GCP の Cloud Monitoring を使って SLI/SLO を運用する
概要
こんにちは、@sshota0809 です。
本記事は Uzabase Advent Calendar 2021 の 7 日目の記事となります。
昨今、SRE の文化を取り入れたり組織を新たに作ったりと様々なチャレンジをする会社が増えていると思います。
また、その中で SLA/SLI/SLO といったサービスに対する指標の策定、運用にチャレンジをする方たちも多いと思います。
今回は、SLI/SLO を定義及び運用するプラクティスの 1 つとして GCP の Cloud Monitoring を使った方法を紹介します。
TL;DR
- GCP の Cloud Monitoring には SLI/SLO を定義できる機能がある
- 定義した指標に対してエラーバジェットのバーンレートベースのアラートも定義することができる
- 各種設定は Terraform のモジュール を使うと簡単
- GCP には各種サービスのデフォルトのメトリクスの他にユーザ自身がメトリクスを定義することも可能なので、様々なメトリクスを使って柔軟に SLI/SLO の定義が可能
早速設定してみる
前置き
SLA / SLI / SLO 、エラーバージェットやバーンレートといった言葉の定義に関しては本記事では説明せず割愛します。
どのように設定できるか、プラクティスの部分に集中します。
また、本記事の内容はだいたい 公式ドキュメント に記載されている内容と同様のものとなっているので、興味がある方は参照してください。
定義する指標
今回は、例として Cloud Run で稼働しているアプリケーションの HTTP ステータスレートに関する指標を下記の通り定義してみます。
- 3 日間の HTTP ステータスコード 200 の割合が 99.9% である
設定方法
サービスの作成
GCP ではサービスという単位で指標となる複数の SLO をグルーピングして管理することができます。
デフォルトでは下記のようにサービスが定義されていないので新しくサービスを定義します。
サービスの定義は Terraform 経由で行います。
今回は下記のような形で Cloud Run に関する指標をグルーピングするサービスを定義してみましょう。
- Terraform Module - google_monitoring_custom_service
resource "google_monitoring_custom_service" "cloud_run" {
service_id = "cloud-run"
display_name = "SLO related to Cloud Run"
}
SLO の定義
さて、サービスができたらいよいよ SLO の定義をしてみましょう。
公式ドキュメントを参照するとわかるのですが、大きく SLO の設定方針を考える際に下記要素を検討する必要があります。
-
指標の選択(どのメトリクスを指標としてトラッキングするか)
- Availability
- サービスの可用性をトラッキング
- Latency
- サービスのレイテンシーをトラッキング
- Other
- ユーザ自身がトラッキングするメトリクスを指定する
- 今回は前項目でサービスを自身で定義したのでこの Other を利用することになります。
- ユーザ自身がトラッキングするメトリクスを指定する
- Availability
-
評価方法の選択
- Request-based
- 指定した時間内のリクエストの合計数に対する評価条件を満たすリクエスト数を測定
- Windows-based
- 指定した時間を更に細切れに、評価対象期間全体に対して良好さの基準を満たす評価期間の数を測定
- Request-based
今回は Request-based がマッチしていそうなのでそちらを採用して SLO の定義を Terraform 経由で定義してみましょう。
- Terraform Module - google_monitoring_slo
resource "google_monitoring_slo" "http_status_rate_200_slo" {
service = google_monitoring_custom_service.cloud_run.service_id
slo_id = "http-status-rate-200"
display_name = "HTTP Status Rate (200)"
goal = 0.999
rolling_period_days = 3
request_based_sli {
good_total_ratio {
good_service_filter = join(" AND ", [
"metric.type=\"run.googleapis.com/request_count\"",
"resource.type=\"cloud_run_revision\"",
"resource.label.\"service_name\"=\"<Cloud Run で稼働しているサービスの名前>\"",
"metric.label.\"response_code\"=\"200\""
])
total_service_filter = join(" AND ", [
"metric.type=\"run.googleapis.com/request_count\"",
"resource.type=\"cloud_run_revision\"",
"resource.label.\"service_name\"=\"<Cloud Run で稼働しているサービスの名前>\"",
])
}
}
}
ポイントは下記になります。
-
goal- 目指す指標のゴール。今回は
99.9%となります。
- 目指す指標のゴール。今回は
-
rolling_period_days- 計測期間となります。今回は直近 3 日となります。
-
