LLMの実験管理 Langfuse & Ragas - 金融コンペと供に -




Langfuseとは、LLMアプリ用に開発されたOSS分析プラットフォームとの事。
Signateさんにて開催された(金融庁共催)第3回金融データ活用チャレンジでは、Dataiku(ローカル版)を活用していました。
しかし、コンペでは提供以外のGUIの使用が禁止だったり、LangChainやllamaIndexを使用したオリジナルコードでも勉強がてら試してみたかったため、Langfuseを触ってみる機会として試してみました。
※ 本記事は、コンペ終了後の内容です。また、最低限の動作確認状態であり、Scoreの部分がおかしいです。。。
Langfuseの導入にあたっては、下記を実行したのみです。
# Get a copy of the latest Langfuse repository
git clone https://github.com/langfuse/langfuse.git
cd langfuse
# Run the langfuse docker compose
docker compose up
0 管理対象モデル
実験対象として、コンペでHITACHI様より御提供頂いていたモデルと近いモデルを準備し、比較していきたいと思います。 ※ コンペは終了しているため、代わりのモデル使用先として、together.aiを使用しつつ、日立さんご提供の物を使用しました。ただし、量子化のサイズ等が違うため、コンペ中のモデルとは厳密な比較はできません。
コンペ中に提供のあったモデル
- meta-llama/lama-3.3-70B-Instruct-fp16
- Qwen/Qwen2.5-72B-Instruct-fp16
- DeepSeek R1(8ビット量子化モデル) ※ エキシビションとしてコンペ終了後に提供のあったモデル
日立殿提供のモデルと似たものを探した所、下記のtogether.aiの無料版を見つけたので、そちらを優先的に使用してみました。
together.aiのモデル
- meta-llama/Llama-3.3-70B-Instruct-Turbo-Free
- deepseek-ai/DeepSeek-R1-Distill-Llama-70B-free
1 データの準備
1.1 問題・回答CSVデータ
コンペではテストデータとして、下記のような問題と正解があるCSVファイルが用意されていました。
problem,ground_truth
アンパンマンの敵は?,バイキンマン
1.2 ベクトルデータベース用 データ準備
はじめはローカルで実施しようとしていましたが、原因不明でうまくいかず、colabにてdoclingを使用しました。1pdfファイル当たり30分ほどかかりました。
下記のようなコードです。
from docling.document_converter import DocumentConverter
source = "/content/drive/MyDrive/1.pdf" # PDF path or URL
converter = DocumentConverter()
result = converter.convert(source)
print(result.document.export_to_markdown())
with open('/content/drive/MyDrive/1.md', 'w') as f:
f.write(result.document.export_to_markdown())
作成後に気づきましたが、LangChain自体でもdoclingが使えたのを知りました。
1.3 ベクトルデータベースモデル
vectorstoreのembeddingsモデルは、自分のPCにて下記の物を準備していましたが、時間が間に合わず、本番ではMSさん提供のtext-embedding-3-largeを使用することにしました。
"cl-nagoya/sup-simcse-ja-base",
"cl-nagoya/ruri-large",
"BAAI/bge-multilingual-gemma2",
"sbintuitions/modernbert-ja-130m",
"hotchpotch/japanese-splade-v2",
"nomic-ai/nomic-embed-text-v2-moe",
"ng3owb/finance_embedding_8k"
これらを、384・512・1023のチャンクサイズで、chromadb・faiss・milvusの3種類で作成していましたが、物によっては作成に10分以上軽くかかったり、1GPUではOut of Memoryになる状態であったため、途中で断念しました。
※ 結論から言うと、時間をかけて作成しましたが、embedding処理する前にきちんとしたテキストデータ・mdデータなどを準備するべきでした。
2 LLM・RAG設定
2.1 パラメータ設定
llmは性質上、確率によって生成される文章であるため、temperature=0に固定し、その他パラメータも固定して試しています。
ただし、使用するモデルによって使用可能なトークン長が異なるため、langchainで使用するllmには、下記のような形で、max_tokens=-1に設定しました。
その他パラメータなどは、モデルによっても異なる?ため、最適な値が分かっていません。
(これも実験管理していくべきでしょうが……)
Together_model_name_list = [
"deepseek-ai/DeepSeek-R1-Distill-Llama-70B-free",
"meta-llama/Llama-3.3-70B-Instruct-Turbo-Free"
]
selected_model_name = Together_model_name_list[0]
repeat_penalty=1.1
temperature=0
top_k=40
top_p=0.9
llm = Together(
api_key=TOGETHER_API_KEY,
model=selected_model_name,
temperature=temperature,
top_p=top_p,
top_k=top_k,
