SQL学び直し
DML
DATA MANIPUlATION LANGUAGE
SELECT
SELECT
カラム名
FROM
テーブル名
WHERE
条件式;
INSERT
INSERT
INTO
テーブル名
(
COLUMN1 -- 論理名
, COLUMN2 -- 論理名
, COLUMN3 -- 論理名
) VALUES ( -- VALUES句という
VALUE1
, VALUE2
, VALUE3
)
- すべての値を選択する場合は、カラム名は省略できる
UPDATE
UPDATE
テーブル名
SET
カラム = 値
WHERE
条件式;
DELETE
DELETE
FROM
テーブル名
WHERE
条件式;
EXPLAINE
EXPMAIN SELECT ~ とか
出力された結果に対して確認ポイント(一例)
-
「Type」 結合型
- 結果が「ALL」deあった場合、善行が読み出されているので、フルテーブルスキャンが意図的かを確認する
-
「Key」選択したインデックスを返す
- インデックスがきいていないと「NULL」が帰ってくる
-
Extra 追加情報
LOCK TABLE
LOCK TABLE テーブル名 IN モード名 MODE (NOWAIT)
- モード名
- EXCLUSIVEで排他
- SHAREで共有ロック
SHOW
LOAD DATA INFILE
DDL
DATA DEFINITION LANGUAGE
CRATE
CREATE
TABLE
(
カラム名 型;
)
ALTER
ALTER
TABLE
テーブル名
ADD
カラム名 型;
ALTER
TABLE
テーブル名
DROP
カラム名;
DROP
TRANCATE
DCL
DATA CONTROL LANGUAGE
GRANT
権限をつける
GRANT 権限名 TO ユーザ名
REVOKE
権限を外す
GRANT 権限名 FROM ユーザ名
TCL
TRANSACTION CONTROL LANGUATE
COMMIT
ROLEBCK
SET TRANSACRION
SAVEPOINT
コメント
--
/* */
セミコロン
;をつかうとそこまでを文の終わりとして扱う。
これによってSQLがそこで終わることを明示的にしますが、
単一のSQLであることが明らかな場合、エラーになる場合もあるので、
つけないほうがいい(取り決め次第)
- 予約語は大文字で書く
- オブジェクト名、カラム名も大文字が良い
- 1 行につき、1 文のみ
- ヘボン式ローマ字で日本語は統一
- 短縮形
- 外来語 => 言語の短縮形、短縮形が存在しない場合は母音を抜かす
- ローマ字 => 短縮は単語の区切れの頭文字、または母音を抜かした子音字
- テーブルエイリアスをつける。エイリアスは副問合せを行う場合、重複しないようにする
- 文字コードはUnicode UTF-8
SQLの整形
- 予約後は左揃え
- WHERE句の条件式の位置は揃える
- 物理カラム名、テーブル名に対応する論理名を入れる場合、その後ろに単数行コメント(-- )にて記述する。
-, カンマとANDは各行の先頭に -
; セミコロンはSQLフレームワークでは記述しない
- SQLに直接記載される値のことをリテラルという
- TEXT型は使わない
- VARCHAR(MAX)で代替する
- CHAR(n)はnに満たない文字数はパディングされる
-
asでエイリアスをつける- テーブルエイリアス
- Oracle DBでは テーブルエイリアスを付ける場合はasの付与がいらない
- カラムエイリアス
SELECT A_COLUMN as TARGET FROM HUGA_TABLE as HUGA - テーブルエイリアス
- DATE型には時刻情報が付与されていないので、日付・時刻の比較の際は、型をケアすること
WHERE句
- SELECT/ UPDATE / INSERT/ DELTEは where句の結果がTRUE(真)となった行に対して実行される
- 比較演算子
| 比較演算子 |
|---|
| = |
| < |
| > |
| <= |
| => |
| <> <= not equal |
NULLの判定
- 何も格納されていない、未定義の状態
- 数字のゼロや空白文字とは異なる
- NULLの判定には
=や<>は使えない -
IS NULL演算子、IS NOT NULL演算子を使う -
VALUE <> HUGAなどの判定にはNULLが含まれない
- NULLと比較を行った結果はTRUE/FALSEではなくUNKNWONとなる
- これが3値論理
LIKE演算子
-
%任意の0文字以上の文字列 -
_任意の1文字 - ESCAPE句を使うと、
%、_自体を演算の値として利用できるLIKE '%100$%' ESCAPE '$'
BETWEEN演算子
値1以上かつ値2以下
BETWEEN VAL1 AND VAL2
- BETWEENのほうが処理性のが悪いこともある
IN/ NOT IN演算子
=演算子の複数バージョン
IN ( 値リスト )
IN
(
VAL1
, VAL2
, VAL3
)
ANY/ ALL 演算子
- 比較演算子のあとに使う。
- 値リストと比較を行った結果を使う
-
ANY: 値リストのうちいずれか1つとの比較演算子の結果を満たす場合 -
ALL: 値リストすべてと、比較演算子の結果を満たす場合 - 式や副問合せと組み合わせて使う
式 比較演算子 ANY/ALL ( 値リスト )
-
NOT INは<> ALLと一緒 -
INは= ANYと一緒
演算子の優先順位
- 優先順位は以下の通り
- NOT
- AND
- OR
-
()で囲むのが可読性も高く、認知負荷も低い
キー
- 主キー(primary key)
- 自然キー(natural key)
- 主キーの役割を果たせる列
- 代替キー/代理キー(サロゲートキー)
- 管理目的のための人為的に追加されたキー
- 自然キー(natural key)
- 複合主キー(compund key)
SELECTの加工
DISTINCT
- 重複行を除外する
SELECT
DISTICT
列名...
