どうも、スプラで見かけた「ふくやまはさまる」のネーミングセンスに感服した@ksterxです。
Claude OpusさんやChatGPT大先生にこの意味をご説明願ったら、頓珍漢な答えが返ってきました。この辺が解せるようになったらAGIであるとかなんとか。
はじめに
前置きはさておき、近年、自然言語処理(NLP)の分野は、ディープラーニングの進化とともに大きく変化しています。初期の深層学習アプローチではリカレントニューラルネットワーク(RNN)に焦点を当てていましたが、2017年の「Attention Is All You Need」という論文の登場により、それまでのアーキテクチャとは全く異なるTransformerアーキテクチャが覇権を握ることになります。しかし、Transformerアーキテクチャにも問題点があり、特に長い文書を処理する際に計算資源が膨大になるという課題がありました。この課題に対処するために、様々な非Transformer系のアーキテクチャが提案されています。
このブログでは、Transformerの問題点を克服しつつ、その強みを活かした比較的新しいアーキテクチャ「Retentive Network(RetNet)」について掘り下げていきます。
基本的に、断りが無ければ原論文から引用しています。
RetNetの概要
RetNetは、Transformerの強力な特性を保ちつつ、上述の問題点に対処する新しいアーキテクチャです。RNNの時系列データを高速に推論する能力と、Transformerの並列計算可能なアテンションによる全トークン間の関係性を捉える能力を組み合わせることで、効率的な学習と推論(+パフォーマンス)を可能にします。
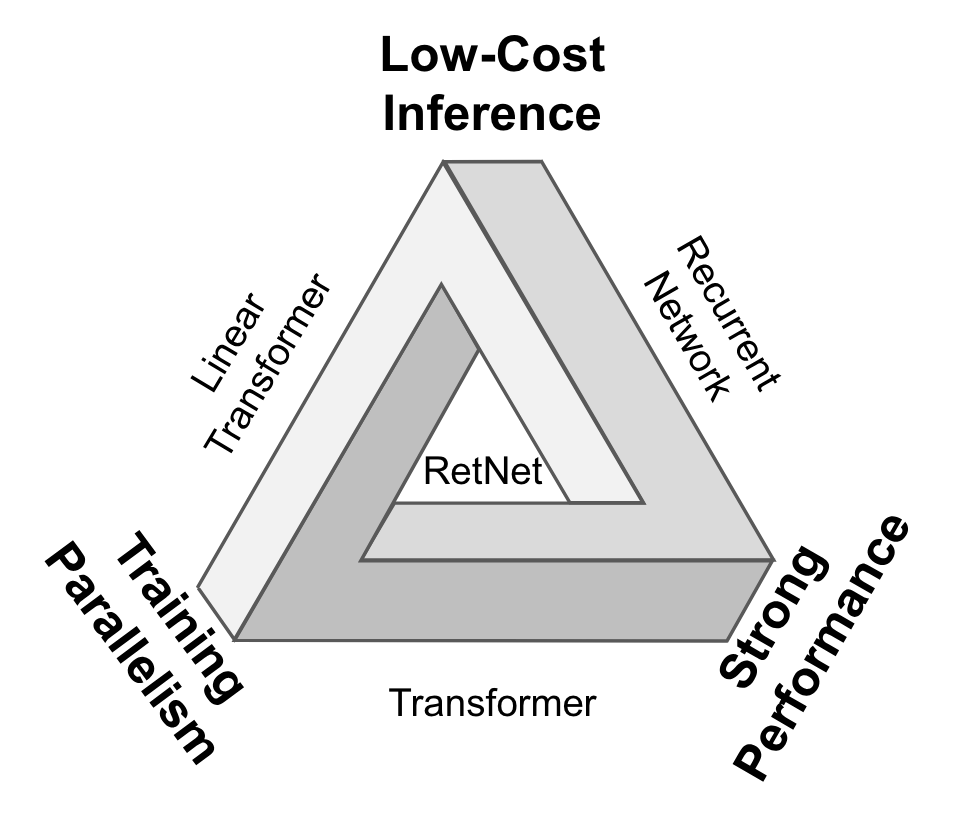
この論文のコアとなる提案 Retention機構について見ていきましょう。入力

