DiscordEarsBotをRenderにデプロイする
イントロダクション
Google MeetやZoomなどと異なり、Discordでは文字起こし(字幕)機能が標準で提供されていません。しかし、文字起こしアプリを利用してスピーカーから流れる音声を文字起こしする場合、複数人の会話だと誰の発話なのかが分かりづらく、精度も落ちてしまいます。そこで、話し手ごとに分離して文字起こししてくれるbotを作れないか調べていたところ、開発して公開してくださっている方がいました。 Herokuでのデプロイ方法については上記ページに記載があるのですが、Renderでデプロイする方法については記載がなかったため、この記事では、GoogleのSpeech-to-Text APIを採用し[1]、Renderの無料プランでデプロイして使用する手順を共有したいと思います。
手順
botの準備
DiscordのDeveloper portalでbotを作成して、運用したいサーバーに導入します。こちらの記事が詳しいので参照してください。
【2023/8/24追記】
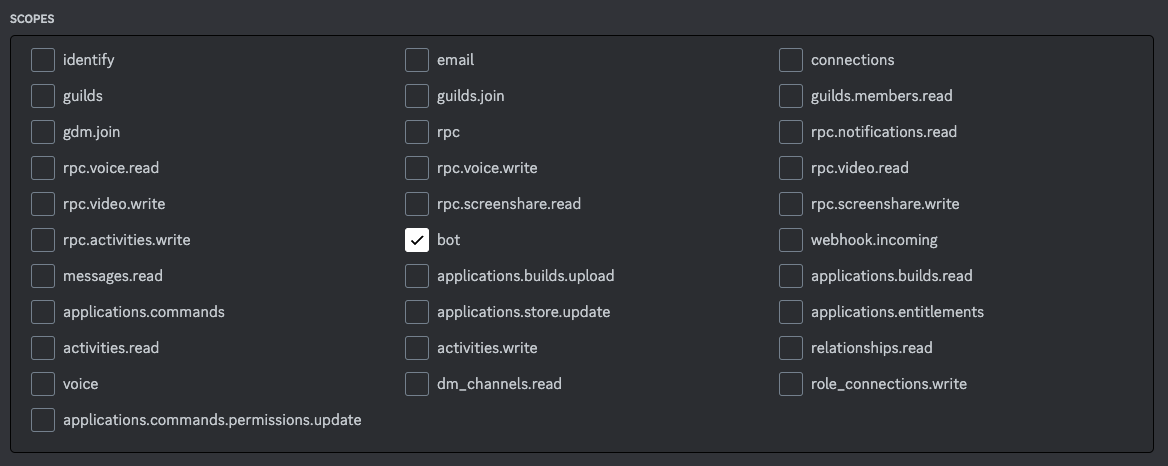
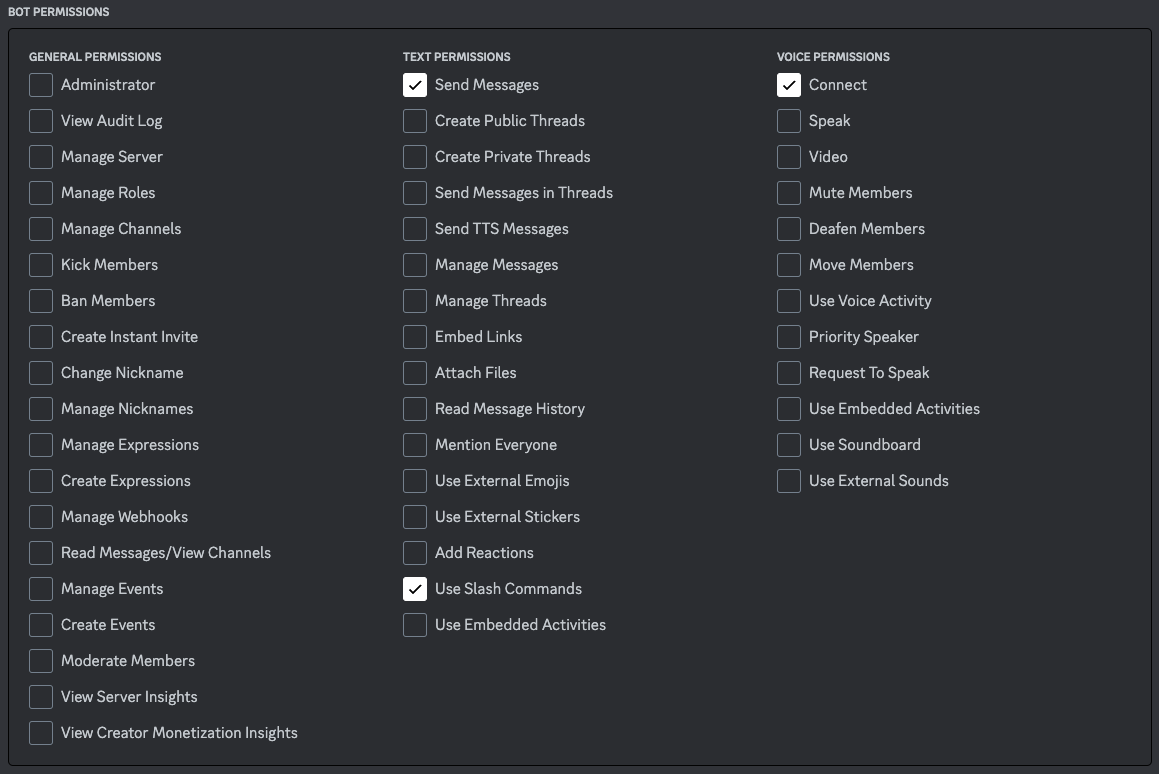
試してみたところ、下記の権限があればbotは動作しました(もしかしたら不要なものも入っているかもしれません)。もし動かないようでしたら管理者権限を付与してみてください。
【2023/9/25追記】
特権インテントの設定が有効になっていないとbotが動作しない可能性があります。こちらを参照してください。
Google Speech-to-Textを使用できるようにする
Google Cloudのアカウントを作成し、Speech-to-Text APIを有効にします。Speech-to-Text APIは毎月60分まで無料なので、いきなりお金がかかることはありません。新しいサービスアカウントを作成し、キーを手元に保存します。
Renderにデプロイする
メニューバーの「New +」から「Web Service」を選択します。

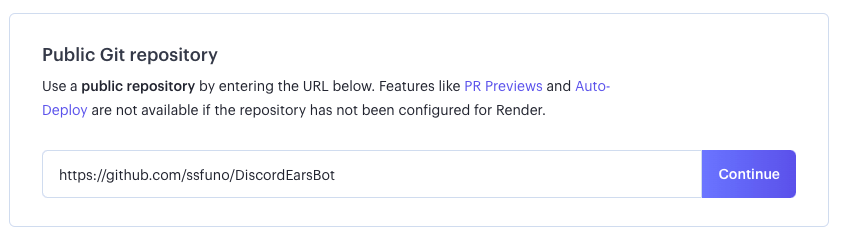
「Public Git repository」の項目で、Renderでデプロイするために私が若干手を加えたデポジトリのURLを入力します[2]。
Nameは適当に設定し、他はデフォルトの値でOKです。Instance TypeがFreeになっていることを確認してください。

