Dataikuで実施するRAG構築 2 - GeminiとPyMuPDFでPDFをOCR処理 -
前回の記事
結論のコードは下記までお進みください(リンクがうまくいきません、、、)
4 使用した全コード
上記コンペにあたり、Dataikuさんのサービスでpythonコードを書いて、Gemini使ったOCR処理を使用してみました。
下記記事などを参考にしています。
0 PDFデータを準備
【データセット】→【フォルダー】
対象のPDFデータを入れるフォルダを作成し、pdfデータをアップロードします。


1 pythonコードを準備
【コードレシピ(python)】
オリジナルのpythonコードを実行するため、格納したデータフォルダに対して、Pythonコードを適用させます。
すると、次のような画面になり、右上の【Edit in Notebook】を選択するとNoteboookとして編集する事が出来ます。ここでは、Notebookで色々試したのち、pythonに反映させて実行を押して次の処理に進むことにします。

※ 追加ライブラリー
Kernelに追加したいライブラリーがある場合、使用したいライブラリーを追加インストールする必要があります。dataikuライブラリーにてcondaまたはpipの方に記載し、保存して更新する必要があります。使用するライブラリーを追加して、更新しましょう。
pymupdf
google-genai
pillow
などなど。
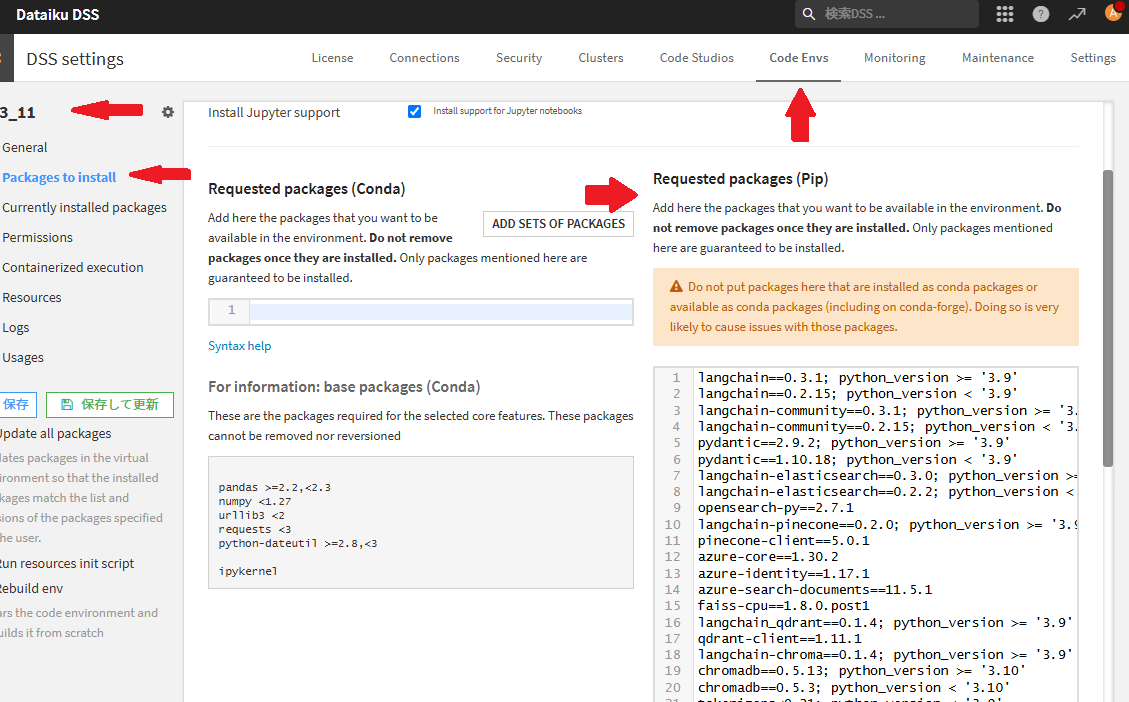

次画面のNotebookでは、作成したpython環境をKernelで指定します。
必要なライブラリーをインストールしたpythonの環境を選択します。

2 Dataikuデータの加工処理
pythonコード画面にてコードを見てみると、

2.1 データをインプット(入力部
main_pdf_datasets = dataiku.Folder("LkS11ZMy")
main_pdf_datasets_info = main_pdf_datasets.get_info()
1.フォルダーを選択(IDを取得)
2.取得したフォルダーの情報を取得
していることが分かります。
ここでは、
main_pdf_datasets → インプットフォルダー名
LkS11ZMy → インプットフォルダーのIDとなります。
左側の画面でもIDが表示されているのが確認できますね。
pythonやNotebookで扱う場合、このIDを使用する事ができるため、他のノードの部分でもこのIDを使ってコードをかけば、別の個所でもこのデータを使用する事ができそうです。
2.2 pandasデータを出力(出力部
# Write recipe outputs
md_python_df = ... # Compute a Pandas dataframe to write into md_python
# Write recipe outputs
md_python = dataiku.Dataset("md_python")
md_python.write_with_schema(md_python_df)
1.出力フォルダーに書き込むためのデータを準備(IDを取得)
2.出力フォルダー(md_python)に、md_python_dfというpandasデータを書き込み
という処理をしていることが見て取ります。
つまり、入力元 → 加工処理 → 出力先という流れになっているため、
自ら実施する処理としては、加工処理【md_python_dfというpandasデータを作成】をすればよいという事になります。
※注意点 pythonコードのエラー
Notebookでは問題ないのに、pythonコード画面に戻すとエラーになるり、Edit in Notebookも選択できなくなった!
