[実践ADK] ADKとLyriaとChainlitで音楽生成エージェント - ① ADKを利用した音楽エージェントの作成
こんにちはサントリーこと大橋です。
先日ADK 1.0.0がリリースされ、同時にADK Javaもリリースされました。
Vertex AIでは、待望のLyria 2がすべての人に開放され、利用できるようになりました。
ただADKについてはADKのサンプルを触ってみたり、チュートリアルを試している方は増えていますが、実際にUIをどう構築し、デプロイや実行をどのように行うのか、といった実運用面で悩んでいる声をよく聞きます。
今回は ADKとLyriaを利用して、音楽生成エージェントを作成し、Agent Engineへデプロイ
UIをChainlitで作成してCloud Runへデプロイして、より実践的なAI Agent アプリケーションを作成したいと思います。
やってみたら結構長くなりそうなので、何回かに分けて書きたいと思います。
今回はADKとLyriaを使って、音楽エージェントを作成してみます。
最終完成品
以下のようなAI Agentになります。
実際に上のリポジトリをクローンしていただいて諸々セットアップすると以下のようになります。
公開してほしい?お金がありません。ごめんなさい。
コード
今回作成したAI Agentは以下においてあります。**現時点では記事の準備中ですが、**コード自体は既に完成していますので、ご興味のある方はご覧ください。
システム構成
AI Agentの説明をする前に今回の最終形のシステム構成を以下に書きます。

システム構成を言葉で説明すると、以下のようになります。
- ADKを利用したAI Agentは Agent Engine上で動かす
- Session管理はVertex AI Agent EngineのSessionサービスを利用
- Artifact管理はCloud Storageを利用
- Chainlitで作成したChatUIは Cloud Run上で動かす
- AI Agentは2つのエージェントを作成
- 音楽ディレクターエージェント(RootAgent a.k.a DirectorAgent)
- 音楽ディレクターエージェントはユーザからの音楽作成依頼をある程度具体化し、作曲家エージェントへ依頼する役目をもちます。
- また通常のユーザとの会話の役割もディレクターエージェントが担います。
- 作曲家エージェント(ComposerAgent)
- 作曲家エージェントは音楽ディレクターエージェントから依頼された内容からLyriaの為にプロンプトを作成しLyriaを利用して音楽を作成します。
- Lyria用のプロンプトをしっかり理解している必要があります。
- 音楽ディレクターエージェント(RootAgent a.k.a DirectorAgent)
です。
音楽生成エージェントチームを作る
まずADKの得意なエージェントチームを作成します。
今回はユーザ作曲依頼からユーザと対話することで作成する音楽をより具体化する音楽ディレクターエージェントと、音楽ディレクターエージェントからの依頼で実際にLyriaを利用して作曲を行う作曲家エージェントを作成します。
作曲家エージェント
作曲家エージェントは2つの役割を持ちます。
- 作曲家エージェントは音楽ディレクターエージェントから依頼された内容からLyriaの為にプロンプトを作成
- Function Toolで作成された作曲ツール(Lyriaを利用)使って音楽を作成
プロンプト
以下が作曲家エージェントのプロンプトです。
上に書いたタスクを書いているのと、Lyriaで良い音楽を作成するためのプロンプトの書き方を書いています。
Lyria向けのプロンプトの書き方については以下を参照してください。
上記ドキュメントをGemini経由でLLM向けに変換&マークダウン化して、貼り付けています。
これをすることで、作曲家エージェントはLyria向けのプロンプトを理解し、正しいプロンプトを作成できます。
作曲ツール (Lyriaの呼び出し)
実際の作曲はLyriaによって行います。
Lyriaはvertex AI SDK経由で呼び出しますが、プロンプトは英語のみ、作成できる時間は30秒までなどいくつかの制約があります。
またよく失敗するので、先程のプロンプトにも失敗したらリトライするように指示してあります。
なお、Lyriaで作成される音楽データはWAV形式のため、mp3に変換してアーティファクトとして保存しています。
細かい話は以下を参照してください。
実際のコードは以下です。
その他の細かい特徴として、pydub経由でWAVからmp3への変換を行っていますが、pydubは内部でFFmpegを利用しています。ローカル環境で実行する場合はFFmpegのインストールが必要ですが、Agent EngineにはFFmpegがインストールされていないため、対策しないとエラーになります。
このため、デプロイの段階でFFmpegのバイナリをダウンロードし、コードと一緒にAgent Engineへデプロイしています。これにより、pydubがエラーを吐いた場合でも、ダウンロードしたFFmpegを利用して処理を継続できるようにしています。
generate_music_tool関数のコード
import base64
import io
import logging
import uuid
import google.auth
from google.adk.tools import ToolContext
from google.cloud import aiplatform
from google.genai import types
from google.protobuf import json_format
from google.protobuf.struct_pb2 import Value
from pydub import AudioSegment
loggger = logging.getLogger(__name__)
async def generate_music_tool(prompt: str, negative_prompt: str, seed: int, sample_count: int, tool_context: ToolContext):
"""
Generates music based on the provided prompts by utilizing Google's AI
Platform services and the lyria-002 model. The function is responsible for setting
up the client, creating request instances and parameters, and executing the request
to retrieve generated samples. The responses consist of generated musical data
predictions.