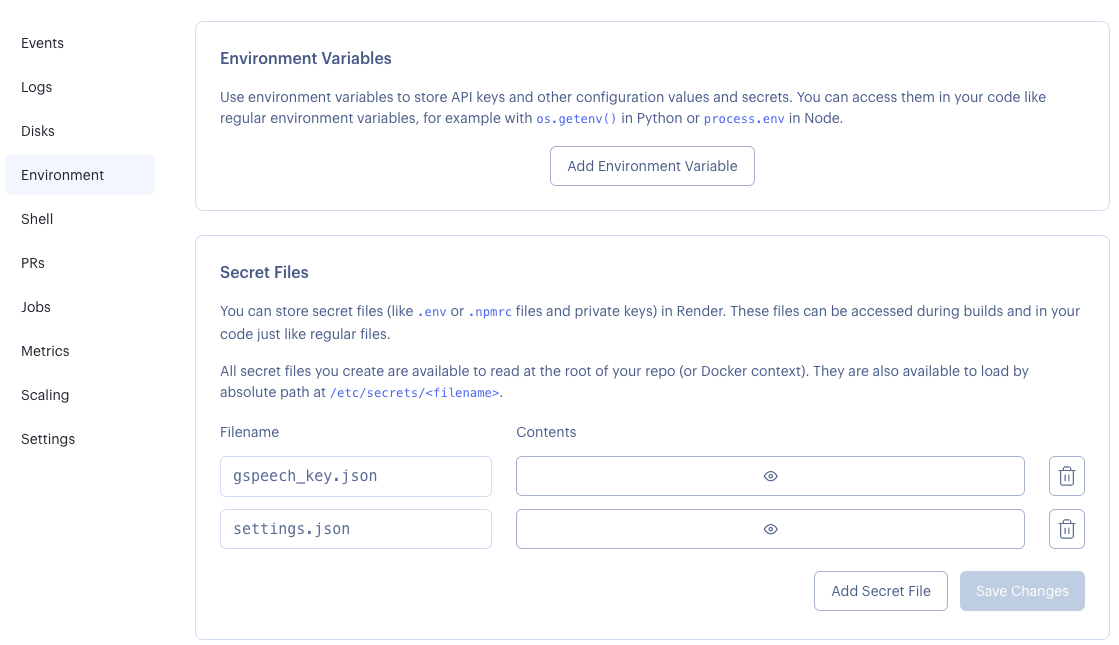
最後に画面下部の「Advanced」から「Add Secret Files」を選択します。
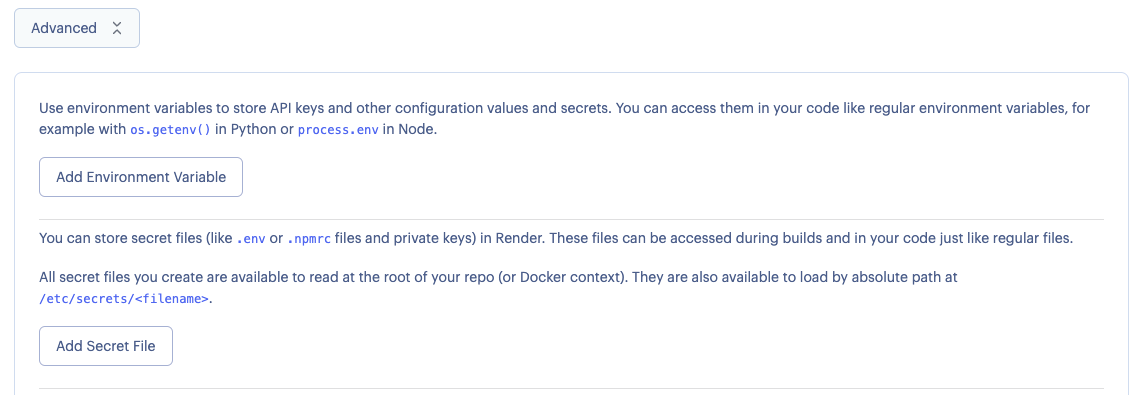
ここで先ほど取得したGoogle Cloudのサービスアカウントキーを「gspeech_key.json」という名前で保存します。
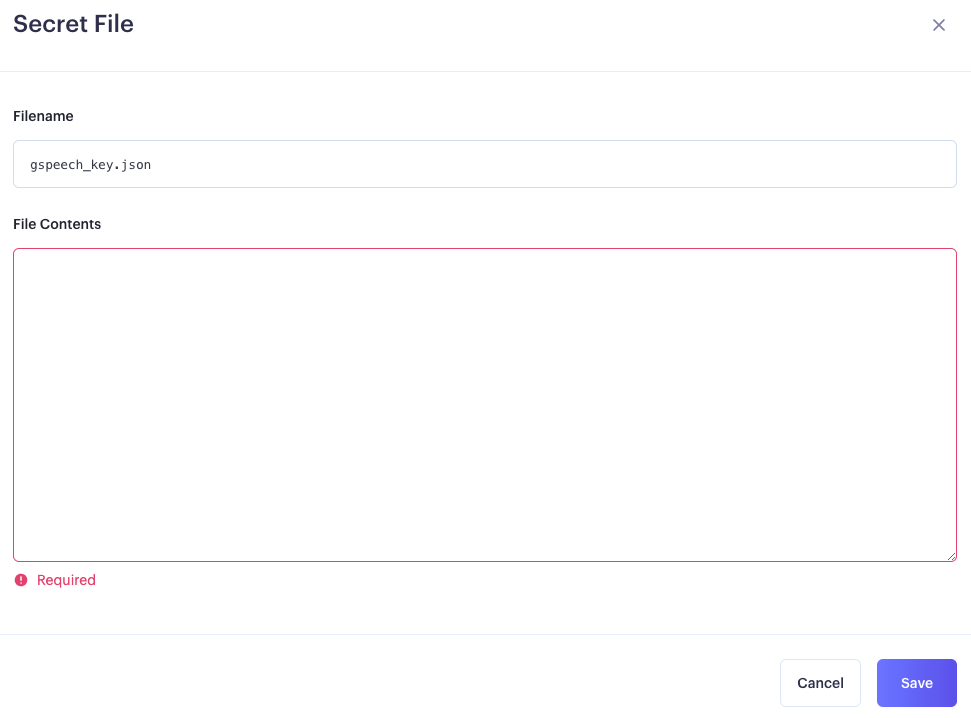
次に、「settings.json」という名前でDiscord botのtokenなどのデータを保存します。SPEECH_METHODには"google"を指定してください。
{
"DISCORD_TOK": "ここにtokenを記載",
"WITAI_TOK": "",
"SPEECH_METHOD": "google"
}
最後に「Create Web Service」を選択してデプロイを開始します。もし途中でSecret Filesの追加途中でデプロイが始まってしまった場合は、Dashboardから作成したサービスを選択して、Environment>Secret Filesから追加できます。
Uptime Robotの設定
今回はWeb Serviceの無料プランとしてデプロイしたため、15分間アクセスがないと自動でスリープ状態になります。このままでは毎回botを使用する前に、デプロイしたサービスのURLにアクセスする必要が出てきてしまうため、Uptime Robotを使って自動で定期的にURLにアクセスするようにします。詳しい手順はこちらの記事が詳しいので参照してください。
Discordでの使用
自分が任意の音声チャンネルに入り、任意のテキストチャンネルで*joinと入力すると、botが音声チャンネルに参加し、会話の内容がテキストチャンネルに文字起こしされます。使用を止めたいときは*leaveと入力します。*helpと入力すると、コマンドのリストが表示されます。
応用例
以下では、コードを書き換えてカスタマイズする方法を紹介します。
Model adaptation
詳細はGoogleの説明をご確認ください。以下に一部を抜粋します。
