Sudachi同義語辞書をElasticsearchで使う(暫定方法)
TL;DR
- Sudachi同義語辞書を「Solr Synonyms形式」に変換して使う
- あくまで暫定的な使い方: 本来は形態素解析結果を元に厳密に展開されるべき
- ちゃんとしたフィルタープラグインは、徳島のSudachi公式がもうすぐ公開してくれるはず
Sudachi同義語辞書とは
同義語が単に羅列されているわけではなく、詳細化した同義関係が付与されています。
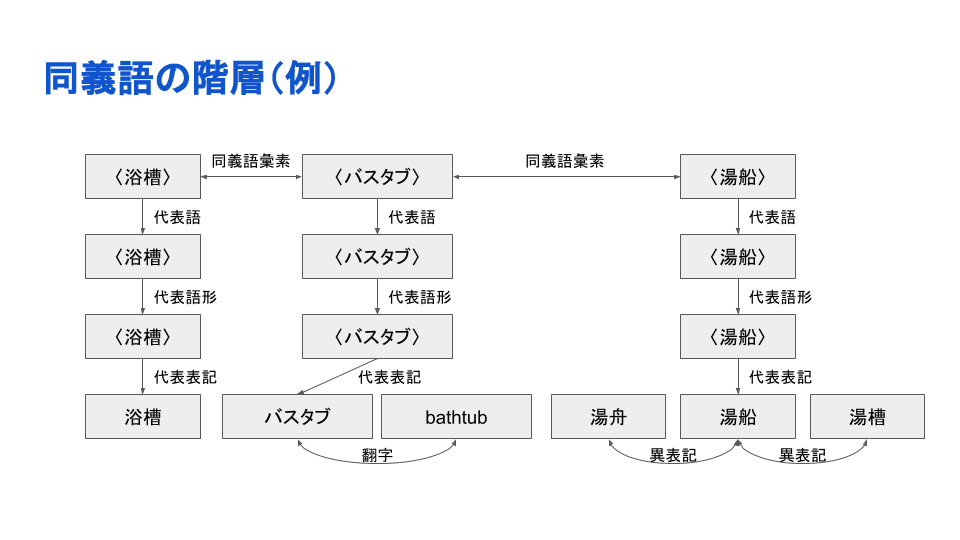
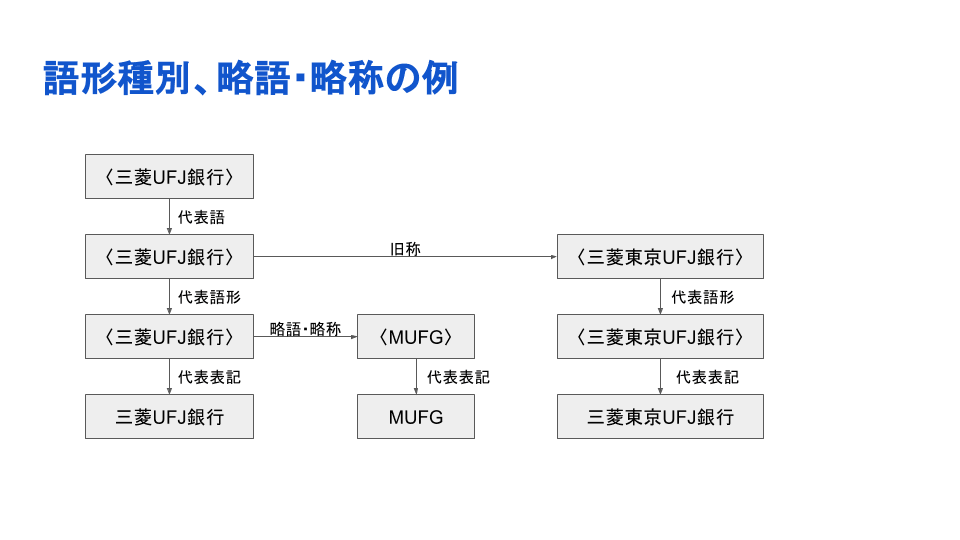
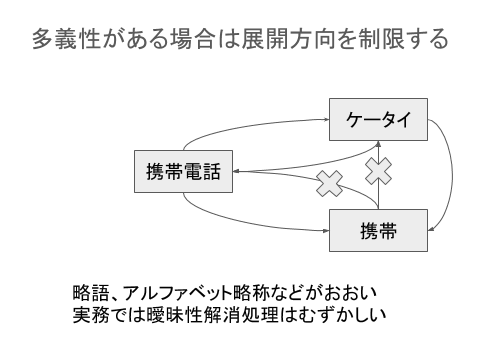
そして、この言語資源は定期的に専門家によりメンテナンス、更新されています。例えば、以下のような語も2020年7月のアップデートなどで追加されています;
...