request_based_sli- Request-based を採用しています。
-
good_total_ratio- 累計のリクエストに対してグリーンとするリクエストを定義し、その割合を求めます。
-
good_service_filter- グリーンとするリクエストの定義です。今回は HTTP ステータスが
200のリクエストをグリーンとするのでそのようなフィルターを定義しています。
- グリーンとするリクエストの定義です。今回は HTTP ステータスが
-
total_service_filter- 累計のリクエストの定義です。HTTP ステータスコードに関わらず、すべてのリクエストを母数としたいのでフィルターからは
response_codeの上限を抜いたものを定義しています。
- 累計のリクエストの定義です。HTTP ステータスコードに関わらず、すべてのリクエストを母数としたいのでフィルターからは
このリソースを apply してあげると GCP の GUI コンソールから下記のような形で SLO の参照が可能となります。
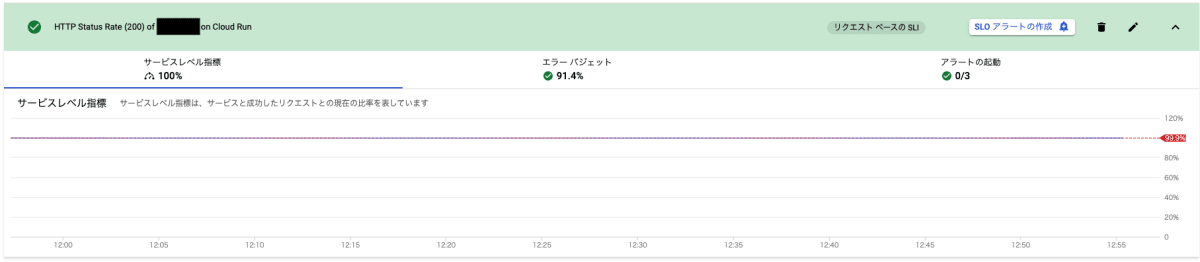
エラーバジェットの計算も自動的に算出してくれるため、場合によっては少し複雑になる計算式をユーザ側で考えて組む必要もなく簡単に SLO のトラッキングが可能です。
エラーバジェットの消費率に基づくアラートを設定する
最後に、エラーバジェットが急速に下がった場合、緩やかに下がった場合の 2 つを観測できるようにエラーバジェットの消費率(バーンレート)ベースのアラートを設定してみましょう。
すでに、上記にあるようにエラーバジェット周りの計算は GCP 側が自動で行ってくれているのでアラートの定義も非常に簡単です。
こちらも Terraform 経由で定義してみましょう。
- Terraform Module - google_monitoring_alert_policy
resource "google_monitoring_alert_policy" "alert_http_status_rate_60m_window" {
display_name = "SLO Burn Rate Alert for HTTP Status Rate (is 200) Burn Rate for 60m window"
combiner = "AND"
conditions {
display_name = "SLO Burn Rate Alert for HTTP Status Rate (is 200) Burn Rate for 60m window"
condition_threshold {
filter = "select_slo_burn_rate(\"projects/<GCP プロジェクトナンバー>/services/cloud-run-slo/serviceLevelObjectives/http-status-rate-200\", 60m)"
threshold_value = "10"
duration = "0s"
comparison = "COMPARISON_GT"
}
}
notification_channels = [<アラートチャンネルを指定>]
}
resource "google_monitoring_alert_policy" "alert_http_status_rate_6h_window" {
display_name = "SLO Burn Rate Alert for HTTP Status Rate (is 200) Burn Rate for 6h window"
combiner = "AND"
conditions {
display_name = "SLO Burn Rate Alert for HTTP Status Rate (is 200) Burn Rate for 6h window"
condition_threshold {
filter = "select_slo_burn_rate(\"projects/<GCP プロジェクトナンバー>/services/cloud-run-slo/serviceLevelObjectives/http-status-rate-200\", 6h)"
threshold_value = "2"
duration = "0s"
comparison = "COMPARISON_GT"
}
}
notification_channels = [<アラートチャンネルを指定>]
}
上記の例では 1h の間でバーンレートが 10 の場合と、 6h の間でバーンレートが 2 だった場合にアラートが上がります。
また、アラートも上記のスクリーンショットのように SLO に紐づく形で GUI からも参照できるので管理がわかりやすいです。
GCP にデフォルトで存在しないメトリクスを指標に利用する
さて、この例では GCP にデフォルトで定義されている Cloud Run のメトリクスを利用しましたが、例えば下記のような場合はどのようにしたら良いでしょうか?
- あるアプリケーション/ミドルウェアから出力されるログに記載されているレイテンシーの値を指標として利用したい(ログは Cloud Logging に転送している前提とする)
任意のアプリケーションに対するメトリクスは GCP では当然デフォルトでは用意されていないので、何かしらの方法で自身でメトリクスを定義する必要があります。
GCP ではユーザが任意でメトリクスを定義できる機能があります。
- カスタム指標
- ユーザ定義のログベースの指標
- AWS 指標
- etc...
こういった機能を利用することによりより柔軟に様々な指標の SLO の定義にも対応することができます。
終わりに
GCP の機能を使うことによって簡単に SLO のトラッキングをすることができました。
もし、GCP を使っている方であれば選択肢の一つぜひ検討してみてください。
Discussion