FROM
テーブル名
- SELECTのすぐ後ろに記載すること
ORDER BY
- 値を並べ替える
- 複数指定できる
- 並び順は省略すると昇順になる。(基本的にはつけたほうがいい)
SELECT
列名...
FROM
テーブル名
ORDER BY
列名 並び順(ASC/DESC)
, ...
- 列番号でもできる(あんまり使わなさそう)
- SELECTで指定した列を順に番号が対応する
- 指定するカラムが変わると対象がずれるので注意が必要
- SELECTで指定した列を順に番号が対応する
SELECT
列名...
FROM
テーブル名
ORDER BY
列番号 並び順(ASC/DESC)
, ...
OFFSET/FETCH
※ MySQL, MariaDB, SQLiteではサポートしていない
- 先頭から数行取るときに使う
- TOP いくつ、とかを出すので
ORDER BYと組み合わせて使う -
ORDER BYで順序を担保する必要がそもそもある
- TOP いくつ、とかを出すので
-
OFFSET: 読み捨てる行の数 -
FETCH: 読み込む行数
SELECT
列名
, ....
FROM
テーブル名
ORDER BY
列名 並び順
, ...
OFFSET 先頭から除外する行数 ROWS
FETCH NEXT 取得行数 ROWS ONLY -- 指定しない場合は記載しなくてもいい
代替
LIMIT
ORDER BY カラム名 並び順 LIMIT 呼び出し数 OFFSET オフセット数 ROWS
ROW_NUMBER
SELECT ....
FROM
(
SELECT
*
, ROW_NUMBER()
OVER
(
ORDE BY
カラム名 並び順
)
FROM
テーブル名
)
集合演算子
-
UNION: 和集合 -
EXPECT(MINUS): 差集合 -
INTERSECT: 積集合
※SELECTした列リストが一致していないと集合演算子は使えない
=> どうしても使いたい場合は、NULLカラムを追加して数を一致させる方法もある
UNION
-
ALLを使うと、重複行をそのまま返す- パフォーマンス的に`ALL
-
TODO: 理由を記載する
-
- パフォーマンス的に`ALL
SELECT 文1
UNION (ALL)
SELECT 文2
ORDER BY
列番号 並び順 ro 列名 並び順
- UNIONを使うと、1つのテーブルに格納されたデータを複数の異なる条件で抽出するケースでも使える。
- これをやると、発行するSQLの数を減らせる
- ORDER BYで列番号を使わない場合は、1つ目のSELECT文のものを利用する
EXCEPT(MINUS)
- oracle DBでは
MINUS - 差集合なのでSELECT文の順序が大事
- 文1の集合のうち、文2にも所属する集合を除外した集合 = 差集合
SELECT 文1
EXCEPT ALL
SELECT 文2
INTERSECT
- 積集合
SELECT 文1
INTERSECT (ALL)
SELECT 文2
選択列リスト
- SELECTの後ろを選択列リストという
- 選択列リストには以下を指定できる
- 列名: 列の内容が出力
- 計算式: 計算の評価結果が出力
- 固定値: 固定値がそのまま出力
SELECT
出金額 --列名の指定
, 出金額 + 100 --計算式での指定
, 'SQL' --固定値の指定
-
計算式での選択列リストはエイリアスをつかうとよい
-
計算式の利用
-
UPDATE,INSERT文でも利用可能
-
-
日付リテラルは数値との
+-で日数の新体を行える -
文字列 || 文字列で文字列を連結できる-
文字列 + 文字列のDBMSもある
-
CASE演算子
条件に合わせて値を変更する
- 構文1
CASE
評価する列や条件式
WHEN
想定する値
THEN
TUREのときに返す値
WHEN
想定する値
THEN
TUREのときに返す値
ELSE
FLASEのときに返す値
END
- 構文2
CASE
WHEN
条件式
THEN
TUREのときに返す値
WHEN
条件式
THEN
TUREのときに返す値
ELSE
FLASEのときに返す値
END
以下のような、行でみた場合、特定のカラムの値に応じて、動的な値を挿入したカラムを付与したいときなどに使うとよい。
SELECT
費目
, 出金額
, CASE
費目
WHEN
'居住費'
THEN
'固定費'
ELSE
'変動費'
END AS 分類
FROM
家計簿
関数
DBMSによって関数は違う
関数はインデックスが効かなくなる可能性があるので、検証をちゃんとすること
ストアドプロシージャ
DB内部の保存したDBの外部から呼びだす手順
主に多数のSQL文からなる処理を1つのストアドプロシージャにまとめて
ネットワーク負荷を減らしたりする
文字列操作
長さ
- LENGTH/LEN( SQL Server)
トリム
-TRIM/LTRIM/RTRIM
置換
- REPLACE(列, target, replaced)
抽出
- SUBSTRING/SUBSTR
- SUBSTRING(文字列を表す列, 抽出を開始する位置, 抽出する文字の数)
- SUBSTR(文字列を表す列, 抽出を開始する位置, 抽出する文字の数)
※抽出する文字の数を指定しないと最後まで
連結
- CONCAT(文字列, 文字列[, 文字列 ]) => 連結後の文字列
- NULLが1つでもあるとNULLをDBMSもある
- 3つ以上連結できないDBではこんな感じ
SELECT CONCAT(費目, ':' || メモ) FROM 家計簿
数値操作
指定桁で四捨五入
- ROUND( 数値を表す列, 有効とする桁数) -> 四捨五入した値
- ROUND(出金額 , -2) 下2桁目で四捨五入する、という意味
指定桁で切り捨てる
-TRUNC( 数値を表す列, 有効とする桁数) -> 切り捨てした値
べき乗を計算
- POWER( 数値を表す列, 指数値)
日付
現在のDATE型リテラル
- CURRENT_DATE
- 引数が不要なので、後ろの()もいらない(つけるとエラー)
現在のTIME型リテラル
- CURRENT_TIME
現在のTIMESTAMP型リテラル
- CURRENT_TIMESTAMP
変換
- CAST(列, AS 型)
NULL時の処理
最初にNULLでなかった値を返す関数、つまり、第一引数がNULLだったらときのデフォルト値のような使い方ができる
- COALESCE(列や式や値, 列や式や値, [列や式や値, ...])
