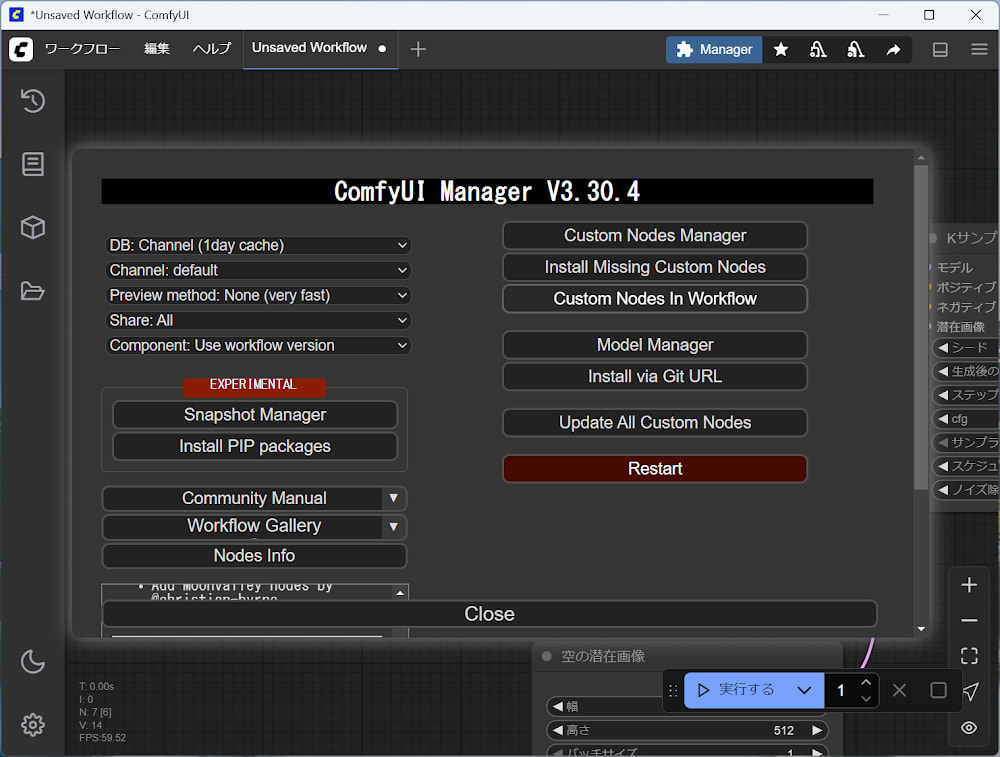
ComfyUI Manager は、ComfyUI の拡張機能やノードパック、モデルなどを簡単に管理・インストールできるツールです。GUI で操作できるため、追加パックの導入やアップデート、アンインストールなどが直感的に行えます。これにより、環境構築や機能拡張がスムーズになり、より快適に ComfyUI を活用できるようになります。
ComfyUI を起動した後、画面右上の「Manage」ボタンをクリックすると ComfyUI Manager が開きます。ここから各種ノードパックやモデルの管理・インストールが可能です。
Model
ComfyUI における「Model」とは、画像生成のベースとなる AI モデル(例:Stable Diffusion、SDXL など)を指します。モデルは画像の生成品質やスタイル、対応するプロンプトの内容に大きく影響します。
基本的な使い方
- 画面上部の「Model Loader」ノードを追加し、使用したいモデルファイル(.ckpt や .safetensors など)を選択します。
- モデルは ComfyUI Manager の「Model Manager」からダウンロード・管理できます。
- モデルを切り替えることで、生成される画像の雰囲気や精度を変えることができます。
- モデルによって対応するプロンプトやパラメータが異なるため、目的に応じて最適なモデルを選択してください。
Stable Diffusion 系以外にも、LoRA や ControlNet などの追加モデルを組み合わせることで、より細かな制御や特殊な画像生成も可能です。
Workflow
ComfyUI における「Workflow」とは、複数のノードを組み合わせて画像生成の処理手順を構築したものです。各ノードの役割や接続関係を視覚的に管理できるため、直感的に複雑な処理を設計・編集できます。Workflow を使うことで、テキストから画像生成、画像の加工、特殊効果の追加など、さまざまな工程を一連の流れとしてまとめることができ、再利用や共有も容易です。
基本的な使い方
- 画面左上の「新規 Workflow」ボタンをクリックして新しいワークフローを作成します。
- 必要なノード(例:テキスト → 画像生成、画像加工など)をドラッグ&ドロップで追加します。
- ノード同士を線でつなぎ、処理の流れを構築します。
- 各ノードのパラメータを設定し、目的に合わせて調整します。
- 「実行」ボタンを押すことで、設定したワークフローに従って画像が生成されます。
- 作成したワークフローは保存・読み込み・共有が可能です。
Node
ComfyUI における「Node」とは、画像生成の各処理や機能を表す部品のことです。ノードは入力・出力を持ち、複数のノードを組み合わせてワークフローを構築します。例えば、テキストから画像を生成するノードや、画像を加工するノードなどがあり、これらを自由につなげることで複雑な処理も視覚的に管理できます。ノードベースの設計により、直感的かつ柔軟に画像生成の流れをカスタマイズできるのが特徴です。
Load Checkpoint
「Load Checkpoint」ノードは、Stable Diffusion などの拡散モデル(.ckpt や .safetensors 形式)を読み込むためのノードです。画像生成ワークフローの最初に配置し、以降のノードで使用するモデル・CLIP・VAE をまとめて提供します。
このノードは、潜在画像(Latent Image)のノイズ除去に使う拡散モデル本体だけでなく、テキストプロンプトのエンコードに使う CLIP モデル、画像のエンコード・デコードに使う VAE モデルも同時に出力します。