023538,1,0,1,0,0,0,(医療),新型コロナウイルス感染症,,
023538,1,0,1,2,0,0,(医療),COVID-19,,
023539,1,0,1,0,0,0,(医療),コロナウイルス,,
023539,1,0,1,0,0,2,(医療),コロナウィルス,,
023539,1,0,1,0,0,1,(医療),Coronavirus,,
023539,1,1,1,0,2,0,(医療),コロナ,,
023540,1,0,1,0,0,0,(医療),SARS-CoV-2,,
023540,1,0,1,1,0,0,(医療),Severe Acute Respiratory Syndrome Coronavirus 2,,
023540,1,1,1,2,0,0,(医療),新型コロナウイルス,,
023540,1,1,1,2,2,0,(医療),新型コロナ,,
023541,1,0,1,0,0,0,(医療),重症急性呼吸器症候群,,
023541,1,0,1,0,1,0,(医療),SARS,,
023541,1,0,1,0,1,2,(医療),サーズ,,
023541,1,0,1,1,0,0,(医療),Severe Acute Respiratory Syndrome,,
023542,1,0,1,0,0,0,(医療),中東呼吸器症候群,,
023542,1,0,1,0,1,0,(医療),MERS,,
023542,1,0,1,0,1,2,(医療),マーズ,,
023542,1,0,1,1,0,0,(医療),Middle East Respiratory Syndrome,,
023543,1,0,1,0,0,0,(),ソーシャルディスタンス,,
023543,1,0,1,0,0,1,(),social distance,,
023543,1,0,2,0,0,0,(),社会的距離,,
023545,1,0,1,0,0,0,(医療),空気感染,,
023545,1,0,2,0,0,0,(医療),空気伝染,,
023545,1,0,3,0,0,0,(医療),エアロゾル感染,,
023546,1,0,1,0,0,0,(医療),二次感染,,
023546,1,0,2,0,0,0,(医療),続発感染,,
023547,1,0,1,0,0,0,(医療),無症状感染,,
023547,1,0,2,0,0,0,(医療),不顕性感染,,
023548,1,0,1,0,0,0,(),不活化,,
023548,1,0,2,0,0,0,(),不活性化,,
023549,1,0,1,0,0,0,(医療/人),重症者,,
023549,1,0,2,0,0,0,(医療/人),重症患者,,
023550,1,0,1,0,0,0,(医療),集中治療室,,
023550,1,0,1,0,1,0,(医療),ICU,,
023550,1,0,1,1,0,0,(医療),intensive care unit,,
...
「Solr Synonyms形式」へ変換する
Sudachiによる形態素解析結果を元に厳密な形で同義語辞書を使うことは(現状では)できないのですが、元の言語資源をSolr Synonyms形式に変換することで、Elasticsearchで活用することができます。
Elasticsearchの同義語フィルターやSolr Synonyms形式については、公式ドキュメントをご覧ください; Synonym token filter | Elasticsearch Reference | Elastic
変換スクリプト
ssyn2es.py (from Pull Request #65 · WorksApplications/elasticsearch-sudachi)
#!/usr/bin/env python
import argparse
import fileinput
def main():
parser = argparse.ArgumentParser(prog="ssyn2es.py", description="convert Sudachi synonyms to ES")
parser.add_argument('files', metavar='FILE', nargs='*', help='files to read, if empty, stdin is used')
parser.add_argument('-p', '--output-predicate', action='store_true', help='output predicates')
args = parser.parse_args()
synonyms = {}
with fileinput.input(files = args.files) as input:
for line in input:
line = line.strip()
if line == "":
continue
entry = line.split(",")[0:9]
if entry[2] == "2" or (not args.output_predicate and entry[1] == "2"):
continue
group = synonyms.setdefault(entry[0], [[], []])
group[1 if entry[2] == "1" else 0].append(entry[8])
for groupid in sorted(synonyms):
group = synonyms[groupid]
if not group[1]:
if len(group[0]) > 1:
print(",".join(group[0]))
else:
if len(group[0]) > 0 and len(group[1]) > 0:
print(",".join(group[0]) + "=>" + ",".join(group[0] + group[1]))
if __name__ == "__main__":
main()
$ python ssyn2es.py SudachiDict/src/main/text/synonyms.txt > synonym.txt
$ head synonym.txt
曖昧,あいまい,不明確,あやふや,不明瞭,不確か
宛て先,あて先,宛先,送り先,送付先,届け先,発送先,配送先
粗筋,あらすじ,荒筋,概略,大略,概要,大要,要約,要旨,梗概,サマリー,サマリ,summary,レジュメ,レジメ,résumé,シノプシス,synopsis,アウトライン,outline=>粗筋,あらすじ,荒筋,概略,大略,概要,大要,要約,要旨,梗概,サマリー,サマリ,summary,レジュメ,レジメ,résumé,シノプシス,synopsis,アウトライン,outline,resume,概ね,あらまし,アブストラクト,abstract
