自己紹介
株式会社ソニックムーブのアプリユニットの渡辺と申します。新卒で入社し、今年から2年目に突入します。
swift/kotlin でスマホアプリの開発をしており、プライベートではpythonを用いたAIの勉強をしております。
導入
近年AIが発達したことで至る所にAIが使用されていますが、今回はスマホアプリにもAIを活用したく、
今回はその活用例とその導入方法を紹介します。
サンプルアプリ
pythonを用いて、独自のアプリのヘルプ等のチャットボットを作成してみます。
今回は、iOSのサンプルアプリを先に作成しましたので、以下で動作を確認してみてください。
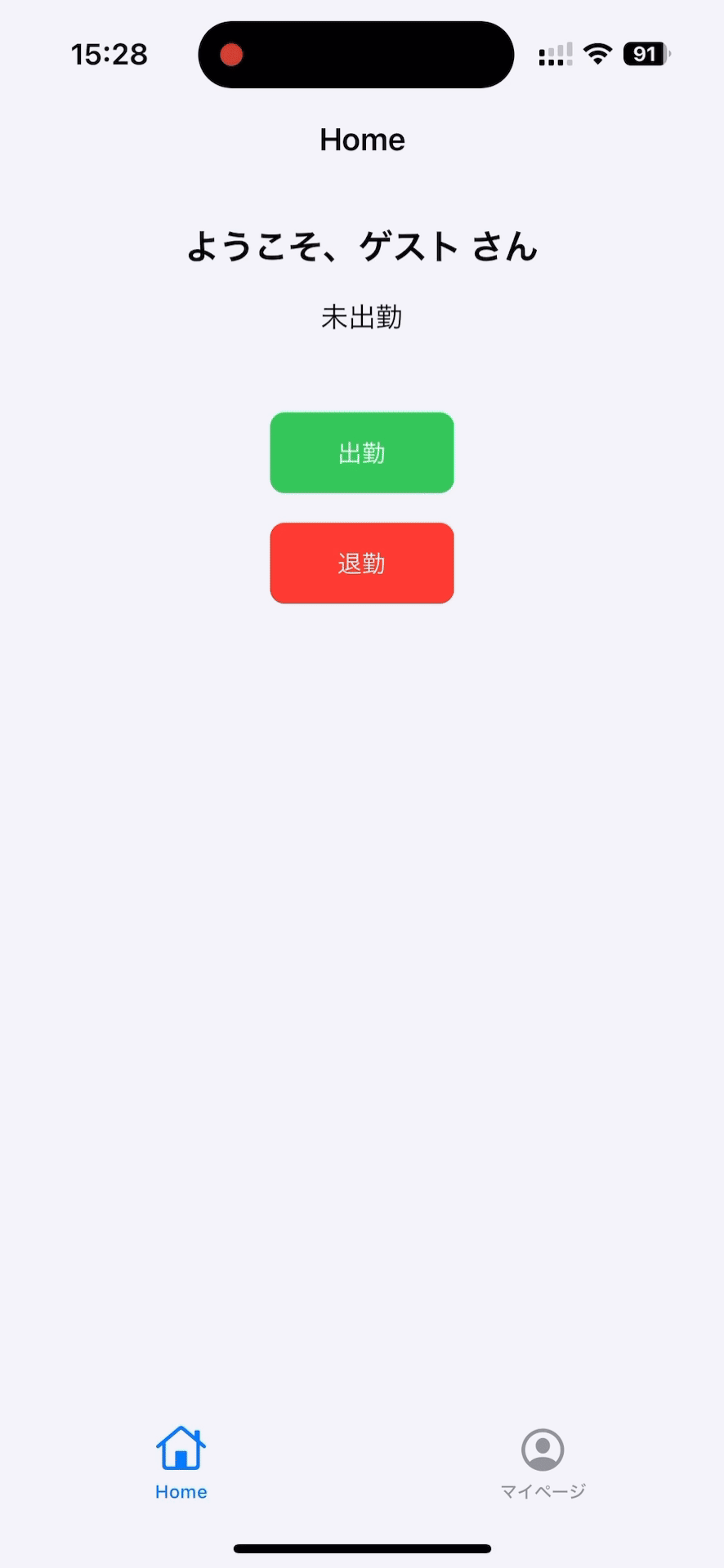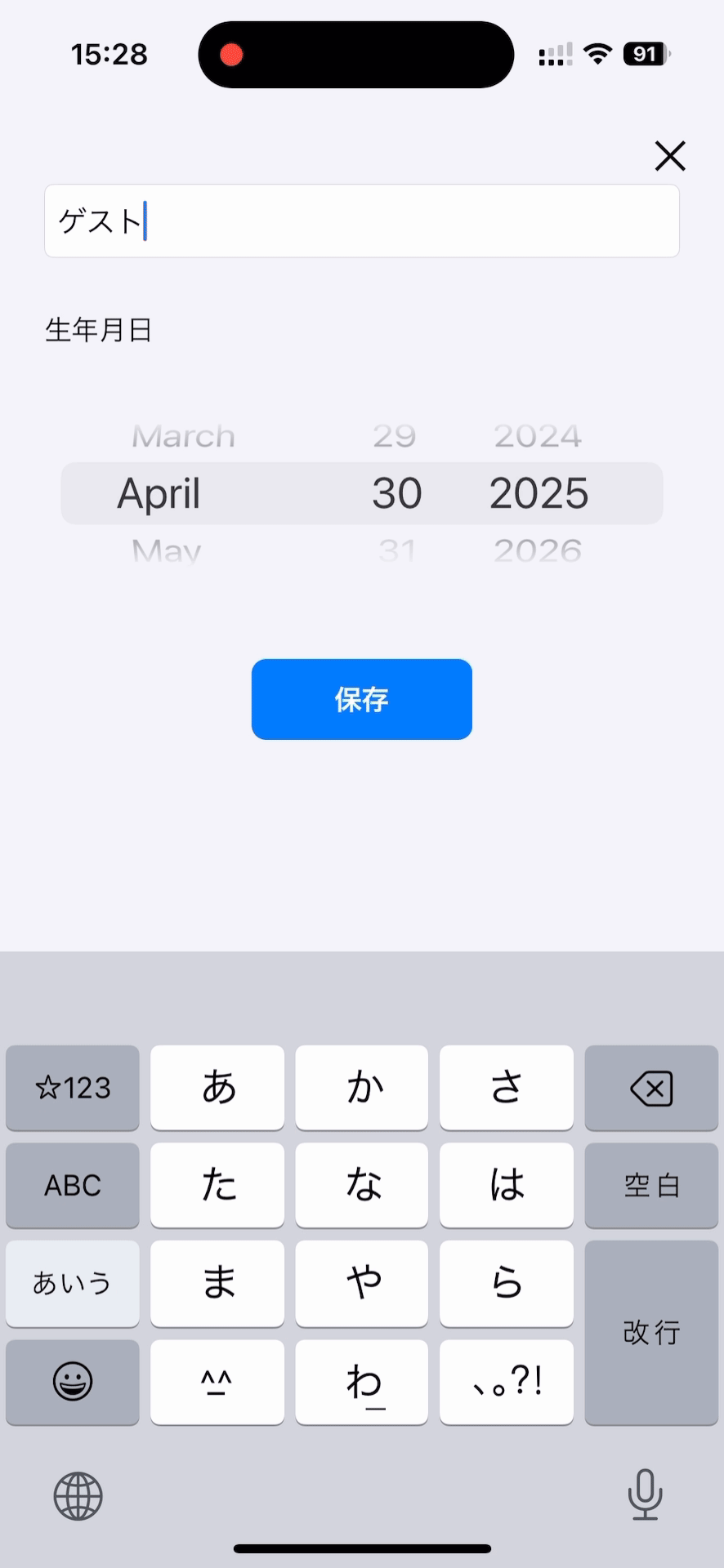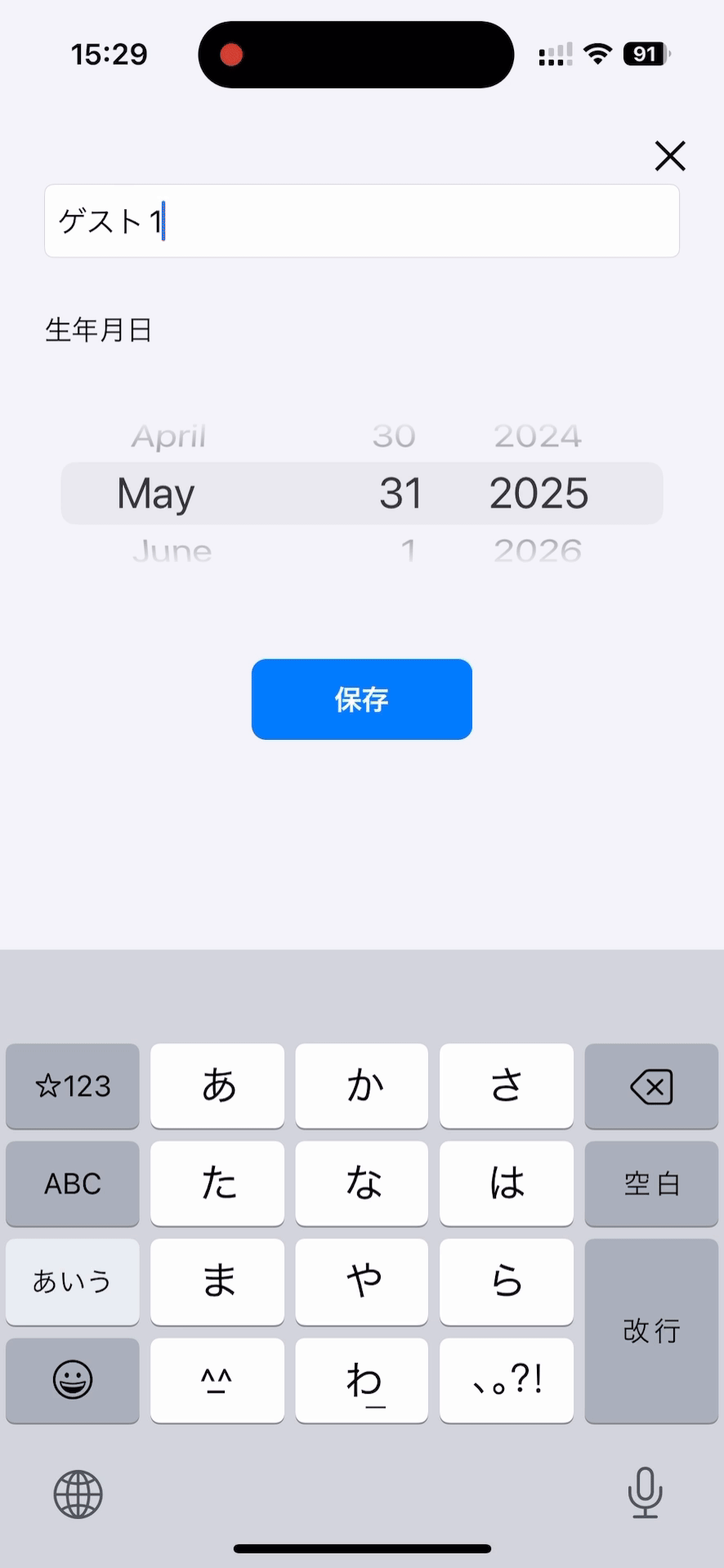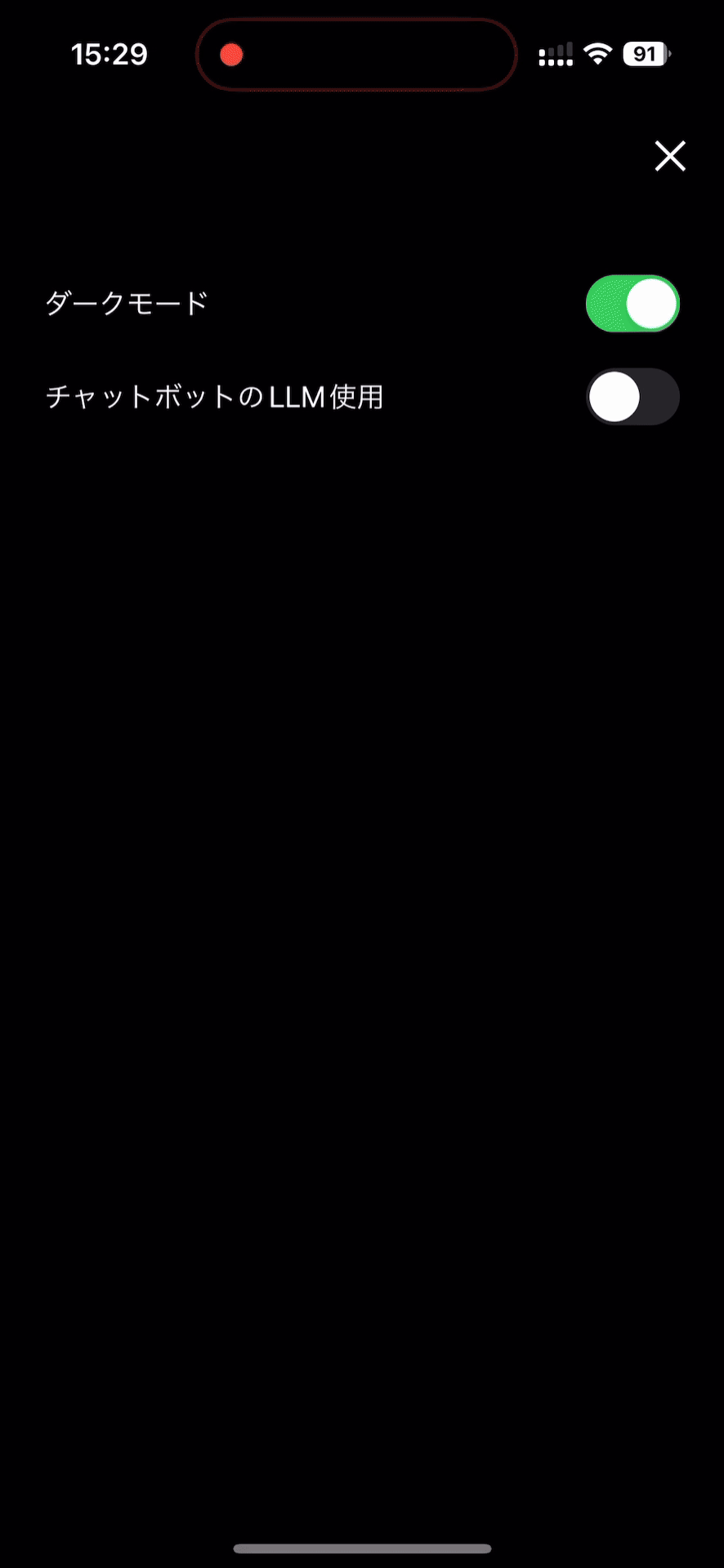
勤怠管理アプリ
機能は以下のものがあります。
- 出勤/退勤ボタン
- プロフィール編集機能
- ダークモード切り替え機能
- ヘルプ機能
サンプルとして作っているため、機能やUIは非常に簡易的です。
AIの活用の目標は、以下のような動作です。

pythonの環境がない方は、私が作成したこちらから簡単にpython環境をセットアップできます。
python環境を準備する