出力
詳細は原論文に譲りますが、この中間状態を介した回帰形式から出発して、適当な仮定の下で式変形を行うと最終的に出力を行列形式で書き下すことができます。
これの何が嬉しいかと言うと、後に詳述しますが推論時には回帰的で省メモリな計算をしつつ、学習時には行列計算による高効率な並列計算が可能になるという、RNNとTransformerモデルのいいとこ取りができるということです。
並列表現
並列表現について詳しく見てみましょう。
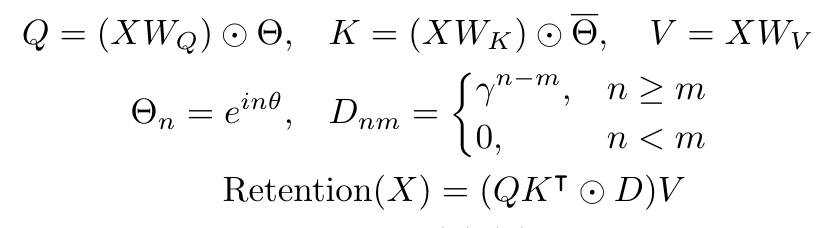
Retention

Attention (Source: All You Need Is Attentionより)
上がRetention機構で、下がAttention機構です。共役行列やSoftmaxなどの違いはあれど、アーキテクチャに関係なく、入力に対して動的に変化する
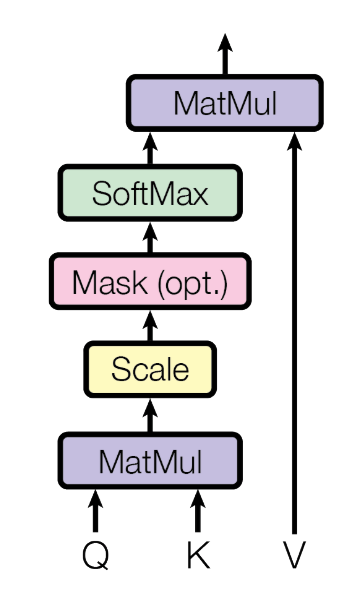
Source: Attention Is All You Need
Attention機構で提案されたような、クエリとキー間での演算をRetentionでも行っており、トークン間の関係性を捉えるような学習が可能であることを示唆していると考えられます。
回帰表現
次に、回帰表現について見てみましょう。

こちらは非常に単純で、キーバリュー演算と、前時刻の中間状態・減衰率の積の和が現時刻の中間状態になります。Retentionの計算結果はクエリとこの中間状態の積です。
Chunk-wise回帰表現
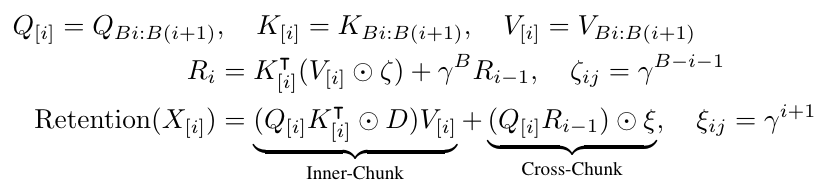
Chunk-wise回帰表現というものも提案されていて、入力をB個のチャンクに分解することで、チャンク単位での並列表現と回帰表現を実現することで、特に長い系列での学習時の効率が、計算速度やメモリ消費量の観点で改善されています。
Multi-Scale Retention (MSR)

TransformerではMHA(Multi-Head Attention)のようにAttention機構を複数保持していましたが、RetNetでも同様にRetention機構を複数保持したアーキテクチャになっています。ただし、RetNetでは各headで用いられる減衰率が異なるように設定されます(マルチスケール化)。Gated Multi-Scale Retentionの出力としては、各headのretentionの正規化下出力と、ゲーティングした残差接続との間で要素積を取り、射影変換したものとなります。
全体的なアーキテクチャ

l(エル)層目のデコーダーレイヤーは上のように書けます。MSRとFFNから成り、これを複数(例えば32層)積み重ねた構造をRetNetはしています。
RetNetの性能
次にRetNetが実際にどのような性能を持っているかを見てみましょう。

