2017年、元OpenAIの共同創業者であり、元テスラのAIディレクターでもある Andrej Karpathy は、自身のブログ記事で、「Software 2.0」という概念を提唱しました。
彼の主張はこうです——
「ソフトウェア開発とは、コードを書くことではなくなる。
大量のデータを準備し、ニューラルネットワークを訓練することが、新しい“プログラミング”になる。」
この考えは、当時としては新鮮で挑戦的でしたが、それからわずか数年で、私たちはさらにその先へと進んでいます。
今年2月、Karpathyは再び、新しい人気キーワードを生み出しました。
それが 「Vibe Coding」です。
Vibe Coding とは、開発者が細かなコードを自ら書くのではなく、「なんとなくこんな感じ(vibe)」という感覚でAIに伝え、動くものを実現してもらうという新しい開発スタイルです。
そして先週、Karpathy は約40分間の講演を通じて、AIによるソフトウェア開発の現在地とこれからを語り、「Software 3.0」 という新たな概念を提示しました。
PythonやJavaScriptを知らなくても、誰もがソフトウェアを“話すように”作れる。
この大転換をKarpathyは「Software 3.0」と名付けました。
では、誰もがプログラマーになれる時代において、ソフトウェアエンジニアという職業はどう変わるのでしょうか?
この講演には、非常に多くの興味深く、示唆に富んだ視点が詰まっています。
そこで本ブログでは、私自身の理解をもとに、特に印象に残ったポイントをピックアップして紹介します。
ご興味のある方は、ぜひ元の動画もあわせてご覧いただくことをおすすめします。
講演動画(YouTube):
講演スライドはこちらからダウンロード可能:
Software 3.0時代、最も人気のあるプログラミング言語は「英語」
Karpathy は 2023年1月から、次の投稿を X に固定しています:
The hottest new programming language is English.
(最もホットな新しいプログラミング言語は、英語だ。)
一見ジョークのように思えるこの言葉も、今ではすっかり現実となりました。
母語で「話すだけ」で開発できる時代へ
従来のソフトウェア開発では、エンジニアは職人のように、C++やPythonといったプログラミング言語を用いて、コンピュータに対する明確かつ詳細な命令を一行ずつ丁寧に書いていました。
次に訪れた「Software 2.0」では、エンジニアはルールを書く代わりに、膨大なラベル付きデータを用意し、モデルを訓練することでタスクを学習させるという“教師”のような役割を担いました。
そして現在、私たちは「Software 3.0」の時代に突入しています。
もはや複雑なプログラミング言語を学ぶ必要はありません。
日常の言葉で「こういうことがしたい」とAIに伝えるだけで、LLM(大規模言語モデル)がそれを理解し、実行してくれるようになったのです。
この変化は、プログラミングの定義そのものを塗り替えます。
私たちはコードを書くのではなく、プロンプト(指示文)を書く。
つまり、ソフトウェアを構築するという行為が「自然言語で意味を伝えること」へと進化したのです。
Karpathyはこの進化を、「感情分析ツール(文章がポジティブかネガティブかを判断する)」の例を通じて分かりやすく説明しています。
このツールを作る方法は、時代ごとに大きく異なります:
- Software 1.0:Pythonでif文などを駆使し、ルールベースで感情を判定する
- Software 2.0:何万件ものラベル付きデータを使って、分類モデルを訓練する
- Software 3.0:母語で「この文はポジティブ/ネガティブ」と数例示すだけで、LLMが判断できるようになる

かつては「ルールを書く」ことがソフトウェア開発でした。
いまや「ルールを例で示す」だけで、AIが開発の多くを肩代わりしてくれる時代です。
古いソフトウェアは、新しいソフトウェアに侵食される
Karpathy は、Tesla で自動運転の開発に携わっていた当時の経験から、次のように語っています。
初期の自動運転ソフトウェアは、大量の C++ ロジックで構築されていた。
しかしニューラルネットの性能が向上すると、その多くを置き換えることができた。
結果的に、同じ機能を持ちつつも、元のコードの多くを削除できた。
つまり、Software 2.0(ニューラルネット)のアプローチが、Software 1.0(人手で書いたコード)を静かに侵食し始めたのです。
そして今、まったく同じ現象が Software 3.0 によって再び起ころうとしています。
今度は、Software 3.0(自然言語 + LLM)が、Software 2.0(機械学習モデル)の領域にまで浸透し、置き換え始めているのです。
LLMの本質とは?──ツールを超えた「新しいOS」の誕生
では、Andrej Karpathy はこの新しいAIエコシステムをどう捉えているのでしょうか?
