🤖
Open-TeleVision: Teleoperation with Immersive Active Visual Feedback
Overview
- 没入型の遠隔操作装置の提案
- VRデバイスにロボットのステレオカメラ画像を投影し、より直感的な操作ができるようにした
- また収集したデータを用いてACTを学習させる際に、1枚の広い画角の画像を使用するより、ステレオ画像を使用した方が成功率が向上した
-
ハードウェアとソフトウェアがOSSとして公開されている
- 公開されているハードウェアは、ロボット(H1とGR-1)を除いた部品
- ライセンスはCC BY-NC 4.0で、営利使用は不可
- Accepted in CoRL2024
Introduction・Related work
- 様々な遠隔操作システムが提案されている
-
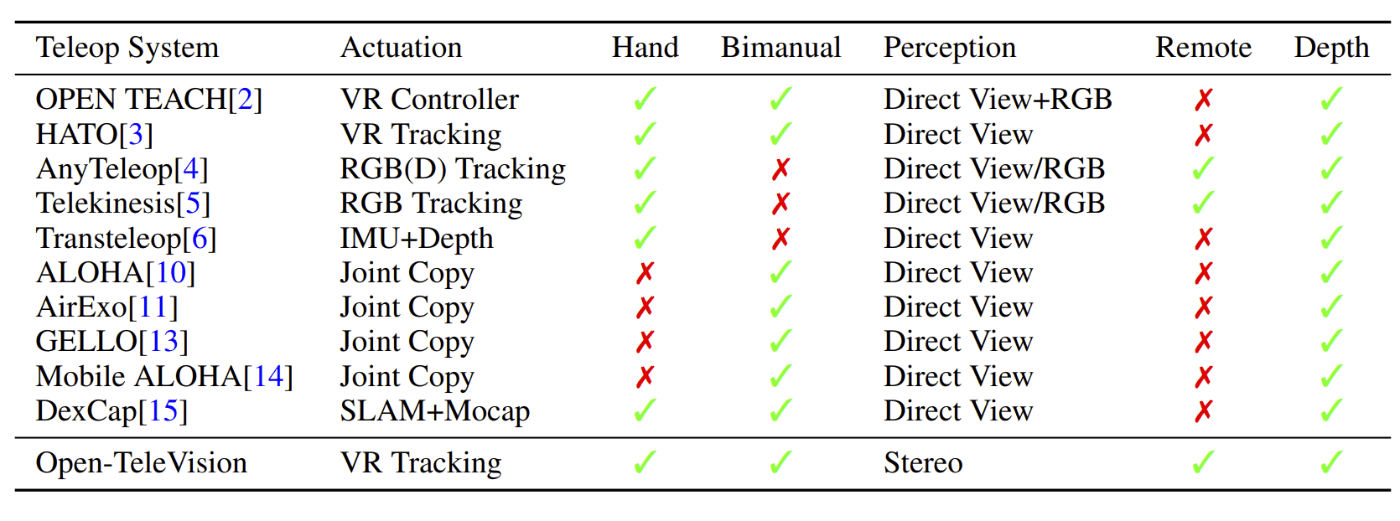
提案するシステムと先行事例の比較
-
VRデバイスを使用した例
-
OPEN TEACH: A Versatile Teleoperation System for Robotic Manipulation
- submitted arXiv in 2024
-
Learning Visuotactile Skills with Two Multifingered Hands
- submitted arXiv in 2024
- 1倍速で連続的に動いている