Inputs
- ckpt_name: 読み込む拡散モデルファイル名(例:sdxl.safetensors など)
Outputs
- MODEL: 潜在画像のノイズ除去に使う拡散モデル
- CLIP: テキストプロンプトのエンコードに使う CLIP モデル
- VAE: 画像のエンコード・デコードに使う VAE モデル
基本的な使い方
- キャンバス上に「Load Checkpoint」ノードを追加します。
- ckpt_name で使用したいモデルファイル(.ckpt や .safetensors)を選択します。
- 出力端子(MODEL, CLIP, VAE)を KSampler や CLIP Text Encode、VAE Decode などのノードに接続して画像生成ワークフローを構築します。
このノードを使うことで、画像生成に必要なモデル・CLIP・VAE を一括で管理でき、複数のモデルを切り替えたり、好みのモデルで画像生成を行うことができます。
CLIP Text Encode (Prompt)
「CLIP Text Encode (Prompt)」ノードは、CLIP モデルを使ってテキストプロンプトを埋め込み(ベクトル化)し、拡散モデルの画像生成をガイドするためのノードです。入力したテキストは CLIP によってエンコードされ、画像生成の方向性に強く影響します。
Inputs
- clip: テキストエンコードに使う CLIP モデル(通常は Load Checkpoint から接続)
- text: 生成したい画像の内容を記述するプロンプト(例:"a cat in the garden" など)
Outputs
- CONDITIONING: 埋め込み済みテキスト情報(KSampler などに渡して画像生成をガイド)
基本的な使い方
- キャンバス上に「CLIP Text Encode (Prompt)」ノードを追加します。
- clip(CLIP モデル)と text(プロンプト)を接続します。
- 出力端子(CONDITIONING)を KSampler ノードなどにつなげて画像生成ワークフローを構築します。
このノードを使うことで、テキストプロンプトの内容が画像生成に正しく反映されるようになります。詳細なプロンプト記述方法はドキュメントのText Promptsも参照してください。
Empty Latent Image
「Empty Latent Image」ノードは、新しい空の潜在画像(Latent Image)を作成するためのノードです。主に text2image ワークフローの最初に使用し、サンプラー(KSampler など)でノイズ付加・除去を行うためのベースとなる画像データを生成します。
Inputs
- width: 潜在画像の幅(ピクセル単位)
- height: 潜在画像の高さ(ピクセル単位)
- batch_size: 生成する潜在画像の枚数
Outputs
- LATENT: 作成された空の潜在画像データ(他のノードへ渡す)
基本的な使い方
- キャンバス上に「Empty Latent Image」ノードを追加します。
- width、height、batch_size を設定します(例:512×512、batch_size=1 など)。
- 出力端子(LATENT)を KSampler ノードなどにつなげて画像生成ワークフローを構築します。
このノードは、テキストから新規画像を生成する際の起点となり、img2img や inpainting には不要です。
KSampler