LLMは「インフラ」である
2016年、Andrew Ng は次のように予言しました:
「AI は新しい電力である」
この言葉が今、現実になりつつあります。
大規模言語モデル(LLM)は、もはやツールではなく、電力や水道のような「公共インフラ」 になり始めています。
- 巨大テック企業は、膨大なコストをかけてモデルを訓練ーーまるで電力会社が発電所を建てるように
- API 経由でトークンごとに課金ーー使った分だけ電気代を払うように
- 私たちは、低遅延・高可用性・安定した品質をLLMに求めているーーまさに公共サービスと同じ目線
そして、LLMサービスが停止すると、まるで「知能の停電(intelligence brownout)」が起きたかのように、世界が一時停止します。
筆者自身も先月、GitHub Copilot が2回連続でダウンした際、多くの開発者がSNSでこう嘆いているのを目にしました:
「まさかの手作業時代に逆戻り……」
それほどまでに、私たちはすでに「知能のインフラ」としてLLMに依存しているのです。
そしてこの依存度は、今後ますます高まっていくでしょう。
LLMは「新しいOS」である
ただし、Karpathy は LLM を単なるインフラ以上の存在として見ています。
それはまるで、新しいオペレーティングシステム(OS) のようなものだと。
- LLMはCPUのように計算を担い、Context Windowはメモリのように情報を一時保持
- LLMアプリ(例:Cursor)は、モデルを切り替えるだけで別の「OS」で動かせる
- これからはモデルそのものだけでなく、周辺のツール群、マルチモーダル対応なども含めて、LLMの「OS化」が進む
- 市場も分裂しており、商用(ChatGPT/Gemini)とオープンソース(LLaMA)が共存する様子は、まさにWindows/MacとLinuxのよう

LLMは、電力よりもはるかに “生きている”ソフトウェアエコシステム なのです。
共通GUIはまだ生まれていない
もしLLMがOSだとしたら、私たちは今、「ターミナル」で直接OSに話しかけている段階です。
ChatGPTのテキストボックスで会話するのは、まさにシェルでOSを操作しているような体験です。

直感的で汎用的なGUI(グラフィカルインターフェース)は、まだ存在していません。
今後、この新しい「OS」のためのGUIが発明される可能性は大いにあるでしょう。
技術の拡散経路が逆転した
もう一つ興味深いのは、LLMはテクノロジーの普及ルートを完全にひっくり返したという点です。
従来、電力・暗号・コンピュータ・GPSなど、すべての画期的技術はまず政府や軍事から始まり、次第に民間や消費者へと広がっていきました。
しかし、LLMはその逆です。
最初に「どうやって卵をゆでるか」を手伝ったのはAIだった。