集計関数
SUM/MAX/MIN/AVG/COUNT
NULLは無視される。すべてNULLの場合は、NULLが返る(COUNTは0が返る)。
COUNT(*)は NULLを含んでカウントする。
- レコード数を数える場合はCOUNT(*)を使う
- COUNT(1)・COUNT('X') ・COUNT(KEY1)という記載はしないほうがいい
-以下のように書けばNULLをゼロ埋めできる
SELECT
COUNT(COALESE(列, 0) as 集計
FROM
テーブル
- 集計をグループに分ける(グループ化)
- グループ化は複数を設けられるが、 基準列名が左からグループ化される
- グループ化したあとはHAVINGで絞り込み
- 選択列リストに指定できるのは、グループ化の基準列 か集計関数の対象のみ。(そうしないと列がボコボコになるので)
SELECT
グループ化の基準列名
, 集計関数 as 集計項目名
FROM
テーブル名
(WHERE)
GROUP BY
グループ化の基準列名
HAVING
条件( 集計項目名の条件を書く事が多い)
副問合せ
ネスト構造、入れ子、副照会、サブクエリ
副問合せのパターン
- 単一の値を抽出する副問合せ: スカラ値
- 複数値が返される副問合せ: ベクター値
- 表形式の複数値が返される副問合せ: マトリックス値
スカラ値
SET句で利用する例
UPDATE
テーブル
SET
列名 = (
SELECT 集計関数 FROM .....
)
選択列リストで利用する例
SELECT
列1
, 列2
, (
SELECT 値 FROM ......) -- 集計関数などを利用しない場合、スカラ値にならない可能性があるクエリは避けるべし
ベクタ値
INで利用する例
SELECT * FROM テーブル WHERE 項目 IN (SELECT DISTICT 費目 FROM 家計簿)
ANY, ALLで利用する例
SELECT * FROM テーブル
WHERE 出金額 < ANY(SELECT 出金額 FROM 家計簿)
- ANY/ALLを使えば 複数行が帰ってくる可能性がある副問合せでも、擬似的に WHERE 出金額 < 値 をつくれる。
NOT IN 演算子の候補を副問合せで作ろうとすると、値にNULLを含むとすべてNULLとなるので注意
NOT IN ( A, B , NULL) -- これは常にNULL
つまり、副問合せはNULLを許容しないようなクエリにすべし
-
WHERE IS NOT NULLCOALESCEを使う
ORACLE DBでは
WHERE (A, B) IN (SELECT C< D, FROM ~) のようなマトリックス値でも条件式にできる
マトリックス値
FROM句で使う( テーブルの代替をマトリックス値にする)
SELECT SUM(SUB.出金額) AS 合計出金額合計
FROM (SELECT )
※ FROM句での副問合せは別名をつけるのが必須のDBMSもある。
INSERT文で利用する