-
Bunny-VisionPro Real-Time Bimanual Dexterous Teleoperation for Imitation Learning
- Univ of Hong Kong, Univ of calfornia, sandiego
- Submitted in arXiv 2024
-
Deep Imitation Learning for Humanoid Loco-manipulation through Human Teleoperation
- Humanoids 2023
- Unive of Texas at Austin
-
Holo-Dex: Teaching Dexterity with Immersive Mixed Reality
- submitted in arXiv 2022
- New York Univ, Meta
-
OPEN TEACH: A Versatile Teleoperation System for Robotic Manipulation
-
RGBカメラを使用し、操作者の手の動きをトラッキングする例
-
AnyTeleop: A General Vision-Based Dexterous Robot Arm-Hand Teleoperation System
- NVLab, RS2023
- Realsenseで自分の手を撮影し、指の関節角度や手の位置を観測し、マッピングする
-
Robotic Telekinesis: Learning a Robotic Hand Imitator by Watching Humans on Youtube
- Carnegie Mellon Univ.
- RSS2022
-
A Mobile Robot Hand-Arm Teleoperation System by Vision and IMU
- IROS2020
-
From One Hand to Multiple Hands: Imitation Learning for Dexterous Manipulation from Single-Camera Teleoperation
- UC San Diego
- submitted in arXiv 2022
-
CyberDemo: Augmenting Simulated Human Demonstration for Real-World Dexterous Manipulation
- UC San Diego, USC
- CVPR 2024
-
AnyTeleop: A General Vision-Based Dexterous Robot Arm-Hand Teleoperation System
-
ウェアラブルグローブを使用した例
-
A Systematic Review of Commercial Smart Gloves: Current Status and Applications
- Sensors2021
-
High-Fidelity Grasping in Virtual Reality using a Glove-based System
- ICRA2021
- A Glove-based System for Studying Hand-Object Manipulation via Joint Pose and Force Sensing
- ICRA2017
-
A Systematic Review of Commercial Smart Gloves: Current Status and Applications
-
特製のハードウェアを使用した例
-
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
- Stanford Univ, UC Berkeley, Meta, RSS2023
- ALOHAの論文
- 東大松尾研のDL輪読会で取り上げられている
-
AirExo: Low-Cost Exoskeletons for Learning Whole-Arm Manipulation in the Wild
- ICRA2024
- 外骨格方式の遠隔操作装置を提案
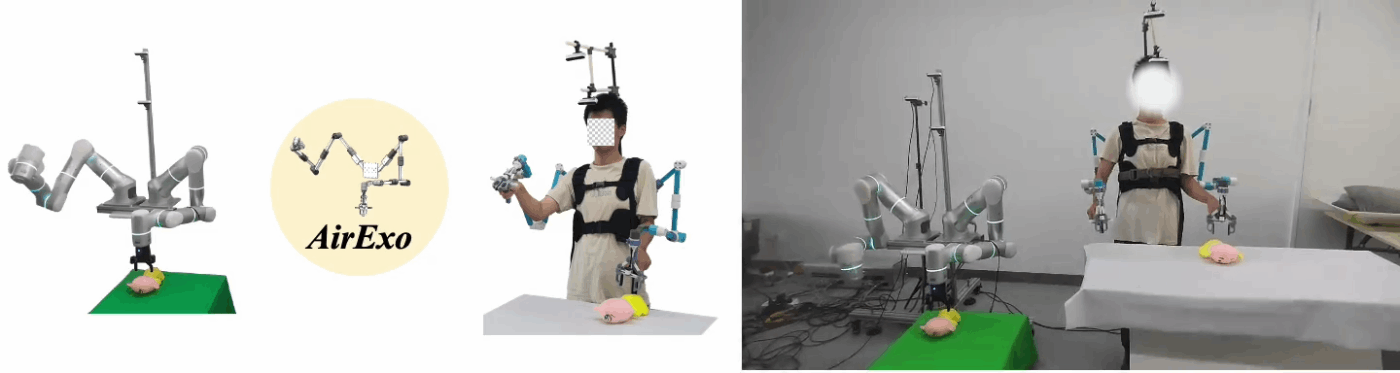
-
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
-
提案するシステムと先行事例の比較
- 遠隔操作システムは、大きく分けると動きと認識の2つの要素で構成されている
- 動きの部分において、人形を操るような(Puppeteer)操作をする場合
- メリット:高い精度でロボット側を操作することができる
- デメリット:ロボットと操作者が同じ場所にいる必要があり、距離が離れた遠隔操作は困難
- 例
-
Yell At Your Robot 🗣️Improving On-the-Fly from Language Corrections
- submitted in arXiv 2024
- Stanford Univ, Univ of California Berkeley
- ALOHAを言語指示から動かすことを提案
- Sergey LevineやChelsea Finnが共著で入っている
-
GELLO: A General, Low-Cost, and Intuitive Teleoperation Framework for Robot Manipulators
- submitted in arXiv 2023
- Univ of California Berkeley
- Pieter Abbeelが共著に入っている
- ALOHAと似た構成
- ALOHAはリーダー側とフォロワー側が同じロボットであったが、こちらはリーダー側は自作でリーダー側にはUR5, Panda, xArm7を用いている
- マッピングしやすくするために、リーダー側のリンク比をフォロワー側に合わせている