という場合、Notebookの方でデータ確認のために記載したmain_pdf_datasets_infoという行などがある場合にエラーとなってしまいます。下記の場合(main_pdf_datasets_info)の個所を削除し、my_python_df = pd.DataFrame()のように、問題ないコードとすれば、またNotebook画面に移ることが可能です。
恐らく、コードとして実行すればおかしい事になる場合、このエラーが出る。?
(この辺り、まだ原因がよく分かっていません【2025/02/08】)
# 削除する main_pdf_datasets_info
my_python_df = pd.DataFrame()
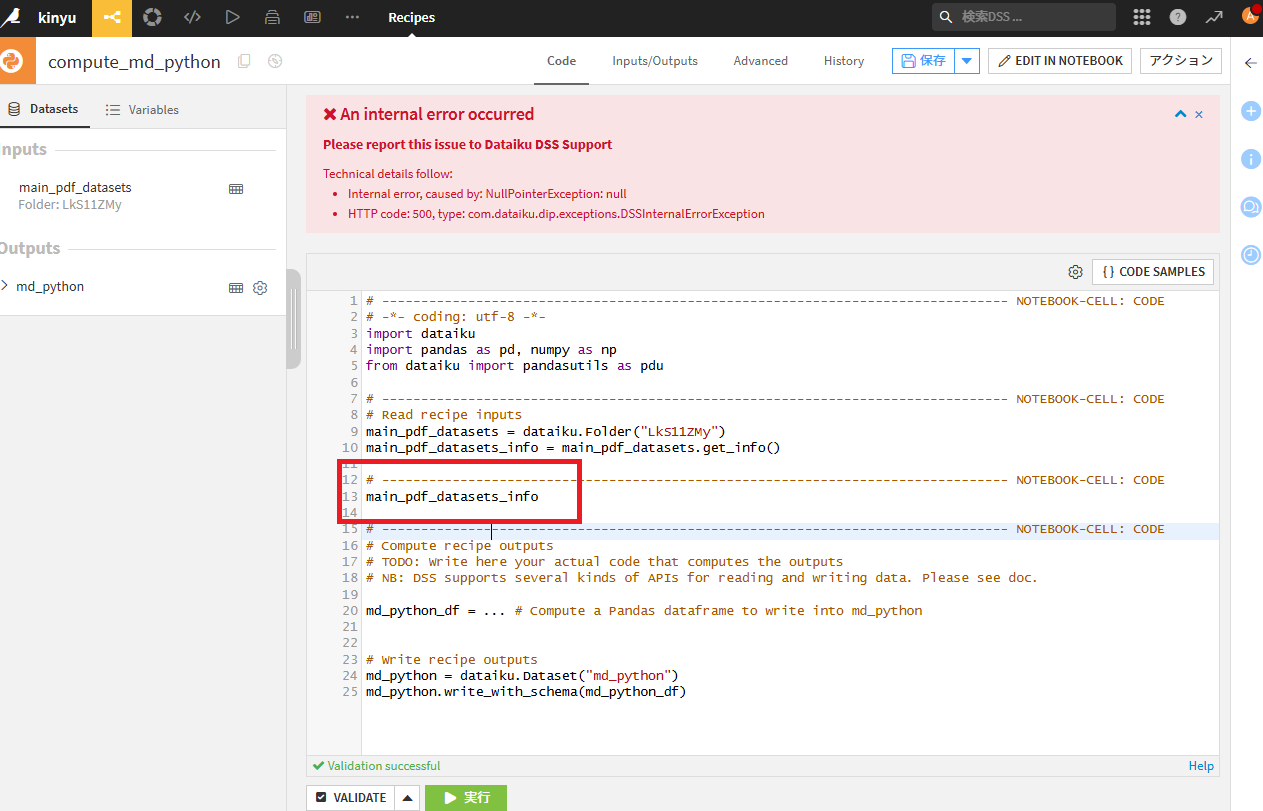
下記のような画面になると思いますが、VIEW CURRENT NOTEBOOKを選択してNotebook画面に遷移することができます。
Notebookとのデータ同期あたりと思いますが、Notebook側で該当セルを削除してSAVE BACK TO RECIPEを実行すれば、エラーが無い状態に戻せると思います。

または、Notebookで使用したライブラリーを使用する環境をAdvancedで設定していなければエラーとなります。?
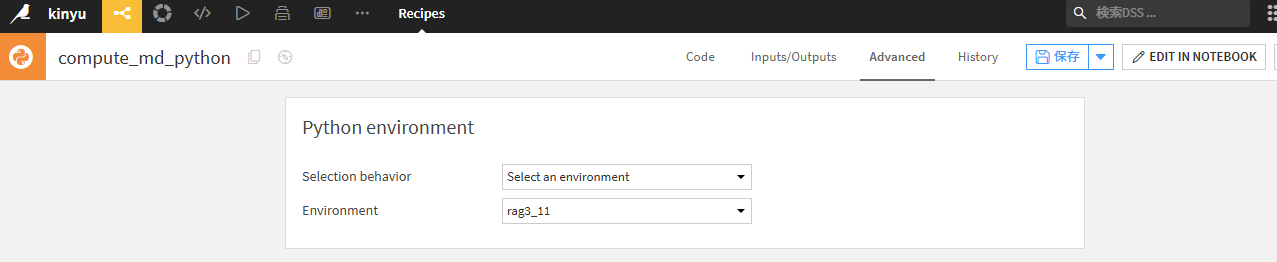
荒業で、pythonコードで適当に改行するとNotebookに遷移できるようになったりします。。。
コードに戻って実行する場合は、きちんとコードが反映されていることを確認してから実行しましょう。
3 Gemini処理を実施
3.1 DataikuのデータセットからPDFファイルを取得
まずは対象のPDFデータを、Dataikuライブラリーを使用し、リストで取得します。
ついでに、PDFファイルの読み込み順をファイル名順にしたいので、ソートしています。
# Read recipe inputs
main_pdf_datasets = dataiku.Folder("LkS11ZMy") # 入力データフォルダのIDを選択
def sort_paths(paths):
"""リスト内のファイルパスを、pdfファイル名に含まれる数値に基づいてソートします。"""
return sorted(paths, key=lambda path: int(re.search(r'(\d+)\.pdf$', path).group(1)))
# データセットのパスを取得
path = main_pdf_datasets.get_path()
# PDFファイル名のリストをglobで取得し、1~という順番に並び替える
pdf_files = glob.glob(os.path.join(path, "*.pdf"))
# ファイルを順番に並べ変える
pdf_files = sort_paths(pdf_files)
3.2 処理したいページを選択
# pdfファイルを指定して読み込む場合 (テスト用)
doc = pymupdf.open(pdf_files[0]) # 1.pdf
page = doc[0] # 1ページ目を選択
# 画像を取得する
pix = page.get_pixmap()
# BytesIOオブジェクトを作成し、Pixmapデータを書き込む
image_data = BytesIO(pix.tobytes())
# PIL Imageオブジェクトとして読み込む
image = Image.open(image_data)
3.3 Geminiにリクエスト
# Geminiと通信する
client = genai.Client(api_key=GEMINI_API_KEY)
response = client.models.generate_content(
model=GEMINI_MODEL,
