🤖
π0: A Vision-Language-Action Flow Model for General Robot Control
概要
-
Physical Inteligenceが内製している学習モデルのPaper
- Physical Inteligenceは2024年創業のサンフランシスコのスタートアップ企業
- あらゆるロボットを制御し、あらゆるタスクを実行できる基盤モデルの研究開発を行っている
- CEOはKarol Hausmanであり、Sergey Levineや、Chelsea Finnが参加している
- Physical Inteligenceは2024年創業のサンフランシスコのスタートアップ企業
- 同社の開発したプロトタイプの学習モデルであるπ0と、提案手法における事前学習・事後学習の効果について紹介されている
- VLMとflow matchingを組み合わせた手法を提案
- Pre-trainingとPost-trainingの効果を検証し、提案手法では有効である結果が得られている
- pre-trainingで幅広い可用性を獲得し、post-trainingで複雑なタスクに適応させる
- 比較では、OpenVLA、Octo、ACT、DPと比較しており、いずれのタスクに対して、比較手法より提案手法の方が高性能 or 同程度の結果が得られている
- Published in their website at 2024/10/31
Introduction・Related work
- 様々な学習モデルが開発されており、人間が容易に取り組むことができないタンパク質の立体構造の予測のような複雑な問題を解く場合にも使用することができるようになってきている
- しかし、多様性という面では、まだ人間の方が優っている
- 人間は、環境の変化や条件の変化などに対応しつつ、問題に取り組むことができる
- 多様性を含むモデルも開発されているが、現実世界の物理的な相互作用の理解が不十分である
- そのため、物理的な相互作用をデータの中にもつロボットのデータが必要である
- また、物体認識や自然言語処理のように学習したい内容だけで構成されるデータで事前学習するより、多様性に富むデータで事前学習した場合の方が性能が良くなる事例のように、ロボットの事前学習でも、目的のタスクだけでなく、多様性に富むデータで学習したほうが良い可能性はある
- タスクに少し失敗した際に、修正/回復としての動作を獲得できる可能性もある
- ただし、データセットに失敗→修正のようなデータを含めることができる
