


こんにちは、SREホールディングス株式会社にてデータサイエンティストをやっております吉田です。
本記事ではMetric Learningを用いた階層型の学習について、背景や実験を交えて紹介します。
対象読者
- 階層的なMetric Learningに興味のある方
- OpenMMlab(mmpretrain)でSupervised Contrastive learning、Hierarchical Multi-Label Contrastive Learningがしたい方
背景
Metric Learning
Metric Learningでは特徴量の学習を通常のクラス分類ではなく、特徴量間同士の距離を学習する形で行います。これにより類似した入力の検出や、未知のクラスへの対応が可能となります。
実例として、kaggleのGoogle Landmark Recognition 2020では与えられた画像が何のランドマークかを予想するタスクでしたが、クラス数が81K以上と非常に多い設定でした。このため通常のクラス分類が難しく、多くの上位回答がArcfaceを用いたMetric Learningのアプローチを用い、テスト対象が学習データのどれと類似しているかで分類していました。
またHappywhale - Whale and Dolphin Identificationでは、イルカとクジラの個体識別を行いタスクでしたが、各個体の枚数が非常に少ない、かつ学習データにない未知の個体に対応する必要があることから、こちらも上位回答がArcfaceを採用していました。
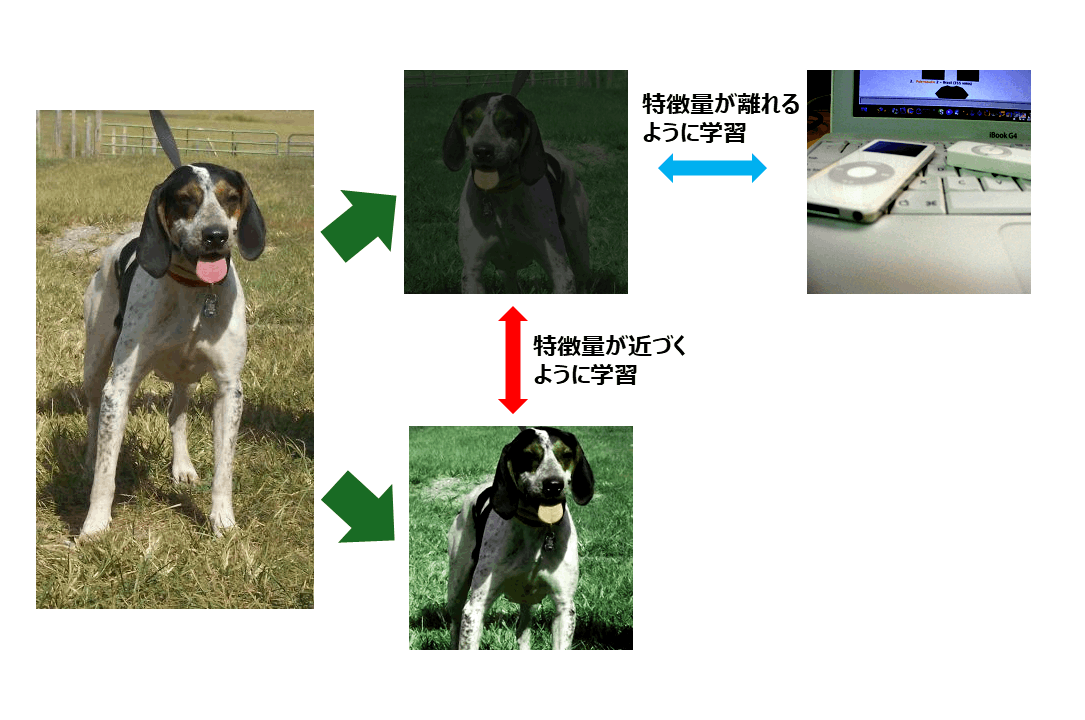
MetricLearningにおけるDataArgumentationの図示
図内の各画像ソース:miniImageNet(CC0: Public Domain)
手法の1つであるSimCLRでは1枚の画像からData Argumentationで2枚の画像を作成し、それらの類似度が高くなるように、一方で同バッチ内の別の画像との類似度が下がるようにします。
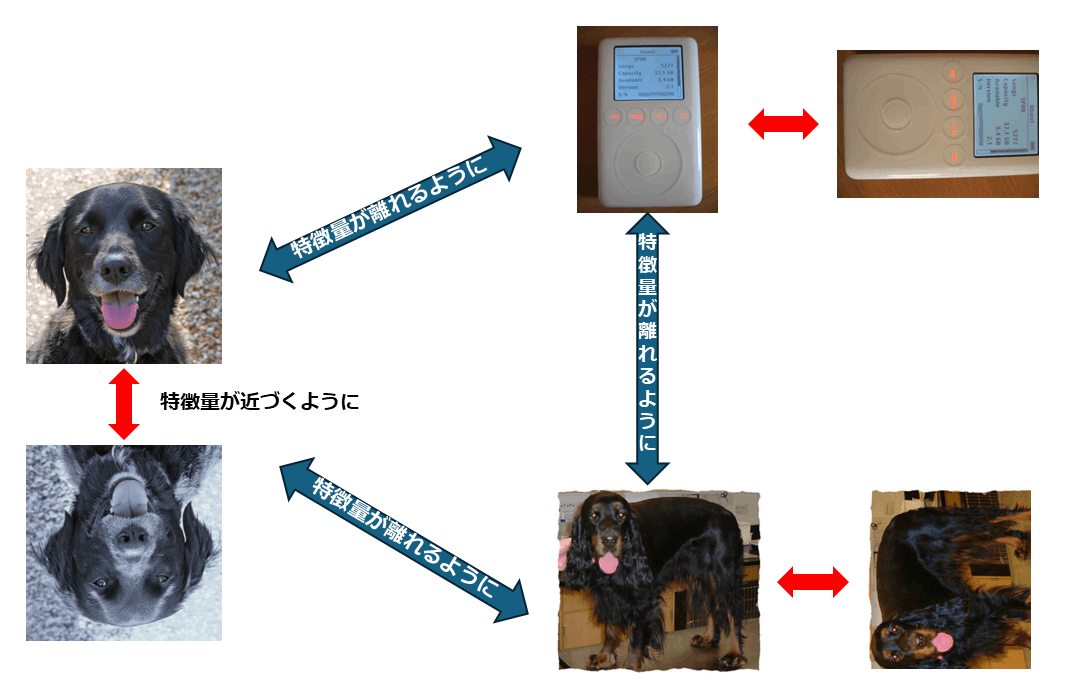
SimCLRにおける1バッチ内での学習の図示
図内の各画像ソース:miniImageNet(CC0: Public Domain)
上記の戦略では同じバッチ内で同じ分類になるべき画像があることもあり、良いバッチの選び方が難しいという課題があります(図のように同じ犬でも距離が離れてしまう)。そのため、ArcfaceやSupervised Contrastive learningのようにMetric Learningにクラス分類の仕組みを組み合わせた手法が提案されています。
Supervised Contrastive learning
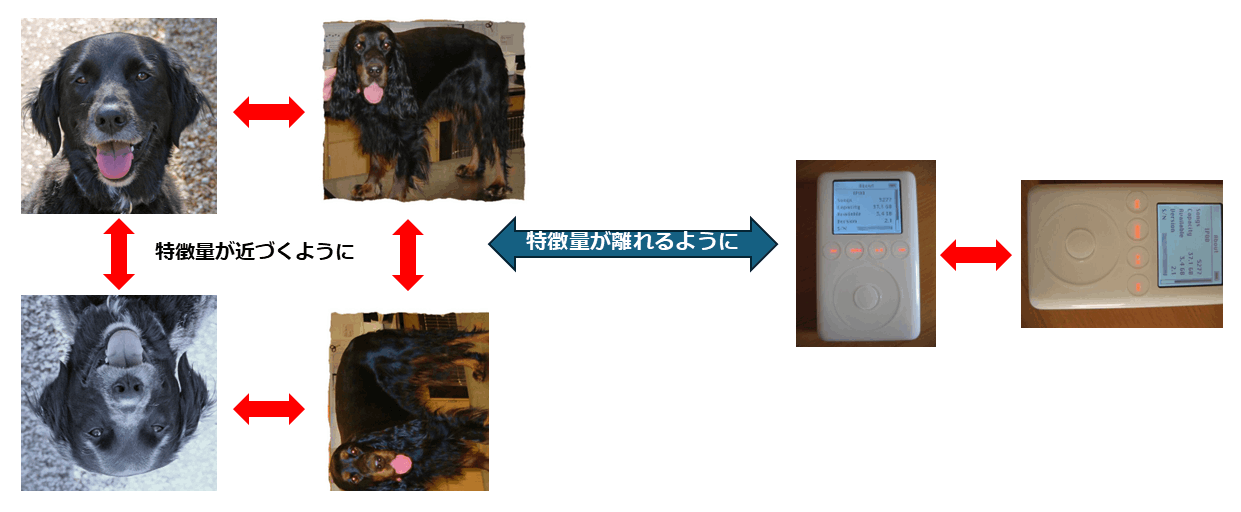
Supervised Contrastive learningにおける学習の図示
図内の各画像ソース:miniImageNet(CC0: Public Domain)
