こんにちは。
SREホールディングス株式会社データサイエンティストの岡林です。
データ分析、機械学習の前処理では通常pandasを使用していますが、データ数が増えてくると処理時間が気になることがあります。
少し前から話題になっているpolarsを使用すると、pandasよりも速く処理ができそうなので、実際に試してみます。
TL;DR
-
polarsはpandasより、概ね数倍〜十倍程度速い - データのread/writeはcsvよりも、parquetを使用した方が速い
- ライブラリの成熟度、安定性の面では
pandasが有利
用途やシーンによって使い分けるのが良い。
動作環境
- M1 MacBook Pro
- メモリ: 16GB
- python: 3.12.0
- numpy: 1.26.0
- pandas: 2.1.2
- polars: 0.19.12
サンプルデータの準備
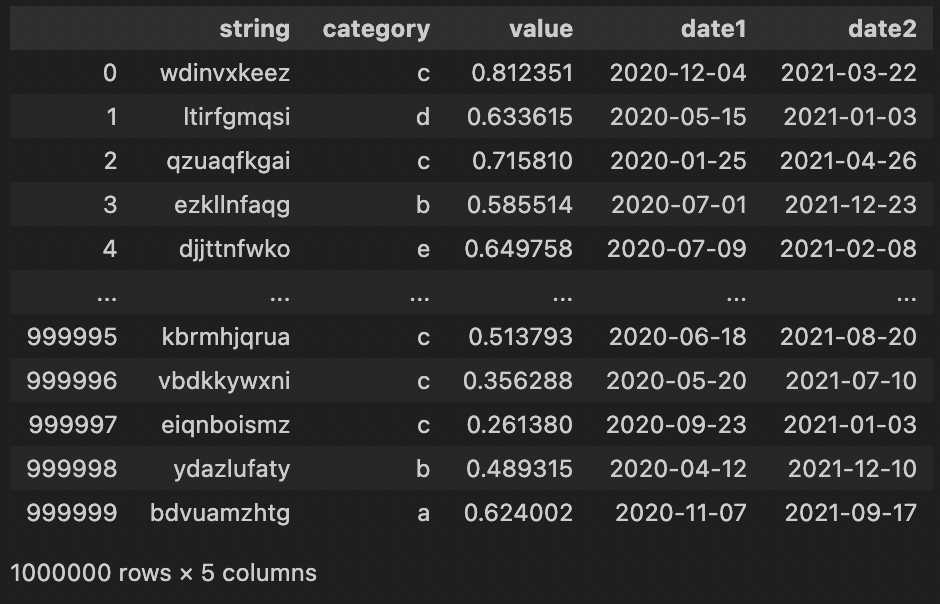
検証用に以下のデータを用意します。データ数は100万件です。
- string: 10文字のランダムな文字列
- category: a ~ e のランダムな1文字
- value: 0 ~ 1 のランダムな数値
- date1, date2: ランダムな日付
import string
import numpy as np
import pandas as pd
import polars as pl
n_letters = 10
n_samples = 1_000_000
rng = np.random.default_rng(1234)
string_list = rng.choice(list(string.ascii_lowercase), (100, n_letters))
string_list = [''.join(string_list[i]) for i in range(100)]
category_list = ['a', 'b', 'c', 'd', 'e']
df = pd.DataFrame(
{
'string': rng.choice(string_list, n_samples),
'category': rng.choice(category_list, n_samples),
'value': rng.random(n_samples),
'date1': np.datetime64('2020-01-01') + rng.integers(0, 365, n_samples),
'date2': np.datetime64('2021-01-01') + rng.integers(0, 365, n_samples)
}
)
データの中身
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 string 1000000 non-null object
1 category 1000000 non-null object
2 value 1000000 non-null float64
3 date1 1000000 non-null datetime64[s]
4 date2 1000000 non-null datetime64[s]
dtypes: datetime64[s](2), float64(1), object(2)
memory usage: 38.1+ MB
csvのread/write
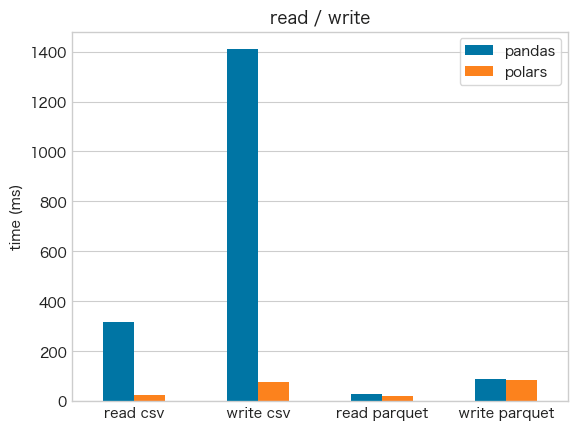
- read/writeともに
polarsが速い - 特にwriteは20倍近くの差がある
read
%%timeit
df_pandas = pd.read_csv('data.csv')
316 ms ± 14.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit
df_polars = pl.read_csv('data.csv')
25.3 ms ± 577 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
write
%%timeit
df_pandas.to_csv('output_pandas.csv', index=False)
1.41 s ± 5.99 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit
df_polars.write_csv('output_polars.csv')
75.1 ms ± 1.07 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
parquetのread/write
- parquetでは
pandasとpolarsの差は少ない - 総じてcsvよりparquetを使った方が速い
read
%%timeit
pd.read_parquet('output_pandas.parquet')
28.3 ms ± 110 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%timeit
pl.read_parquet('output_polars.parquet')
