はじめに
こんにちは。スペースマーケットでWebエンジニアしてるmotimoti63です。
2025年1月に入社してから二ヶ月経ちました。こういった技術的なブログ投稿は初めてですが少しでも役に立つ情報を発信できればと思います。
大学時代にスクレイピングをしててその時に動的なサイトでもスクレピング可能な方法があったので紹介します。
Scrapyとは?
Python製の強力なスクレイピングフレームワークです。通常の静的サイトであれば、HTMLを解析してデータを取得することができますが、Scrapyはそれに加え、非同期処理による高速なクロールやリトライ・キャッシュ機能、データパイプラインを備えているため、大規模なデータ収集も効率的に行えます。
また、Seleniumはブラウザを直接操作するためリソースが重く、BeautifulSoupは単なるHTMLパーサーとしての機能に特化しているのに対し、Scrapyは全体のスクレイピングプロセス(リクエストの生成からデータの抽出、保存まで)を統合的に管理できる点が大きな魅力です。
Playwrightとは?
PlaywrightとはMicrosoftが開発したオープンソースのE2Eテスト自動化フレームワークです。
Scrapy-Playwrightとは?
ScrapyにPlaywrightを統合した拡張ライブラリです。これにより、
- JavaScriptを実行して完全にレンダリングされたページを取得できる
- headlessブラウザ(Chromium, Firefox, WebKit)を利用できる
といったメリットがあります。
環境
- Python 3.13.1
- scrapy-playwright 0.0.43
- playwright 1.50.0
構造
myproject/
├── scrapy.cfg # プロジェクト全体の設定ファイル
└── myproject/ # プロジェクトの Python パッケージ
├── __init__.py
├── items.py # 収集するデータ(アイテム)の定義
├── middlewares.py # ダウンローダやスパイダーのミドルウェア
├── pipelines.py # 収集したデータの後処理(保存・整形など)
├── settings.py # プロジェクト全体の設定(こちらでscrapy-playwrightを設定してあげる)
└── spiders/ # 各スパイダー(クロール対象のロジック)の定義
├── __init__.py
└── sample_spider.py #今回はquotes_spider.pyに書き換え
Scrapy-Playwrightの導入
必要なライブラリのインストール
まず、ScrapyとScrapy-Playwrightをインストールします。
pip install scrapy scrapy-playwright
Python パッケージのPlaywrightをインストールする必要があるため、以下のコマンドも実行します。
pip install playwright
検証(比較)
Scrapyでの場合
今回はこちらのJavaScriptで実装したページを参考にしてみる。一応このページは今回スクレピング対象にテスト用で作成したものになります。v0で簡単に作ってみました。皆さんも是非使ってみてください。一瞬でサイトが完成します!
では、実際に実装していく👇
以下のコードをこちらのsample_spider.pyにコピペする
import scrapy
class RealEstateSpider(scrapy.Spider):
name = "realestate"
allowed_domains = ["kzmlywhd669dcr21t5cl.lite.vusercontent.net"]
start_urls = ["https://kzmlywhd669dcr21t5cl.lite.vusercontent.net/"]
def parse(self, response):
# 物件カードの要素を取得
properties = response.css("div.property-card")
if properties:
for prop in properties:
yield {
"property_id": prop.attrib.get("data-property-id"),
"image_url": response.urljoin(prop.css("img.property-image::attr(src)").get()),
"title": prop.css("h3.property-title::text").get(),
"address": prop.css("p.property-address::text").get(),
"price": prop.css("span.property-price::text").get(),
"type": prop.css("span.property-type::text").get(),
"size": prop.css("div.property-size p::text").get(),
"layout": prop.css("div.property-layout p::text").get(),
"year": prop.css("div.property-year p::text").get(),
"station": prop.css("div.property-station p::text").get(),
}
else:
self.logger.info("物件情報が見つかりませんでした。JSレンダリングが必要な場合は、Splashなどのツールをご検討ください。")
実際に以下のコマンドで実行してみる(scrapy.cfgがある同じ階層で。)
python -m scrapy crawl realestate
実行結果