The generated music will be saved to artifact, The filename will be like 'generated_audio_{sample_number}.mp3'.
:param prompt: The prompt to use for generating music in English, it sends to Lyria model.
:param negative_prompt: The negative prompt for avoiding specific features in the
generated music. When you don't need passing, you can set the empty string.
:param seed: The random seed for initialization to control the variability in
output. When you don't need passing, you can set -1.
:param sample_count: The number of samples to generate. it must be 1-4.
:param tool_context: An object representing the contextual or environmental
information required for the tool's execution.
:return: list of the generated music_id, when it returns None, the process is failed. please retry again with changing the prompt.
"""
try:
client_options = {"api_endpoint": "aiplatform.googleapis.com"}
client = aiplatform.gapic.PredictionServiceClient(client_options=client_options)
params: dict[str, str|int] = {"prompt": prompt}
if negative_prompt:
params["negative_prompt"] = negative_prompt
if seed > 0:
params["seed"] = seed
if sample_count:
params["sample_count"] = sample_count
instance = json_format.ParseDict(params, Value())
instances = [instance]
parameters_dict = {}
parameters = json_format.ParseDict(parameters_dict, Value())
_, project_id = google.auth.default()
endpoint_path = f"projects/{project_id}/locations/us-central1/publishers/google/models/lyria-002"
loggger.info(f"endpoint path {endpoint_path}")
response = client.predict(endpoint=endpoint_path, instances=instances, parameters=parameters)
predictions = response.predictions
loggger.info(f"Returned {len(predictions)} samples")
mp3_list = []
for index, pred in enumerate(predictions):
bytes_b64 = dict(pred)["bytesBase64Encoded"]
decoded_audio_data = base64.b64decode(bytes_b64)
audio_segment = AudioSegment.from_wav(io.BytesIO(decoded_audio_data))
out = io.BytesIO()
try:
audio_segment.export(out, format="mp3", bitrate="192k")
except Exception as e:
loggger.exception(f"failed to export mp3 audio {e}, retrying with local ffmpeg")
audio_segment.converter = "composer/ffmpeg-7.0.2-amd64-static/ffmpeg"
audio_segment.export(out, format="mp3", bitrate="192k")