18.8 ms ± 69.6 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
write
%%timeit
df_pandas.to_parquet('output_pandas.parquet')
88.2 ms ± 3.25 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%timeit
df_polars.write_parquet('output_polars.parquet')
86.4 ms ± 1.76 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
データ型変換
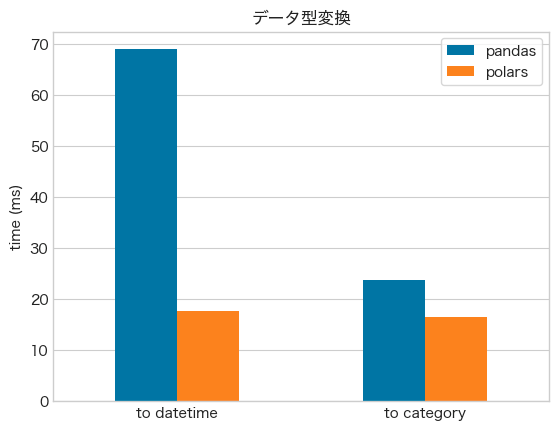
- データ型の変換でも
polarsが速い
str to datetime
%%timeit
pd.to_datetime(df_pandas['date1'], format='%Y-%m-%d')
69 ms ± 839 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%timeit
df_polars.select(pl.col('date1').str.to_date(format='%Y-%m-%d'))
17.6 ms ± 127 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
str to category
%%timeit
df_pandas['category'].astype('category')
23.7 ms ± 1.02 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%timeit
df_polars.select(pl.col('category').cast(pl.Categorical))
16.4 ms ± 267 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
集計
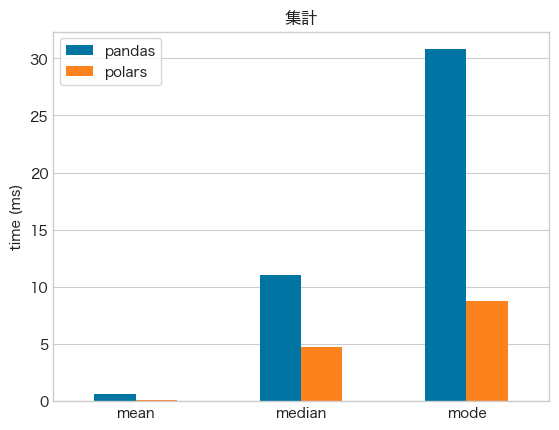
- 集計でも
polarsが速い
mean
%%timeit
df_pandas['value'].mean()
662 µs ± 25.3 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
%%timeit
df_polars.select(pl.col('value').mean())
133 µs ± 2.21 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
median
%%timeit
df_pandas['value'].median()
11 ms ± 151 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%%timeit
df_polars.select(pl.col('value').median())
4.74 ms ± 157 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
mode
%%timeit
df_pandas['string'].mode()
30.8 ms ± 490 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%timeit
df_polars.select(pl.col('string').mode())
8.74 ms ± 351 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
変換
str.contains
-
str.containsではpolarsが10倍以上速い - 複数の
str.containsを行うと、pandasは線形に処理時間が増えていくのに対して、polarsは処理時間の増加が緩やか
%%timeit
df_pandas['string'].str.contains('a')
200 ms ± 5.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit
df_polars.select(pl.col('string').str.contains('a'))
14.8 ms ± 361 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%%timeit
a = df_pandas['string'].str.contains('a')
b = df_pandas['string'].str.contains('b')
c = df_pandas['string'].str.contains('c')
d = df_pandas['string'].str.contains('d')
e = df_pandas['string'].str.contains('e')
987 ms ± 10.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit
df_polars.select(
pl.col('string').str.contains('a').alias('a'),
pl.col('string').str.contains('b').alias('b'),
pl.col('string').str.contains('c').alias('c'),
pl.col('string').str.contains('d').alias('d'),
pl.col('string').str.contains('e').alias('e'),
)
22.9 ms ± 737 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
str.replace
%%timeit
df_pandas['string'].str.replace('a', 'A')
146 ms ± 1.39 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%timeit
df_polars.select(pl.col('string').str.replace('a', 'A'))
9.01 ms ± 25.4 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
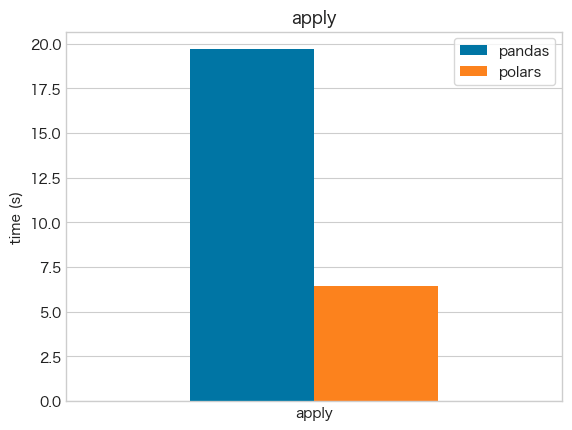
apply
- 他の処理と比較して、
applyの処理は特に遅いことが確認できる -
pandasもpolarsも、なるべくapplyを使わないことが推奨される -
applyにおいても、polarsの方が速い
from dateutil.relativedelta import relativedelta
%%timeit
df_pandas[['date1', 'date2']].apply(
lambda x: relativedelta(x['date1'], x['date2']).months,
axis=1
)
19.5 s ± 114 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit
df_polars.select(['date1', 'date2']).map_rows(
lambda x: relativedelta(x[0], x[1]).months
)
6.46 s ± 10.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
処理時間まとめ

複数の処理をまとめて比較
def func_pandas():
df = pd.read_csv('data.csv')
df['date1'] = pd.to_datetime(df['date1'], format='%Y-%m-%d')
df['date2'] = pd.to_datetime(df['date2'], format='%Y-%m-%d')
df['a'] = df['string'].str.contains('a')
df['date_diff'] = (df['date2'] - df['date1']).dt.days
df['string'] = df['string'].str.replace('a', 'A')
return df
%%timeit
func_pandas()
831 ms ± 12.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
def func_polars():
df = pl.read_csv('data.csv').with_columns(
pl.col('date1').str.to_datetime(format='%Y-%m-%d'),
pl.col('date2').str.to_datetime(format='%Y-%m-%d'),
pl.col('string').str.contains('a').alias('a'),
).with_columns(
(pl.col('date2') - pl.col('date1')).dt.days().alias('date_diff'),
pl.col('string').str.replace('a', 'A')
)
return df
%%timeit
func_polars()
58.7 ms ± 1.65 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
まとめ
大規模なデータを扱う場合は、pandasよりpolarsの方が速いことが確認できました。
また、データの読み書きについては、csvよりparquetが優れています。書き出し時のファイルサイズについても、parquetはcsvより有利です。
一方でpolarsはその安定性にはまだ不安があります。Jupyter Notebookで大規模なデータを処理をしていると、何度かkernel crashに遭いました。
高速化の恩恵が大きい大規模なデータの処理やbatch処理では、polars、parquetを、安定性や互換性が求められるシーンではpandas、csvの使用を検討するのが良いと思います。

Discussion