yfinanceのAPIで取得した株価データを自動で収集・可視化するデータパイプラインを構築(Google Cloud)
はじめに
本記事では、GCP(Google Cloud Platform)のサービスを組み合わせて、yfinanceのAPIで取得した株価データを自動で収集・可視化するデータパイプラインを構築した過程を解説します。
実務でBigQueryには触れていたものの、データパイプラインを一から設計・構築する経験はなかったので、個人の学習プロジェクトとしてこのタスクに取り組みました。
作りたいもの:全自動の株価モニタリングシステム
今回構築するシステムは、以下の3つのステップを毎日自動で実行します。
- データの取得・加工: yfinanceから優良企業の株価データを取得・整形します。
- データの格納: 整形したデータをBigQueryに格納します。
- データの可視化: BigQuery上のデータをLooker Studioで可視化し、いつでもモニタリングできるダッシュボードを構築します。
システムの全体像は以下の通りです。
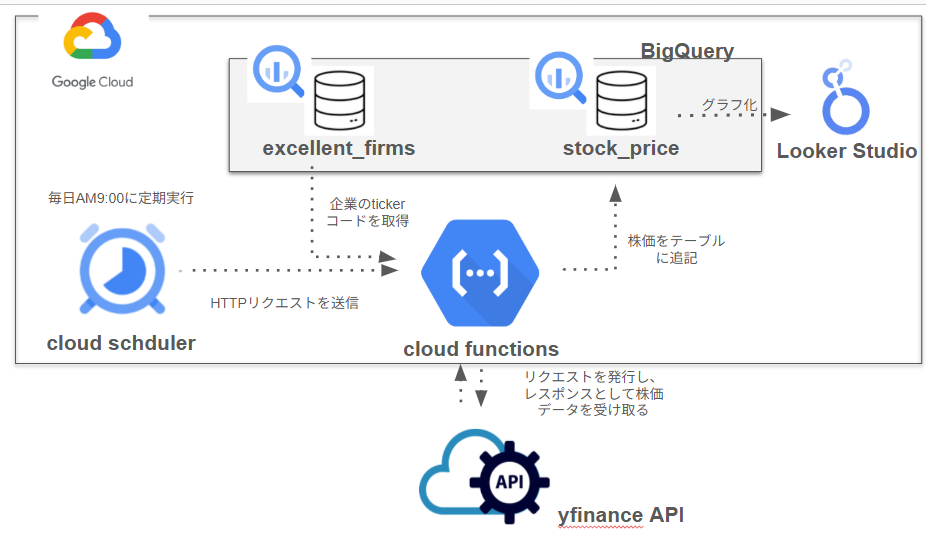
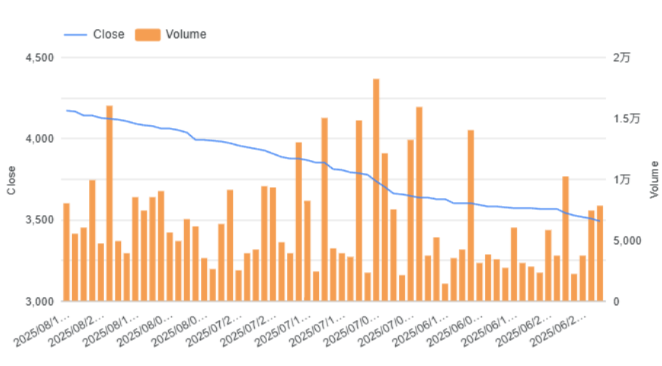
Looker Studioの画像
なぜこれらのサービスを選んだのか?
