LangChain Graph Retrieverを使ってみた
LangChain Graph Retrieverを使ってみた
1. はじめに
最近、LangChainの「Graph Retriever」というのを見つけた。
LangChain - Graph RAG
The GraphRetriever from the langchain-graph-retriever package provides a LangChain retriever that combines unstructured similarity search on vectors with structured traversal of metadata properties. This enables graph-based retrieval over an existing vector store.
既存のベクトルストアのグラフベース検索が可能になる?
Neo4jなどのグラフデータベースを使ってナレッジグラフ構築せずとも、データ間の関係性を考慮した検索ができるらしい・・・
なんかMicrosoftが発表してた「LazyGraphRAG」に似てるな・・・
LazyGraphRAG: Setting a new standard for quality and cost
実際に使用している記事をあまり見ないので、へっぽこエンジニアですが試してみることにしました。
ツッコミ所がいっぱいな可能性があると思うので、その場合は優しく指摘してねエロい人達。
2. 実装
プロジェクト構成
まず、プロジェクトの基本構成。
/
├── app/
│ ├── app.py # Gradio WebUI
│ └── graphrag.py # GraphRAG
├── docker/
│ └── app/
│ ├── Dockerfile
│ └── requirements.txt # 依存関係
└── docker-compose.yml
Dockerfileとかdocker-compose.ymlとかは今回主題ではないので、特に説明しません。
エロい人達なら分かってるもんね?
依存関係
どのライブラリを使用するかは必要なので記載しときます。
langchain
langchain-openai
langchain-graph-retriever
graph_rag_example_helpers
gradio
必須なのはlangchainとlangchain-graph-retrieverです。
今回はgpt-4.1-nano(やっすぅ~い)を使用するので、langchain-openaiを入れています。
OpenAI以外のモデルを使用するなら、それに合ったものを入れてくだせぇ。
graph_rag_example_helpersはGraphRAGの検証に使用するテストデータを得るために入れています。
gradioは実際にGraphRAG検索をブラウザから試せるように入れています。
import
graphrag.pyを実装していきます。
まずは、import!
import os
import logging
from typing import Dict, List, Optional, Tuple
from pathlib import Path
from pydantic import BaseModel, Field
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_graph_retriever import GraphRetriever
from graph_retriever.strategies import Eager
from graph_rag_example_helpers.datasets.animals import fetch_documents
# ログ設定
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
ベクトルストアは簡単にInMemoryVectorStoreを使用します。
LLMはOpenAIのものを使用するので、OpenAIEmbeddingsとChatOpenAIを。
あとはLangChainのLCELで使用する諸々をインポートします。
GraphRetrieverで必要なのは、GraphRetrieverとEagerです。
fetch_documentsは検証データ用です。
後は、何かログを書き込むかもしれないので、簡単なロガーを持っておきます。
GraphRAGクラスの作成
GraphRAG関連の処理を実装するGraphRAGクラスを作成します。
class GraphRAG:
"""GraphRAG クラス"""
# この後、ごにゃごにゃ実装していきます
# GraphRAGクラスのインスタンスを作成
graphrag_class = GraphRAG()
最後にクラスのインスタンスを作成しているのは、app.pyからのimportにより、疑似的なシングルトンみたいな形にするためです。とりあえずこれでいいよね?(
コンストラクタ
まずはコンストラクタで諸々初期化するよ。
def __init__(self):
"""コンストラクタ"""
self.embeddings: Optional[OpenAIEmbeddings] = None
self.vector_store: Optional[InMemoryVectorStore] = None
self.graph_retriever: Optional[GraphRetriever] = None
self.graph_chain = None
self.standard_retriever = None
self.standard_chain = None
self.llm: Optional[ChatOpenAI] = None
self.documents: List[Document] = []
# OpenAI APIキーの存在確認
if os.getenv('OPENAI_API_KEY'):
try:
# エンベディングモデルとLLMを初期化
# (これらは自動的に環境変数 OPENAI_API_KEY を参照)
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
self.llm = ChatOpenAI(model="gpt-4.1-nano", temperature=0)
logger.info("OpenAI APIキーを確認し、モデルを初期化しました")
except Exception as e:
logger.warning(f"OpenAIモデル初期化エラー: {e}")
else:
logger.warning("OPENAI_API_KEY環境変数が設定されていません")
エンベッディングモデル、LLM、ベクトルストア、リトリーバー、チェインを格納する属性を初期化しています。
リトリーバーとチェインについては、GraphRAG検索用、標準ベクトル検索用でそれぞれ持つようにしています。
OpenAIAPIキーは、環境変数OPENAI_API_KEYに設定されていることを前提としています。
ハードコーディングするなよ?