- タスクに少し失敗した際に、修正/回復としての動作を獲得できる可能性もある
- 上記のようなメリットを獲得する可能性はあるが、ロボットの基盤モデルの開発はいくつもの課題が存在する
- 1つ目は、大規模な事前学習による最大のメリットを得るためには、相応の規模で実施する必要があること
- 2つ目は、多様なデータと複雑な現実環境を適切に扱うことができるようなモデルアーキテクチャにする必要があること
- 3つ目は、正しい学習方法を用いること
- これが一番重要である
- 複雑なタスクに対して、柔軟かつロバストに対応することができるモデルの学習方法はモデルのアーキテクチャと同様に重要である
- 提案手法の学習では、他の言語モデルと同様に事前学習と事後学習を実施している
Overview
- 学習は事前学習と事後学習の2段階に分けている
- 事前学習(pre-training)
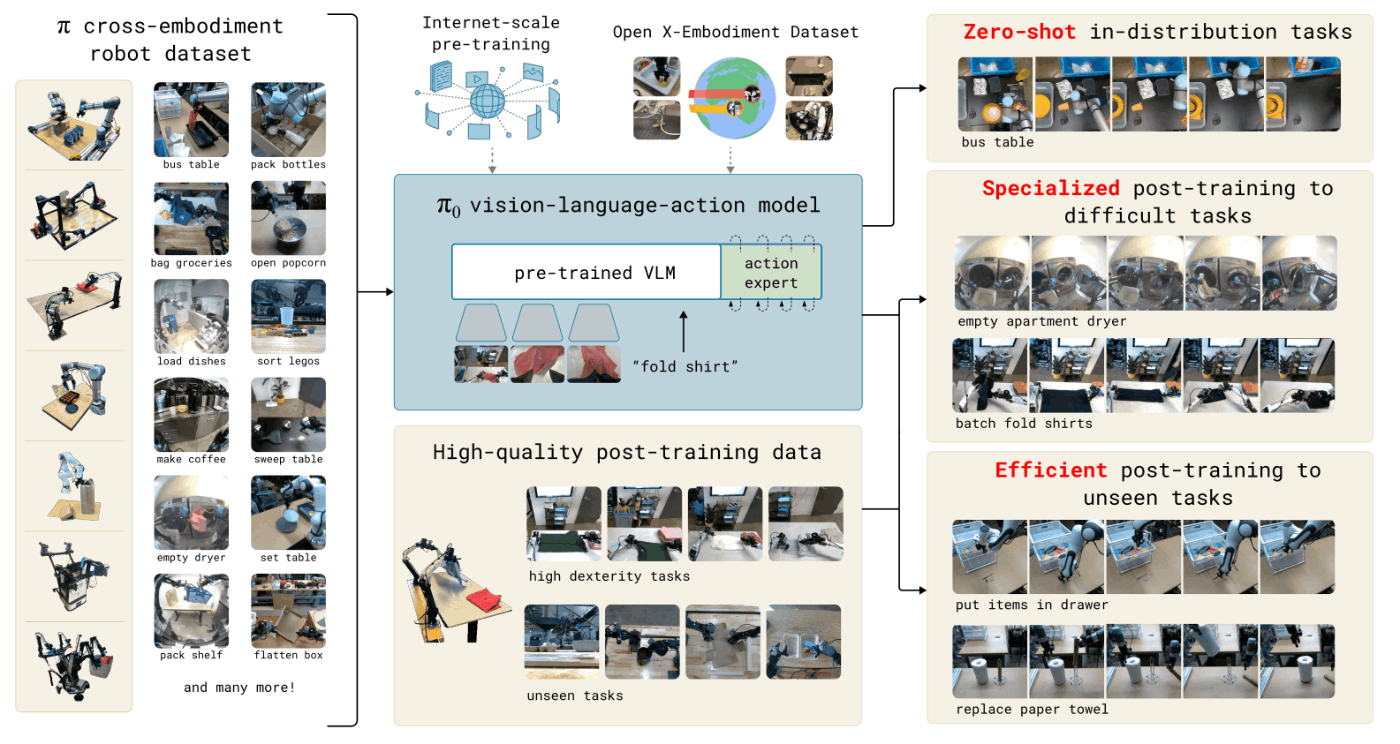
- 使用するデータセットでは、OXEのデータセットと自前で用意するデータセットを混合させている
- OXEのデータセットは22台のロボットから収集したデータで構成
- 自前のデータセットは、7つの異なるロボットで68種類のタスクを実行した際のデータで構成
- 実際に学習する際には、タスク名やロボットの軌道に対するラベルも含めて使用している
- 事前学習の目的は、基礎モデルの獲得であり、幅広い可用性と汎用性をもたせることが重要である
- そのため、基礎モデルはある1つのタスクに対して特化した性能の獲得は必須ではない
- 使用するデータセットでは、OXEのデータセットと自前で用意するデータセットを混合させている
- 事後学習(post-training)
- より複雑で器用さが必要なタスクを実行するために実施する
- 質が良いデータを用いて、あるタスクに対してモデルをFine-tuningする
- 検証では、効果的な事後学習(小〜中程度量のデータ)と高品質な事後学習(大容量のデータ)を行った
- 事前学習(pre-training)
- 学習モデル
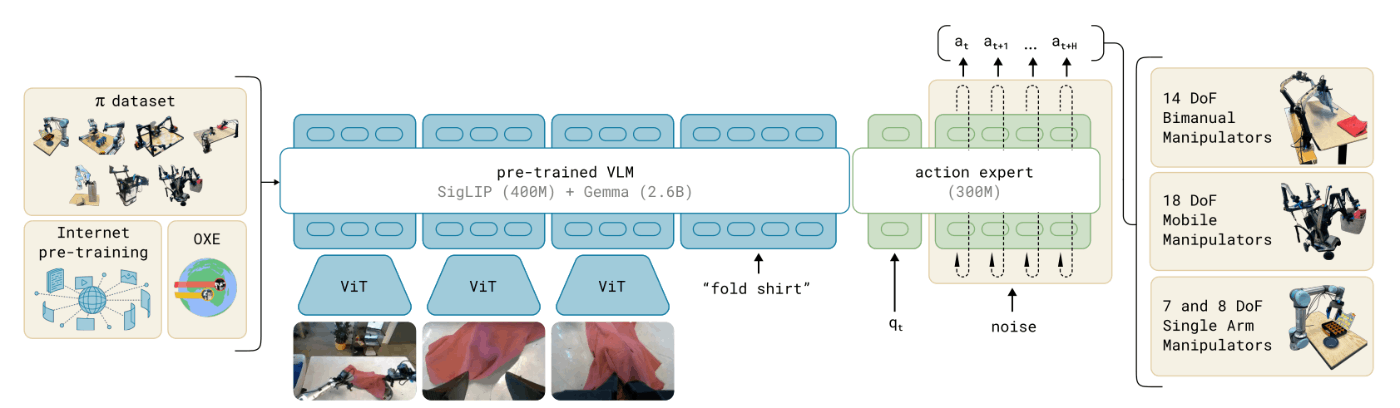
- モデルは、PaliGemma VLMをベースに、改良したものを使用している
- ベースモデルにflow matchingを用いたAction出力部を追加している
- PaliGemmaは比較的小さいモデルであり、リアルタイムな推論が可能であるため採用しているが、フレームワークには、他のPre-trained VLMを組み合わせることは可能