これから紹介するコードは以下からもダウンロードできます。
python側ソースコード
今回は2種類のAIを作成します。1つ目はカテゴリ分類AIのチャットボットです。
ひとまず私のpythonSetupTempleteのrequirements.txtに、以下の通り使用するライブラリを記載します。
torch
transformers
datasets
fugashi
ipadic
unidic-lite
protobuf
flask
ollama
(Macの場合)ターミナルで、プロジェクトのルートディレクトリに移動し、README.mdの通りにセットアップを進めます。
cd /path/to/the/pythonSetupTemplete
git clone https://github.com/pyenv/pyenv.git ~/.pyenv
./init.sh 3.8.10
venv/bin/activate
これでpythonの環境が利用できるようになります。
モデルを作成する
今回は、質問に対して固定の回答を
必要なライブラリをインポートし、以下のように記載します。
import torch
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
Trainer,
TrainingArguments,
)
from datasets import load_dataset
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME, num_labels=6).to(device)
dataset = load_dataset("json", data_files="faq_data.json")
def preprocess(examples):
return tokenizer(examples["question"], truncation=True, padding=True, max_length=128)
tokenized = dataset.map(preprocess, batched=True)
tokenizerとは、文章を分割して学習に使える数値データに変換するためのもので、preprocessはtokenizerの下準備と思ってください。
例)
「今日はいい天気です。」
→["今", "日", "は", "いい", "天", "気", "です", "。"]
→[数値1、数値2、数値3、数値4、数値5、数値6、数値7、数値8]
datasetとは、以下のような学習データです。問題に対して適切な回答を記したデータを用意する必要があります。
[
{
"question": "名前を変更するにはどこを操作すればいいですか?",
"answer": "名前の変更はプロフィール設定から行えます。",
"label": 0
},
{
"question": "名前の変更はどこでできますか?",