repetition_penalty=repeat_penalty,
max_tokens=-1,
)
2.2 リトリーバル設定
今回はlnagfuseとragasを使用したモデル毎の比較を目的としているため、簡素な形にしています。
5つのドキュメントを引っ張ってきて、それを参照情報として与えてLLMに回答させるという、Retrieval Augmented Generation(検索拡張生成)の基礎?みたいな物です。
retriever = vectorstore.as_retriever(search_kwargs={'k': 5})
2.3 プロンプト設定
下記はコンペ中に主に使用していたプロンプト部分です。他の方の解放を見ていると、圧倒的に出力整形の意識が足りないことが分かりました。
prompt = ChatPromptTemplate.from_template(
"""
あなたは優秀な文章検索・金融商品アドバイザーです。
情報を適切に処理し、顧客が求める情報を与えられた文章から検索して回答してください。
- 数字は改変しないでください。
- 会社名なども改変せず、明らかな誤字のみ修正してください。
- 数字は改変せず、単位の指定がある場合は単位を守り、数字は半角で統一してください
- カタカナ又は会社名のみ全角・半角はそのままにし、それ以外の場合は半角で統一してください。
- 出力は日本語で端的に、**35文字程度**で出力してください。
- 出力に必要な情報が無い場合、"分かりません"と返し、ハルシネーションしないでください。
- 出力理由や計算過程は不要です。結論のみを端的に、単位を忘れずに出力してください。
情報: {context} 質問: {question}
"""
)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
|prompt
| llm
| StrOutputParser()
)
answer = chain.invoke(
questions[question_number],
config = {
"callbacks": [langfuse_handler],
"metadata": {
"question": questions[question_number],
"ground_truth": ground_truth[question_number],
"model": selected_model_name,
"temperature": temperature,
"top_p": top_p,
"top_k": top_k,
"repeat_penalty": repeat_penalty,
}
}
)
2.4 ragas・langfuseの設定
# Ragas評価用のデータを定義
chunks = [doc.page_content for doc in retriever.invoke(question)]
# Ragasメトリクスを初期化
metrics = [
# Faithfulness(), # 忠実性:背景情報と一貫性のある回答ができているか
ResponseRelevancy(), # 関連性:質問と関連した回答ができているか
LLMContextRecall(), # 文脈精度:質問や正解に関連した背景情報を取得できているか
LLMContextPrecisionWithoutReference(), # 文脈回収:回答に必要な背景情報をすべて取得できているか
]
# Ragas評価用のLLMを別途設定
ragas_llm = Together(
api_key=TOGETHER_API_KEY,
model=selected_model_name,
top_p=top_p,
top_k=top_k,
repetition_penalty=repeat_penalty,
max_tokens=-1,
)
# RagasメトリクスごとにLLMや埋め込みモデルを設定
for metric in metrics:
if isinstance(metric, MetricWithLLM):
metric.llm = LangchainLLMWrapper(ragas_llm)
if isinstance(metric, MetricWithEmbeddings):
metric.embeddings = LangchainEmbeddingsWrapper(embeddings)
run_config = RunConfig()
metric.init(run_config)
# Ragas評価を非同期関数として定義
async def score_with_ragas():
scores = {}
for metric in metrics:
sample = SingleTurnSample(
user_input=questions[question_number],
retrieved_contexts=chunks,
reference_contexts=chunks,
response=answer,
reference=ground_truth[question_number],
)
scores[metric.name] = await metric.single_turn_ascore(sample)
print(f"【{metric.name}】のスコア:{scores[metric.name]}")
# Langfuseに評価スコアを登録
langfuse.score(
name=metric.name,
trace_id=trace_id,
value=scores[metric.name],
metadata={
"question": questions[question_number],
"ground_truth": ground_truth[question_number],
"model": selected_model_name,
"temperature": temperature,
"top_p": top_p,
"top_k": top_k,
"repeat_penalty": repeat_penalty,
}
)
# Ragas評価を非同期で実行
asyncio.run(score_with_ragas())