- モデルは、PaliGemma VLMをベースに、改良したものを使用している
The π0 MODEL
- 他のTransformerをbackbornとするモデルと同様に、画像エンコーダ部分では、ロボットのカメラ画像を言語トークンと同様の次元にエンコードしている
- また、backbornには、ロボット用の入力と出力を追加している
- 提案手法では、Actionを連続値として表現するために、conditional flow matchingを使用している
- flow matchingにより、高い正確性と多峰性を備え、複雑で高周期な制御が必要なタスクを扱えるようになる
- モデルのアーキテクチャはTransfusionから着想をえており、複数の入力から1つのTransformerを学習する構成になっている
- 入力トークンには、flow matchingの損失から得られる連続的な出力値と一致するトークンと、クロスエントロピー損失から得られる離散的な出力値に一致するトークンを使用している
- Transfusionに基づいて、ロボットのActionとStateのトークンに別々の重みを適用することにより、性能が向上することを確認した
- Atはアクションのシーケンス
- ChunkしているActionのサイズは50にしている
- atはaction tokenであり、action exportへの入力である
- ChunkしているActionのサイズは50にしている
- Otは複数の画像(It)、言語トークン(lt)、ロボットの各関節値(qt)で構成されている
- 画像の枚数はロボットに搭載されているカメラによって変わるため、2~3種とされている
- 画像とロボットの関節値は、トークンと同じ空間にエンコードして使用している
- action expertでは全てのaction tokenを互いに関連付けするために、full bidirectional attetion maskを使用している
- 提案するモデルは、0から学習することも、他の関節VLMのバックボーンからFine-tuningすることも可能であるが、検証では、PailGemmaをベースモデルとして使用している
- モデルの大きさと性能の比率がちょうど良いモデルとして、PailGemmaを使用した
- PailGemmaは、OSSで30億個のパラメータを持つモデル
- 追加でAtion exportのための、3億個のパラメータを追加し、合計で33億個のパラメータを持つモデルとして使用した
- また、4.7億個のパラメータで構成される小さいモデル(π0-small)も用意した