"answer": "名前の変更はプロフィール設定から行えます。",
"label": 0
},
{
"question": "登録した生年月日を変更したいです。",
"answer": "生年月日の変更はプロフィール設定から行ってください。",
"label": 1
},
{
"question": "プロフィールの誕生日を直すには?",
"answer": "生年月日の変更はプロフィール設定から行ってください。",
"label": 1
}
]
modelとは、すでにある程度学習済みのAIで、num_labelとはdataSetのlabelの数のことです。
上記detaSetでいうanswerの種類のことです。次に、それらを使用してtrainerという学習の環境を準備します。
args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=3e-5,
per_device_train_batch_size=16,
num_train_epochs=10,
weight_decay=0.01,
logging_dir="./logs",
)
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized["train"],
eval_dataset=tokenized["train"],
tokenizer=tokenizer,
)
この辺りは、どう学習を進めるかの設定のようなものですが、今回詳しい説明は省略します。
そして学習を発火させるコードを記載して実行します。
trainer.train()
model.save_pretrained(SAVE_DIR)
tokenizer.save_pretrained(SAVE_DIR)
SAVE_DIRには任意のpathを指定し、
python src/train.py
のように実行することで学習が開始されます。
モデルを利用する・API化する
以下のように、先ほど学習(ファインチューニングとも言う)させたモデルを準備します。
from flask import Flask, request, jsonify
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import ollama
import re
MODEL_DIR = "./saved_model_pt"
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_DIR).to(device)
model.eval()
tokenizerを用意し、modelも保存したpathからロードして、eval()によって推論モードにします。
def predict(message):
inputs = tokenizer(message, return_tensors="pt", truncation=True, padding="max_length", max_length=128)