「KSampler」ノードは、指定したモデルとプロンプト(Positive/Negative Conditioning)を使い、与えられた潜在画像(Latent Image)をノイズ付加・除去して新しい画像を生成するコアノードです。text2image や img2img など、ほぼ全ての画像生成ワークフローで中心的な役割を担います。
Inputs
- model: ノイズ除去に使うモデル(Load Checkpoint から)
- positive: ポジティブプロンプト(CLIP Text Encode などから)
- negative: ネガティブプロンプト(CLIP Text Encode などから)
- latent_image: 入力する潜在画像(Empty Latent Image などから)
- seed: ノイズ生成に使う乱数シード
- control_after_generate: シード値の制御(固定・ランダム・増減)
- steps: デノイズ処理のステップ数
- cfg: Classifier-Free Guidance Scale(プロンプト反映度)
- sampler_name: 使用するサンプラー名(例:Euler A, DPM++ 2M Karras など)
- scheduler: スケジューラーの種類
- denoise: 潜在画像に加えるノイズの強度
Outputs
- LATENT: デノイズ後の潜在画像(他のノードへ渡す)
基本的な使い方
- キャンバス上に「KSampler」ノードを追加します。
- model、positive、negative、latent_image、seed などを接続します。
- sampler_name、steps、cfg、denoise などを設定します。
- 出力端子(LATENT)を VAE Decode などのノードにつなげて画像生成ワークフローを完成させます。
このノードは、プロンプトや各種パラメータに応じて画像の内容や品質をコントロールできます。img2img では denoise を 1 未満に設定することで元画像の特徴を残しつつ新しい画像を生成できます。
VAE Decode
「VAE Decode」ノードは、潜在空間(Latent Space)の画像を VAE(Variational Autoencoder)を使ってピクセル画像(PNG/JPG など)にデコードするノードです。生成モデル(Stable Diffusion など)が出力した潜在画像を人間が見られる画像データに変換します。
Inputs
- samples: デコードする潜在画像(KSampler などから)
- vae: 使用する VAE モデル(Load Checkpoint などから)
Outputs
- IMAGE: デコードされた可視画像データ(他のノードや保存処理へ渡す)
基本的な使い方
- キャンバス上に「VAE Decode」ノードを追加します。
- samples(潜在画像)と vae(VAE モデル)を接続します。
- 出力端子(IMAGE)を「Save Image」や「Preview」などのノードにつなげて、生成画像を保存・表示します。
このノードを使うことで、生成モデルが出力した潜在画像を最終的な可視画像として取り出すことができます。VAE の種類によって色味やディテールが変わるため、好みに応じて VAE を切り替えることも可能です。
Save Image
「Save Image」ノードは、生成したピクセル画像(PNG/JPG など)をファイルとして保存するためのノードです。画像をノードグラフ内でプレビューしたい場合は「Preview Image」ノードを使います。
Inputs
- image: 保存するピクセル画像(VAE Decode などから)