part = types.Part.from_bytes(data=out.getvalue(), mime_type="audio/mp3")
artifact_id = uuid.uuid4().hex
await tool_context.save_artifact(artifact_id, part)
mp3_list.append(artifact_id)
tool_context.state.update({"music_artifact_list": mp3_list})
return mp3_list
except Exception as e:
loggger.exception(f"failed to create the music. {e}")
return None
Agentのコード
以下が作曲家エージェントのコードです。
上記で主な特徴については説明済みですので、ここでは割愛します。
音楽ディレクターエージェント
音楽ディレクターエージェントは主にユーザとの対話を担当します。
ユーザーからの音楽制作依頼からユーザとの対話を繰り返すことで最低限音楽が作成できる様にユーザーの意図を具体化し、作曲家エージェントへ実際の制作依頼を行います。
プロンプト
プロンプトは以下です。
上に書いたタスクを書いてるぐらいです。
特徴を上げると、ユーザーへの質問がしつこくならないように制御を行っているぐらいです。
なお、実際にユーザーへ公開するAI Agentの場合、システムプロンプトを非公開にするなど、セキュリティ面を考慮したプロンプトを追加することをおすすめします。
Agentのコード
音楽ディレクターエージェントのコードは以下です。
音楽ディレクターエージェント
import copy
import logging
import os
from google.adk.agents import Agent
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse
from google.adk.tools.agent_tool import AgentTool
from google.genai import types
from .prompts import instructions
from .sub_agents.composer.agent import root_agent as composer_agent
if "GOOGLE_CLOUD_AGENT_ENGINE_ID" in os.environ:
# run on agent engine
import google.cloud.logging
client = google.cloud.logging.Client()
client.setup_logging()
call_composer_agent = AgentTool(composer_agent)
logger = logging.getLogger(name)
async def load_artifact(callback_context: CallbackContext, llm_response: LlmResponse) -> LlmResponse:
if not callback_context.state.get("music_artifact_list"):
return llm_response
parts_new = copy.deepcopy(llm_response.content.parts)
for filename in callback_context.state.get("music_artifact_list"):
logger.info(f"Loading artifact: {filename}")
if "GOOGLE_CLOUD_AGENT_ENGINE_ID" in os.environ:
parts_new.append(types.Part.from_text(text=f"<artifact>{filename}</artifact>"))
continue
else:
audio_artifact = await callback_context.load_artifact(filename=filename)
if audio_artifact is None:
continue
audio_bytes = audio_artifact.inline_data.data
mime_string = 'audio/mp3'
parts_new.append(types.Part.from_bytes(data=audio_bytes, mime_type=mime_string))
callback_context.state.update({"music_artifact_list": None})
llm_response_new = copy.deepcopy(llm_response)
llm_response_new.content.parts = parts_new
return llm_response_new
root_agent = Agent(