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
label = torch.argmax(outputs.logits, dim=1).item()
return label_to_answer.get(label, "該当する回答が見つかりません。")
with torch.no_grad():
outputs = model(**inputs)
label = torch.argmax(outputs.logits, dim=1).item()
return label_to_answer.get(label, "該当する回答が見つかりません。")
上記コードでトークナイザーなどの準備などをし、モデルによる推論を行って回答を数値(dataSetのlabel)で取得します。
これを以下のようにすれば、API化してアプリと連携する準備が整います。
@app.route("/help", methods=["GET"])
def chat():
message = request.args.get("message", "")
if not message:
return jsonify({"response": "メッセージが空です。"}), 400
answer = predict(message)
if answer.startswith("エラー:"):
return jsonify({"response": answer}), 400
return jsonify({"response": answer})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=3000, debug=True)
この場合、プログラムを実行してからブラウザで「http://localhost:3000/help?message=質問内容」というURLにアクセスすると、AIの回答結果が表示されます。
アプリと連携する
これから紹介するコードも以下でダウンロード可能です。
swift(iOS)側ソースコード
長くなるのでバッサリと省略しますが、
let params: [String : Any] = [
"message": text // 質問内容の文字列
]
APIClient.shared.get("http://localhost:3000/help", parameters: params)
.observe(on: MainScheduler.instance)
.subscribe(onSuccess: { [weak self] json in
let reply = Message(json: json)
SVProgressHUD.dismiss()
}, onFailure: { error in