- このモデルではVLMのInitializationは入っていないため、VLMの効果を確かめることができる
Data collection and training recipe
- 幅広い機能をもたせた学習モデルには、表現力豊かなモデルだけでなく、正しいデータセットとそれ以上に正しい学習方法が必要である
- LLMの学習で行われているように、複数の段階に分けて学習を行う方式(pre-trainingとpost-training)を採用している
- pre-tainingでは、幅広い知識を獲得させるために実施され、post-trainingでは、あるタスクに特化するようにさせるために実施される
- 上記のように各段階での学習の目標が異なるため、データセットもPre用とPost用で分けている
- pre用のデータセットは、可能なかぎり幅広いタスクで構成され、各タスクの挙動も、多様性を持たせている
- post用のデータセットは、あるタスクにおいて効果的に実施するために、必要な挙動を含める必要がある
- 直感的には、Pre用のデータセットでは、(質は高く)幅広いデータで構成することにより、復帰動作や複雑性が高い状況で上手く実行できるようになる
- 上記は、質が高いPost用のデータセットでは獲得できない
Pre-training and post-training
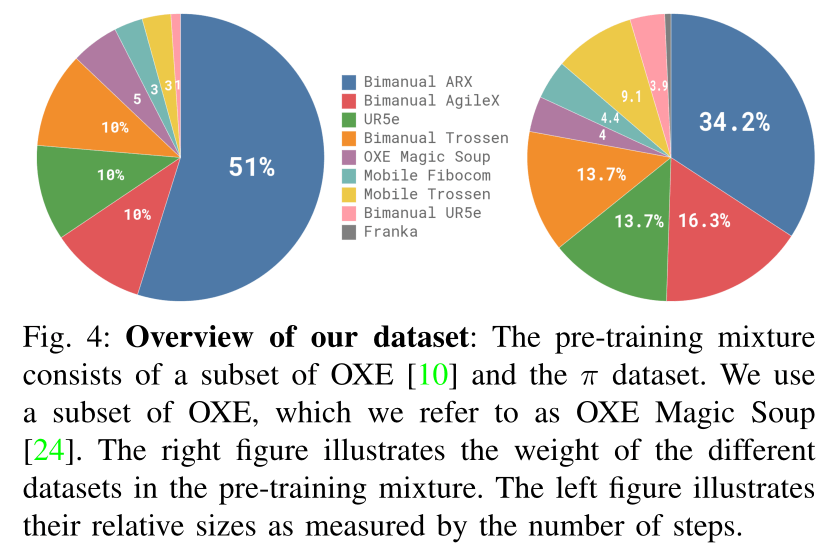
- pre-training用のデータの全データ中の9.1%はOSSのOXE,Bridge V2、DROIDで構成している
- これらのデータセット中のデータは、1、2個のカメラ画像と2~10Hz程度の低周期な制御レートで操作されているロボットで構成されている
- 自前で構築しているデータセットは、より複雑で器用なタスクに対応するために、9億300万個のデータで構築している
- 制御周期を30Hzだとすると、約8361時間のデータになる
- 1億600万個のデータは、単腕のアームで取得し、7億9700万個のデータは双腕のアームで取得している
- ロボットは7種類、タスクの種類は68種であり、それぞれのタスクは複雑な動作が含まれている
- Pickup等ではなく、Bussingのような動詞で表現されるタスク内容になっている
- データセットはタスクが均等になるように構成していないため、重み付けをして使用している
- また、QtやAtの次元はデータセット内のロボットの最大次元で固定している
- 次元の低いロボットでは、QtやAtの必要ない部分を0埋めしている