model='gemini-2.0-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction=instructions(),
tools=[call_composer_agent],
after_model_callback=load_artifact
)
重要な点は2つあります。
1つ目は after_model_callback に登録されている load_artifactです。
これは、作曲家エージェントにより作成された音楽がアーティファクトとして登録されているので、それをユーザーへ返すための処理を行っています。
ローカルやCloud Run上でAgentを動かす場合は、そのままAgentのメッセージとして返却しますが、
Agent Engineの場合は、アーティファクトのidのみをテキストとして返却するようにしています。
Agent Engineは制限があるのか、メッセージサイズが大きいとエラーとなるためです。
クライアント側でこのアーティファクトのidを受け取って改めてダウンロードすることを想定します。
async def load_artifact(callback_context: CallbackContext, llm_response: LlmResponse) -> LlmResponse:
if not callback_context.state.get("music_artifact_list"):
return llm_response
parts_new = copy.deepcopy(llm_response.content.parts)
for filename in callback_context.state.get("music_artifact_list"):
logger.info(f"Loading artifact: {filename}")
if "GOOGLE_CLOUD_AGENT_ENGINE_ID" in os.environ:
parts_new.append(types.Part.from_text(text=f"<artifact>{filename}</artifact>"))
continue
else:
audio_artifact = await callback_context.load_artifact(filename=filename)
if audio_artifact is None:
continue
audio_bytes = audio_artifact.inline_data.data
mime_string = 'audio/mp3'
parts_new.append(types.Part.from_bytes(data=audio_bytes, mime_type=mime_string))
callback_context.state.update({"music_artifact_list": None})
llm_response_new = copy.deepcopy(llm_response)
llm_response_new.content.parts = parts_new
return llm_response_new
2つ目はComposer AgentをAgentToolでToolとして扱っている点です。
Agentチームを作る場合、sub agentの使い方としては、sub_agentsに登録するか、AgentToolを利用して、toolとして利用する方法があります。
今回のケースでは、ユーザとの対話はディレクターエージェントの責任としており、作曲家エージェントはあくまで、ディレクターエージェントから呼び出されるものとしているため、AgentToolとして扱っています。
この辺りはUXにも関わるので、両方試してみると良いと思います。
試す
では実際にadkの開発環境を利用して、これらのAgentチームを動かしてみましょう。
adk web

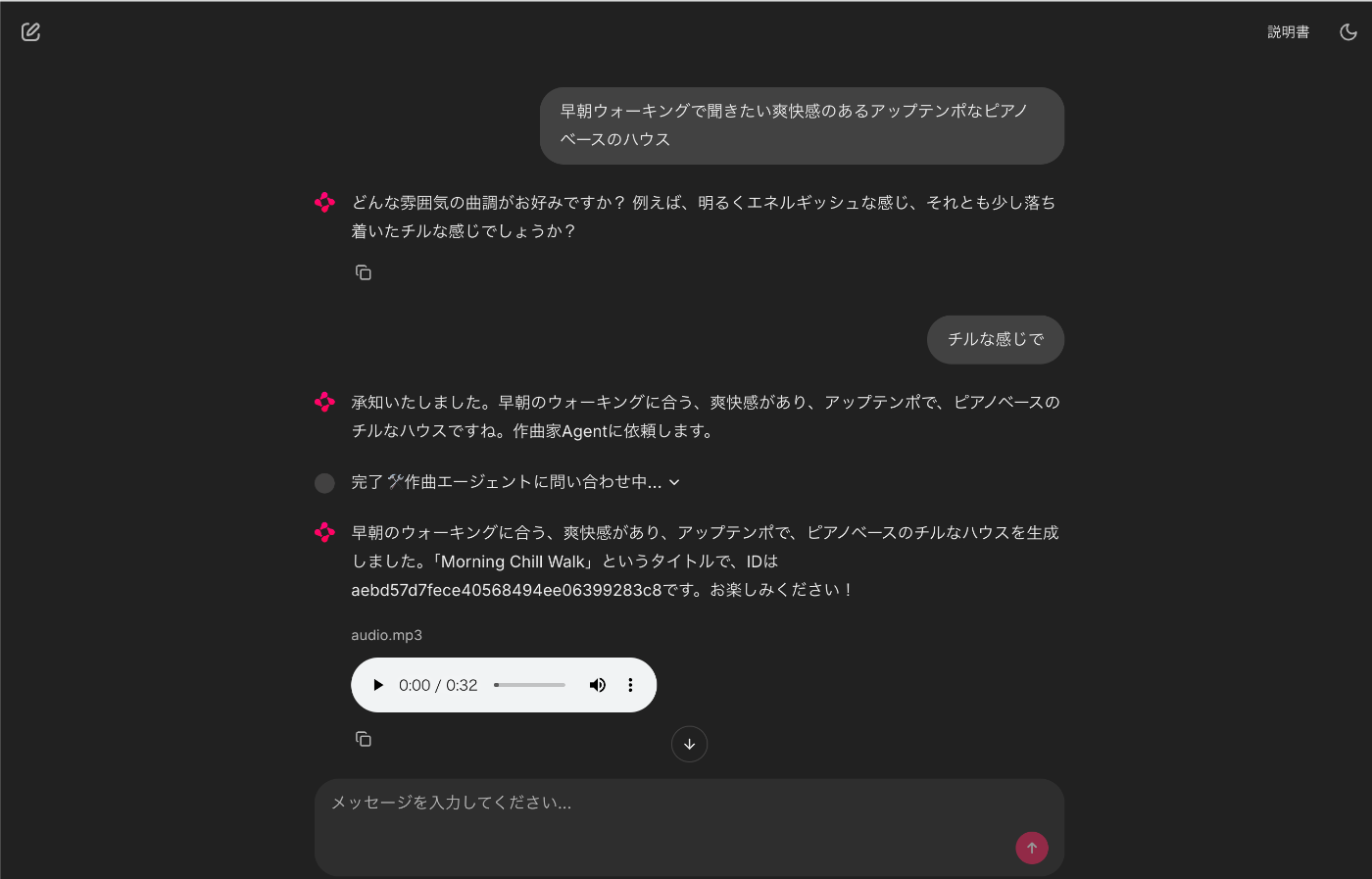
ディレクターエージェントに作曲依頼をすると、よりイメージが具体化するように聞いてきます。
そして一通り情報を聞くと、作曲家エージェントへ聞いた内容を渡します。

作曲家エージェントが作曲を行いartifactへ保存し、ディレクターエージェントに返却します。
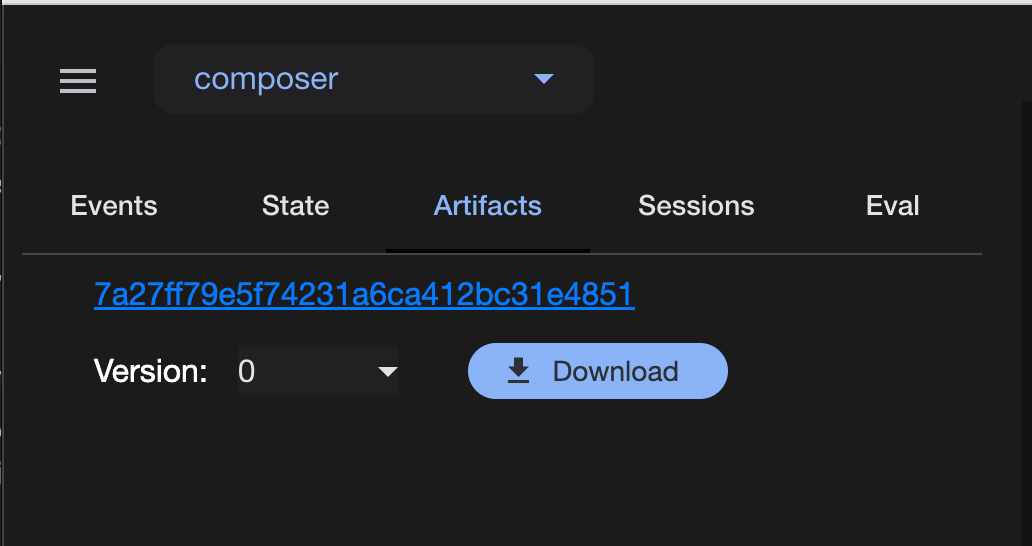
artifactにデータも保存されています。
ちょっと実際に作った曲を何処かに上げたいのですが、場所がないのでごめんなさい。
まとめ
今回はLyriaを利用した、音楽生成エージェントチームを作成しました。
Lyriaを使うことで音楽を簡単に作成することができました。
また、AI AgentにLyria用のプロンプトを作成させることで、Lyriaに適したプロンプトを作成することができました。
このようなAgent間の分業(特化)はADKの得意分野なのでだいぶ少ないコードで作ることができました。
次回はUI側について説明したいと思います。
Discussion