INSERT
INTO
テーブル名
SELECT
このケースはVALUESの指定がいらない。副問合せではなく、INSERTの特殊構文
相関副問合せ
- 副問合せでは、外側のSQL文(主問い合わせ)とは独立している
- 相関副問合わせでは、主問い合わせの列要素などを利用できる
- よくある例が「他のテーブルに値が登場する行のみ抽出したい」
SELECT
列
FROM
テーブル1
WHERE
EXISTS (
SELECT
1
FROM
テーブル2
WHERE
テーブル1.列 = テーブル2.列
)
- 通常の副問合せと異なり、相関副問合せでは、副問合せ1回⇢主問い合わせ1回を繰り返すので、負荷がかかる
- なのでSELECT * はつかわず、
1をつかう - EXISTS句は WHERE EXISTS (副問合せ) が存在した場合のみ実行する のような使い方をする
テーブルの結合
SELECT
列選択リスト
FROM
テーブルA as A
JOIN
テーブルB as B
ON
結合条件 ( A.X = B.X)
-
左表(FROMに指定したテーブル)にどういった列を追加するかを(行を繰り返し突合することを)結合と呼ぶ
-
内部的には、以下のSQLを繰り返し投げて、1行を1つづつ、つないでいる
-
SELECT * FROM 右表(JOINに指定したテーブル) WHERE 結合条件 -
INNER JOIN (内部結合)
- 結合相手の行がない、条件列がNULLの場合、結合しない
-
OUTER JOIN (外部結合)
- 結合相手の行がない、条件列がNULLの場合、も含めて結合する(たりないところは全部NULLにする)
- どちらの表か(つけないとLEFT)
- LEFT
- RIGHT
- FULL
※ INNERは ANDなので FULLとはかない
-
FULL JOINはUNIONで代用できる
- MySQLやMariaDBでは FULL JOINが利用できないので
SELECT 選択列リスト FROM テーブル
LEFT OUTER JOIN 右表
ON 左表の結合条件列 = 右表の結合条件列
UNION
SELECT 選択列リスト FROM テーブル
RIGHT OUTER JOIN 右表
ON 左表の結合条件列 = 右表の結合条件列
- JOIN は以下のように3つ以上重ねることもできる
SELECT 日付, 費目 .名前, 経費区分.名称
FROM 家計簿
JOIN 費目
ON 家計簿.費目ID = 費目.ID
JOIN 経費区分
ON 費目.経費区分ID = 経費区分.ID
- 副問合せの結果も結合できる
SELECT 日付, 費目 .名前, 経費区分.名称
FROM 家計簿
JOIN ( SELECT) as 費目 -- マトリックス値を返す
ON 家計簿.費目ID = 費目.ID
- 同じテーブル同士を結合
- 自己結合(self join)、再帰結合(recursive join)
- 一つのテーブルの中で、行(タプル)間の意味的関連をもつ、列をつなげるのに使う。