- post-training用のデータは、簡単なタスクでは5時間程度のデータが必要であり、複雑なタスクの場合は100時間以上のデータが必要になる
Launguage and high-level policies
- 複雑なタスクを実行するためには、入力された文章の意味を理解する必要があるため、sematic reasoningや高レベルなPoliciyが必要になる
- 提案手法では、入力に言語も入れ込んでいるため、SayCanのよに、LLMによりタスクをサブタスクに分けて実行することができる
Robot system detailes
- データセット中で使用しているロボットは次の通り
- UR5e
- Bimanual UR5e
- Franka
- Bimanual Trossen
- Bimanual ARX and bimanual AgileX
- Mobile Trossen and mobile ARX
- Mobile Fibocom

Experimental evaluation
- 次の点について検証されている
- Pre-trainingによる性能の向上
- 言語入力に対する表現の忠実性
- 他の器用なタスクを実行するモデルとの違い
- 複雑な他段階タスクへの適用可能性
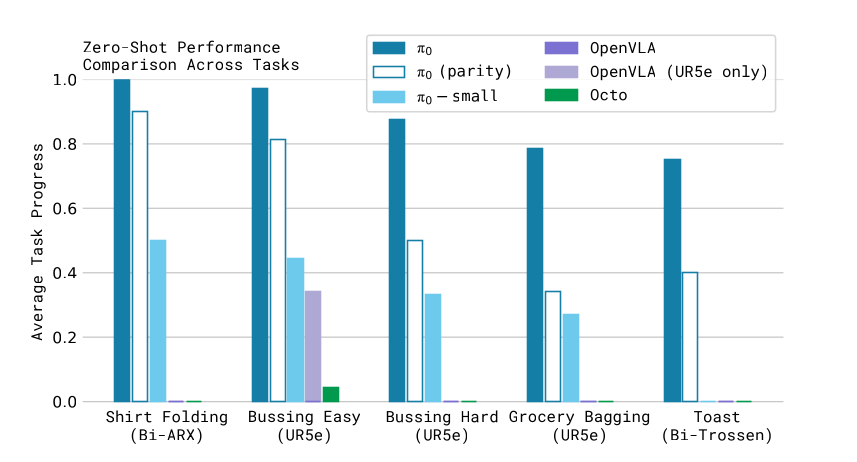
Evaluating the base model
- Pre-trainingのみのモデルで、5つのタスクを実行した
- shirt folding
- bussing easy
- bussing hard
- grocery bagging
- toast out of toaster
- 比較モデルも同様のデータセットで学習させた
- 比較モデルは次の通り
- OpenVLA
- 70億のパラメータを持つモデル
- Action Chunkingや高周期な制御がサポートされていないので、自前のデータセットを適用させることがかなり困難だった
- Octo
- 9300万個のパターメータを持つモデル
- OctoはVLAではないため、拡散プロセスでActionを生成するようにしている
- 学習は自前のデータセットで実施した
- OpenVLA
- 時間が限られていたため、OpenVLAとOctoの学習のエポック数は、提案手法と異なっている
- そのため、提案手法を同じステップ数程度に設定し学習したものとも比較する
- また、OpenVLAについては、UR5eでFine-tuningしたモデルも用意した