モデル適応機能を使用すると、提案される可能性がある他の候補よりも、Speech-to-Text が特定の単語やフレーズをより高い頻度で認識するように設定できます。たとえば、音声データに「weather」という単語が含まれているとします。Speech-to-Text が「weather」という単語を検出した場合、「whether」よりも多く「weather」と文字変換されることが理想的です。この場合は、モデル適応を使用して「weather」と認識するように Speech-to-Text にバイアスをかけることができます。
この機能は今のところLatest Longモデルでは使えないので、標準モデルを使う必要がありますが、私の環境では文字起こし自体の精度が落ちてしまう印象でした。もし標準モデルを使用したい場合は、index.jsのうち下記の部分を削除します。
- useEnhanced: true,
- model: 'latest_long',
文字起こしの対象となる時間の閾値を変更
デフォルトだと、1秒未満もしくは19秒より長い発話は文字起こしされません。これを変更したい場合、index.jsのうち下記の部分を修正します。
if (duration < 1.0 || duration > 19) {
【参考】コード変更点の説明
前述のとおり、私のリポジトリのコードはオリジナルのコードから一部修正したものです。プライベートな会話を扱う可能性のあるプログラムですので、修正の意図を説明します。
discord.jsバージョンアップ等の対応
私がローカル環境でテストした際、オリジナルのコードはそのままだと動作しませんでした。使用しているライブラリのバージョンアップ等の影響があるようでした。オリジナルの開発者とは別の方が改修したものを公開してくださっていたので、それをforkして使用しています。プログラミングそのものも音声データの処理も全く詳しくなく、何が何やらだったので、本当に助かりました。 また、Renderにデプロイした際にNode.jsのバージョンが最新だと動かなかったので18.xに指定したほか、@discordjs/opusをインストールするようにしています。
Renderの無料プランに対応
本来botはBackground Workerとしてデプロイするべきなのですが、無料プランではBackground Workerが使えないので、Expressを使って簡単なWebアプリケーションとして実装しました。こちらのコードを(ChatGPTに手伝ってもらい)Node.jsに置き換えたものを使用させていただきました。
拡張モデルの使用
