Unicodeの正規化
NFCとかNFD、NFKC、NFKDを整理してみます。
合成
Unicodeにおいて、複数の符号位置(code position, code point)を組み合わせて1文字を表すことができます。これを合成(composed)と呼びます。その反対は、分解(decomposed)と呼びます。
合成する場合は、合成のベースとなる基底文字と合成のために使う結合文字を組み合わせることで1文字を表します。結合文字は合成のためだけに使われ、それ単体で使われることはありません。
合成の例
は U+306F + ゜ U+309A => ぱ
ぱ U+3071 もコードポイント一つで表現できる。
package main
import "fmt"
func main() {
fmt.Println("\u306F\u309A")
fmt.Println("\u3071")
}
結果は下記のとおりです。
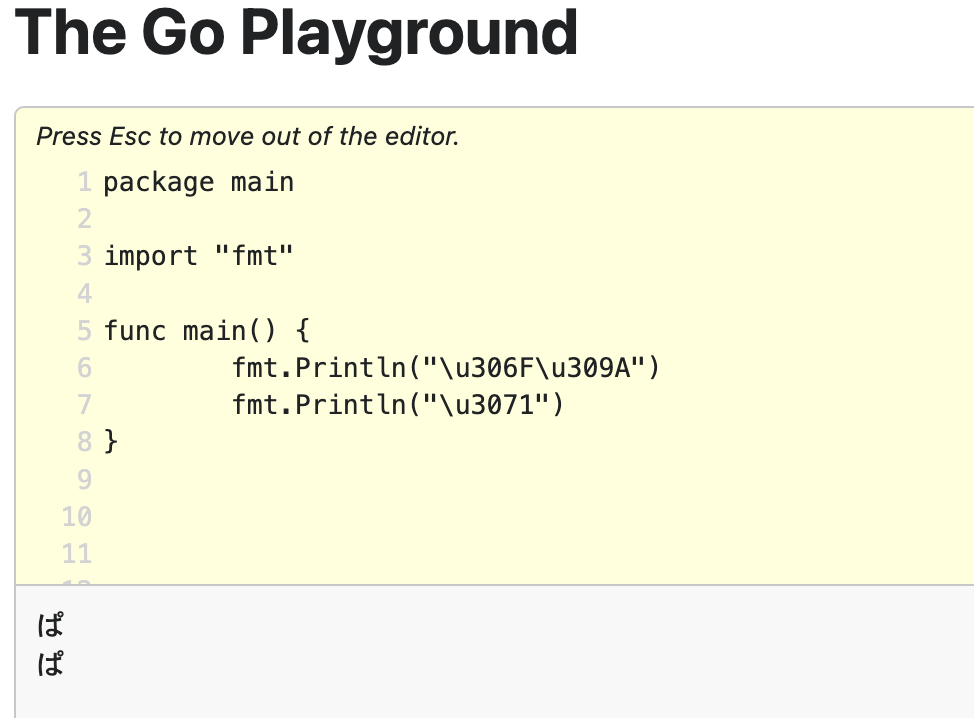
ぱ を 合成して2つのコードポイントから1文字にするのと、もともと1つのコードポイントを使って1文字にした例となります。
このように、Unicodeでは、同じ文字として表示するために、複数の表現方法があります。
Unicodeの等価性
正準等価(canonical equivalence)
視覚的および機能的に等価であるものを正準等価と呼びます。
前の例では、U+3071 と U+306F + U+309A は正準等価となります。
互換等価(compatibility equivalence)
正準等価より広い意味での等価を表すものです。
視覚的な違いのみがあり、意味的な区別はないものを互換等価としています。
例えば、① (丸付きの1) と 1 は互換等価となります。
正規化
同じ文字に複数の表現方法(複数の符号化表現)があると、文字比較をするときに符号化表現をあわせておかないと同じ見た目でも一致しないというようなことも起こり得ます。
そこで、文字の符号化表現を揃えることをします。これを正規化(normalization)と呼びます。
正規化には4パターンあります。
- NFD(Normalization Form Canonical Decomposition) 正準等価で分解
- NFC(Normalization Form Canonical Composition) 正準等価性によって分解し、再度合成する。これにより文字の並びが変化することもある
- NFKD(Normalization Form Compatibility Decomposition) 互換等価で分解
- NFKC(Normalization Form Compatibility Composition)互換等価性によって分解され、正準等価性によって再度合成
すでに多くの文字がNFCで表現されていて、コードポイント数が減りやすいことから、正規化においてはNFCが使われることがほとんどです。
GoでNFCをやってみる
golang.org/x/text/unicode/norm を使うことで正規化ができます。
例は下記のとおりです。
package main
import (
"fmt"
"golang.org/x/text/unicode/norm"
)
func main() {
a := "\u306F\u309A"
a_nfc := norm.NFC.String(a)
b := "\u3071"
b_nfc := norm.NFC.String(b)
fmt.Printf("%s, %v \n", a, []rune(a))
fmt.Printf("%s, %v \n", a, []rune(a_nfc))
fmt.Printf("%s, %v \n", a, []rune(b))
fmt.Printf("%s, %v \n", a, []rune(b_nfc))
}

runeを使ってコードポイントを表示しているので、実際にUnicodeの符号表現とは見た目が変わりますが、やりたいことは伝わるかなと。
こんな感じでGoでは正規化ができます!
参照
Discussion