SimCLRを拡張させた手法で、入力に対して正解クラスを割り当てることで、各バッチで同一クラスの距離が近くなるように、異なるクラスの類似度が遠くなるように学習していきます。学習の流れはSimCLRと同じで、バッチサイズ内部の画像にData Argumentationをかけ、画像ごとに2枚の画像を生成します。異なるのは以下のロス関数です。
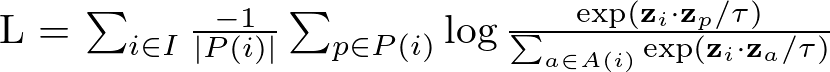
Supervised Contrastive learningのloss関数
Iがバッチサイズ、P(i)がiと同じラベルになる画像、A(i)がiと異なるラベルになる画像の集合です。
loss=-log(同じクラス同士のコサイン類似度)+log(違うクラス同士のコサイン類似度)となり、同じクラスに所属する入力のロスは小さくなるように、他方は違うクラスに所属する入力は大きくなります。これにより、同一クラスの特徴量が正しく近い位置に配置されやすくなります。
Hierarchical Multi-Label Contrastive Learning
Supervised Contrastive learningで特徴量を学習できます。しかし、現実では1つの階層でクラス分類するには課題があります。
現実には犬の中にもゴールデンレトリバー、ブルドッグ、プードルのような犬種があり、これらは別々のラベルとして扱いたいこともあるでしょう。一方で別々として学習させてしまうと、例えば犬Aと犬Bの類似度は猫よりは高くなってほしいですが、ロス関数にそのような計算はなく、この要件は満たされません。
このように1つの階層のラベル付けには課題があり、複数階層での学習を行いたくなります。そのための手法がHierarchical Multi-Label Contrastive Learningです。
手法
学習の流れ自体はSupervised Contrastive learningと同様で、ロス関数を以下のように拡張しています。
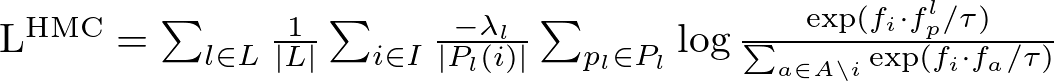
Hierarchical Multi-Label Contrastive Learningのloss関数
Lが階層であり、Supervised Contrastive learningに階層のロス計算を追加した形となっております。各階層ごとにロス計算をし、階層内で同一クラスに所属する入力の類似度が高くなるようにしています。
λによって階層ごとの重みを指定しており、基本的には犬種のような一番下の階層の重みが大きく、犬のように上位の階層に行くほど小さくします。
実験
データ
miniImageNetのデータを用いてSupervised Contrastive learning、Hierarchical Multi-Label Contrastive Learningの学習を行います。miniImageNetは各画像にラベル付けされた物体が映っている、またラベル間の階層構造が定義されており、階層型学習に扱いやすいため使用しました。
簡略化のため、今回は4階層目にある以下の3つのクラスを使用します。

Dog
図内の各画像ソース:miniImageNet(CC0: Public Domain)