テストデータ読み込み
次にテストデータを読み込むよ。
def load_sample_data(self) -> str:
"""サンプルデータ(動物データセット)を読み込み"""
try:
# サンプル動物データを作成
self.documents = fetch_documents()
return f"[成功] {len(self.documents)}件の動物データを読み込みました"
except Exception as e:
return f"[エラー] データ読み込みエラー: {str(e)}"
今回は動物データセットを使用して検証します。graph_rag_example_helpersから提供されるサンプルデータを利用しています。
中身はこんな感じ。(3件だけ出力しました)
[Document(id='aardvark', metadata={'type': 'mammal', 'number_of_legs': 4, 'keywords': ['burrowing', 'nocturnal', 'ants', 'savanna'], 'habitat': 'savanna', 'tags': [{'a': 5, 'b': 7}, {'a': 8, 'b': 10}]}, page_content='the aardvark is a nocturnal mammal known for its burrowing habits and long snout used to sniff out ants.'),
Document(id='albatross', metadata={'type': 'bird', 'number_of_legs': 2, 'keywords': ['seabird', 'wingspan', 'ocean'], 'habitat': 'marine', 'tags': [{'a': 5, 'b': 8}, {'a': 8, 'b': 10}]}, page_content='the albatross is a large seabird with the longest wingspan of any bird, allowing it to glide effortlessly over oceans.'),
Document(id='alligator', metadata={'type': 'reptile', 'number_of_legs': 4, 'keywords': ['reptile', 'jaws', 'wetlands'], 'diet': 'carnivorous', 'nested': {'a': 5}}, page_content='alligators are large reptiles with powerful jaws and are commonly found in freshwater wetlands.')]
idには動物の名前、metadataにはその動物の属性、page_contentsにはその動物の説明文という構造になっています。
metadataのtypeは種類、number_of_legsは脚の本数、keywordは特徴、habitatは生息地です。tagsはなんだろね。
GraphRetrieverはこのmetadataを使用して、グラフベースの検索をやるらしい・・・
ベクトルストア設定
テストデータをベクトルストアに格納するよ。
def setup_vector_store(self) -> str:
"""ベクトルストアを設定"""
try:
# InMemoryVectorStoreを作成
self.vector_store = InMemoryVectorStore.from_documents(
documents=self.documents,
embedding=self.embeddings
)
return "[成功] ベクトルストアが正常に作成されました"
except Exception as e:
return f"[エラー] ベクトルストア作成エラー: {str(e)}"
LangChainのInMemoryVectorStoreを使用してベクトルストアを構築します。
特に言うことなし。
GraphRAG検索用レトリーバー作成
GraphRAG検索用レトリーバーを作成するよ。
def setup_graph_retriever(self, k: int = 5, start_k: int = 1, max_depth: int = 2) -> str:
"""GraphRetrieverを設定"""
try:
# GraphRetrieverを作成
self.graph_retriever = GraphRetriever(
store=self.vector_store,
edges=[("habitat", "habitat")],
strategy=Eager(k=k, start_k=start_k, max_depth=max_depth)
)
return f"[成功] GraphRetriever設定完了 (k={k}, start_k={start_k}, max_depth={max_depth})"
except Exception as e:
return f"[エラー] GraphRetriever作成エラー: {str(e)}"
ここがGraphRetrieverの核心部分。
エッジ(関係性)を指定して、グラフ構造での検索を実行します。
-
edges: 検索時のデータ間の関係性を指定(from, to) -
strategy: 検索戦略 -
k: 最終的な検索結果数 -
start_k: 初期検索数 -
max_depth: グラフ探索の最大深度
今回のedges=[("habitat", "habitat")]は、「生息地で紐づけて探索」ということらしい。
とりあえずこれで。
GraphRAG検索用チェイン作成
GraphRAG検索用のLCELチェインを作成するよ。
def setup_graph_chain(self) -> str:
"""GraphRAG用のRAGチェーンを設定"""
try:
# プロンプトテンプレートを作成
prompt = ChatPromptTemplate.from_template("""
以下のコンテキストのみに基づいて質問に答えてください。
コンテキスト: {context}
質問: {question}
回答: """)
def format_docs(docs: List[Document]) -> str:
"""ドキュメントをフォーマット"""
formatted_docs = []
for doc in docs:
doc_text = f"動物: {doc.id}\n"
doc_text += f"説明: {doc.page_content}\n"
doc_text += f"メタデータ: {doc.metadata}"
formatted_docs.append(doc_text)
return "\n\n".join(formatted_docs)
# GraphRAG用RAGチェーンを作成
self.graph_chain = (
{"context": self.graph_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| self.llm
| StrOutputParser()
