概要
みなさん、Elasticsearch使ってますか?
検索機能のあるプロダクトを開発しているところは導入されているとこも多いのではないでしょうか?
今日はBigQuery上からElasticsearchへのお手軽に同期する方法を紹介します。
あららびっくりこんな簡単に同期ができるなんて...
Elasticsearchへデータを同期するにはAWSbatch等を使ってせっせとbatch作ることになると思います。
同期対象がBigQueryのデータの場合、かなりお手軽にbatchを作成することが可能です。そうDataflow templateを使えばね。
GoogleさんがBigQueryからElasitcsearchへの同期処理のDataflowで起動できるtemplateを用意してくれており、
- ElasticsearchクラスタのURL、index、apikey
- BigQueryのプロジェクト名、データセット名、テーブル名
を設定するだけで、簡単に同期することができます。
例えば、下記のようなテーブルを同期したいとします。
作曲者の情報が入っているcomposersテーブルがあるとしましょう。
作曲者名の他、国、年代、代表曲が格納されています。
| id | name | famous_song |
|---|---|---|
| 1 | ベートーヴェン | 交響曲第9番『合唱』 |
| 2 | モーツァルト | 交響曲第40番 |
| 3 | チャイコフスキー | 交響曲第6番『悲愴』 |
| 4 | ドヴォルザーク | 交響曲第9番『新世界より』 |
こちらのデータをcomposers indexに同期したいとします。
PUT composers
{
"mappings": {
"dynamic": "false",
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text",
"analyzer": "kuromoji"
},
"famous_song": {
"type": "text",
"analyzer": "kuromoji"
}
}
}
}
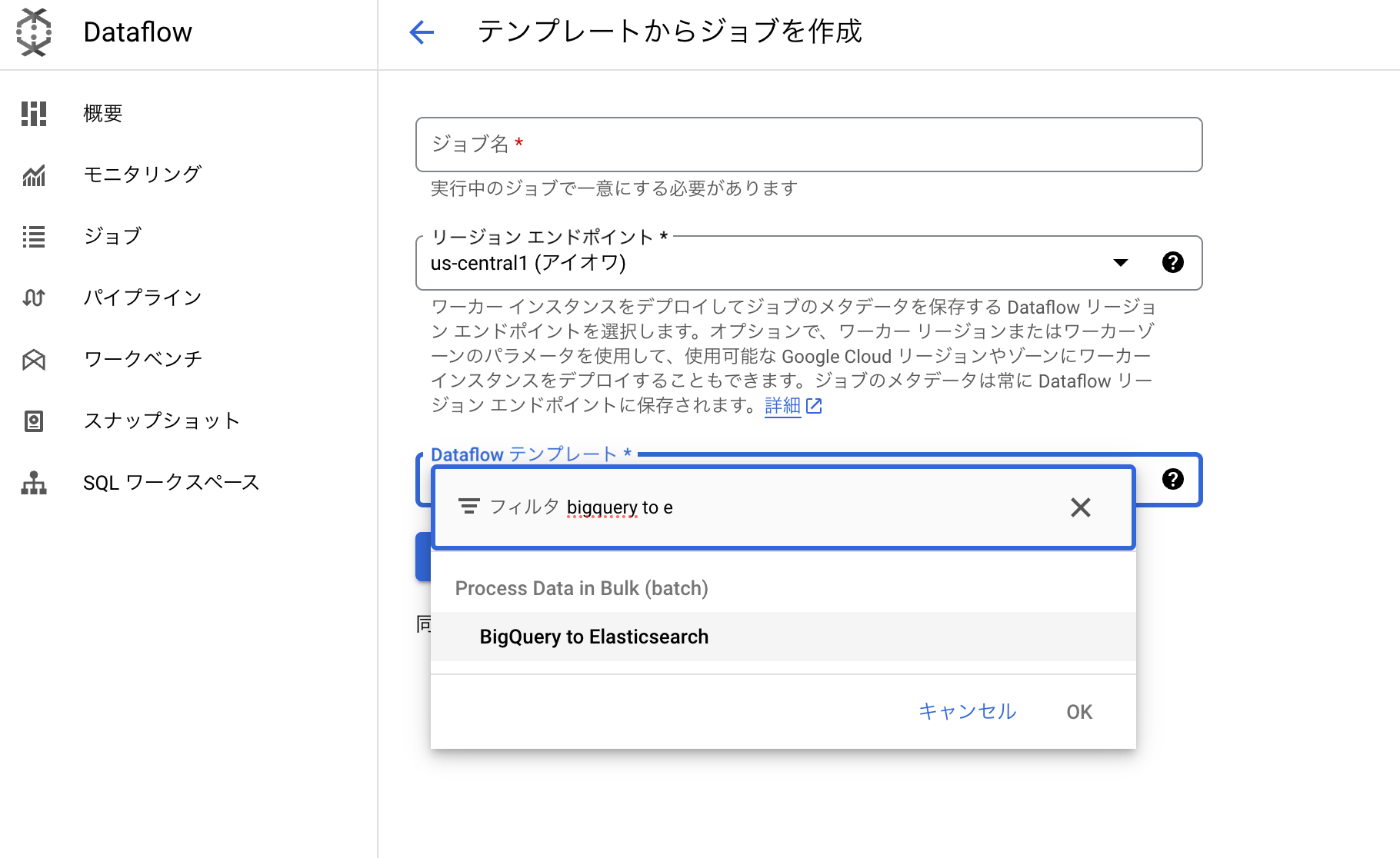
Dataflowの「テンプレートからジョブを作成」を押下。

下記のようにDataflowテンプレートから「BigQuery to Elasticsearch」を選択します。
必須パラメータを入力
ElasticsearchのURLかElasticCouldを使っている方はCloudIDを入力します。
Elasticsearchで発行したAPI Keyと同期先のindexも指定します。

同期対象のBigQuery dataset名、テーブル名も入力します。
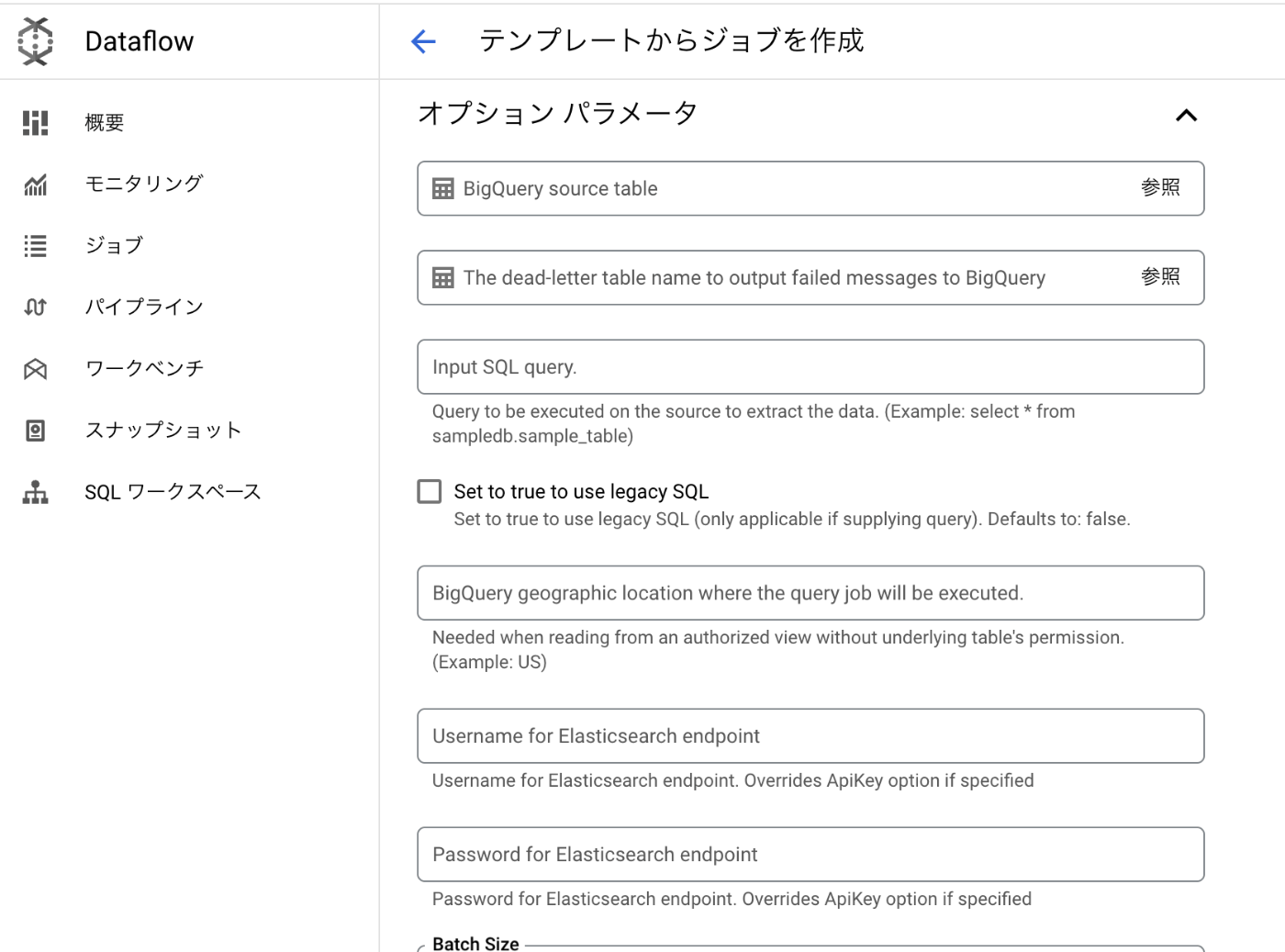
今回はupsert usePartialUpdate true の設定で実行してみましょう。
これでDataflow templateからElasticsearch Bulk APIの update を使って同期されるようになります。

しばらく待つと、同期が完了します。
これでquery叩いてみると。
// リクエスト
GET composers/_search
// レスポンス
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "composers",
"_id": "3",
"_score": 1,
"_source": {
"id": "3",
"name": "チャイコフスキー",
"country": "交響曲第6番『悲愴』"
}
},
{
