

こんにちは、@ken11です。
ご無沙汰している間に転職し、今はSpiral.AI株式会社というスタートアップにいます。
今日はそのSpiral.AIの記念すべき最初のエンジニアブログとして、ArgillaとSlackを使った生成モデルのブラインドテストの話をしたいと思います。
そもそもなぜブラインドテストが必要なのか?
ブラインドテストというのは、商品名などの情報を隠した状態で性能などを評価する手法ですが、わかりやすく言えば格付けチェックとかGACKTのいる部屋とかまあそんなようなやつです()

生成AIと昨今呼称されるもの、生成系の機械学習モデルというのは、そもそもその成果物(出力結果)を定量的に評価することが難しいです。
たとえば質問応答型の生成モデルがあったとして、次のような入力をしたとします。
入力:
日本の首都はどこですか?
これに対する出力結果が
出力:
東京です
だったとしましょう。
このとき、「正しい情報を回答する」ことがこのモデルの目的であればそれでよいと言えるかもしれません。
しかし、たとえば「面白いボケを回答する」ことを目的につくったモデルだった場合はどうでしょうか?その場合はこの出力内容では困るでしょう。
ではどういった出力内容だったら「面白いボケを回答する」ことを満たしていると言えるでしょうか?
それを評価するには「面白い」ことを定量的にはかる手法が求められますが、それは簡単なことではありません。なにを以て「面白い」と感じるかは人それぞれ違うからです。
このように定量的にはかることが困難なケースが生成系の機械学習モデルでは多いと思います。画像生成の場合でも「こういった画像がほしい」を定量的に表現して評価することは困難ではないでしょうか?
こういった場合に、定性的に複数モデルの優劣を評価する一つの手段として、ブラインドテストを用いる方法があると考えています。
ArgillaとSlackを使った生成モデルのブラインドテスト
では本題です。
我々は日々さまざまな生成系の機械学習モデルを作成していますが、それらの性能をはかるのにブラインドテストを行いたいケースが多々あります。
このブラインドテストは、単に生成結果をランダムにスプレッドシートに貼り付けて評価者に「良い」「良くない」をつけてもらう方法でもよいのですが、せっかくなので今回はArgillaを使ってブラインドテストを行うようにしてみました。
Argillaとは
Argillaとは、ヒューマン・イン・ザ・ループのような思想で、モデルの再学習・フィードバックループのためのアノテーションなどを効率的に行えるオープンソースのアプリケーションです。
現状はとても盛んに開発が行われており、どんどん機能が強化されている状況ですが、本来的にはこのArgillaにはブラインドテストを行う機能はありません。
しかし、その強力なアノテーションツールとしての機能を活用することで、ブラインドテストを効率化しようというのが今回の僕の試みです。
概要