- filename_prefix: ファイル名の先頭に付ける文字列(例:output_)
Outputs
このノードは出力を持ちません。
基本的な使い方
- キャンバス上に「Save Image」ノードを追加します。
- image(画像データ)を接続します(通常は VAE Decode から)。
- filename_prefix で保存ファイル名の先頭を設定します(必要に応じて)。
- ワークフローを実行すると、指定したフォルダに画像ファイルが保存されます。
画像の整理やファイル名のフォーマットについてはSave File Formattingも参照してください。
ComfyUI Impact Pack
ComfyUI Impact Pack は、ComfyUI の機能を拡張するための追加ノード集です。画像生成や加工、特殊効果など、標準の ComfyUI には含まれていない多彩な処理を簡単にワークフローへ組み込むことができます。これにより、より高度な画像生成やカスタマイズが可能となり、クリエイティブな表現の幅が広がります。初心者から上級者まで、用途に応じて柔軟に活用できる便利な拡張パックです。
ComfyUI Impact Subpack は、ComfyUI Impact Pack をさらに拡張するための追加ノード集です。特定の用途や高度な画像生成・加工処理に特化したノードが含まれており、より細かなカスタマイズや表現が可能になります。Impact Pack と組み合わせて使うことで、ワークフローの幅が広がり、より多彩な画像生成が実現できます。
ComfyUI Impact Pack の導入手順
-
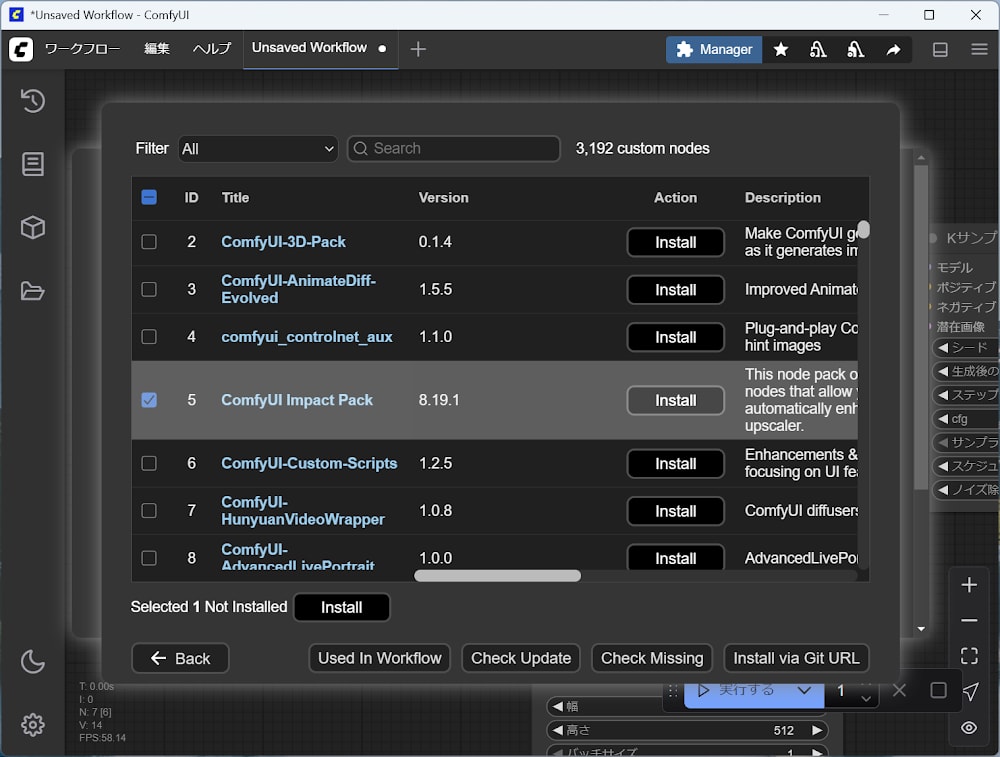
ComfyUI Manager から
Custom Nodes Managerをクリックします。 -
カスタムノード一覧の中から ComfyUI Impact Pack を探して Action の
installをクリックします。 -
ComfyUI Impact Pack のバージョンを選択し
Selectをクリックします。 -
Action に
Restart Requiredと表示されたらRestartをクリックします。

ComfyUI Impact Subpack の導入手順
-
ComfyUI Manager から
Custom Nodes Managerをクリックします。 -
カスタムノード一覧の中から ComfyUI Impact Subpack を探して Action の
installをクリックします。 -
ComfyUI Impact Subpack のバージョンを選択し
Selectをクリックします。 -
Action に
Restart Requiredと表示されたらRestartをクリックします。


トラブルシューティング
インストールで次のエラーが発生しました。
[Impact Pack/Subpack] Loaded 0 model(s) from whitelist: C:\Users\st-little\Documents\ComfyUI\user\default\ComfyUI-Impact-Subpack\model-whitelist.txt
No module named 'ultralytics'
原因の詳細は Model loading configuration related to weights_only を参照してください。
解決方法は、ComfyUI\user\default\ComfyUI-Impact-Subpack\model-whitelist.txt に次のようにモデルを追記します。