- 比較モデルは次の通り
- 評価指標は、10エピソードで構成されるタスクの1エピソードごとの成功率の平均値とした
- フルで成功すると1.0で、部分的に成功すると0.~となる
- 結果
- π0は、全てのタスクにおいてベースラインをほぼFullの成功率を示した
- Parity版やSmall版でも、OpenVLAやOctoよりも良い結果だった
- 上記より、大規模で表現力豊かなモデルと拡散モデルやflow mathicngで複雑なモデルの分布を組み合わせることによって、性能が向上するとしている
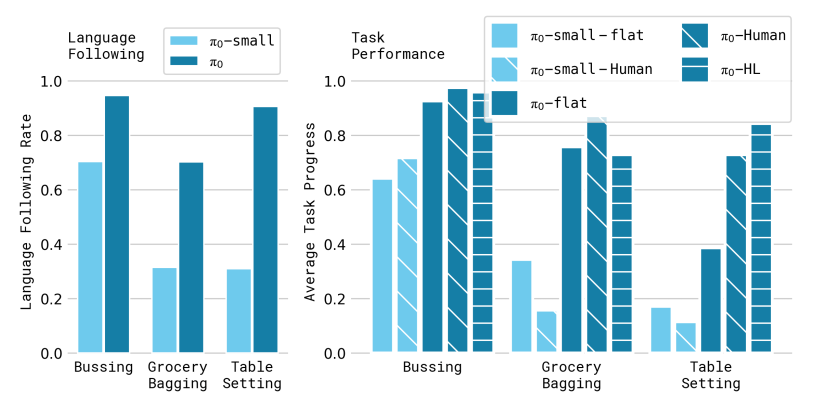
Following launguage commands
- 評価用のタスクにFine-tuningした提案手法と、Small版に対して、入力の抽象具合を変化させ、どの程度言語司令に従うか検証している
- π0-flat
- 直接、タスク名を入力
- π0-human
- 人間が高レベルな言語司令を細かい段階に分けて入力
- π0-HL
- High-Level VLMからの出力を入力
- π0-flat
- 各タスクは、いくつかの言語司令で構成されている
- Bussing
- clean a table, placing dishes, cutlety in a bin, trash into a trash binが含まれる
- Table Seeting
- take out items from a bin to set a table, including a place mat, dishes, silverware, napkin, and cupsが含まれる
- Grocery bagging
- pack grocery items, such as bags of coffee beans, barley, marshmallow, seaweed, almonds, spaghetti, and cans into a bag
- Bussing
- 各タスクにおいて10回以上の回数を実施した
- 結果
- タスク名をHigh level VLMや人間が細かい段階に分けて入力することにより性能が向上した
Learing new dexterous tasks
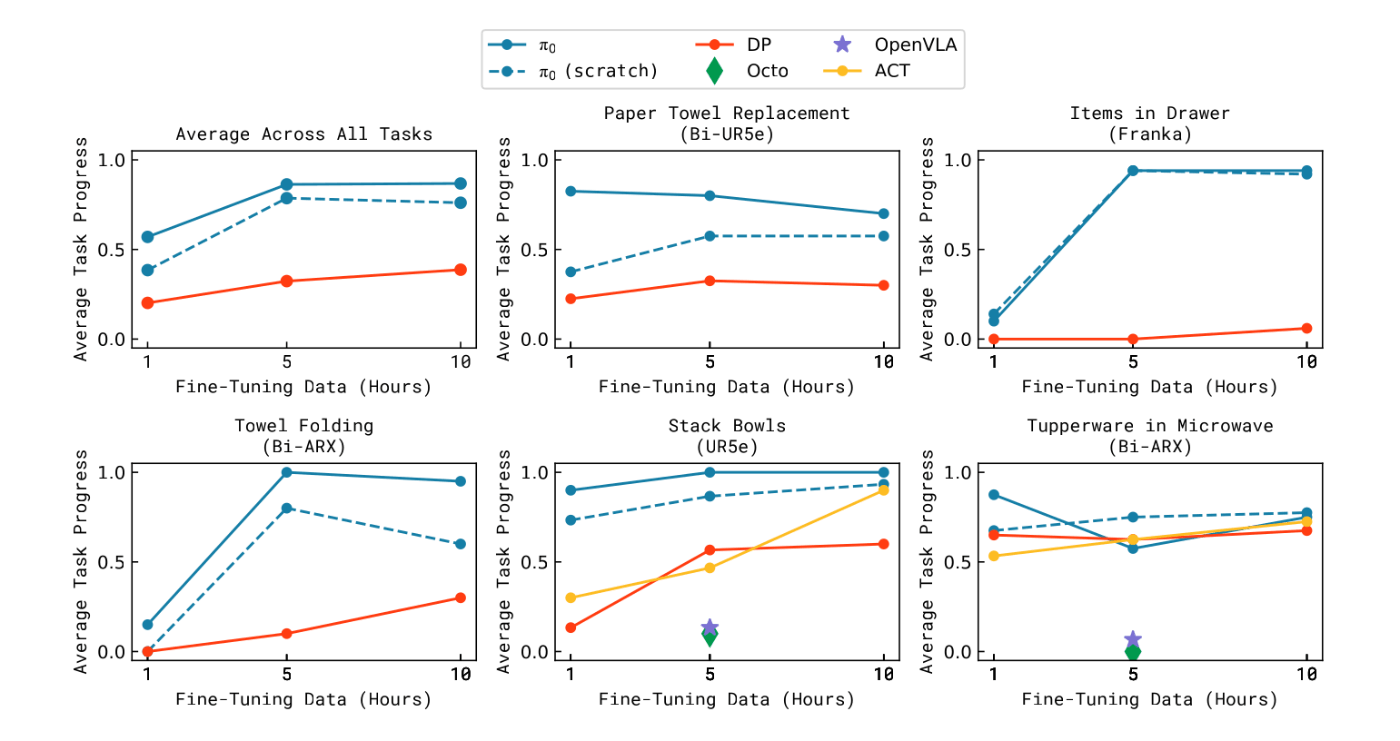
- データセットに含まれていない新規のタスクに対して、データセットの量を変化させ、どの程度で学習されるかを検証した
- 新規タスクについては、pre-trainingに含まれるタスクに類似しているものから、類似していないものまで設定している