Speech-to-Text APIはデフォルトだと音声データに応じて適当なモデルを選択してくれるようなのですが、私の環境ではLatest Longモデルを指定した方が精度が出たのと、なぜか(発話していない)下品な単語が文字起こしされる頻度も減ったので、Latest Longモデルを使用するようにしています。それ以外にもいくつかモデルがありますが、各モデルの説明はこちら、日本語でどのモデルが使用可能かはこちらを確認してください。
まとめ
本記事では、GoogleのSpeech-to-Text APIを採用し、Renderの無料プランでデプロイして使用する手順を整理しました。
実際にFPSゲーム中の会話を文字起こししてみた感想としては、固有名詞もあって十分な精度とは言えず、会話の話題がなんとなく推測できる程度と感じました。とはいえ、通常の会話では一定の精度が出ているとも感じるので、金銭的なコストを踏まえても使用に値するケースもあるのではないかと思います。この記事がそうしたケースでの導入にあたって参考になれば幸いです。
今後は毎月5時間まで無料のMicrosoft Azure Speech to Textや、1分あたり$0.006のOpenAI Wisper APIなどを利用して、より安価に高精度な文字起こしができないか検証してみたいと考えています[3]。
最後に、私はプログラミング初学者ですので誤りが含まれている可能性もあると思います。ご意見ご指摘や、上記のサービスの実装例をご存知の方、ぜひお知らせいただけますと助かります。また、導入方法などでご不明点ありましたら回答しますので、お気軽にご連絡ください。
【追記】Azure Speech to Textも試してみた(が失敗した)
【2023/9/25追記】
公式ドキュメントを参考に、下記のようなコードを組み込んでテストしてみたのですが、全く意味不明なテキストが返ってきました。これはサンプリングレートの問題なのではないかと感じています。
DiscordEarsBotで扱っている音声データはサンプリングレートが48kHzなのですが、Azure Speech to Textで標準の16kHz以外に指定する方法が見つからず、リサンプリングをするにもNode.jsのライブラリで変換できるものが見つからなかったので、保留にしています。詳しい方いらしたらお教えいただけると幸いです。
const sdk = require("microsoft-cognitiveservices-speech-sdk");