それは国家機密でも兵器開発でもありませんでした。
LLMは、まず「私たちの日常」に届きました。
その後、企業や行政がようやくその価値を理解し、追いつこうとしています。
技術の矢印が「下から上」に向かう時代。
だからこそ、LLM時代のアプリは、従来の技術とは全く違う形でスタートし、進化していくことになるのです。
LLMは「認知的にクセのある超優等生」
LLM(大規模言語モデル)を理解するにあたって、Karpathyは「心理学的な視点」が役に立つと語ります。
彼は LLM を「人間の精神(people spirits)」のような存在だと捉えています。
なぜなら、LLMは人間の会話・文章・思考パターンから学習しており、ある意味、人間のランダム性を模倣するシミュレーターのようなものだからです。
そのため、LLMは「擬似的な心」を持つようにふるまい、驚異的な能力と致命的なクセの両方を持ち合わせています。
LLMの超能力:
- 圧倒的な知識量(百科事典レベル)
- 高速な言語処理能力
- 瞬時にテキストを生成・理解する能力
LLMの認知的クセ:
- 幻覚(Hallucination):事実のように見えるが、間違った情報を生成する
- ギザギザ知能(Jagged Intelligence):ある領域では天才的だが、別の領域では初歩的なミスをする(例:9.11 > 9.9と主張する)
- 前向性健忘(Anterograde Amnesia):過去の会話や経験を保持できず、毎回リセットされる
- 安全性の脆弱性:特定のプロンプトにより騙されたり、誤作動を起こしたりする
これらの特徴を理解することは、LLMを安全かつ有効に活用するうえで不可欠です。
我々は、LLMの能力を引き出すと同時に、その「認知的クセ」とうまく付き合っていく必要があります。
LLMの制御が鍵:全て任せるのは危険
では、どうすればAIと安全に協働できるのでしょうか?
Karpathyの答えは明確です——
部分的な自律性(Partial Autonomy) を持ったAIプロダクト。
部分自律の具体例:Cursor
その一例として、彼はAIコーディングツール「Cursor」を紹介しています。

Cursorは、従来どおり人間が全て手動で操作できるインターフェースを持ちながら、以下のようなLLM統合機能も備えています:
- コンテキスト管理:コードやチャット内容を整理し、文脈に合った応答を生成
- マルチモード連携:複数モデルを組み合わせ、コード生成・レビュー・編集などを同時進行
- 人間が操作可能なGUI:色分け・承認ボタンなどでAIの提案を視覚的に管理
重要なのは、常に人間が介入できること です。
一部だけAIに任せたり、全文書き換えをさせたり、自分で微調整したり。
すべての選択は人間が握っているのです。
「生成 - 検証」のサイクルを高速に回す
この考え方は、これからのAIプロダクト設計にも大きく影響します。
