クローラーを作るならCloudflare Workersがおすすめ
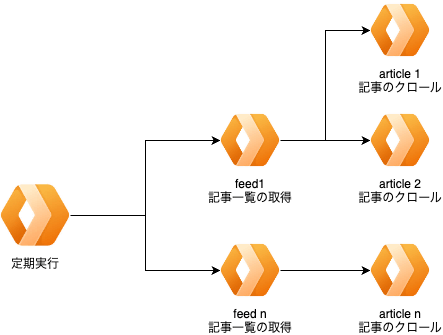
クローラーのシステム構成案
これまで他者の提供するRSSやアグリゲータで記事収集してたのですが、これでは手の届かない情報というものがあります。
例えば
- RSSが提供されてないサイト
- ログインが必要なサイト
- そのユーザーのみが閲覧できるサイト
これらに機械的にアクセスする手段としてヘッドレスブラウザがあります。
pupeeteerに代表されるヘッドレスブラウザは、通常のブラウザ操作を自動化するのに役立ちます。
2024年の4月にCloudflareから発表された「Browser Rendering API」はサーバレス基盤上でヘッドレスブラウザを動かすことができるサービスです。
Cloudflare Workersはサイズの制限が厳しい反面、うまく使うと安価で高速なシステムを構築できます。
追加料金なしの構成を考えた結果が上の図です。
毎時aggregateをcronで実行し以下の処理を行います。
- aggregate.ts... 事前に登録されているfeeds分のfeed QUEUEを発行
- aggregate_feed.ts... feed_idを受け取る。該当feedの更新を確認して更新分のarticle QUEUEを発行
- aggregate_article.ts... article_idを受け取る。articleについて取得しDBに保存
指定の制限時間内で処理を終わらせる必要があるため、コンテンツ量の増加が処理時間に影響しないように設計する必要があります。
またBrowser Rendering APIのレート制限も厳しいため、失敗時に時間をおいて再度クロールする再送処理も必要です。
上記二つを解決するために、Cloudflare Queueの木構造を採用しています。
親は子イベントに関心を持っていないためQueueを発行するだけで処理を終えることができます。
aggregate.ts
└─ feed QUEUE
├─ feed1
├─ feed2
└─ ...
└─ feedn
└─ aggregate_feed.ts
└─ article QUEUE
├─ article1
├─ article2
└─ ...
└─ articlen
└─ aggregate_article.ts
└─ 記事のDB保存
メッセージをvalibotで定義する
QueueはJSON形式のメッセージを受け取ります。
それらにはtypeが存在しており、それによってルーティングを行います。
いわゆるtagged unionと呼ばれるものですが、valibotを使うことで型安全なメッセージを定義できます。
import * as v from "valibot";
export const AggregateSchema = v.object({
type: v.literal("aggregate"),
});
export const FeedSchema = v.object({
type: v.literal("feed"),
feedId: v.number(),
});
export const ArticleSchema = v.object({
type: v.literal("article"),
articleId: v.number(),
});
export const Schema = v.variant("type", [
AggregateSchema,
FeedSchema,
ArticleSchema,
]);
export type AggregateMessage = v.InferOutput<typeof AggregateSchema>;
export type FeedMessage = v.InferOutput<typeof FeedSchema>;
export type ArticleMessage = v.InferOutput<typeof ArticleSchema>;
export type Message = v.InferOutput<typeof Schema>;
export const sendQueue = async (message: Message, env: Env) => {
await env.QUEUE.send(JSON.stringify(message));
};
export const sendBatch = async (messages: Message[], env: Env) => {
await env.QUEUE.sendBatch(
messages.map((message, i) => ({
body: JSON.stringify(message),
delaySeconds: i * 10,
})),
);
};
再送処理とルーティング
上記スキーマをもとにQueueに入ってきた後の処理を行います。
Cloudflare Queueは再送処理をサポートしているため、レート制限エラーが発生した場合にretryでdelaySecondsを指定することで任意の時間後に再送することができます。
Google geminiの無料枠15回/分もこれで回避できます。
worker_job.ts... メッセージを受け取り、ルーティングを行う
const router = (message: Message, env: Env): Promise<Response> => {
switch (message.type) {
case "aggregate":
return aggregate(env);
case "feed":
return aggregateFeed(env, message);
case "article":
return aggregateArticle(env, message);
default:
throw new Error("Invalid message type");
}
};
export async function handleJob(
batch: MessageBatch,
env: Env,
ctx: ExecutionContext,
) {
for (const rawMessage of batch.messages) {
try {
const message = v.parse(Schema, JSON.parse(rawMessage.body as string));
const response = await router(message, env);
return response;
} catch (err) {
// 再送回数を定義
// 60秒後に再送することでレート制限を回避
if (rawMessage.attempts < 10) {
rawMessage.retry({ delaySeconds: 60 });
}
}
}
return new Response("No messages processed.", { status: 404 });
}
定期実行される木のルート部分
Cloudflare Workersはcronをサポートしているため、定期実行される関数を定義することができます。cronは変更容易性が比較的低いのでロジックを入れずキューを発行するだけにとどめることを意識しました。
wrangler.toml
[triggers]
crons = ["0 * * * *"] # Runs every hour
worker_scheduleer.ts... 定期実行される関数
export async function handleSchedule(