Equipment
図内の各画像ソース:miniImageNet(CC0: Public Domain)

establishment
図内の各画像ソース:miniImageNet(CC0: Public Domain)
階層としては以下のようになります。
- dog
- Golden setter
- Golden retriever
- Walker hound
- Saluki
- Ibizan hound
- Dalmatian
- Newfoundland
- Miniature poodle
- Komondor
- Malamute
- Boxer
- Tibetan mastiff
- French bulldog
- equipment
- horizontal bar
- parallel bars
- iPod
- photocopier
- establishment
- bookshop
- tobacco shop
コード
こちらのHierarchical Multi-Label Contrastive Learningの公式実装を使用します。
記事冒頭に書いた通り、今回は上記をOpenMMLabを通して使用します。論文の再現であれば上記をそのまま実行してもよいですが、様々なデータセットやモデルに拡張させるには扱いづらいです。なので今回はCVフレームワークであるOpenMMLabの中のmmpretrainを使用します。
OpenMMLabについてこちらの記事等を参考にしていただきつつ、今回はこちらのレポジトリに従ってmmpretrainの環境を整えていただければ大丈夫です。
上記をmmlabから呼び出すために、Modelを以下のように定義します。
Modelソースコード
from losses import HMLC, SupConLoss # https://github.com/salesforce/hierarchicalContrastiveLearning/tree/masterのlosses/losses.pyをimport
class SupervisedCLR(BaseSelfSupervisor):
"""SupervisedCLR.
mmpretrainからの入力をHMLC向けにして呼び出す。
"""
def __init__(
self,
backbone: dict,
neck: Optional[dict] = None,
head: Optional[dict] = None,
target_generator: Optional[dict] = None,
pretrained: Optional[str] = None,
data_preprocessor: Optional[Union[dict, nn.Module]] = None,
init_cfg: Optional[dict] = None,
is_hierarchical: bool = False,
hierarchical_type: str = "hmc",
):
super(SupervisedCLR, self).__init__(