)
return "[成功] GraphRAG用RAGチェーンが正常に設定されました"
except Exception as e:
return f"[エラー] GraphRAGチェーン作成エラー: {str(e)}"
GraphRetrieverを使用したRAGチェーンを構築します。
LangChainのLCELで、検索→フォーマット→プロンプト→LLM→パースの流れを定義しています。
これも特に言うことなし。
標準検索用のレトリーバー、チェイン作成
GraphRAGと比較できるように、標準ベクトル検索用のレトリーバー、LCELチェインを作成しとくよ。
def setup_standard_retriever(self, k: int = 5) -> str:
"""標準ベクトル検索用のリトリーバーを設定"""
try:
# 標準ベクトル検索リトリーバーを作成
self.standard_retriever = self.vector_store.as_retriever(search_kwargs={"k": k})
return f"[成功] 標準ベクトル検索リトリーバー設定完了 (k={k})"
except Exception as e:
return f"[エラー] 標準リトリーバー作成エラー: {str(e)}"
def setup_standard_chain(self) -> str:
"""標準ベクトル検索用のRAGチェーンを設定"""
try:
# プロンプトテンプレートを作成
prompt = ChatPromptTemplate.from_template("""
以下のコンテキストのみに基づいて質問に答えてください。
コンテキスト: {context}
質問: {question}
回答: """)
def format_docs(docs: List[Document]) -> str:
"""ドキュメントをフォーマット"""
formatted_docs = []
for doc in docs:
doc_text = f"動物: {doc.id}\n"
doc_text += f"説明: {doc.page_content}\n"
doc_text += f"メタデータ: {doc.metadata}"
formatted_docs.append(doc_text)
return "\n\n".join(formatted_docs)
# 標準ベクトル検索用RAGチェーンを作成
self.standard_chain = (
{"context": self.standard_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| self.llm
| StrOutputParser()
)
return "[成功] 標準ベクトル検索用RAGチェーンが正常に設定されました"
except Exception as e:
return f"[エラー] 標準RAGチェーン作成エラー: {str(e)}"
これも特に言うことなし。
標準検索とGraphRAG検索の比較
GraphRAGの検索を実装するよ。
標準ベクトル検索も実施して、比較した出力を出すようにするよ。
def compare_with_standard_retrieval(self, question: str) -> str:
"""標準検索との比較"""
try:
if not question.strip():
return "質問を入力してください"
# 1. 標準ベクトル検索
standard_docs = self.standard_retriever.invoke(question)
standard_answer = self.standard_chain.invoke(question)
# 標準検索結果(全メタデータ付き)
standard_info_list = []
for doc in standard_docs:
doc_text = f"• {doc.id}: {doc.page_content}\n"
doc_text += f" {doc.metadata}"
standard_info_list.append(doc_text)
standard_info = "\n".join(standard_info_list)
# 2. GraphRAG検索
graph_docs = self.graph_retriever.invoke(question)
graph_answer = self.graph_chain.invoke(question)
# GraphRAG検索結果(全メタデータ付き)
graph_info_list = []
for doc in graph_docs:
doc_text = f"• {doc.id}: {doc.page_content}\n"
doc_text += f" {doc.metadata}"
graph_info_list.append(doc_text)
graph_info = "\n".join(graph_info_list)
# 比較結果をフォーマット
comparison = f"""
═══════════════════════════════════════════════════════════════
【標準ベクトル検索による回答】
{standard_answer}
【標準ベクトル検索で取得されたドキュメント】({len(standard_docs)}件):
{standard_info}
═══════════════════════════════════════════════════════════════
【GraphRAGによる回答】
{graph_answer}
【GraphRAGで取得されたドキュメント】({len(graph_docs)}件):
{graph_info}
═══════════════════════════════════════════════════════════════
"""
return comparison
except Exception as e:
return f"[エラー] エラー: {str(e)}"
LLMからの回答と、実際に検索されたドキュメントを表示するようにしています。
ここまでで、一応必要な処理は全部実装しました。
3. UI実装
Gradioを使用して、簡単にブラウザから検索を実行できるようにします。
私にフロントエンドのセンスはない。
import
まずはimport!
import gradio as gr
from graphrag import graphrag_class
Gradioで必要なものと、graphrag.pyで作成したGraphRAGクラスインスタンスのgraphrag_classをインポートします。
セットアップ
Gradioインターフェースから実行できるアクションを実装するよ。
まずはセットアップから実装するよ。
def handle_setup(k: int, start_k: int, max_depth: int) -> str:
"""セットアップを実行"""
try:
results = []
results.append("[開始] 一括セットアップを開始します...\n")
# 手順1: APIキー設定状況を確認
results.append("【手順1】APIキー設定を確認中...")