contents=[
"""
OCR処理し、markdown形式で返してください。
""",
image,])
また、下記のようなコードで、Geminiから帰ってきたステータスコードやトークン使用数などもDataFrameに格納するようにしました(Dataikuさんでいうllm_ouptput列?でしょうか)
ただし、お試しとして4ページだけ処理するコードとしています。
# ファイル1と2のそれぞれ先頭2ページだけを処理するためのループ
all_data = []
global_index = 1 # グローバルインデックス
for file_index, pdf_file in enumerate(pdf_files[:2]): # 最初の2つのファイルのみ処理
doc = pymupdf.open(pdf_file)
for page_index in range(min(2, len(doc))): # 各ファイルの先頭2ページのみ処理
page = doc[page_index]
# 画像を取得する
pix = page.get_pixmap()
# BytesIOオブジェクトを作成し、Pixmapデータを書き込む
image_data = BytesIO(pix.tobytes())
# PIL Imageオブジェクトとして読み込む
image = Image.open(image_data)
client = genai.Client(api_key=GEMINI_API_KEY)
try:
response = client.models.generate_content(
model=GEMINI_MODEL,
contents=[
"""
OCR処理し、markdown形式で返してください。
""",
image,])
for candidate in response.candidates:
for part in candidate.content.parts:
metadata = {"file": file_index + 1, "page": page_index + 1} # file_indexとpage_indexを使用
all_data.append({
'index': global_index, # グローバルインデックスを使用
# 返ってきたテキスト
'text': part.text,
'metadata': json.dumps(metadata), #metadata列を追加 json形式
# 使用したモデル
'model_version': response.model_version,
# 返ってきたテキストのトークン数
'candidates_token_count': response.usage_metadata.candidates_token_count if response.usage_metadata else None, # Noneチェック
# 入力したテキストのトークン数
'prompt_token_count': response.usage_metadata.prompt_token_count if response.usage_metadata else None, # Noneチェック
# 合計トークン数
'total_token_count': response.usage_metadata.total_token_count if response.usage_metadata else None, # Noneチェック
# 出力トークンの対数確率の平均
'avg_logprobs': candidate.avg_logprobs,
# モデルがトークン生成を停止した理由 (SAFETY: 安全性違反, RECITATION: 著作権違反)
'finish_reason': candidate.finish_reason,