SELECT 日付, メモ, 関連日付, B.メモ
FROM 家計簿
JOIN 家計簿 as B -- テーブルに別名をつける
ON 家計簿.関連日付 = B.日付
- 一部のDBではJOINを使わないでかけるが、チームの取り決めに従うべし
SELECT 選択列リスト
FROM
テーブルA, テーブルB
WHERE
両テーブルの結合条件
``
- 一部のDBでは外部結合を(+)でつけられるが非推奨とのこと
- 以下はRIGHT OUTER JOIN
```sql
SELECT 選択列リスト
FROM
テーブルA, テーブルB
WHERE
テーブルAの結合条件 = テーブルBの結合条件(+)
``
トランザクションデータ
原子性(atomicity)
-
トランザクションにおいて、一部の更新処理だけが、実行されることはNG
- 分割不可能な単位をトランザクションとする(べき)
-
そこでコミットとロールバック
- BIGIN : 以降のSQL群を1つのトランザクションとする
- COMMIT: ここまでのSQL群を1つのトランザクションとして、変更を確定する
- ROLLBACK: ここまでのSQL群を1つのトランザクションとして、明示的にROLLBACKする(最新のCOMMITまで戻す)
- データが更新できるか、の確認だけにつかう??
-
SAVEPOINT: ROLLBACK先をトランザクション内に設ける
-SAVEPOINT SP_UPD1;で作成
-ROLLBACK TO SAVEPOINT SP_UPD1; -
最近のツールは自動コミットされるので、
- BEGINをつけて自動コミットを解除する
- MySQLでは
SET AUTOCOMMIT=0という SQLを実行する
分離性(Isolation)
同時実行のサイドエフェクト
- ダーティーリード
- 未確定の変更を他者が参照できてしまう
- 反復不能読み取り(non-repeatable update)
- 更新をかけていないのみSELCTの実行結果がトランザクション内で異なる
- 間にUPDATE文を他者に投げられてしまう
- ファントムリード
- 更新をかけていないのみSELCTの実行結果がトランザクション内で異なる(行数が増える)
- 一回目の結果の行数に依存する処理がおかしくなる
- 間にINSERT文を他者に投げられてしまう
トランザクションの分離レベル
- READ UNCOMMITED
- READ COMITTED
- REPEATABLE READ
- SERIALIZABLE
| 分離レベル | ダーティーリード | 反復不能読み取り | ファントムリード |
|---|---|---|---|
| READ UNCOMITTED | 恐れアリ | 恐れアリ | 恐れアリ |
| READ COMITTED | 発生しない | 恐れアリ | 恐れアリ |
| REPEATABLE READ | 発生しない | 発生しない | 恐れアリ |