"_index": "composers",
"_id": "1",
"_score": 1,
"_source": {
"id": "1",
"name": "ベートーヴェン",
"country": "交響曲第9番『合唱』"
}
},
{
"_index": "composers",
"_id": "2",
"_score": 1,
"_source": {
"id": "2",
"name": "モーツァルト",
"country": "交響曲第40番"
}
},
{
"_index": "composers",
"_id": "4",
"_score": 1,
"_source": {
"id": "4",
"name": "ドヴォルザーク",
"country": "交響曲第9番『新世界より』"
}
}
]
}
}
というように簡単に同期できました。
もっと複雑なindexでもできるの...?
えっ?ArrayとかNested field使ってるからウチじゃ使えないな?
いえいえ同期できます!
Elasticsearchではfieldを配列にすることができます。
先ほどの例でいうと代表曲がそれぞれの作曲家で1曲しか入っていませんでしたが、何曲も入れたい!というユースケースです。
さらに配列内のデータで検索したい場合、今回の例でいうと代表曲から作曲者を検索したいという場合、Nested fieldを使うと便利でしょう。
これらの場合でもDataflow templateを使って同期可能です。
BigQeuryにはstructやarrayといった型があり、これらの型を使ったテーブルを同期することで実現できます。
代表曲を複数持ちたい場合、下記のようなテーブルを作成することで同期が可能です。
| id | name | famous_song |
|---|---|---|
| 1 | ベートーヴェン | 交響曲第9番『合唱』 |
| ピアノソナタ『月光』 | ||
| 2 | モーツァルト | 交響曲第40番 |
| オペラ『魔笛』 | ||
| ピアノ協奏曲第21番『エルヴィラ・マドリガル』 | ||
| 3 | チャイコフスキー | 交響曲第6番『悲愴』 |
| バレエ音楽『くるみ割り人形』 | ||
| 4 | ドヴォルザーク | 交響曲第9番『新世界より』 |
| 交響詩『水の精』 |
[]かARRAY_AGG()等で配列を作るとよいでしょう。
SELECT
1 AS id,
"ルベートーヴェン" AS name, # 名前
["交響曲第9番『合唱』","ピアノソナタ『月光』"] AS famous_song, # 代表曲
UNION ALL
SELECT
2 AS id,
"モーツァルト" AS name, # 名前
["交響曲第40番","オペラ『魔笛』","ピアノ協奏曲第21番『エルヴィラ・マドリガル』"] AS famous_song, # 代表曲
UNION ALL
SELECT
3 AS id,
"チャイコフスキー" AS name, # 名前
["交響曲第6番『悲愴』","バレエ音楽『くるみ割り人形』"] AS famous_song, # 代表曲
UNION ALL
SELECT
4 AS id,
"ドヴォルザーク" AS name, # 名前
["交響曲第9番『新世界より』","交響詩『水の精』"] AS famous_song, # 代表曲"
;
これも同じくDataflow templateでElasticsearchへ同期すると下記のような結果を取得することができます。
{
"took": 813,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "composers",