print("エラー: \(error)")
SVProgressHUD.dismiss()
})
.disposed(by: disposeBag)
このようにAPIのクエリに質問文を追加してコールすれば、回答が返ってきます。
詳しくは実際にgithubからソースコードをダウンロードしてご確認ください。
LLM(chatGPTのようなAI)も使用できる
長くなるため説明はしませんが、以下のようにヘルプページにchatGPTのようなLLMと呼ばれる、
より回答の柔軟性が高いモデルも使用可能です。サンプルアプリにも、設定から使用するモデルを切り替えられるようにして追加しました。(ローカルサーバーだとLLMは重たいです。動画も一部カットしています。)
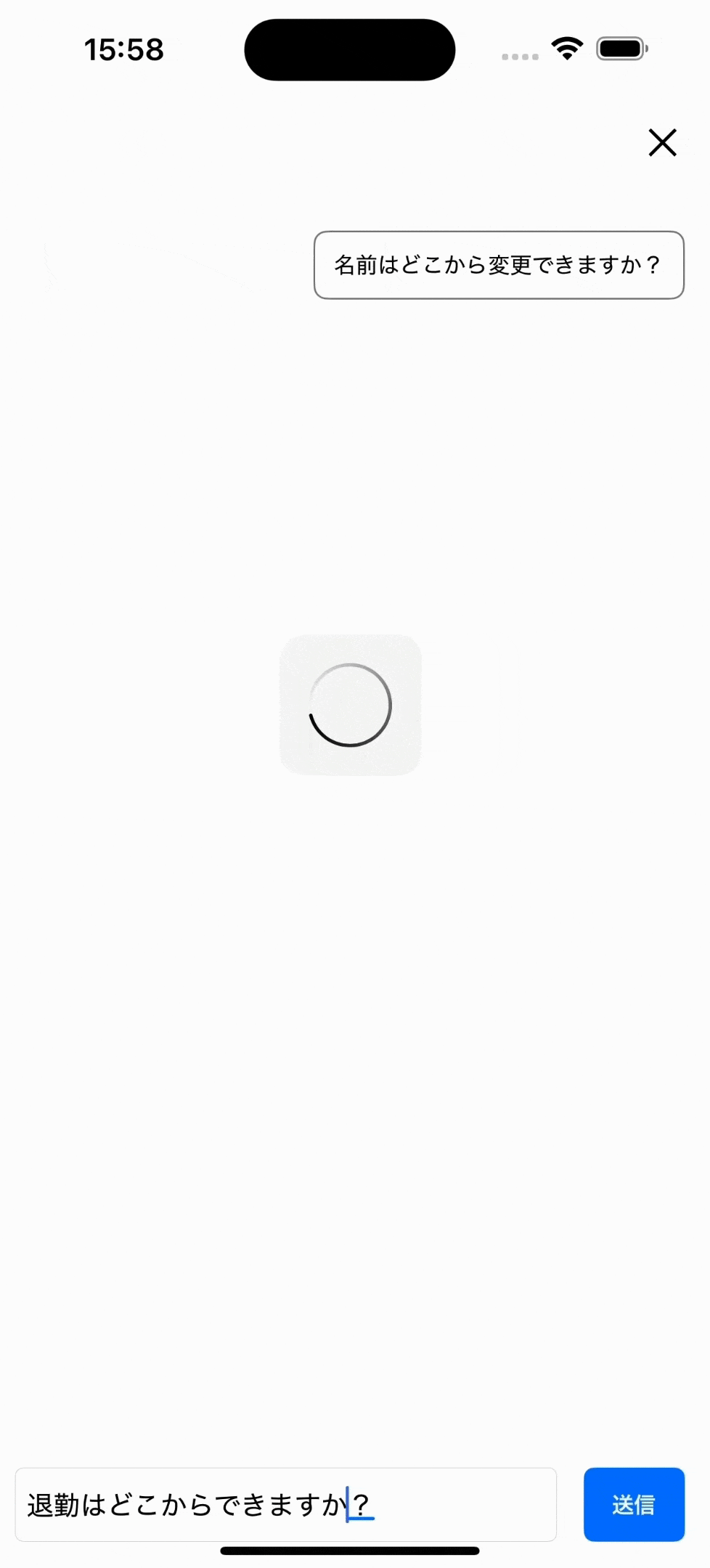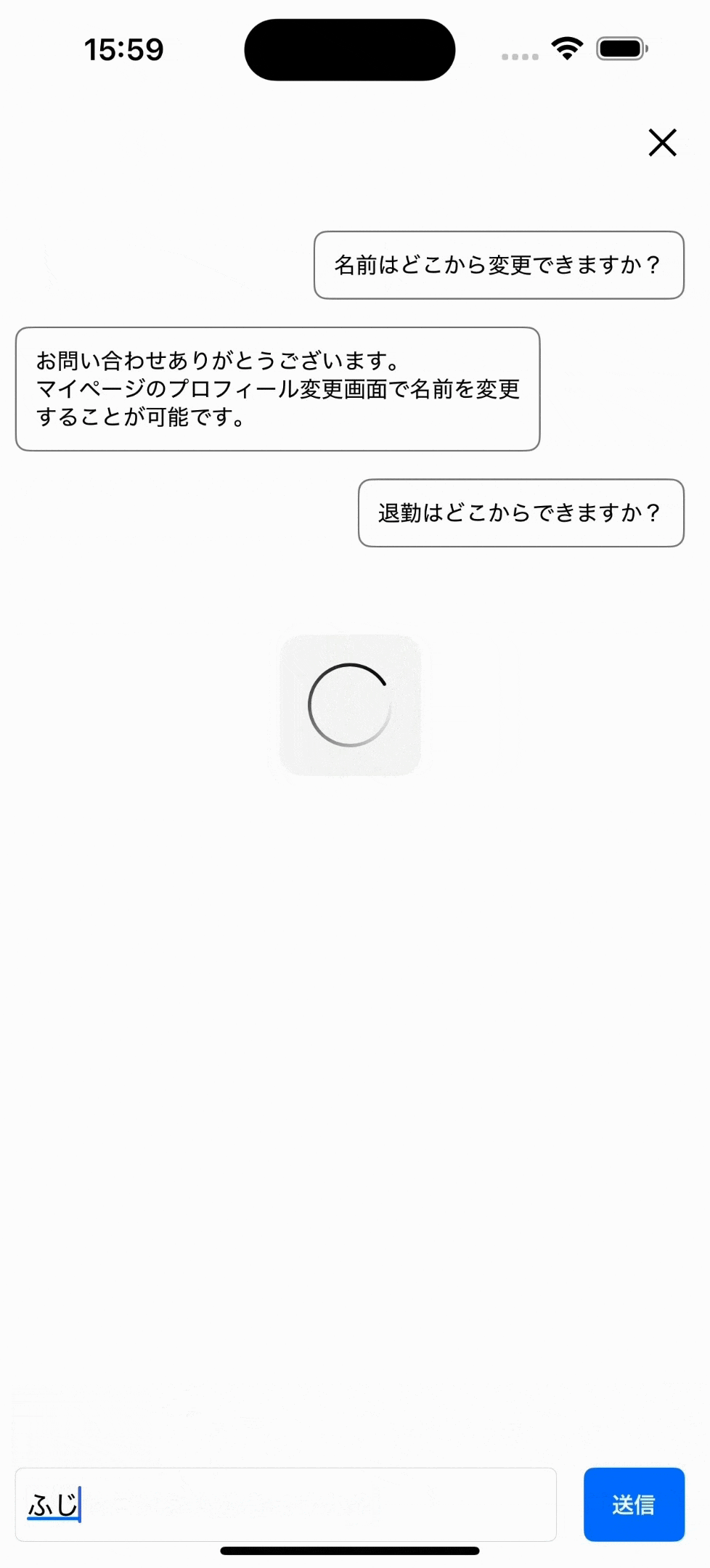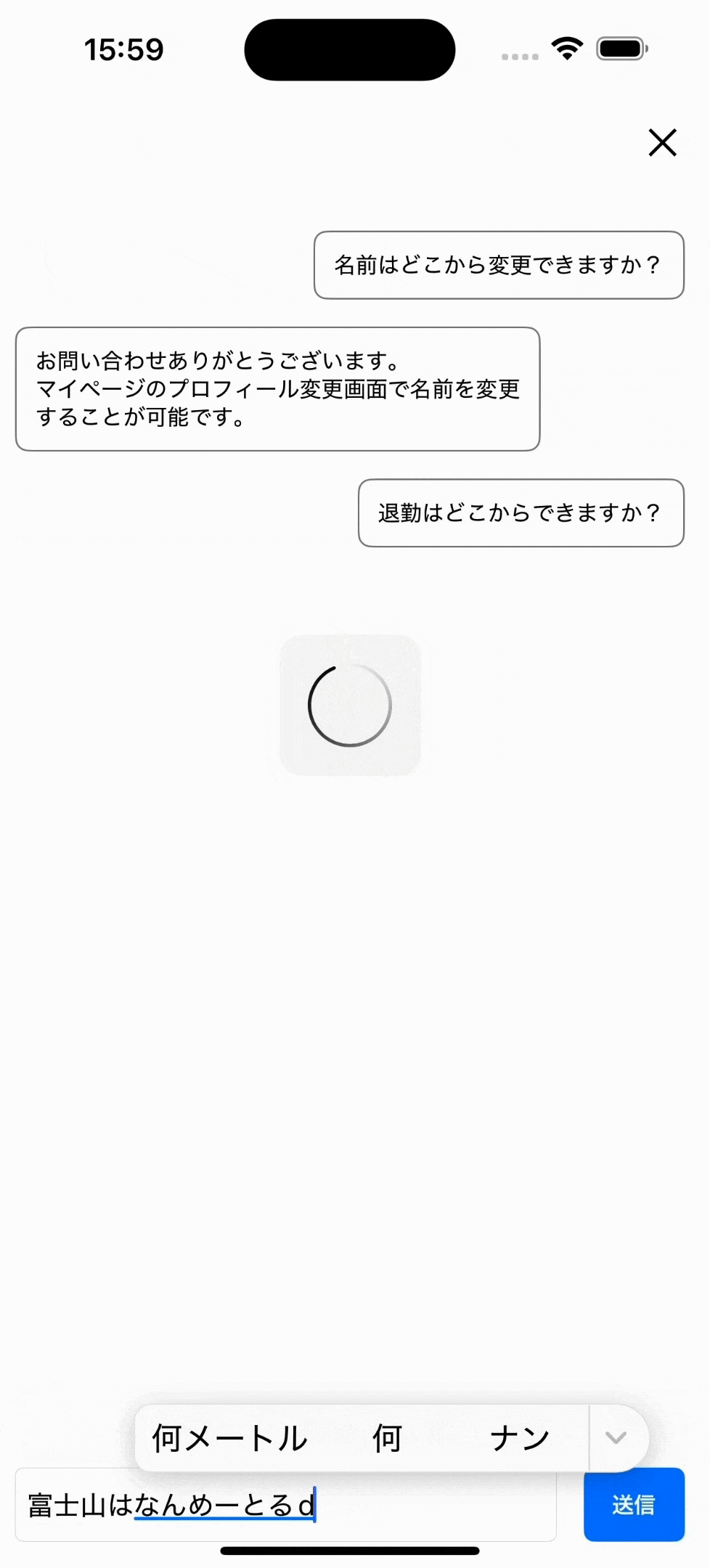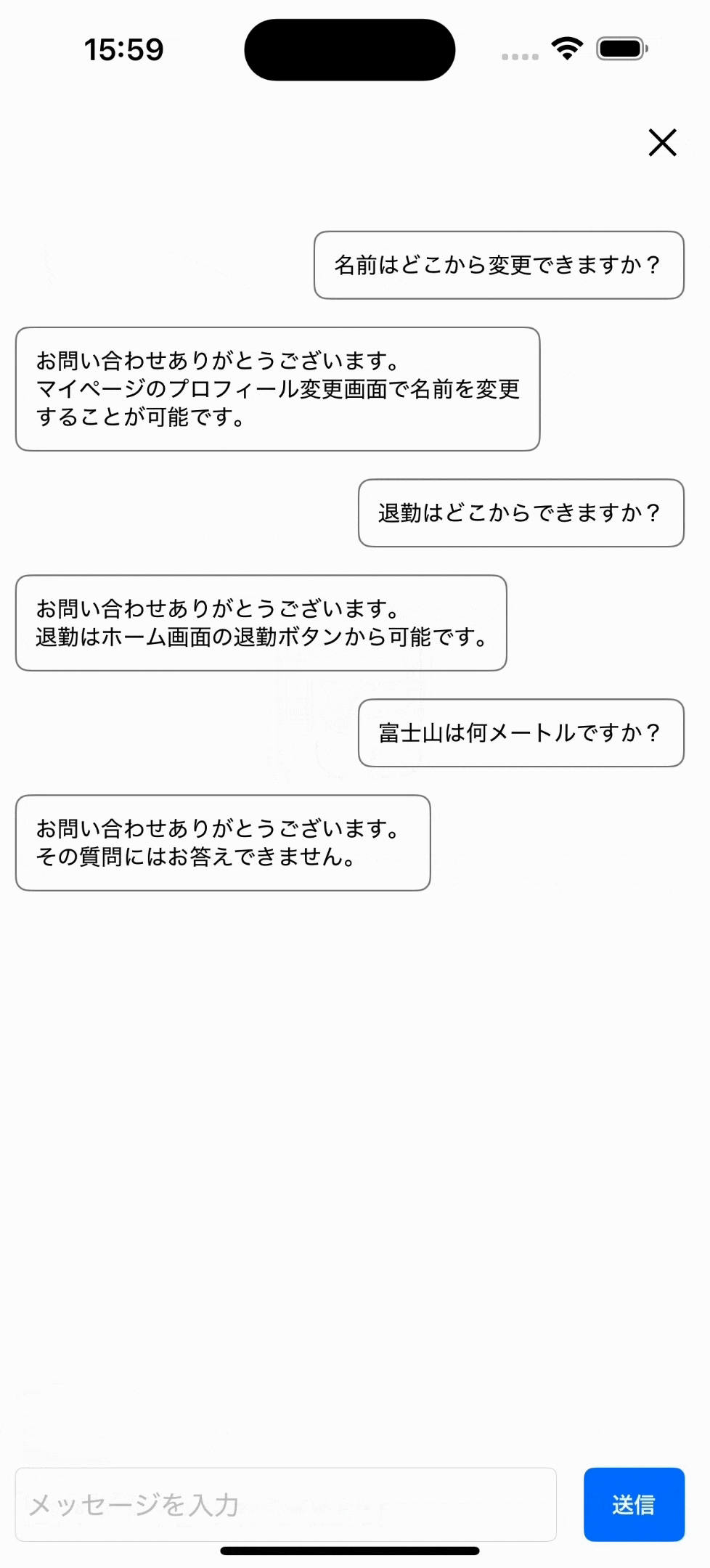
わかりにくいですがLLMでは、回答を固定ではなくAIが内容を考えて出力します。
まとめ
大雑把な説明にはなりましたが、このようにモデルに学習させサーバーでAPIとして立てることで、アプリではヘルプのチャットbotとしてAIを活用することができました。参考になれば幸いです。

Discussion