| SERIALIZABLE | 発生しない | 発生しない | 発生しない |
上ほど高速、下程安全
SET TRANSACTION LEVEL 分離レベル名
SET CURRENT ISOLATION 分離レベル名
どっちかを使う
DBMSによっては利用可能なレベルが異なる
- ORACLE DBはREAD COMMITED/ SERIALIZABLEしか選択できない(DEFAULTはSERIALIZABLE)
- ORACLE DB/ PostgreSQLは分離レベルとして READ UNCOMMITTEDが存在しない
- DBとしてコミットされていない情報は読めないようになっているため
- 書き換え済みと書き換え前の2つのバージョンを併存させる並列実効制御(MVCC: mutil version concurrency control)がされている
トランザクション中のロック
-
排他ロック
- データの更新時
-
共有ロック
- データの参照時
-
明示的なロック
- 行ロック: 特定の1行をロック
- 表ロック: テーブル全体をロック
- ページロック
- 表ロック
- データベースロック
-
明示的な行ロック
行ロック-
SELECT ~ FOR UPDATE (NOWAIT)-
NOWAITをつけると即時エラー終了して、ロックが解除されるのを(他のクエリに)待機させない
-
-
表ロック
- `LOCK TABLE テーブル名 IN モード名 MODE (NOWAIT)
- モード名
- EXCLUSIVEで排他
- SHAREで共有ロック
- モード名
デッドロック
- DBMSは内部にでデッドロックを検知し、自動で解除する機能があるが、
- ロックをかける順番を統一することで、発生する可能性をなくせる
ロックエスカレーション
- Bd2, SQL serverなどでは、複数の下位レベルのロックが発生すると負荷が増えるので、上位のロックに変更するような機能があるが、デッドロックが発生する可能性があるので、発生条件を細かく設定したり、明示的に禁止することも可能
2層コミット(2フェーズコミット)
- データベースA,データベースBに分けて情報を記載しるうときに、片方がダウンするうと、データの整合性が取れなくなってしまうケースなどでつかう。双方のデータベースに対して、確定準備と確定の2段階の支持でコミットを行うことで原子性を担保する。

テーブルの作成
- CREATE TBALE
CREATE TABLE テーブル名 (
列名 型
, 列名 型 DEFAULET デフォルト値
, 列名 型 NOT NULL
, 列名 型 CHECK(条件式)
, 列名 型 UNIQUE
, 列名 型 PRIMARY KEY
, 列名 型 REFERENCES テーブル名(列名)
,
PRIMARY KEY (列名, [列名, ...])
FOREIGN KEY (参照元列名) REFERENCES 参照先テーブル名(参照先列名)
)
テーブルの削除
- DROP