このようにscrapyだとデータ取得できない。
Scrapy-Playwrightの場合
続いて先ほどのrealestate.pyと同じ階層に以下のコードを作成してあげる
import scrapy
from scrapy_playwright.page import PageMethod
class RealEstatePlaywrightSpider(scrapy.Spider):
name = "realestate_playwright"
allowed_domains = ["kzmlywhd669dcr21t5cl.lite.vusercontent.net"]
start_urls = ["https://kzmlywhd669dcr21t5cl.lite.vusercontent.net/"]
# ScrapyPlaywrightの設定をしてあげる
custom_settings = {
"PLAYWRIGHT_BROWSER_TYPE": "chromium",
"DOWNLOAD_HANDLERS": {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
},
"TWISTED_REACTOR": "twisted.internet.asyncioreactor.AsyncioSelectorReactor",
}
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url, meta={
"playwright": True,
"playwright_page_methods": [
PageMethod("wait_for_selector", "div.property-card")
]
})
async def parse(self, response):
properties = response.css("div.property-card")
if properties:
for prop in properties:
yield {
"property_id": prop.attrib.get("data-property-id"),
"image_url": response.urljoin(prop.css("img.property-image::attr(src)").get()),
"title": prop.css("h3.property-title::text").get(),
"address": prop.css("p.property-address::text").get(),
"price": prop.css("span.property-price::text").get(),
"type": prop.css("span.property-type::text").get(),
"size": prop.css("div.property-size p::text").get(),
"layout": prop.css("div.property-layout p::text").get(),
"year": prop.css("div.property-year p::text").get(),
"station": prop.css("div.property-station p::text").get(),
}
else:
self.logger.info("物件情報が見つかりませんでした。")
実際に以下のコマンドで実行してみる
python -m scrapy crawl realestate_playwright
実行結果
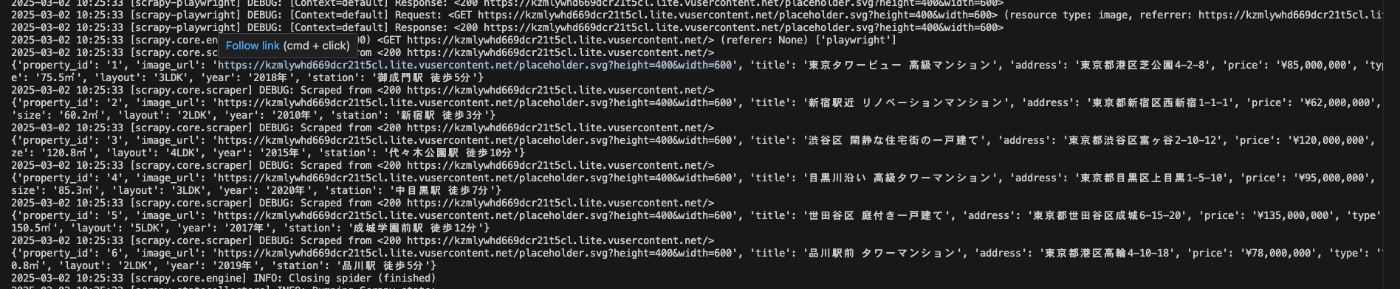
このようにデータ取得できましたね!

あとは自分が好きなような形で保存していただければ!
さいごに
Scrapy と Playwright を組み合わせることで、JavaScript で動的に生成されるサイトからも簡単にデータを取得できるようになります。今回はシンプルなデータ取得の例を紹介しましたが、Scrapy‑Playwright は、JavaScript 製のページネーション、無限スクロール、ログインが必要なページなど、より複雑なシナリオにも強力に対応します。一つだけデメリットとしてはメモリを純正のScrapyよりも食うのでそこら辺はインフラコストなど考慮した上で考えてみてください!ぜひお試しください!

スペースを簡単に貸し借りできるサービス「スペースマーケット」のエンジニアによる公式ブログです。 弊社採用技術スタックはこちら -> whatweuse.dev/company/spacemarket
Discussion