# Add base filenames of trusted models (e.g., my_old_yolo.pt) here, one per line.
# This allows loading them with `weights_only=False` if they fail safe loading
# due to errors like 'restricted getattr' in newer PyTorch versions.
# WARNING: Only add files you absolutely trust, as this bypasses a security feature.
# Prefer using .safetensors files whenever possible.
face_yolov8m.pt
face_yolov8n_v2.pt
hand_yolov8s.pt
Node
FaceDetailer
「FaceDetailer」ノードは、画像内の顔を自動検出し、その領域だけを高解像度で再生成(インペイント)することで顔のディテールを向上させるカスタムノードです(ComfyUI-Impact-Pack の一部)。
検出した顔部分を一旦拡大し、Stable Diffusion のサンプリング(生成)を小領域に対して行い、細部を修復・強調した後、元の画像に合成します。これにより、全体の構図や背景を保ちつつ、顔だけを鮮明で高品質に仕上げることが可能です。
特に SDXL 系モデル(例:Pony Diffusion V6)でアニメ調の人物画像を扱う場合、小さく崩れがちな顔や目・口などを補正するのに有用です。
Inputs
- image: 入力画像(顔を修正したい画像データ)
- model: 画像生成に使うモデル(Stable Diffusion など、Load Checkpoint から)
- clip: テキストエンコードに使う CLIP モデル(Load Checkpoint から)
- vae: 画像のエンコード・デコードに使う VAE モデル(Load Checkpoint から)
- positive: ポジティブプロンプト(CLIP Text Encode などから)
- negative: ネガティブプロンプト(CLIP Text Encode などから)
- bbox_detector: 顔検出に使うモデル(YOLO など)
- sam_model_opt: セグメンテーションモデルのオプション(顔領域抽出用)
- guide_size: 顔領域を拡大して詳細化する際の基準ピクセルサイズ(例:512, 768, 1024 など)
- guide_size_for_bbox: guide_size の適用基準(バウンディングボックス or クロップ領域)
- denoise: 顔部分の再生成時の変化度合い(0 ~ 1、低いほど元の顔を残す)
- sampler_name: 顔再生成時に使うサンプリングアルゴリズム(例:Euler A, DPM++ 2M Karras など)
- steps: 顔領域のサンプリングステップ数(例:20 ~ 30)
- cfg: Classifier-Free Guidance Scale(プロンプト反映度、例:7 ~ 9)
Outputs
- image: 顔修正後の画像データ(全体画像)
- cropped_refined: 顔領域のみを切り出して高精細化した画像
- cropped_enhanced_alpha: 顔領域の高精細化+アルファチャンネル付き画像
- mask: 顔領域のマスク画像(合成・編集用)
基本的な使い方
- キャンバス上に「FaceDetailer」ノードを追加します。
- 顔を修正したい画像データを接続します(通常は KSampler などから)。
- guide_size(顔拡大サイズ)、denoise(変化度合い)、sampler_name(サンプラー)、steps(ステップ数)、cfg(ガイダンス尺度)などを設定します。
- 出力端子を「Save Image」や他のノードにつなげて、修正後の画像を保存・表示します。
このノードを使うことで、顔部分だけを高精細に修復・強調でき、アニメ調や人物画像の品質向上に役立ちます。パラメータを調整することで、顔の大きさやディテール、雰囲気を自在にコントロールできます。
注意点
- 顔検出には YOLO 系モデル(例:
face_yolov8n_v2.ptなど)が必要です。未導入の場合は顔検出ができず、エラーが表示されます。ComfyUI Manager や GitHub からダウンロードしてください。 - セグメンテーションモデル(SAM など)が未導入の場合も、顔領域抽出ができません。必要に応じて追加してください。
- 顔が小さすぎる場合や複数人が写っている場合、検出精度が低下することがあります。guide_size や bbox_detector のパラメータを調整してください。
Tips
モデルの保存先を別ドライブに変更する(Windows)
大量のモデルを保存すると C ドライブの容量を圧迫します。既定の保存先を別ドライブや NAS に移し、元の場所にシンボリックリンクを作成することで、ComfyUI からは従来どおり参照しつつ実体を別の場所に置けます。
- 変更前の保存先: C:\Users\myuser\Documents\ComfyUI\models
- 変更後の保存先: \\192.168.0.10\data\ComfyUI\models
手順(管理者権限のコマンド プロンプト)
-
ComfyUI を終了します。
-
変更後の保存先(\\192.168.0.10\data\ComfyUI\models)を作成し、必要なら既存モデルを移動します。
-
管理者権限で「コマンド プロンプト」を開き、以下のコマンドでディレクトリのシンボリックリンクを作成します。
mklink /d C:\Users\myuser\Documents\ComfyUI\models \\192.168.0.10\data\ComfyUI\models -
エクスプローラーや
dirでリンクが作成されたことを確認し、ComfyUI を起動してモデルが認識されるか確認します。
注意事項
- シンボリックリンクの作成には「管理者権限」が必要です。
- 環境によって ComfyUI のモデルパスが異なる場合があります。ご自身の環境の
modelsフォルダパスで置き換えてください。
Discussion