DROP (IF EXISTS)TABLE テーブル名
列の追加/削除
ALTER TABLE テーブル名 ADD 列名 型 成約
ALTER TABLE テーブル名 DROP 列名
※ DDLはDBMSによってはロールバックできない
データの全件削除
DDLに属するので高速、ロールバックできない。DMLのDELETEはログを残すので
ロールバックできる
TRUNCATE TABLE テーブル名
インデックス
CREATE INDEX インデックス名 ON デーブル名(列名), [デーブル名(列名), ....]
DROP INDEX インデックス名 (ON デーブル名)
複数の列を指定する複合インデックスも可能
インデックスによって高速化できるケース
基本的には等価評価(=演算子)
- WHERE句での完全一致検索
WHERE インデックスを貼った列名 = 値
- WHERE句での前方一致検索
WHERE インデックスを貼った列名 LIKE 'PREFIX%'
後方一致、中間一致はインデックスが効かないので使わない
- ORDER BY
- JOINの結合条件になるカラム
インデックス作成によるデメリット
- 検索情報を保持するのでディスク容量をつかう
- テーブルのデータが更新されるとインデックスを再作成する必要がある
- 更新分の処理時間がふえる
ビュー
CREATE VIEW ビュー名 AS セレクト文
DROP VIEW ビュー名
ビューを参照するときは、SELECT文が発行されている
マテリアライズドビューでキャッシュされているケースもある
採番
- 自動で連番を振る
各DBMSにはオートインクリメントの列を設定できる。
- 当たり前だが、使うときはINSERTで当該表は含めない
PRIMARY KEYとかにも使う
-- MySQL、MariaDB
CREATE TABLE テーブル名 (
ID INTEGER PRIMARY KEY AUTO_INCREMENT
)
-- PostgreSQL
CREATE TABLE テーブル名 (
ID SERIAL PRIMARY KE
)
2) シーケンスをつく合う
CREATE SEQUENCE シーケンス名
DROP SEQUENCE シーケンス名
-- ORACLE
SELECT シーケンス名.CURRVAL FROM DUAL;
SELECT シーケンス名.NEXTVAL FROM DUAL;
-- PostgreSQL
SELECT CURRVAL('シーケンス名')
SELECT NEXTVAL('シーケンス名')
-- こんな感じで副問合せと一緒に使うと良い
-- PostgreSQLの例
INSERT
INTO
IDを使うテーブル名
(
ID
, 名前
)
VALUES
(
(
SELECT
NEXTVAL('費目シーケンス')
)
)
3)その他
INTEGER型かつ主キー制約の列にNULLをいれるとIDがつく、みたいなDBMS独自機能もある
※ 現在のIDの最大値をテーブルから取得して、IDをクライアント側で決めるのは非推奨