- UR5e stack bowls
- bussingに似ているため、比較的容易
- Towel folding
- shirt foldingに似ているため、比較的容易
- Tupper in microwave
- 対象のオブジェクトがデータセットに含まれていに場合もあるため、中程度の難易度
- Paper towel replacement
- タオルホルダーはデータセットに含まれていないので、高難度
- Franka items in drawer
- Frankaのデータセットに似たタスクはないため、高難度
- UR5e stack bowls
- Fine-tuneingさせたOpenVLAとOcto、ACT、Diffusion Policyと比較する
- OpenVLAのFine-tuningさせる際のCheckpointは公開されているものを使用
- ACTとDPは、比較的少ないデータセットで器用なタスクを実行するモデルとして比較対象にしている
- 結果
- 各タスクで10回程度思考した際の成功率を比較
- 似ているタスクだと、性能が出やすく、全くデータセットに含まれていないタスクであってもある程度の性能が出る
- OpenVLAとOctoは最も成功率が低い
- Pre-trainedされてるモデルとされていないモデルでは、性能差が2倍になるタスクもある
Mastering complex multi-stage tasks
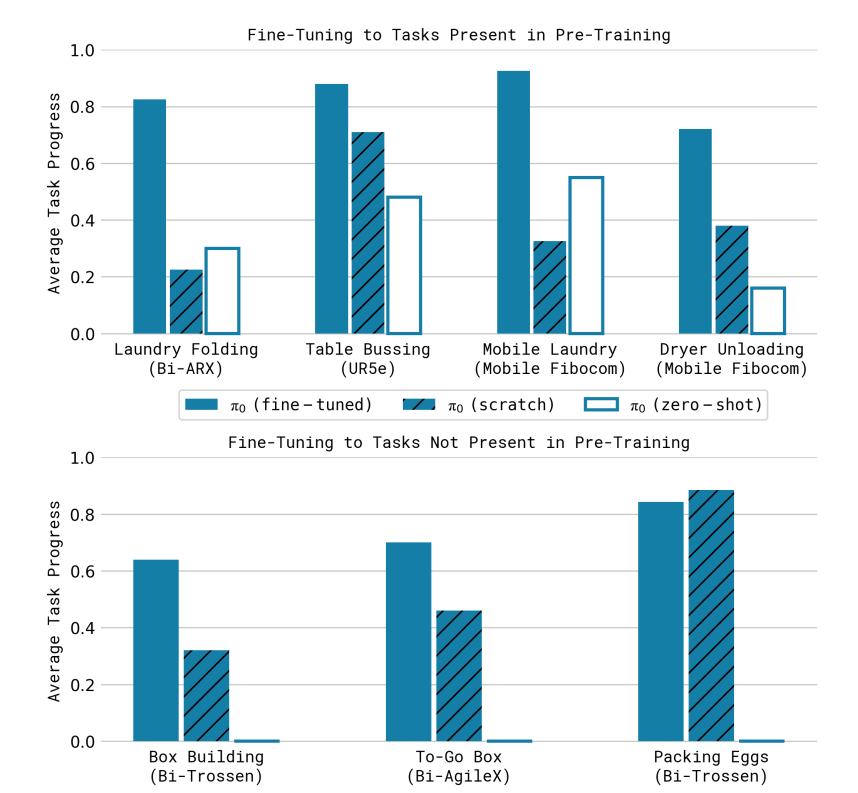
- 複数の段階で構成されるタスクへの対応具合を検証する
- 検証で設定したタスクh次の通り
- Laundry folding
- 移動なし、かごの中の服を取り出し、畳み、重ねる
- pre-trainingのデータに含まれている
- Mobile laundry
- laundry foldingを実行するための台車移動
- pre-trainingのデータに含まれている
- Dryer unloading
- 乾燥機から衣服を取り出し、かごに入れる
- pre-trainingのデータに含まれている
- Table bussing
- テーブルの上の物体をどかしてきれいにする
- 皿の上に食べ物がある場合には、それらをゴミ箱にいれてから片付ける
- pre-trainingのデータに含まれていない
- Box building
- 畳まれているダンボールを組み立てる
- pre-trainingのデータに含まれていない