"_id": "4",
"_score": 1,
"_source": {
"id": "4",
"name": "ドヴォルザーク",
"country": "交響曲第9番『新世界より』",
"famous_song": [
"交響曲第9番『新世界より』",
"交響詩『水の精』"
]
}
},
{
"_index": "composers",
"_id": "3",
"_score": 1,
"_source": {
"id": "3",
"name": "チャイコフスキー",
"country": "交響曲第6番『悲愴』",
"famous_song": [
"交響曲第6番『悲愴』",
"バレエ音楽『くるみ割り人形』"
]
}
},
{
"_index": "composers",
"_id": "2",
"_score": 1,
"_source": {
"id": "2",
"name": "モーツァルト",
"country": "交響曲第40番",
"famous_song": [
"交響曲第40番",
"オペラ『魔笛』",
"ピアノ協奏曲第21番『エルヴィラ・マドリガル』"
]
}
},
{
"_index": "composers",
"_id": "1",
"_score": 1,
"_source": {
"id": "1",
"name": "ルベートーヴェン",
"country": "交響曲第9番『合唱』",
"famous_song": [
"交響曲第9番『合唱』",
"ピアノソナタ『月光』"
]
}
}
]
}
}
こんな複雑なのもいけます。こちらは代表曲をジャンル分けしている場合です。
| id | name | famous_song.orchestra | famous_song.piano |
|---|---|---|---|
| 1 | ベートーヴェン | 交響曲第9番『合唱』 | |
| ピアノソナタ『月光』 | |||
| 2 | モーツァルト | 交響曲第40番 | |
| ピアノ協奏曲第21番『エルヴィラ・マドリガル』 | |||
| 3 | チャイコフスキー | 交響曲第6番『悲愴』 | |
| バレエ音楽『くるみ割り人形』 | |||
| 4 | ドヴォルザーク | 交響曲第9番『新世界より』 | |
| 交響詩『水の精』 |
こちらのようなデータ構造はSTRUCT()で作ることができます。
SELECT
1 AS id,
"ベートーヴェン" AS name, # 名前
[
STRUCT("交響曲第9番『合唱』" AS orchestra, "ピアノソナタ『月光』" AS piano)
] AS famous_song, # 代表曲"
UNION ALL
SELECT
2 AS id,
"モーツァルト" AS name, # 名前
[
STRUCT("交響曲第40番" AS orchestra, "ピアノ協奏曲第21番『エルヴィラ・マドリガル』" AS piano)
] AS famous_song, # 代表曲"
UNION ALL
SELECT
3 AS id,
"チャイコフスキー" AS name, # 名前
[
STRUCT("交響曲第6番『悲愴』" AS orchestra, CAST(NULL AS STRING) AS piano),
STRUCT("バレエ音楽『くるみ割り人形』" AS orchestra, CAST(NULL AS STRING) AS piano)
] AS famous_song, # 代表曲"
UNION ALL
SELECT
4 AS id,
"ドヴォルザーク" AS name, # 名前
[
STRUCT("交響曲第9番『新世界より』" AS orchestra, CAST(NULL AS STRING) AS piano),