学習並列化
学習の並列化については、Transformer、RetNetともにできます。これは、先の並列表現のおかげですね。従来のRNNでは並列化ができないため学習効率が良くないです。
推論コスト
推論コストは、TransformerはAttention計算で最新のトークンのクエリと、過去と自身のキーに対する計算をする必要があるので、
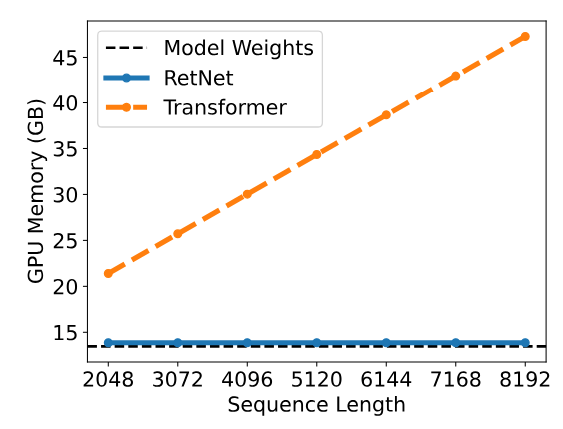
メモリ消費量
キャッシュは、TransformerがKVキャッシュとして
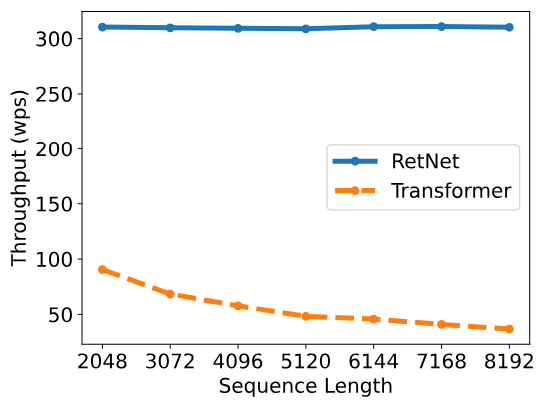
スループット
RetNetは系列長が増大しても、ほとんどスループットに変化はありません(そもそものスループットがすごいですね()
他の非Transformerアーキテクチャについて
Attention計算のデメリットを克服するためにRetNet以外にも様々な手法が提案されています。
ここでは、非Transformerアーキテクチャと便宜的に呼んではいますが、むしろTransformerの派生モデルというべきかもしれません。

RetNetと近しいモデルにLEX Transformerがあげられます。概要の方で、回帰表現と並列表現の同等性について触れましたが、その途中で出てくる表現が上の式です。これはxPosそのものであり、LEX TransformerではxPosを適用した
他にも、Linear AttentionやRWKV、S4、Mambaと言ったものが非Transformerとしてあげられます。
その他にも、Linear Attention、RWKV、S4、Mambaなどのアーキテクチャが非Transformerアーキテクチャとして提案されています。これらのモデルは、学習効率や推論効率を向上させることを目指しており、計算資源が限られた環境でも高性能な処理が可能です。
まとめ
現在、Transformer系のモデルが世界的に主流となっていますが、明示的に履歴を保持するAttentionは学習効率や推論効率が悪いことが課題となっており、計算資源が乏しい環境ではOpenAIやAnthropicのようなAPIを使わざるを得ない状況です。このような背景の中、RetNetのような新しいアーキテクチャが、NLPの分野に新たな可能性をもたらすかもしれません。
LLMエンジニアを募集しています!!
SpiralAIでは、生成AI×エンタメをテーマに様々なプロジェクトが立ち上がっています!最近では、マルチターン会話モデルを発表したりしています。
是非、ご興味があれば@ksterxや採用ページまでご連絡ください〜

Discussion