backbone=backbone,
neck=neck,
head=head,
target_generator=target_generator,
pretrained=pretrained,
data_preprocessor=data_preprocessor,
init_cfg=init_cfg,
)
self._is_hierarchical = is_hierarchical
if self._is_hierarchical:
self._loss = HMLC(loss_type=hierarchical_type)
else:
self._loss = SupConLoss()
def loss(self, inputs: List[torch.Tensor], data_samples: List) -> Dict:
device = torch.device("cuda") if inputs[0].is_cuda else torch.device("cpu")
# anchorとcompareの2つが来るのでstackで1つにする
inputs = torch.stack(inputs, 1)
inputs = inputs.reshape((inputs.size(0) * 2, inputs.size(2), inputs.size(3), inputs.size(4)))
x = self.backbone(inputs)
features = self.neck(x)[0]
# 正規化
features = features / (torch.norm(features, p=2, dim=1, keepdim=True) + 1e-10)
# [batch, 2(anchor,compare), neckのshape]に変形
features = features.view(features.shape[0] // 2, 2, features.shape[1])
if self._is_hierarchical:
# 階層型用のラベル作成
targets = [data.gt_label for data in data_samples]
labels = torch.concat(targets).reshape(len(targets), len(targets[0])).to(device)
else:
# 非階層型のラベル作成
targets = torch.IntTensor([data.gt_label[0] for data in data_samples]).to(device)
labels = targets.contiguous().view(-1, 1)
loss = self._loss(features, labels)
return {"loss": loss}
次にDatasetに関する話です。
通常のラベルは数値を付与しますが、階層型の場合は配列としてラベルを付与します。
HMLCの実装ではラベルの配列を以下のように定義します。
[["階層1ラベル","階層2ラベル",・・・,'元のラベル','未使用ラベル'],[...]]