// Azureのアカウントを作成し、SpeechKeyやSpeechRegionを設定
// 日本だとSpeechRegionはjapaneastにするのが良さそう
const speechConfig = sdk.SpeechConfig.fromSubscription("YourSpeechKey", "YourSpeechRegion");
speechConfig.speechRecognitionLanguage = "ja-JP";
// 既定の形式を使用してPushAudioInputStream をサポートするメモリを作成
const pushStream = sdk.AudioInputStream.createPushStream();
pushStream.write(buffer);
pushStream.close();
const audioConfig = sdk.AudioConfig.fromStreamInput(pushStream);
// 音声認識を実行し、文字起こしされたテキストを表示
const speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig);
speechRecognizer.recognizeOnceAsync(result => {
console.log(`azspeech: ${result.text}`);
speechRecognizer.close();
});
-
いくつかの文字起こしサービスを利用できるようになっているのですが、VoskモデルとGoogleのSpeech-to-Text APIを使用してみたところ、私の環境(主にFPSゲームでの通話音声)だとGoogleの方が精度が高いことが分かったため、その手順について説明します。他のモデルの使用方法については、オリジナルのリポジトリのReadmeを参照してください。 ↩︎
-
RenderとGitHubのアカウントを接続したうえで、私のリポジトリをforkすれば、「Connect a repository」から利用することもできます。この場合、リポジトリをprivateにしていても使用できると思います。 ↩︎
-
Amazon Transcribeは基本料金がGoogleと同じで、毎月の無料枠(60分間)が1年で消滅してしまうので、候補から外して考えています。 ↩︎
Discussion