-
Yell At Your Robot 🗣️Improving On-the-Fly from Language Corrections
- 認識については、ロボットの作業空間を作業者自身の目で3人称視点から観察する方法が最も操作しやすい
- デメリット:操作する際にロボット自身がオクルージョンになり、方策を学習するための十分な情報が画像中に含まれているかどうかを確認することができない
- VRヘッドセットでパススルーを使用する場合も同様である
- 例(1人称視点)
-
Mobile ALOHA Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
- submitted in arXiv 2024
- Stanford Univ.
- 移動台車の上にALOHAのシステムを搭載することを提案
-
DexCap: Scalable and Portable Mocap Data
Collection System for Dexterous Manipulation- submitted in arXiv 2024
- 人間の動きからロボットのデータセットを作成するため、遠隔操作するより3倍速くデータを収集することができる

-
Universal Manipulation Interface In-The-Wild Robot Teaching Without In-The-Wild Robots
- submitted in arXiv 2024
- Stanford Univ, COLUBIA Enjineering, TRI
- ロボットのカメラがin-hand形式で取り付けられていることより、手首より先があれば学習データを収集することができるため、そのようなデバイスを用意し、データを収集している

-
Mobile ALOHA Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
- デメリット:操作する際にロボット自身がオクルージョンになり、方策を学習するための十分な情報が画像中に含まれているかどうかを確認することができない
- 動きの部分において、人形を操るような(Puppeteer)操作をする場合
- 提案するシステムでは、VRデバイスを用いて、複数のロボット(Unitree H1, Fourier GR1)を操作した
- 操作者の手の位置をVRデバイス(Apple Vision Pro)でトラッキングし、IKからロボットにマッピングしている
- 指の動きも上記と同様にマッピングする
- ロボットのヘッドの動きは、VRデバイスの姿勢と合うようにマッピングする
- 一人称視点におけるactive sensing(頭を動かせること)には、遠隔操作と方策学習用のデータ収集の2つの面においてメリットが存在する
- 遠隔操作の面では、頭が動くことにより直感的に作業範囲を観測することができる
- 方策学習の面では、頭を動かすことも含めて学習することができる
- また、VRデバイスにおける画像表示ではステレオ画像を映し出しており、これにより操作者の空間理解がより高まる
- また学習でもステレオ画像を用いて、学習すると方策のパフォーマンスが向上する
TeleVision System
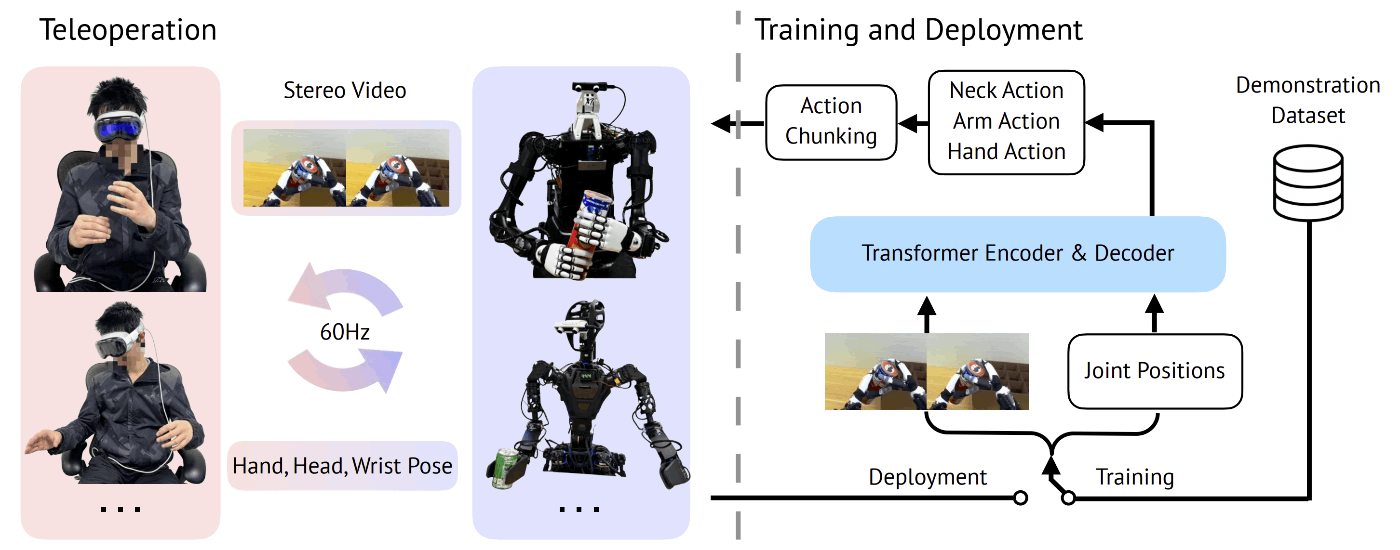
- web serverにはVuerを使用している
- VRデバイスから、手と頭、手首の姿勢を取得しServerに送信している
- ロボットからは、480x640のステレオ画像をServerに送信している
- 全体的な制御周期は60Hz
- IKはPinocchioで解いている
Experiments
-
次の2つの観点に注目し、実験を行った
-
模倣学習のパフォーマンスに影響するキーポイントはどのような要素なのか?
- → 提案手法の中ではステレオ画像を入力画像とすることが重要
-
効率良くデータ収集するためにはどうすればよいか?
- → あまり言及されていない?
- 効率よく計算資源を使用するためには、頭を動かし適切な視野角を設定することが重要であることは言及されている
-
模倣学習のパフォーマンスに影響するキーポイントはどのような要素なのか?
-
実験では模倣学習のアルゴリズムとして2つの変更を入れたACTを使用した
- ACT:Action Chunking with Transformers
- ALOHAで提案されているアルゴリズム
- 1つ目の変更は、バックボーンはResNetではなく、DinoV2を使用している
- 2つ目の変更は、transformer encoderの入力画像に4枚のRGB画像ではなく、2枚のステレオ画像を使用している
- DinoV2では各画像に対して、16x22のTokenを出力する
- このTokenはロボットの現在の関節角度に投影される
- 使用するロボット(H1, GR-1)によって異なる
- Action Spaceとして、絶対関節値を使用している
- このTokenはロボットの現在の関節角度に投影される
- ACT:Action Chunking with Transformers
-
実験では4つのタスクを実行した
- Can Sorting
- Can Indertion
- Folding
- Unloading
-
それぞれのタスクでは、タスクを実行するために視野範囲を移動させる必要がある設定にしている
- 頭を動かさないと、適切な視野範囲とならないようにしている
-
また、オブジェクトの配置位置もランダムで置いている
-
Can Sorting
- 10個の缶(5個のSprite、5個のコーラ)を整理することを1エピソードとした
-
Can Insertion
- 缶を拾って、缶の型が合う箇所に挿入していくタスクで、6個の缶を挿入することを1エピソードとした
-
Folding
- タオルの片方の2つの頂点をそれぞれつまみ、もう片方の2つの頂点に合わせることを1エピソードとした
-
Unloading
- 右手で筒を取り出し左手に持ち替え、特定の場所に挿入するタスクで、4つの筒を4つのスロットに挿入することをを1エピソードとした