※ブラインドテスト構成図絵
今回つくったのは画像のような仕組みです。
まず、ブラインドテスト用のデータ(評価対象のモデルによる生成結果)をCSVにして、Argillaにプッシュします。
プッシュされたデータに対して評価者となる人たちに評価してもらいます。
最後に、Slackから結果集計用のLambdaをキックすると、Argillaから結果を取得・集計し、Slackに最終結果が投稿されるといったものです。
では、ポイントを順番に説明します。
1. Argillaにプッシュする
まずは複数モデルによる生成結果をCSVにしてArgillaにプッシュします。
def main(args):
# load csv
# expected format
#
# question | model-name-a | model-name-b
# ---------|--------------|-------------
# ほげ | ふがふが | ぴよぴよ
#
df = pd.read_csv(args.csv_path)
column_names = df.columns.tolist()
model_names = column_names[1:]
# create labels
labels = []
for i in range(len(model_names)):
labels.append(f"answer-{i+1}")
questions = [
rg.RankingQuestion(
name="response_ranking",
title="面白さでランキング付けしてください",
required=True,
values=labels,
)
]
fields = []
fields.append(rg.TextField(name=column_names[0], required=True))
for label in labels:
fields.append(rg.TextField(name=label, required=True))
dataset = rg.FeedbackDataset(
guidelines="Please, read the prompt carefully and...",
questions=questions,
fields=fields,
)
# create records
records = []
for index, row in df.iterrows():
# shuffle and mask answers
tmp_keys = copy.deepcopy(model_names)
random.shuffle(tmp_keys)
shuffled_dict = {}
shuffled_dict[column_names[0]] = row[column_names[0]]
for i, label in enumerate(labels):
shuffled_dict[label] = row[tmp_keys[i]]
models = {}
for i, tk in enumerate(tmp_keys):
models[f"model-{i+1}"] = tk
records.append(
rg.FeedbackRecord(
fields=shuffled_dict,
metadata={"models": models},
)
)
dataset.add_records(records)
dataset.push_to_argilla(name=args.dataset, workspace=args.workspace)
まず、今回は RankingQuestion を使って評価をしていきます。
RankingQuestion は、ある質問に対する回答を「回答-1」「回答-2」「回答-3」のようにならべて、それぞれにランキング付けできるものです。もともとのArgillaではRLHFなどで使うことを想定していると思いますが、今回はブラインドテストにこの機能を使います。
次に、ポイントとなるのはモデル名をマスクしてシャッフルしている点です。
ブラインドテストなのでモデル名は隠さないといけませんが、結果集計時にはモデル名を知りたいのでうまく隠蔽していく必要があります。また、常に回答の順番が同じでは評価者が気づいてしまったりしてよいテストにならないので、回答順をシャッフルしていく必要があります。
これらを行っているのが後半のレコード作成の処理の部分です。
隠したモデル名をあとで復元する手段として、 FeedbackRecord の metadata フィールドを使い、ここに元のモデル名を埋め込んでいます。
2. Slackで集計をキックする
本来であれば対象の評価者が全員評価を終えたところで自動的に集計・通知するのが理想ではありますが、評価者が固定でない場合や人数が多く全員が必須ではない場合など、集計が必要になるタイミングは実運用上まちまちになるというのをふまえ、今回は集計が欲しくなったらSlackからキックする方法を選択しました。
キックにはSlackのスラッシュコマンドを利用しており、
/summary workspace dataset
のような形で呼び出せるようにしています。
3. 集計
続いて、Lambda上で動いている集計用のスクリプトです。
def main(args):
RANK_SCORE = [5, 2, 1]
OFFSET = 1
rg.init(
api_url=os.environ["ARGILLA_API_URL"],
api_key=os.environ["ARGILLA_API_KEY"],
)
feedback = rg.FeedbackDataset.from_argilla(args.dataset, workspace=args.workspace)
models = {}
for record in feedback.records:
# init models
for v in record.metadata["models"].values():
if models.get(v) is None:
models[v] = 0
if record.responses:
for res in record.responses:
for v in res.values["response_ranking"].value:
models[
record.metadata["models"][f"model-{v.value.split('-')[1]}"]
] += RANK_SCORE[int(v.rank) - OFFSET]
highest_score = max(models.values())
winners = [model for model, score in models.items() if score == highest_score]
post_slack(models, winners)
FeedbackDataset.from_argilla で先ほどプッシュして評価者が評価済みのデータセットを取得してきます。
取得してきたデータセットには、元のプッシュしたデータの内容に加えて評価者による評価内容も含まれているので、これを集計していきます。
ポイントとしては、先ほどプッシュした際に付与した metadata を元にモデル名を復号しながら、それぞれのモデルが何ポイント獲得しているか集計する点です。
また、単純に1位に選ばれた回数で比較してもブラインドテストとしては十分ですが、評価者が多い場合などのために今回はボルダルールを採用しています。
ただ、ボルダルールに関してはチーム内からも「2位以下のモデルが全然ダメで話にならないケースでも得点が入ってしまうのはいかがなものか」といった声もあがっており、今後よりよい集計方法を模索していきたいと考えています。
仕上がり
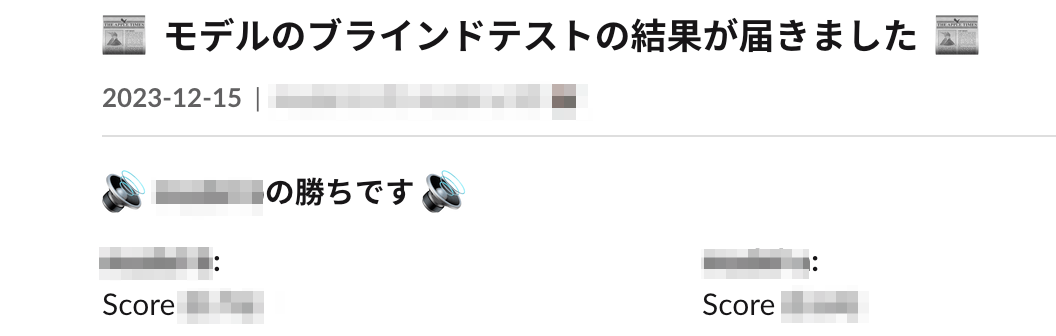
こんな感じでSlackに通知が来るようになりました。
なによりいちいち人手で集計しなくて済むのはとても楽です。
Argilla本来の使い方からは逸れているかもしれませんが、ブラインドテストのために自前でなにかつくるのも嫌だったのでとても助かりました。
これを使ってどんどん生成モデルのブラインドテストを進めていきたいと思います。
まとめ
今回は、Spiral.AI株式会社内で最近やったこととして、ArgillaとSlackを使った生成モデルのブラインドテストについてご紹介しました。
ArgillaはHuggingFaceのSpacesでも気軽にホスティングできるので、とても便利なツールだと思います。
今回は本来と少し違う使い方をしていますが、弊社では本来の用途でもガンガン活用しています。
最近ではLLMOpsなんて言葉も出てきていますが、まさにそのLLMOpsに欠かせないツールの一つといってもよいのではないかと僕は考えています。
そんな感じで、僕は相変わらず機械学習まわりで活動しております。
Spiral.AIも今年できたばかりの会社ですが、非常に活気があって楽しい現場なので、興味があればいつでもお声がけください。
それでは、みなさまよいクリスマスをお過ごしください!

Discussion