- LLMは必要な情報を「すべて見えているか」?
- LLMは必要な操作を「すべて実行できるか」?
- そして人間は、その出力を「ちゃんと検証・修正できるか」?
Karpathyは、AIとの協働の鍵として以下の2点を挙げます:
- 検証サイクルの高速化:GUIを活用して、人間が素早く出力をチェックできるようにする
- 制御の確保:AIが数千行ものコードを生成し暴走しないよう、出力の粒度を制限する
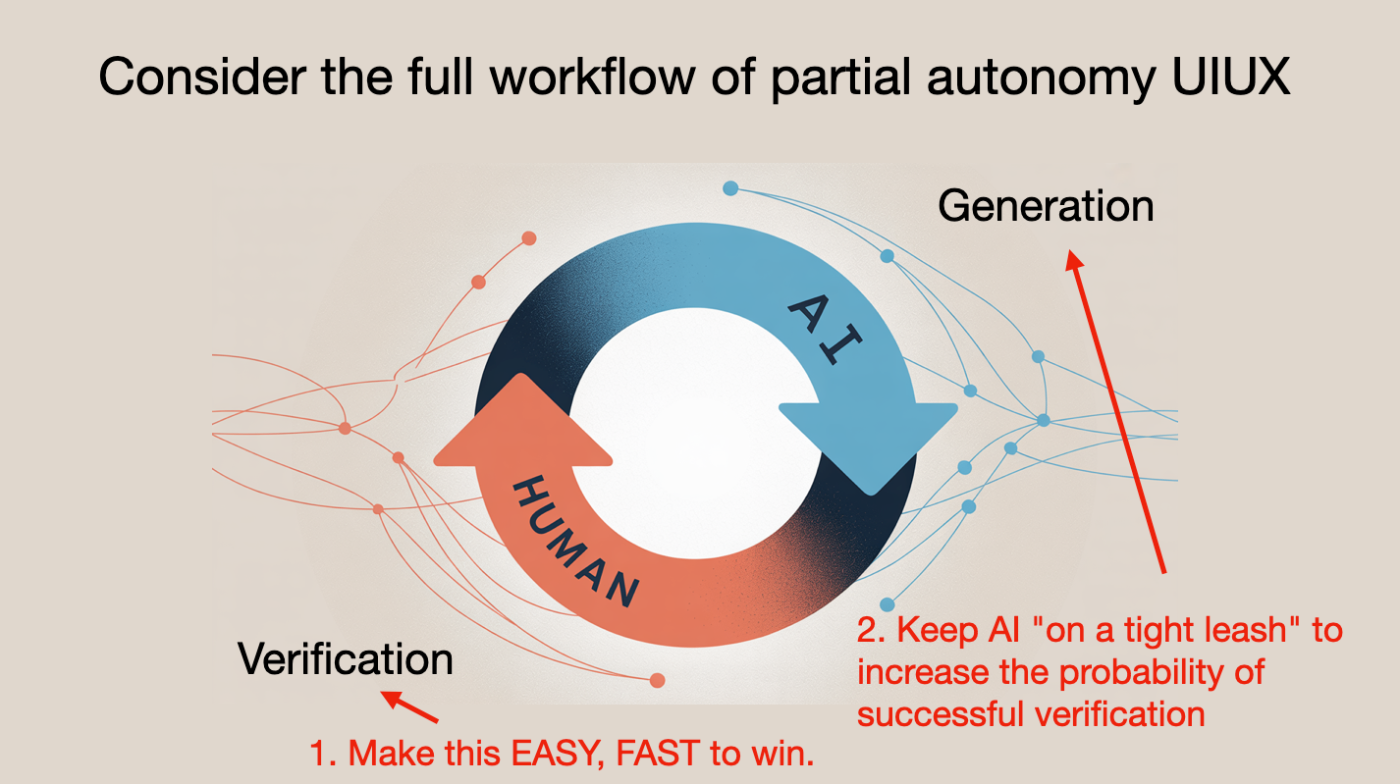
そしてもう一つ大切なのが、プロンプトの明確さです。
曖昧なプロンプトでは、AIの出力も不安定になるため、結果として、何度も検証・修正を繰り返すことになります。
だからこそ、「最初のプロンプト」に時間をかける価値があるのです。
「2025年はAIエージェント元年?」 Karpathyの慎重な見方
近年、「2025年はAIエージェント元年だ」といった期待の声が多く聞かれます。
しかしKarpathyは、その見方に懐疑的です。
彼は自身の体験をこう語ります:
2013年、Waymoの自動運転車に40分乗ったとき、完璧な走行だった。
「これはもう実用化される」と思った。
でも、それから12年経っても、自動運転はまだ“完璧”とは言えない。
つまり、「技術的にできる」 ことと、「製品として使える」 ことは全く別物なのです。
Karpathyは、今のAIエージェントに対してこう考えています:
「2025年はAIエージェントの元年」ではなく、
「AIエージェントの10年が始まる」 と捉えるべきだ。

今こそ、「AIエージェントのためのインフラ」を作るチャンス
Vibe Codingの時代では、誰もがプログラマーのようにAIを使ってツールを作れるようになりました。
Karpathy自身もSwiftの知識がないにもかかわらず、AIを活用して、数時間でiOSアプリを構築し、実機で動かすことに成功しています。
しかし、彼はすぐにある問題に気づきます──
「コードを書くのは簡単。でも、本当に使える製品にするのがとても大変だ」
エージェントがまだ手を出せない「本当の課題」
アプリのコア機能自体はすぐに動きました。
でも、それを「現実の製品」にするには、多くの非コード作業が必要です。
- 認証機能の実装
- 決済システムの導入
- ドメインの取得と設定
- クラウドへのデプロイ など
そして、これらの作業の多くは、ブラウザ上でのボタン操作とドキュメントに沿った手動設定。
たとえばGoogleログインの統合だけでも、Google Console上でいくつもの画面を行き来し、細かい設定を手動で行わなければいけません。
コンピュータが「何をクリックすべきか」を私に指示してくる。
だったら最初からコンピュータが自分でやってくれればいいじゃないか!