})
global_index += 1 # グローバルインデックスを増加
except Exception as e:
# print(f"Error processing file {file_index+1}, page {page_index+1}: {e}")
metadata = {"file": file_index + 1, "page": page_index + 1}
all_data.append({
'index': global_index,
'text': "error",
'metadata': json.dumps(metadata),
'model_version': GEMINI_MODEL, # エラー発生時もモデル名を書き込む
'candidates_token_count': "error",
'prompt_token_count': "error",
'total_token_count': "error",
'avg_logprobs': "error",
'finish_reason': str(e), # エラー情報を文字列として格納
})
global_index += 1
continue # エラーが発生した場合でも次のページに進む
4 使用した全コード
※ Dataikuさん用のコードとなっているため、使用するAPI_KEYやモデル、インプットデータやアウトプットデータなどは環境に合わせて変更する必要が有ります。
複数のPDFなどを投げた場合、一気に無料枠を超えてしまうため、気をつけてください。
4ページだけバージョン
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
import os
import re
import glob
import pymupdf
from PIL import Image
from io import BytesIO
import json
from google import genai
from google.genai import types
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
GEMINI_API_KEY = "sss"
GEMINI_MODEL = "gemini-2.0-flash"
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Read recipe inputs
main_pdf_datasets = dataiku.Folder("LkS11ZMy") # 入力データフォルダのIDを選択
main_pdf_datasets_info = main_pdf_datasets.get_info()
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
def sort_paths(paths):
"""リスト内のファイルパスを、pdfファイル名に含まれる数値に基づいてソートします。"""
return sorted(paths, key=lambda path: int(re.search(r'(\d+)\.pdf$', path).group(1)))
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# データセットのパスを取得
path = main_pdf_datasets.get_path()
# PDFファイル名のリストをglobで取得し、1~という順番に並び替える
pdf_files = glob.glob(os.path.join(path, "*.pdf"))
# ファイルを順番に並べ変える
pdf_files = sort_paths(pdf_files)