今回のケースでは、bookshopの正解ラベルは
[2,18,0]
のようになります。
これらをモデルは以下のようにfor文で取得し、元のラベル、階層1のラベル、階層2のラベル・・・と階層ごとにラベルを取り出し、それぞれロス計算を行います。
for l in range(1,labels.shape[1]):
mask[:, labels.shape[1]-l:] = 0
Datasetのコードは以下の通りです。
Datasetのソースコード
import os
from collections import defaultdict
from collections.abc import Mapping
from typing import Callable, Dict, List, Optional, Sequence, Union
import numpy as np
from mmengine.config import Config
from mmengine.dataset import BaseDataset
from mmpretrain.registry import DATASETS
@DATASETS.register_module()
class HierarchicalImagenet(BaseDataset):
def __init__(
self,
ann_file: Optional[str] = "",
metainfo: Union[Mapping, Config, None] = None,
data_root: Optional[str] = "",
data_prefix: dict = dict(img_path=""),
filter_cfg: Optional[dict] = None,
indices: Optional[Union[int, Sequence[int]]] = None,
serialize_data: bool = True,
pipeline: List[Union[dict, Callable]] = [],
test_mode: bool = False,
lazy_init: bool = False,
max_refetch: int = 1000,
) -> None:
self.data_root = data_root
self.label_map = self.create_label_map()
super().__init__(
ann_file,
metainfo,
data_root,
data_prefix,
filter_cfg,
indices,
serialize_data,
pipeline,
test_mode,
lazy_init,
max_refetch,
)
def create_label_map(self) -> Dict[str, Dict[str, int]]:
"""ディレクトリ構造をもとに階層型ラベルのマップを作成する.
Example:
{'': {'equipment': 0, 'dog': 1, 'establishment': 2},
'equipment': {'n03584254': 0, 'n03888605': 1, 'n03924679': 2, 'n03535780': 3},
}
"""
label_map = defaultdict(dict)
for root, _, _ in os.walk(self.data_root):
relative_path = os.path.relpath(root, self.data_root)
if relative_path == ".":
continue
parts = relative_path.split(os.sep)
current_path = ""
for i, part in enumerate(parts):
if i == 0:
# 最上位ディレクトリのとき
if part not in label_map[""]:
label_map[""][part] = len(label_map[""])
else:
parent_path = current_path
if part not in label_map[parent_path]:
# 新しいラベルの設定、ディレクトリの取得順に各階層の番号を割り当て
label_map[parent_path][part] = len(label_map[parent_path])