Karpathyはそう叫びます。
AIエージェントのためのインフラを作る
ここで彼が提案するのは、次の問いです:
「AIエージェントが理解・操作しやすいように、私たちのインフラを作り変えられないか?」
robots.txtからllms.txtへ:
Webサイトには、検索エンジン向けの案内ファイル robots.txt があります。
同じように、今後はLLM向けの llms.txt を用意して、「このドメインが何をする場所なのか」を説明するべきかもしれません。

LLMが読めるドキュメントへ:
人間向けのドキュメント──例えば、「ここのボタンをクリック」などの手順──は、LLMにとって扱いにくいです。
VercelやStripeなどはすでに、そうした手順を curl コマンドなどに置き換え、Markdown形式で提供しています。
ドキュメントの形式だけでなく、内容そのものをLLMフレンドリーに書き直す流れが始まっています。

データ変換ツールの進化:
最近では、GitHubのURLを少し変更するだけで、そのリポジトリ全体をLLM向けに整形してくれるツール(例:Gitingest)も登場。
さらに高度なツール(例:DeepWiki)は、コードベースを自動解析して、LLMが理解しやすいドキュメントを生成してくれます。
今は「エージェントが理解しやすい世界」を用意するべき時期
将来的には、LLMが人間と同じようにGUIを操作できるようになるかもしれません。
でも今はまだ、私たちが情報を整えてあげる方がずっと現実的で効率的です。
「Agent First」 でインフラを考えることこそ、これからの開発の本質になるかもしれません。
感想:これからの開発者に求められる力とは?
自然言語がプログラミング言語になることで、ソフトウェアを創るハードルは一気に下がり、
より多くの人が「創る側」に回れる時代が到来しました。
この変化を前に、
「もしかして、ソフトウェアエンジニアという職業はいずれ不要になるのでは?」
という不安の声もよく耳にします。
でも私は、Karpathy と同じく、職業としての「エンジニア」は終わらないと感じています。
ただし、それはこれまでと同じ意味ではありません。
「ソフトウェアエンジニア」という言葉の定義と役割が、根本から書き換えられようとしている。
これから求められるのは、
単に「コードを速く正確に書ける人」ではありません。
むしろ、
AIの力を引き出し、適切に検証し、目的に沿って組み合わせる「設計者」や「プロダクト思考の持ち主」
のような役割が重要になっていきます。
それは、車が発明された時代に、
速く走れる人ではなく、「車を運転できる人」が活躍するようになった
のと同じです。
車が登場したとき、人類がすべきだったのは走り続けることではなく、運転免許を取ることだった。
Karpathy の語る「Software 3.0」は、まさにそのような歴史的な転換点に
私たちが今まさに立っていることを示しているように思いました。
AI時代におけるエンジニアの在り方に迷っているとしたら、
「より早く走る」ことを目指すのではなく、
「どう運転し、どこへ向かうか」 に目を向けてみるのが良いのかもしれません。

スペースを簡単に貸し借りできるサービス「スペースマーケット」のエンジニアによる公式ブログです。 弊社採用技術スタックはこちら -> whatweuse.dev/company/spacemarket
Discussion