- テーブルのロックが必要
- 採番したID行を削除したあとに、同一のID行が使われてしまう
※ダミーのテーブル
DUAL, SYSIBM.SYSDUMMY1 など
データを安全に使う
- コミット、ロールバック
- テーブルの型、制約
- 分離レベル、ロック
- ACID特性
- Atomicity(原子性)
- 処理は完了するか、初期の状態か
- Consistency(一貫性)
- データの内容が矛盾しない、 いつ行っても同じ結果になる
- Isolation(分離性)
- 複数の処理を同時に実行しても副作用がない
- Durability(永続性)
- データは保持される
- Atomicity(原子性)
バックアップ
- 差分バックアップ
- フルバックアップ
ログファイル
- トランザクションログ、REDOログ(アーカイブログ) という
- それまでに実行したSQL文が乗っているので、あとから同一手順を踏むことで復元できる
ロールフォワード
- 残っているバックアップを開始点として、ログファイルのSQLを実行することで復元できる
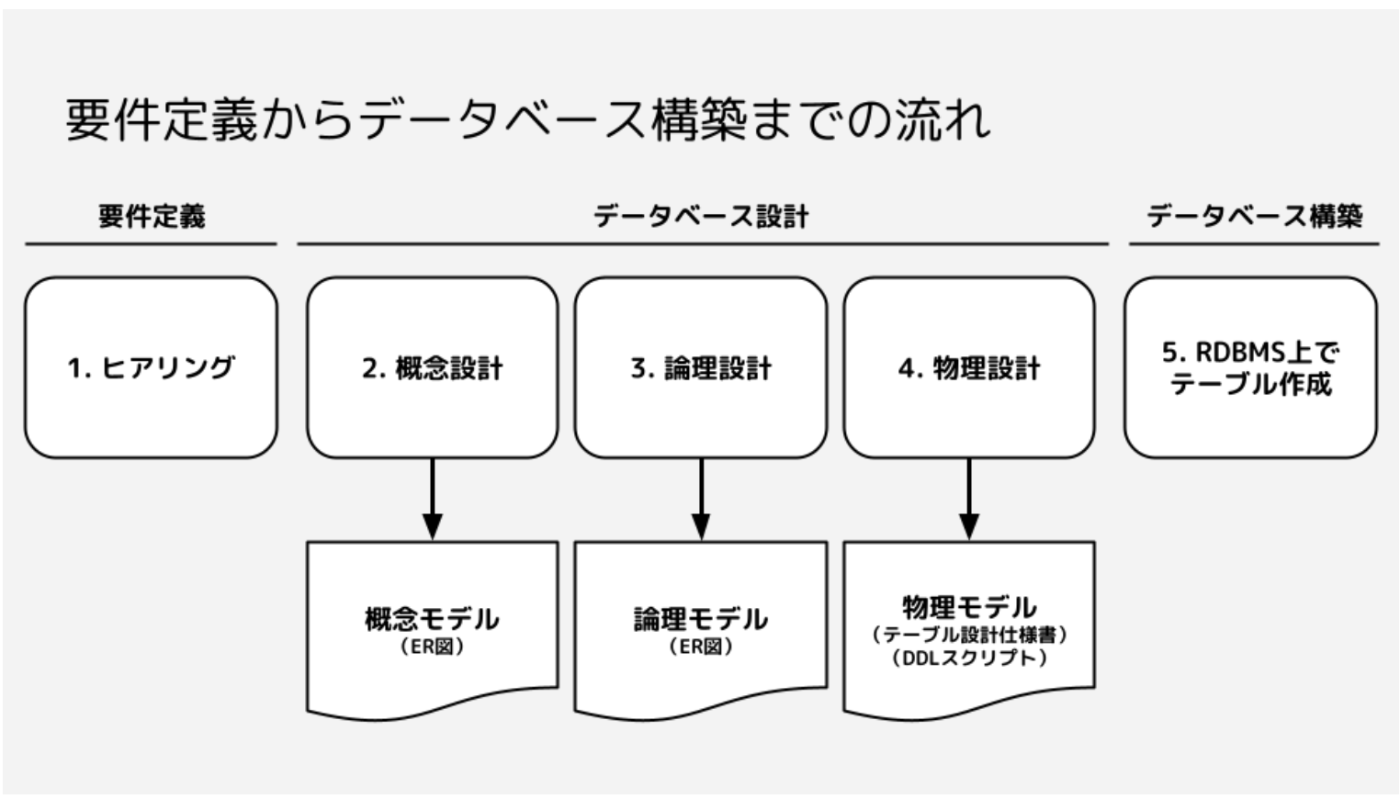
データベースの設計作業
より良いテーブル設計は「1つの事実は1箇所に( one-fact in one-place)」
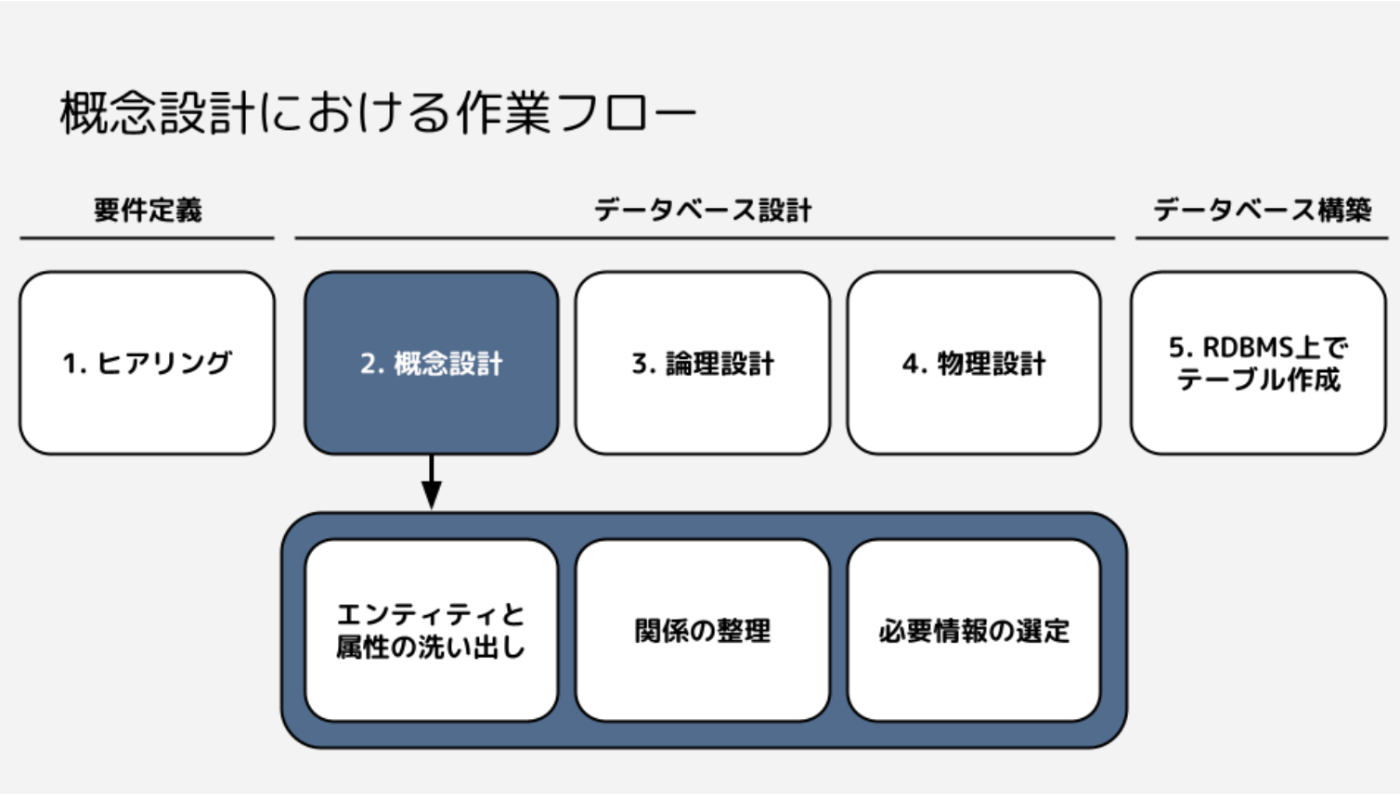
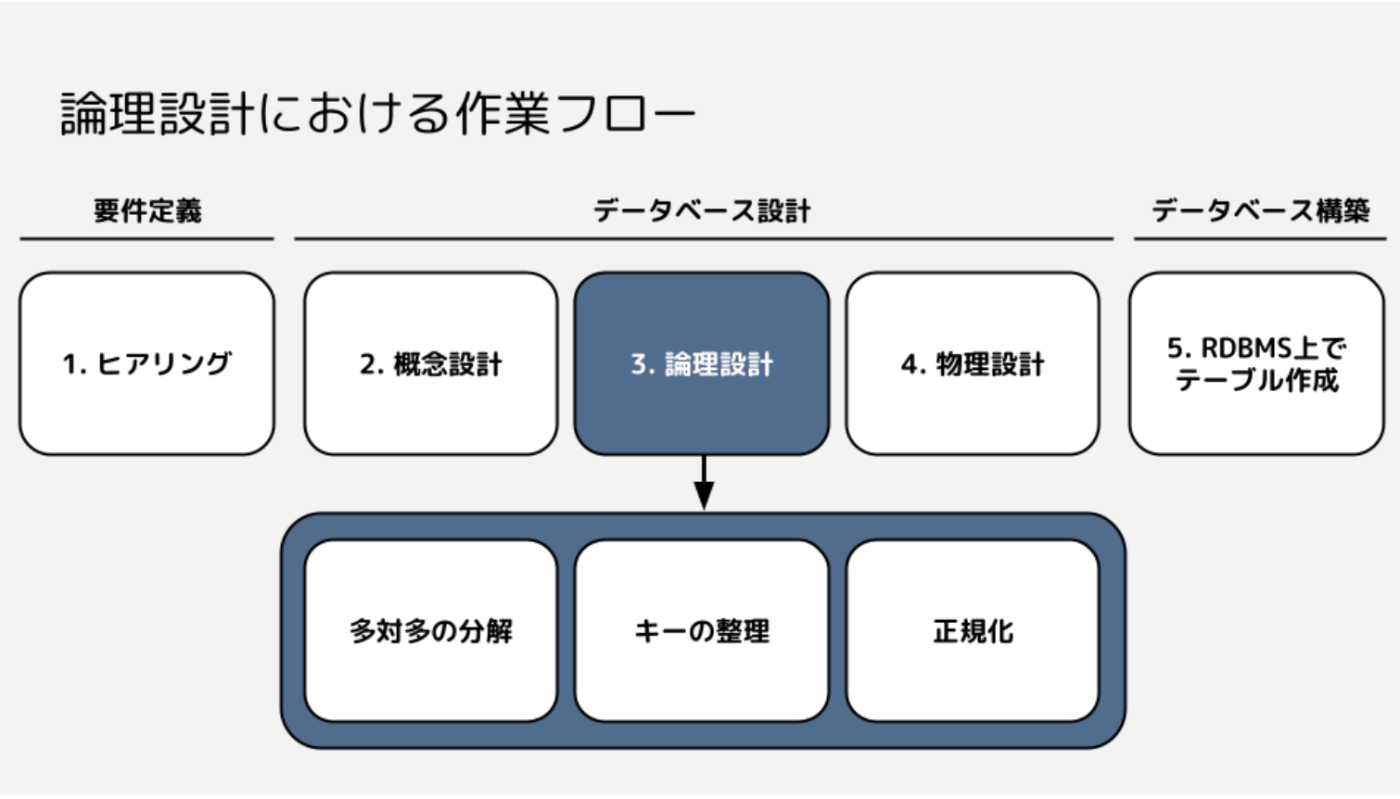
設計のアウトプットはモデル
- 概念設計 => 概念モデル = ER図
- 概念設計ではユースケースからエンティティを取り出す
- 論理設計 => 論理モデル = ER
- 物理設計 => 物理モデル
モデリング

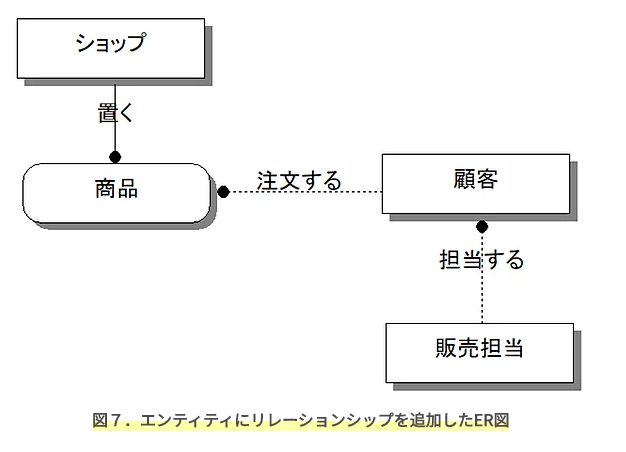
ER図

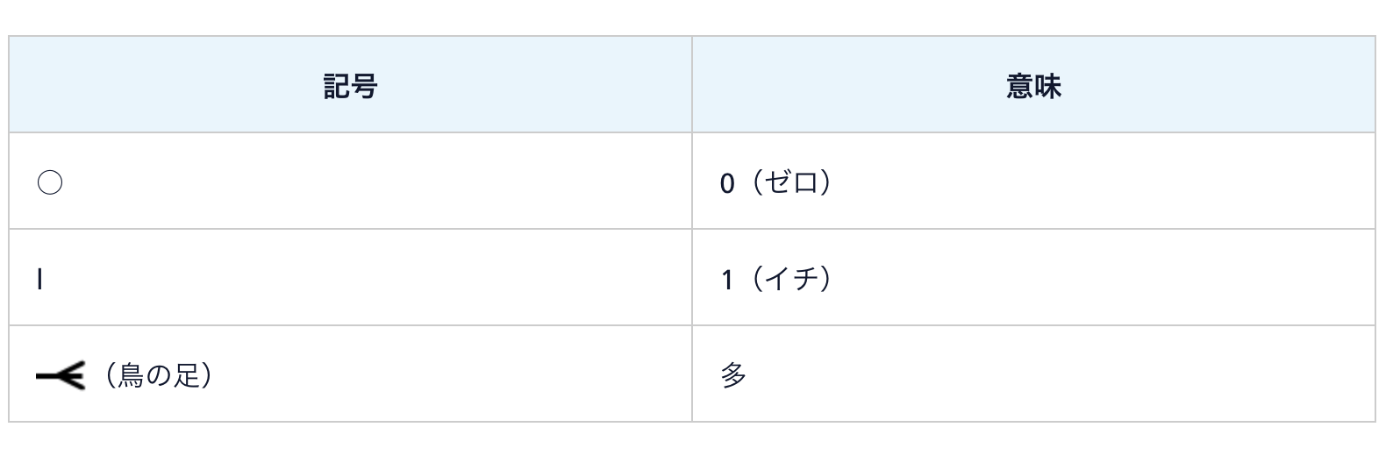
モデルについて
概念モデル
-
まずはじめにシステムに登場する「モノ」を洗い出し、エンティティとして定義する。
- 四角い箱で
- エンティティ配下の2主留意に分けられる
- リソースエンティティ
- システムの基本データ。最終的にはマスタテーブルとなる
- イベントエンティティ
- 業務データを管理する。最終的にはトランザクションデータテーブルとなる
- リソースエンティティ
-
関係あるエンティティ間にリレーションシップ(関連線)を引く。
- リレーションシップには方向性があり、主語 -> 目的語で線を引く。 向きが若料に先に●をつける- 主語が親エンティティ、目的語が子エンティティ
- 依存リレーションシップ(実線で書く)
- 親エンティティが存在しないと、子エンティティが存在できない
- 非依存リレーションシップ(点線で書く)
- 依存じゃないもの
- 多対多リレーションシップ(双方に
●があり、点線)- 依存なし。
- 中間リレーション(0, 1対多)の関係に変更する