# current_pathの更新
current_path = os.path.join(current_path, part)
return dict(label_map)
def get_hierarchical_label(self, path: str) -> List[int]:
"""pathの階層ラベルの取得"""
parts = path.split(os.sep)
label = []
current_path = ""
for _, part in enumerate(parts):
# 各階層のラベルを取得
label.append(self.label_map.get(current_path, {}).get(part, 0))
current_path = os.path.join(current_path, part)
# 末尾に使わないラベル0を追加
label.append(0)
return label
def load_data_list(self) -> List[dict]:
data_infos = []
# data_root内の画像を取得
for root, _, files in os.walk(self.data_root):
for file in files:
if not file.lower().endswith((".png", ".jpg", ".jpeg")):
continue
img_path = os.path.join(root, file)
relative_path = os.path.relpath(root, self.data_root)
label = self.get_hierarchical_label(relative_path)
data_infos.append({"img_path": img_path, "gt_label": label})
return data_infos
最後に設定ファイルを作成します。
設定ファイルはこちらを参考にしながら、modelとdatasetを先ほど作成したものに変更します。最低限学習ができる状態にした設定ファイルは以下です。
設定ファイル
from . import HierarchicalImagenet
from . import SupervisedCLR
default_scope = "mmpretrain"
# model settings
pretrained = "https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth"
data_preprocessor = dict(
type="SelfSupDataPreprocessor", mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True
)
model = dict(
type=SupervisedCLR,
data_preprocessor=data_preprocessor,
is_hierarchical=True,
backbone=dict(
type="ResNet",
depth=18,
in_channels=3,
norm_cfg=dict(type="SyncBN"),
zero_init_residual=True,
init_cfg=dict(type="Pretrained", checkpoint=pretrained, prefix="backbone"),
),
neck=dict(
type="NonLinearNeck", # SimCLR non-linear neck
in_channels=512,
hid_channels=256,
out_channels=128,
num_layers=2,
with_avg_pool=True,
),
)
# data settings
view_pipeline = [
dict(type="RandomResizedCrop", scale=224, backend="pillow"),
dict(type="RandomFlip", prob=0.5),
dict(
type="RandomApply",