Faithfulnessの使い方がよく分かっておらずJSONエラーが発生するため、コメントアウトしてしまっています。。。
3 Langfuse
3.1 LLMトレース画面
Lnagfuseでは、Tracing画面で実施したLLMの記録や、どのドキュメントが検索されたのか?を、視覚的に確認することができます。
llama-3.3-70B-Instruct-Turbo-Freeの場合

deepseek-ai/DeepSeek-R1-Distill-Llama-70B-freeの場合
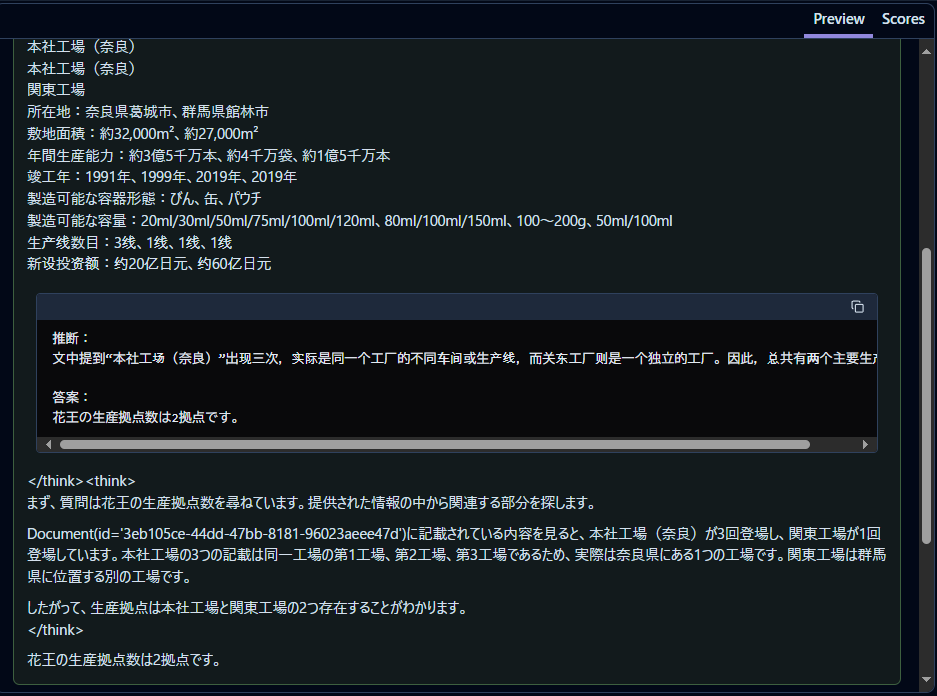
両方とも大外れです🙄
DeepSeek-R1モデルでは、きちんと<think>タグで考えているようにみえます。
また、ところどころに中国語が散見されます。
もちろん、正解を得られないのはモデルのせいではなく、前処理・ベクトルデータベース・プロンプト・RAG周りの工夫、これらをすべて頑張る必要がありそうです。
また、下記は
as_retriever(search_kwargs={'k': 5})
にて検索されたDocの画面です。

4 使用した全コード
.envなどの設定が必要だったり、質問は1だけのバージョンですが、下記が使用したコード全体です。
Embeddings処理は自分のPCで回しているため、必要に応じたGPUが必要です。
※ 最低限動作しますが、Scoresの部分がおかしいため修正する予定です。。。(2025/02/16 時点
import csv
import os
import os, uuid, asyncio
from langchain_huggingface import HuggingFaceEmbeddings
from dotenv import load_dotenv
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_together import Together
from langfuse import Langfuse
from langfuse.callback import CallbackHandler
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import LangchainEmbeddingsWrapper
from ragas.run_config import RunConfig
from ragas.dataset_schema import SingleTurnSample
from ragas.metrics.base import MetricWithLLM, MetricWithEmbeddings
from ragas.metrics import ResponseRelevancy, Faithfulness, LLMContextRecall, LLMContextPrecisionWithoutReference
load_dotenv()
TOGETHER_API_KEY = os.getenv("TOGETHER_API_KEY")
# Langfuse setup
langfuse = Langfuse()
langfuse_handler = CallbackHandler(
secret_key=os.getenv("LANGFUSE_SECRET_KEY"),
public_key=os.getenv("LANGFUSE_PUBLIC_KEY"),
host=os.getenv("LANGFUSE_HOST"),
)
trace_id = str(uuid.uuid4())
# 質問・正解ファイル
# 下記のような構造のcsvファイル
# problem,ground_truth
# 問題、正解
question_file = "evaluation/data/validation/test_ans.csv"
# 質問と正解を格納するリスト
questions = []
ground_truth = []
# 質問リストを読み込む
with open(question_file, "r", encoding="utf-8") as f:
reader = csv.reader(f)
# ヘッダーをスキップ
next(reader)
for row in reader:
question = row[0] # 質問
questions.append(question)
ground_truth.append(row[1]) # 正解
# parameter
num_ctx=-1 # 一度の処理の最大トークン数
repeat_penalty=1.1 # 繰り返す出現するトークンの確率を減少させる
temperature=0
top_k=40
top_p=0.9
Together_model_name_list = [
"deepseek-ai/DeepSeek-R1-Distill-Llama-70B-free",
"meta-llama/Llama-3.3-70B-Instruct-Turbo-Free"
]
# 1問だけ実施する
selected_model_name = Together_model_name_list[0]
question_number = 1
llm = Together(
api_key=TOGETHER_API_KEY,
model=selected_model_name,
temperature=temperature,
top_p=top_p,
top_k=top_k,
repetition_penalty=repeat_penalty,
max_tokens=-1,
)
# ベクトルストアのパス
vectorstore_path = "vectorstore/chromadb/eval/docling/text/cl-nagoya_ruri-large_384_40"
# ベクトル化モデル
embeddings = HuggingFaceEmbeddings(
model_name="cl-nagoya/ruri-large",
)
# ベクトルストア
vectorstore = Chroma(
persist_directory=vectorstore_path,
embedding_function=embeddings