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# ファイル1と2のそれぞれ先頭2ページだけを処理するためのループ
all_data = []
global_index = 1 # グローバルインデックス
for file_index, pdf_file in enumerate(pdf_files[:2]): # 最初の2つのファイルのみ処理
doc = pymupdf.open(pdf_file)
for page_index in range(min(2, len(doc))): # 各ファイルの先頭2ページのみ処理
page = doc[page_index]
# 画像を取得する
pix = page.get_pixmap()
# BytesIOオブジェクトを作成し、Pixmapデータを書き込む
image_data = BytesIO(pix.tobytes())
# PIL Imageオブジェクトとして読み込む
image = Image.open(image_data)
client = genai.Client(api_key=GEMINI_API_KEY)
try:
response = client.models.generate_content(
model=GEMINI_MODEL,
contents=[
"""
OCR処理し、markdown形式で返してください。
""",
image,])
for candidate in response.candidates:
for part in candidate.content.parts:
metadata = {"file": file_index + 1, "page": page_index + 1} # file_indexとpage_indexを使用
all_data.append({
'index': global_index, # グローバルインデックスを使用
# 返ってきたテキスト
'text': part.text,
'metadata': json.dumps(metadata), #metadata列を追加 json形式
# 使用したモデル
'model_version': response.model_version,
# 返ってきたテキストのトークン数
'candidates_token_count': response.usage_metadata.candidates_token_count if response.usage_metadata else None, # Noneチェック
# 入力したテキストのトークン数
'prompt_token_count': response.usage_metadata.prompt_token_count if response.usage_metadata else None, # Noneチェック
# 合計トークン数
'total_token_count': response.usage_metadata.total_token_count if response.usage_metadata else None, # Noneチェック
# 出力トークンの対数確率の平均
'avg_logprobs': candidate.avg_logprobs,
# モデルがトークン生成を停止した理由 (SAFETY: 安全性違反, RECITATION: 著作権違反)
'finish_reason': candidate.finish_reason,
})
global_index += 1 # グローバルインデックスを増加
except Exception as e:
# print(f"Error processing file {file_index+1}, page {page_index+1}: {e}")
metadata = {"file": file_index + 1, "page": page_index + 1}
all_data.append({
'index': global_index,
'text': "error",
'metadata': json.dumps(metadata),
'model_version': GEMINI_MODEL, # エラー発生時もモデル名を書き込む
'candidates_token_count': "error",
'prompt_token_count': "error",
'total_token_count': "error",
'avg_logprobs': "error",
'finish_reason': str(e), # エラー情報を文字列として格納
})
global_index += 1
continue # エラーが発生した場合でも次のページに進む
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# DataFrameの作成
df = pd.DataFrame(all_data, index=[d['index'] for d in all_data])
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Write recipe outputs
md_python = dataiku.Dataset("md_python")
md_python.write_with_schema(df)
5 結果
全データに適用すると、時間もかかりAPI無料枠がすぐ終わってしまうため、2ファイルの先頭2ページ目だけで処理してみました。
まずは、1ページだけで試行錯誤するのがいいでしょう。
textを見るとmarkdown形式で返してくれる代わりに、【```markdown LLMのテキスト```】という文字が入ってしまうため、加工処理が必要そうですね。

下記は、API_KEYの設定が間違っていた場合の画像です
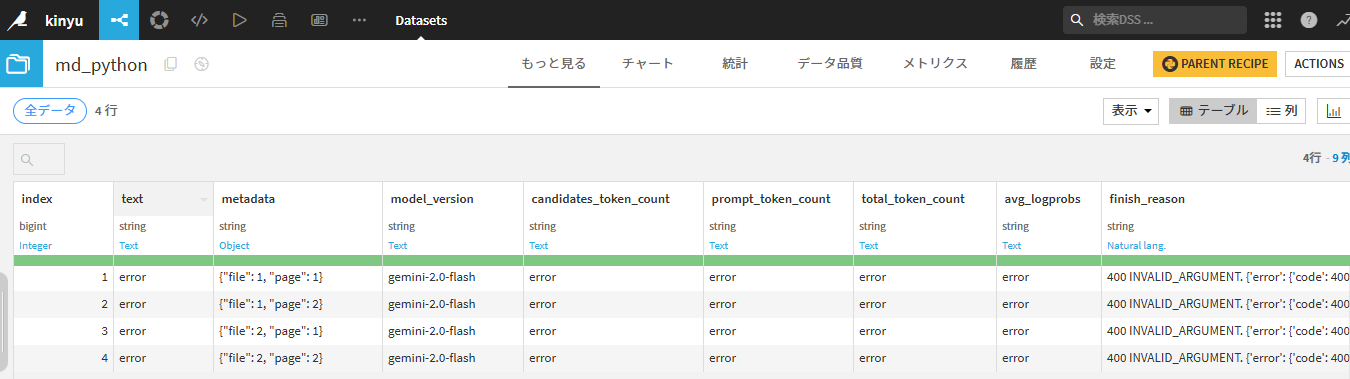
下記、参考情報
使用したデータに対する情報(トークン数の確認など
そのうち、レスポンスデータのステータス
| 列挙型 | フィルタの種類 | 説明 |
|---|---|---|
| STOP | なし | モデルが自然な停止点または指定された停止シーケンスに達したことを示します。 |
| MAX_TOKENS | なし | モデルがリクエストで指定されたトークンの最大数に達したため、トークンの生成が停止されました。 |
| SAFETY | 構成可能な安全フィルタ | 安全上の理由から回答にフラグが付けられたため、トークンの生成が停止されました。 |
| RECITATION | 引用フィルタ | 未承認の引用で回答にフラグが付けられたため、トークンの生成が停止されました。 |
| SPII | 構成不可の安全フィルタ | 回答に個人を特定できる機密情報(SPII)のコンテンツが含まれているため、トークンの生成が停止されました。 |
| PROHIBITED_CONTENT | 構成不可の安全フィルタ | 禁止されているコンテンツ(通常は CSAM)が含まれており、回答にフラグが付けられたため、トークンの生成が停止されました。 |
| FINISH_REASON_UNSPECIFIED | なし | 終了の理由は指定されていません。 |
| OTHER | なし | この列挙型は、トークンの生成を停止するその他のすべての理由を指します。トークンの生成は、すべての言語でサポートされているわけではありません。サポートされている言語の一覧については、Gemini の言語サポートをご覧ください。 |
Discussion