このシステムを構築するにあたり、GCPの様々なサービスの中から最適なものを選定しました。
1. データの取得・加工: Cloud Functions
データを取得する処理をGCP上で実行するため、Cloud Functionsを選択しました。同じような用途で使えるサービスは他にもありますが、以下の理由でFunctionsが最適だと判断しました。
- Dataflow: 大規模なバッチ処理やストリーミング処理に適したサービスです。今回は数千〜数万件の比較的少量のデータを扱うため、Dataflowの機能はオーバースペックだと判断しました。
- Cloud Data Fusion: データを取得・変換するETL/ELTパイプラインをGUI上で構築できます。しかし、yfinanceのAPIを叩くにはロジックをコードで記述する必要があり、GUIでの操作が難しいと判断しました。
- Cloud Functions: コンテナベースで実行環境を自由にカスタマイズできる柔軟なサービスです。Cloud Functionsでも十分要件を満たせることから、よりシンプルで軽量なCloud Functionsを選びました。
2. バッチ処理:Cloud Scheduler
毎日決まった時間にデータ取得処理を実行するためには、Cloud Schedulerが最適です。Cloud Functionsを定期的にHTTPリクエストで叩くように設定することで、完全に自動化されたデータパイプラインを構築できます。
3. データの格納:BigQuery
実務で慣れていることから、データの格納先としてBigQueryを選定しました。Looker Studioとの連携もスムーズです。
4. ダッシュボード:Looker Studio
Looker Studio は、BigQueryとネイティブに連携しており、無料で使える強力なBIツールです。特別な権限設定をすることなく、BigQueryのデータを直接可視化できるため、アウトプットツールとして最適な選択でした。
実装手順とコード解説
ここからは、実際に構築したシステムの詳細をステップバイステップで解説します。
事前準備:優良企業マスタの作成とサービスアカウント権限の付与
yfinanceからデータを取得するため、あらかじめモニタリングしたい企業のティッカーコード(証券コード)をBigQueryのテーブル(excellent firms)に登録しておきます。このテーブルを「優良企業マスタ」として使用しました。
また、GCPサービス間で連携を行うため、適切な権限を持つサービスアカウントを作成し、設定します。
| サービスアカウント | 役割 | 必要な主な権限 |
|---|---|---|
sa-functions |
Cloud Functionsの実行者 |
BigQuery データ編集者<br>BigQuery ジョブユーザー
|
sa-deploy |
Cloud Buildのデプロイ実行者 |
Cloud Functions 開発者<br>Artifact Registry 書き込み
|
sa-build |
Cloud Build全体の実行者 |
サービスアカウントユーザー (デプロイ先のSAに対する権限) |
Cloud Functionsのコード
BigQueryからティッカーリストを取得し、yfinanceでデータを取得・加工、そしてpandas_gbqでBigQueryに書き込む処理をPythonで記述します。メモリ上限を超えないよう、データを分割して書き込むように最適化しました。
import google.cloud.bigquery as bigquery
import yfinance as yf
import pandas as pd
import pandas_gbq
import functions_framework
from datetime import datetime, timedelta
import os
@functions_framework.http
def fetch_stock_price(request):
# プロジェクトIDとテーブルIDを環境変数から取得
project_id = os.environ.get('GCP_PROJECT')
table_id = f'{project_id}.finance.stock_price'
# BigQueryクライアントを初期化
client = bigquery.Client(project=project_id)
# BigQueryから優良企業マスタのティッカーリストを取得
query = "SELECT Ticker FROM `my-project-1567934249798.finance.excellent_firms`"
query_job = client.query(query)
tickers = [row.Ticker for row in query_job.result()]
# データを追記するための設定
if_exists_mode = 'append'
for ticker in tickers:
try:
# yfinanceの仕様に合わせるために.Tを追加
yf_ticker = f"{ticker}.T"
# yfinanceから株価データを取得
today = datetime.now()
yesterday = today - timedelta(days=1)
start_date = yesterday.strftime('%Y-%m-%d')
end_date = today.strftime('%Y-%m-%d')
data = yf.download(
tickers=yf_ticker,
start=start_date,
end=end_date,
interval="1d",
multi_level_index=False
)
# データフレームの加工
if data.empty:
print(f"Skipping {yf_ticker}: No data found for the period.")
continue
data['Ticker'] = ticker
data.reset_index(inplace=True)
cols = ['Ticker', 'Date'] + [col for col in data.columns if col not in ['Ticker', 'Date']]
data = data[cols]
# BigQueryへの書き込み(インクリメンタルな書き込みでメモリ消費を抑制)
pandas_gbq.to_gbq(
data,
table_id,
project_id=project_id,
if_exists=append
)
return 'Data loaded to BigQuery successfully!', 200
Cloud Schedulerの設定
GCPコンソールからCloud Schedulerのジョブを作成し、以下のように設定します。
-
ターゲット:
HTTP - URL: デプロイしたCloud FunctionsのトリガーURL
-
認証: 認証ヘッダーとして
OIDC(OpenID Connect)トークンを選択し、サービスアカウントにCloud Functions 起動元ロールを付与します。 -
頻度:
0 9 * * *(毎日午前9時(UTC)に実行)など、任意のスケジュールを設定します。
これにより、Cloud Functionsが定期的に実行され、データが自動でBigQueryに格納されるようになります。
アウトプット
最終的に完成したシステムは、GitHubで公開しています。
記事には書き切れていない処理(githubとCloud functions連携による、自動デプロイ、財務情報の取得など)も記載しています
- GitHubリポジトリ: https://github.com/yamayama3689/finance
さいごに
本プロジェクトを通じて、GCPのサービスを組み合わせてデータパイプラインを一から構築する経験を積むことができました。特に、Cloud Functionsのメモリ最適化やサービスアカウントの権限管理などが勉強になりました。
ただ、取り組んでいる中でクラウド周りの知識が甘く、いまいち理解しきれない記事も多かったので、そのあたりの情報も今後キャッチアップしていきたいです。
Discussion