controller: ScheduledController,
env: Env,
ctx: ExecutionContext,
) {
console.log(controller.cron);
const client = createClient(env);
const aggregateResponse = await aggregate(env, client);
if (!aggregateResponse.ok) {
console.error(`Error aggregating: ${aggregateResponse.text()}`);
}
return new Response("Scheduled jobs completed.", { status: 200 });
}
jobs/aggregate.ts... 事前に登録されているfeeds分のfeed QUEUEを発行
export async function aggregate(env: Env) {
// 全て取得
const { data } = await getFeeds(env);
if (!data) {
return new Response("No feeds found.", { status: 404 });
}
// 該当のmessageの形式に変換
const feeds = data.map<FeedMessage>((feed) => ({
feedId: feed.id,
type: "feed",
}));
// 全て送信するだけ
await sendBatch(feeds, env);
return new Response(`${feeds.length} Feeds enqueued successfully.`, {
status: 200,
});
}
一覧の取得
該当のページにアクセスして、記事の一覧を取得します。
この時点では記事の内容は取得していません。
HTMLだった場合はBrowser Rendering APIを使ってHTMLを取得しaタグを抽出してarticle QUEUEを発行します。
jobs/aggregate_feed.ts... feed_idを受け取る。該当feedの更新を確認して更新分のarticle QUEUEを発行
export async function aggregateFeed(env: Env, message: FeedMessage): Promise<Response> {
const feed = await getFeed(env, message.feedId);
if (feed.error) {
return new Response("Failed to fetch feed.", { status: 400 });
}
const articleList = await getArticleList(env, feed.data.url);
const articleIds = await saveArticles(env, articleList);
const articleMessages = articleIds.map<ArticleMessage>((id) => ({
articleId: id,
type: "article",
}));
await sendBatch(articleMessages, env);
return new Response("Feed processed successfully.", { status: 200 });
}
// Browser Rendering APIを使って記事一覧を取得
// 実際には不要なリンク除外や相対パスの処理もしてます
// Tips: 重複チェックはキューの先で行う。Skipされることが自明ならばここで除外する
async function getArticleList(env: Env, url: string) {
const browser = await puppeteer.launch(env.BROWSER);
const page = await browser.newPage();
await page.goto(url, { waitUntil: "networkidle0" });
const articleList = await page.evaluate(() => {
const articles = Array.from(document.querySelectorAll("a"));
return articles.map<ArticleMessage>((article) => ({
url: article.href,
title: article.textContent,
}));
});
await browser.close();
return articleList;
}
記事の取得
記事の内容を取得します。ここでもBrowser Rendering APIを用いて記事の内容を取得し、DBに保存します。
jobs/aggregate_article.ts... article_idを受け取る。articleについて取得しDBに保存
export async function aggregateArticle(env: Env, message: ArticleMessage) {
const article = await getArticle(env, message.articleId);
if (article.error) {
console.error("Error fetching article:", article.error);
return new Response("Failed to fetch article.", { status: 400 });
}
// Skip if article already aggregated
// Tips: 重複チェックはキューの先で行う。何が投げられてもいいように設計すること
if (article.data.content) {
return new Response("Article already aggregated.", { status: 200 });
}
// Browser Rendering APIを使って記事を取得
const browser = await puppeteer.launch(env.BROWSER);
const page = await browser.newPage();
await page.goto(url, { waitUntil: "networkidle0" });
const content = await page.content();
await browser.close();
const updateArticle = await updateArticleSummary(env, message.articleId, { content });
if (updateArticle.error) {
return new Response("Failed to update article.", { status: 400 });
}
return new Response("Success", { status: 200 });
}
Cloudflare QueueとBrowser Rendering APIはどちらも$5/月の有料プランですが、上記構成だと追加料金が発生しないので安心です。
ただユーザーに解放するとなると、レート制限(2ブラウザ/分)が優っちゃうので気をつけてください。
Discussion