- To-go box
- 皿から食べ物を箱に詰める
- pre-trainingのデータに含まれていない
- Packing eggs
- ボールの中にある6個の卵を卵パックに入れる
- pre-trainingのデータに含まれていない
- Laundry folding
- 全ての工程を実行できた場合には、1.0とし、部分的にできていた場合には、0.~程度のスコアとしている
- 他の手法では、タスクが実行できなかったため、提案手法でablationし比較している
- fine-tuning
- pre-training + fine-tuning
- zero-shot
- pre-trainingのみ
- scratch
- pre-trainingなし、fine-tuningのデータのみ
- fine-tuning
- 結果
- fine-tuninedなπ0は、全てのタスクにおいて50%以上の成功率を達成
- pre-trainingは困難なタスクに対して、効果的である
Discussion,limitations and future work
- pre-trainng用のデータセットの構成をどのようにすべきかについては、まだ検証が足りない
- また、あるタスクを実行する際に、どのくらいのデータの種類、データ量で学習すると良い性能になるのかについても不明瞭である
- 多様なタスク、ロボットのデータセットを組み合わせることによって、どれくらいの効果があるのか予測することはできないため、追加検証が必要である
Appendix
Inference
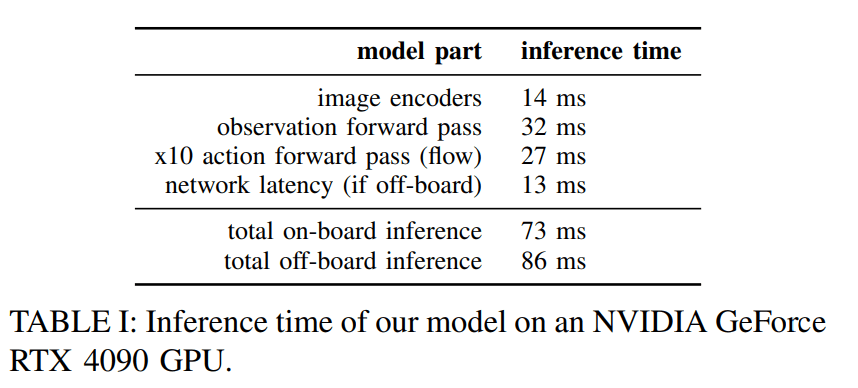
- 3つのカメラ画像を使用した際の推論時間について記載されている
- GPUはRTX4090を使用し、Mobile robotの場合には、推論はオンボードではなく、外部PCで実行している
- 外部PCとはWifiで接続
- H個のステップをchunkしているため、推論前にH個のActionを実行することもでき、temporal ensemblingのように実行することも可能だが、tmporal ensemblingは性能が良くないことが実験から判明した
- そのため、action chunkをopen loopで実行していた
- FrankaとUR5eの場合には、0.8秒ごとに推論し、20Hzで制御司令(16個のActionを実行)を出していた
- 他のロボットの場合には、0.5秒ごとに推論し、50Hzで制御司令(25個のActionを生成)を出していた
Discussion