transforms=[dict(type="ColorJitter", brightness=0.8, contrast=0.8, saturation=0.8, hue=0.2)],
prob=0.8,
),
dict(type="RandomGrayscale", prob=0.2, keep_channels=True, channel_weights=(0.114, 0.587, 0.2989)),
dict(type="GaussianBlur", magnitude_range=(0.1, 2.0), magnitude_std="inf", prob=0.5),
]
train_pipeline = [
dict(type="LoadImageFromFile"),
dict(type="MultiView", num_views=2, transforms=[view_pipeline]),
dict(type="PackInputs"),
]
train_dataloader = dict(
batch_size=32,
num_workers=4,
persistent_workers=True,
sampler=dict(type="DefaultSampler", shuffle=True),
collate_fn=dict(type="default_collate"),
dataset=dict(
type=HierarchicalImagenet,
data_root="/home/docker/japanpile_soil_similarity/dataset",
pipeline=train_pipeline,
),
)
train_cfg = dict(type="EpochBasedTrainLoop", max_epochs=1000)
# optimizer
optim_wrapper = dict(type="OptimWrapper", optimizer=dict(type="SGD", lr=0.001, momentum=0.9, weight_decay=0.0001))
# runtime settings
default_hooks = dict(checkpoint=dict(type="CheckpointHook", interval=10, max_keep_ckpts=3))
param_scheduler = dict(
type="MultiStepLR",
by_epoch=True,
milestones=[400],
gamma=0.1,
)
下記を実行することで学習を行えます。
cd mmpretrain
python tools/train.py [作成したconfigファイル]
実験結果
実験結果として、各クラス間のコサイン類似度の平均値を示します。
まずはSupervised Contrastive learningの結果です。
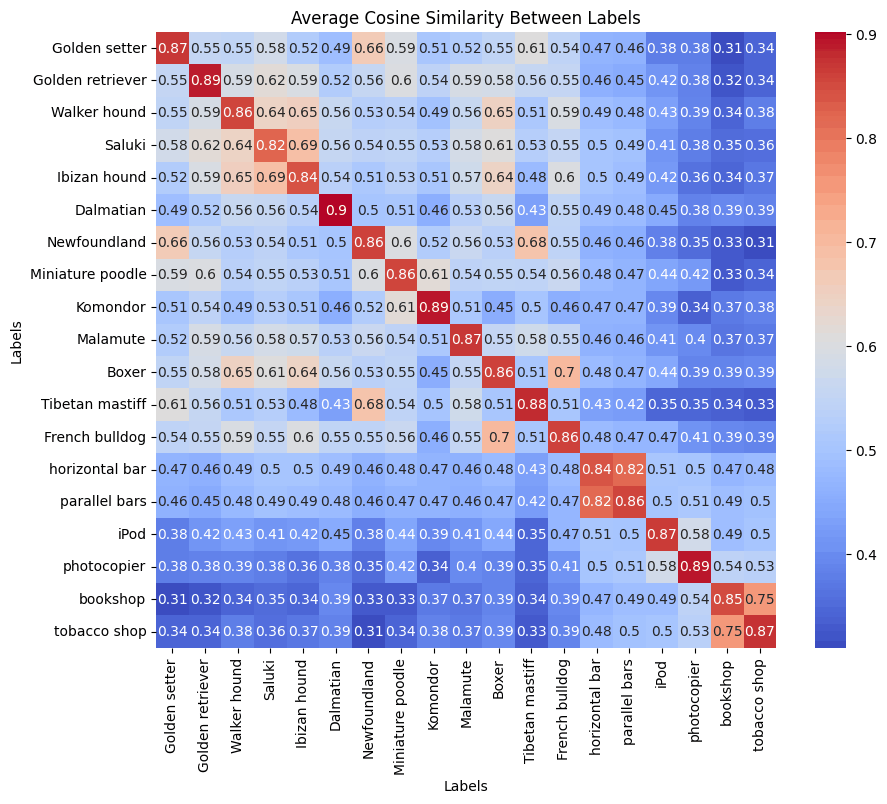
Supervised Contrastive learningの結果
上記のように各クラスごとでは強い相関を示しています。
BoxerとFrench bulldog、horizontal barとpararell barsのように識別が難しい例はどちらも高い類似度となってしまっていますが、今回はこちらの精度改善については深追いしません。
次に、Hierarchical Multi-Label Contrastive Learningです。
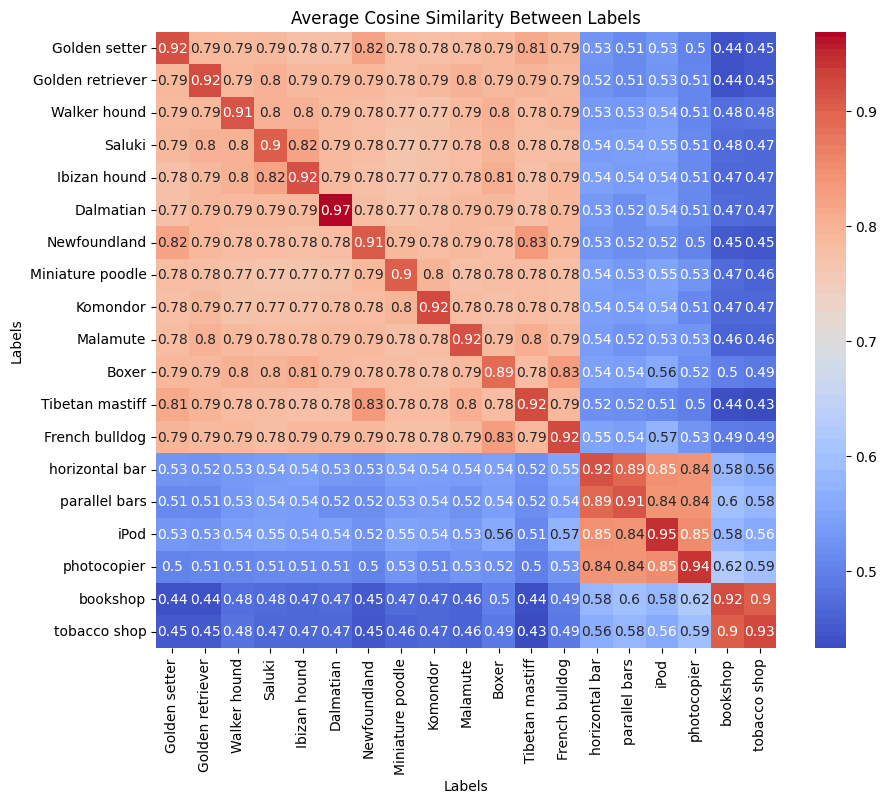
Hierarchical Multi-Label Contrastive Learningの結果
各クラスごとの類似度が強いのはそのままですが、犬同士、物同士、お店同士と上位階層内での類似度も高くなっています。目的としていたことが実現できました。
まとめ
階層的な学習手法の1つとしてHierarchical Multi-Label Contrastive Learningの紹介をしました。今回は階層2つで行いましたが、より深い階層も扱うことも可能ですし、精度面など扱いきれていないことは多いので、この記事を参考に深堀していただけると嬉しいです。
階層構造を保持した特徴量比較は様々な使い道があるかもしれないと考えており、参考になりましたら幸いです。

Discussion