Imitation Learning Results
- アブレーションでは、使用したアルゴリズムから変更した部分を無くし評価した
- バックボーンをResNet18にした場合、入力画像でステレオ画像を用いる部分に左側の画像だけ使用する場合の2パターン
- 全てのモデルは5e-5の学習率でAdamWで最適化し、バッチサイズは45、イテレーションは25Kとし、1枚のRTX4090で学習した
- Can Sortingのみ、H1とGR-1の両方で実行し、他の3つのタスクはH1だけで実行した
- オリジナルのACTの実装では、空間情報を補うために4つの画像を用いていたが、今回の実験では2枚のステレオ画像をを使用しているため、ResNetのバックボーンだと空間情報の取得がより困難になる可能性がある

-
Can Sorting
- Appedinxに10個のデータから学習したと記載されている
- H1の結果
- ステレオ画像ではない入力画像を使用した場合、暗黙的なDepth情報が得られないため、缶のPickupに失敗しやすい
- またソーティングも、Pickupが失敗してしまうと、第3者が介入する必要があり、推論画像の精度が低下する
- GR-1の結果
- Pickingは良いパフォーマンスだが、Placingの結果が良くなかった
- この結果はハンドとグリッパーの形状の違いにあると考えられる
- ハンドとグリッパーで缶を掴んだ際のオクルージョンが変わるため、失敗しやすくなる
- Appedixにおいて追加実験について述べられており、ラベル付きの缶を使用すると成功率が大幅に改善したという記載がある
- ハンドとグリッパーで缶を掴んだ際のオクルージョンが変わるため、失敗しやすくなる
- またACTのChunk sizeによる影響も考えられる
- Chunk sizeは60にしており、推論は60Hzで実行していたが、この長さだとPickupした際の缶の色を忘れてしまっている可能性がある
-
Can Insertion
- Appedinxに20個のデータから学習したと記載されている
- ステレオ画像無しだと、適切な缶の掴む位置を掴むことに失敗しやすかった
-
Folding
- Appedinxに20個のデータから学習したと記載されている
- ステレオ画像無しだと、手先を強くテーブルに押し付けてしまいタオルを上手く動かすことができなかった
-
Unloading
- Appedinxに20個のデータから学習したと記載されている
- ステレオ画像無しだと、筒とハンドの相対姿勢の姿勢を正確に推定することができないため、筒の取り出しに失敗しやすい
Generalization
- 汎化性能については、ある条件をランダムにすることにより評価した
- H1を用いたCan Sortingのタスクにおいて、間隔を30mmとした4x4のグリッドの各点に缶を置いた際のPickingの成功率を確認した
- 結果として幅広い範囲を網羅することができると記載されているが、成功率が0の箇所も存在する