経緯,いきさつ,事情,経過,事由=>経緯,いきさつ,事情,経過,事由,理由,訳
閉店,店仕舞い=>閉店,店仕舞い,クローズ,close
開店,始業,営業開始=>開店,始業,営業開始,店開き,オープン,open
お喋り,おしゃべり,話,はなし,トーク,talk,会話,カンバセーション,conversation
支払,決済=>支払,決済,支払い,勘定,精算,会計,御愛想,愛想
特別会計,特会
御出掛け,おでかけ,お出かけ,お出掛け,外出
展開抑制の扱い
上記の変換は、Solr Synonyms形式での => という表記を使って、展開方向の抑制も考慮されています。
例えば、以下の同義語エントリがあったとします;
アイスクリーム,ice cream,ice=>アイスクリーム,ice cream,ice,アイス
この時「アイスクリーム」は、 アイスクリーム, ice cream, ice, アイス に展開されます。
他方で 「アイス」は、アイス としか出力されず、同義語展開されません。
変換した同義語辞書を使う
変換したSolr Synonyms形式のファイルは、Elasticsearchのデフォルトのフィルター Synonym token filter や Synonym graph filter で使うことができます。
句読点記号の扱い
€ や & といった記号を取り除く必要があります。取り除かないと "term: € was completely eliminated by analyzer" といったエラーがでます。
取り除くには "discard_punctuation": true と analyzer を設定します。他の方法としては、 "lenient": true と設定し、 synonym filter が例外を無視するというのもあります。
これらの記号は Punctuation として設定されています。詳細は SudachiTokenizer.javaの該当箇所 をご覧ください。
Elasticsearchの設定例
{
"settings": {
"analysis": {
"filter": {
"sudachi_synonym": {
"type": "synonym_graph",
"synonyms_path": "sudachi/synonym.txt"
}
},
"tokenizer": {
"sudachi_tokenizer": {
"type": "sudachi_tokenizer"
}
},
"analyzer": {
"sudachi_synonym_analyzer": {
"type": "custom",
"tokenizer": "sudachi_tokenizer",
"filter": [
"sudachi_synonym"
]
}
}
}
}
}
ここでは、変換した同義語ファイルが $ES_PATH_CONF/sudachi/synonym.txt にあることを想定しています。
また、もし sudachi_split フィルターも利用したい場合は、同義語フィルターの 後 にセットしてください。前にある場合 term: 不明確 analyzed to a token (不) with position increment != 1 (got: 0) というようなエラーが発生します。
解析例
ケース 1.
リクエスト
{
"analyzer": "sudachi_synonym_analyzer",
"text": "アイスクリーム"
}
レスポンス
{
"tokens": [
{
"token": "アイスクリーム",
"start_offset": 0,
"end_offset": 7,
"type": "SYNONYM",
"position": 0
},
{
"token": "ice cream",
"start_offset": 0,
"end_offset": 7,
"type": "SYNONYM",
"position": 0
},
{
"token": "ice",
"start_offset": 0,
"end_offset": 7,
"type": "SYNONYM",
"position": 0
},
{
"token": "アイス",
"start_offset": 0,
"end_offset": 7,
"type": "SYNONYM",
"position": 0
}
]
}
ケース 2.
リクエスト
{
"analyzer": "sudachi_synonym_analyzer",
"text": "アイス"
}
レスポンス
{
"tokens": [
{
"token": "アイス",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
}
]
}
関連文献
- Add documentation about SudachiDict synonym by sorami · Pull Request #65 · WorksApplications/elasticsearch-sudachi (当記事とほぼ同じ内容です)
- Elasticsearchのための新しい形態素解析器 「Sudachi」 - Qiita (Elastic stack (Elasticsearch) Advent Calendar 2017)
- Elasticsearchで今すぐ使えるビジネス向けトークナイザーSudachi (Elasticsearch勉強会 in 京都, 2018年8月2日)
詳細化した同義関係をもつ同義語辞書の作成
- https://www.anlp.jp/proceedings/annual_meeting/2020/pdf_dir/P4-14.pdf
- 高岡一馬, 岡部裕子, 川原典子, 坂本美保, 内田佳孝
- 第26回言語処理学会年次大会, March 18, 2020.
( img from https://twitter.com/sorami/status/1239848113273069569 )

詳細化した語彙関係をもつ同義語辞書を用いた日本語のRelation Embedding学習への取り組み
- 勝田哲弘, 山村崇, 竹林佑斗, 久本空海, 高岡一馬, 内田佳孝, 岡照晃(国語研), 浅原正幸(国語研)
- NLP若手の会 (YANS) 第15回シンポジウム, September 23, 2020.
( img from https://twitter.com/sorami/status/1308581126617796608 )

わからないことや要望があったら
公式Slackに投稿したり、GitHubレポジトリでissueを立てると良いです; Sudachi公式Slack参加リンク
Enjoy Full Text Search!
Discussion