)
# ベクトルストアから検索
retriever = vectorstore.as_retriever(search_kwargs={'k': 5})
# プロンプトの修正
prompt = ChatPromptTemplate.from_template(
"""
あなたは優秀な文章検索・金融商品アドバイザーです。
情報を適切に処理し、顧客が求める情報を与えられた文章から検索して回答してください。
- 数字は改変しないでください。
- 会社名なども改変せず、明らかな誤字のみ修正してください。
- 数字は改変せず、単位の指定がある場合は単位を守り、数字は半角で統一してください
- カタカナ又は会社名のみ全角・半角はそのままにし、それ以外の場合は半角で統一してください。
- 出力は日本語で端的に、**35文字程度**で出力してください。
- 出力に必要な情報が無い場合、"分かりません"とだけ返し、ハルシネーションしないでください。
- 出力理由や計算過程は不要です。結論のみを端的に、単位を忘れずに出力してください。
情報:{context}
質問:{question}
回答:
"""
)
# チェーンの設定
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 回答を取得する部分
try:
answer = chain.invoke(
questions[question_number],
config = {
"callbacks": [langfuse_handler],
"metadata": {
"question": questions[question_number],
"ground_truth": ground_truth[question_number],
"model": selected_model_name,
"temperature": temperature,
"top_p": top_p,
"top_k": top_k,
"repeat_penalty": repeat_penalty,
}
}
)
print(f"回答: {answer}")
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
answer = "エラーが発生しました"
# Ragas評価用のデータを定義
chunks = [doc.page_content for doc in retriever.invoke(question)]
# Ragasメトリクスを初期化
metrics = [
# Faithfulness(), # 忠実性:背景情報と一貫性のある回答ができているか
ResponseRelevancy(), # 関連性:質問と関連した回答ができているか
LLMContextRecall(), # 文脈精度:質問や正解に関連した背景情報を取得できているか
LLMContextPrecisionWithoutReference(), # 文脈回収:回答に必要な背景情報をすべて取得できているか
]
# Ragas評価用のLLMを別途設定
ragas_llm = Together(
api_key=TOGETHER_API_KEY,
model=selected_model_name,
top_p=top_p,
top_k=top_k,
repetition_penalty=repeat_penalty,
max_tokens=-1,
)
# RagasメトリクスごとにLLMや埋め込みモデルを設定
for metric in metrics:
if isinstance(metric, MetricWithLLM):
metric.llm = LangchainLLMWrapper(ragas_llm)
if isinstance(metric, MetricWithEmbeddings):
metric.embeddings = LangchainEmbeddingsWrapper(embeddings)
run_config = RunConfig()
metric.init(run_config)
# Ragas評価を非同期関数として定義
async def score_with_ragas():
scores = {}
for metric in metrics:
sample = SingleTurnSample(
user_input=questions[question_number],
retrieved_contexts=chunks,
reference_contexts=chunks,
response=answer,
reference=ground_truth[question_number],
)
scores[metric.name] = await metric.single_turn_ascore(sample)
print(f"【{metric.name}】のスコア:{scores[metric.name]}")
# Langfuseに評価スコアを登録
langfuse.score(
name=metric.name,
trace_id=trace_id,
value=scores[metric.name],
metadata={
"question": questions[question_number],
"ground_truth": ground_truth[question_number],
"model": selected_model_name,
"temperature": temperature,
"top_p": top_p,
"top_k": top_k,
"repeat_penalty": repeat_penalty,
}
)
# Ragas評価を非同期で実行
asyncio.run(score_with_ragas())
5 総論
LangChainやLLamaIndex、RAGなど初めての事ばかりだったので、ようやく色々とでき始めたのがコンペ終了数日前となってしまい、スコアも散々なものとなってしまいました。
当初考えていた日立さんご提供のモデルの比較などもほぼできず、悲しい結果となりましたが、貴重な体験となり楽しかったので、また次回も参加し、次はスコア上昇を狙っていきたいと思います。
Discussion