STRUCT("交響詩『水の精』" AS orchestra, CAST(NULL AS STRING) AS piano)
] AS famous_song, # 代表曲"
;
indexはNested filedを使う場合はこのようなmappingsにするとよいでしょう。
PUT composers
{
"mappings": {
"dynamic": "false",
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text",
"analyzer": "kuromoji"
},
"famous_song": {
"type": "nested",
"properties": {
"orchestra": {
"type": "text",
"analyzer": "kuromoji"
},
"piano": {
"type": "text",
"analyzer": "kuromoji"
}
}
}
}
}
}
こちらも同期すると下記のような結果を取得することができます。
{
"took": 393,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "composers",
"_id": "3",
"_score": 1,
"_source": {
"id": "3",
"name": "チャイコフスキー",
"famous_song": [
{
"orchestra": "交響曲第6番『悲愴』"
},
{
"orchestra": "バレエ音楽『くるみ割り人形』"
}
]
}
},
{
"_index": "composers",
"_id": "4",
"_score": 1,
"_source": {
"id": "4",
"name": "ドヴォルザーク",
"famous_song": [
{
"orchestra": "交響曲第9番『新世界より』"
},
{
"orchestra": "交響詩『水の精』"
}
]
}
},
{
"_index": "composers",
"_id": "1",
"_score": 1,
"_source": {
"id": "1",
"name": "ベートーヴェン",
"famous_song": [
{
"orchestra": "交響曲第9番『合唱』",
"piano": "ピアノソナタ『月光』"
}
]
}
},
{
"_index": "composers",
"_id": "2",
"_score": 1,
"_source": {
"id": "2",
"name": "モーツァルト",
"famous_song": [
{
"orchestra": "交響曲第40番",
"piano": "ピアノ協奏曲第21番『エルヴィラ・マドリガル』"
}
]
}
}
]
}
}
このようにDataflow templateを使うことでお手軽にElasticsearchへ同期することができました!
BigQueryからElasticsearchへデータ同期する必要のある方ぜひ試してみて頂ければと思います!
最後に
スペースマーケットでは、一緒にサービスを成長させていく仲間を探しています。
ビジネスサイド、エンジニアメンバー共に話しやすいメンバーが多く非常に働きやすい環境だと思います!
ご興味ある方ぜひ見てみて下さい!

スペースを簡単に貸し借りできるサービス「スペースマーケット」のエンジニアによる公式ブログです。 弊社採用技術スタックはこちら -> whatweuse.dev/company/spacemarket
Discussion