Why Use Active Sensing?

- 視野角が広いカメラと、提案手法である頭を動かすことで広範囲な視野範囲を獲得し、注目領域をクロップする方法を比較した
- 1つの視野角が広いカメラの場合は、PoI(Point-of-intrest)が見切れてしまう場合がある
- この場合には、複数のカメラを使用するかもしくは、タスクごとにカメラの取り付け位置を調整する必要がある
- また、視野角が広いことにより関係が無い情報も撮影してしまうため、学習や推論時の計算コストが上がってしまう問題もある
- 提案する手法と比較すると、視野角が広いカメラの場合、2倍の学習時間および推論時間が必要になる
- 画像サイズを4倍にしているから計算時間が2倍になっている?とすると、視野範囲の問題ではない可能性がある

- 提案する手法と比較すると、視野角が広いカメラの場合、2倍の学習時間および推論時間が必要になる
- 位置が固定されたカメラの場合、操作者の焦点が合いやすい画角中心にPoIが無い場合もあるため、操作が直感的ではなくなる
Teleoperated Perfomance
- 3つの遠隔操作タスクを追加で実行した
-
Wood-board Drilling
- 1Kgのドリルを持って、木の板に穴を開ける
-
Earplugs Packing
- 耳栓を拾ってスロットに入れる
-
Pipette
- ピペットで液体を抽出し、試験管に入れる
-
Wood-board Drilling
- H1のモータはバックラッシがあり、また剛性や正確性が少ないことによらず、上記のタスクを実行することができた
- それぞれのタスクの成功率や実行時間は記載されていない

User Study
- 4人の操作者に試してもらい、VRデバイスでステレオ画像を見ながら操作する方法を評価した
- 操作者の対象は20~25歳の学部生
- 全てのタスクにおいて、だいたい5分くらいの習熟時間を与えて観測した
- 1つのカメラからの画像よりステレオ画像の方が、タスクの実行時間と成功率において良い結果を示した
- また、操作者からもステレオの方が使いやすいという定性的な意見もあった

- また、操作者からもステレオの方が使いやすいという定性的な意見もあった
Appendix
Discussion on Comparing with Prior Teleoperation Systems
-
Actuation
- 様々なアプローチが存在するが、モーションキャプチャーのグローブを使用する方法が最も直感的であると考えるが、商用のグローブはコストが高い上に、手首の姿勢推定ができない
- ALOHAは成功していが、エンドエフェクタはグリッパーのままであり、Joint-copyingシステムはハンドの操作まで拡張できていない
- VR機器の発展により、VR機器に搭載されているセンサーから得られた情報から実行されてるハンドトラッキング等の機能の精度も向上しているため、より遠隔操作に使用しやすくなっている
-
Perception
- 認識は重要な部分であるがあまり研究されていない
- 多くのシステムでは、操作者自身の目でロボットの作業空間やロボットを認識している
- 人間は先天的にステレオ視しているため、Depth情報が組み込まれている
- ただし直接見るような構成にしてしまうと、距離が離れた遠隔操作は実施できない
- そのため提案しているようなステレオ構成の方が距離が離れた遠隔操作に適している
- First to Provideと記載しているが、次のようなシステムとの違いが気になる
- 映像転送の距離については紹介されていたが、遅延については言及されていなかった
Experimental Details and Hyperparameters
Hyperparameters
- タスクにより、ACTのChunk sizeを変更している
- Can Insertionを除いたタスクでは全て60に設定しているが、Can Insertionでは1100に設定している
Discussion