if graphrag_class.embeddings and graphrag_class.llm:
api_result = "[成功] APIキーは既に設定されています"
else:
api_result = "[エラー] APIキーが設定されていません。環境変数OPENAI_API_KEYを確認してください。"
results.append(f" 結果: {api_result}")
# 手順2: サンプルデータ読み込み
results.append("\n【手順2】サンプルデータを読み込み中...")
data_result = graphrag_class.load_sample_data()
results.append(f" 結果: {data_result}")
# 手順3: ベクトルストア作成
results.append("\n【手順3】ベクトルストアを作成中...")
vector_result = graphrag_class.setup_vector_store()
results.append(f" 結果: {vector_result}")
# 手順4: 標準ベクトル検索リトリーバー設定
results.append("\n【手順4】標準ベクトル検索リトリーバーを設定中...")
standard_retriever_result = graphrag_class.setup_standard_retriever(k)
results.append(f" 結果: {standard_retriever_result}")
# 手順5: 標準ベクトル検索チェーン設定
results.append("\n【手順5】標準ベクトル検索チェーンを設定中...")
standard_chain_result = graphrag_class.setup_standard_chain()
results.append(f" 結果: {standard_chain_result}")
# 手順6: GraphRetriever設定
results.append("\n【手順6】GraphRetrieverを設定中...")
retriever_result = graphrag_class.setup_graph_retriever(k, start_k, max_depth)
results.append(f" 結果: {retriever_result}")
# 手順7: GraphRAGチェーン設定
results.append("\n【手順7】GraphRAGチェーンを設定中...")
chain_result = graphrag_class.setup_graph_chain()
results.append(f" 結果: {chain_result}")
return "\n".join(results)
except Exception as e:
return f"セットアップ中にエラーが発生しました:\n{str(e)}"
APIキーの確認~チェーンの作成までの一連の流れを実行します。
引数のk start_k max_depthは後にUIから入力できるようにします。
比較検索
標準ベクトル検索とGraphRAG検索の比較を実行するアクションを実装するよ。
def handle_comparison(question: str) -> str:
"""標準検索との比較を実行し、結果を整形して返す"""
try:
comparison = graphrag_class.compare_with_standard_retrieval(question)
return comparison
except Exception as e:
return f"比較中にエラーが発生しました:\n{str(e)}"
UI表示
インターフェースを実装するよ。
def create_main_interface() -> gr.Blocks:
"""メインインターフェースを作成"""
with gr.Blocks(title="LangChain GraphRAG") as demo:
with gr.Tab("GraphRAG検索"):
# セットアップ
with gr.Column():
with gr.Row():
k_input = gr.Slider(1, 10, value=5, step=1, label="検索結果数 (k)")
start_k_input = gr.Slider(1, 5, value=1, step=1, label="開始点数 (start_k)")
max_depth_input = gr.Slider(0, 3, value=2, step=1, label="最大深度 (max_depth)")
setup_all_button = gr.Button("セットアップ実行", size="lg")
setup_status = gr.Textbox(
label="セットアップ実行結果",
lines=10,
interactive=False
)
# 検索
with gr.Column():
question_input = gr.Textbox(
label="質問",
placeholder="質問を入力してください...",
lines=2
)
with gr.Row():
compare_button = gr.Button("標準検索と比較")
# 比較結果表示エリア
comparison_output = gr.Textbox(
label="検索結果比較",
lines=12,
interactive=False
)
# セットアップ
setup_all_button.click(
fn=handle_setup,
inputs=[k_input, start_k_input, max_depth_input],
outputs=[setup_status]
)
# 比較検索
compare_button.click(
fn=handle_comparison,
inputs=[question_input],
outputs=[comparison_output]
)
return demo
セットアップと、比較検索が実行できるようにします。
それぞれの結果はTextBoxに表示します。
セットアップでは、検索結果数 (k)、開始点数 (start_k)、最大深度 (max_depth) をSliderで入力できるようにします。
こんなとこかな?
エントリーポイント
最後に、エントリーポイントを実装するよ。
if __name__ == "__main__":
# メインアプリケーションを起動
demo = create_main_interface()
demo.launch(
server_name="0.0.0.0", # Docker環境用
server_port=7860,
share=False,
debug=True
)
Docker環境での実行を考慮し、server_name="0.0.0.0"でアクセス可能にしています。
これでへっぽこ検証環境が完成!!!
4. テスト
トップ画面表示
ブラウザからアクセスすると、次のような感じに表示されるよ。

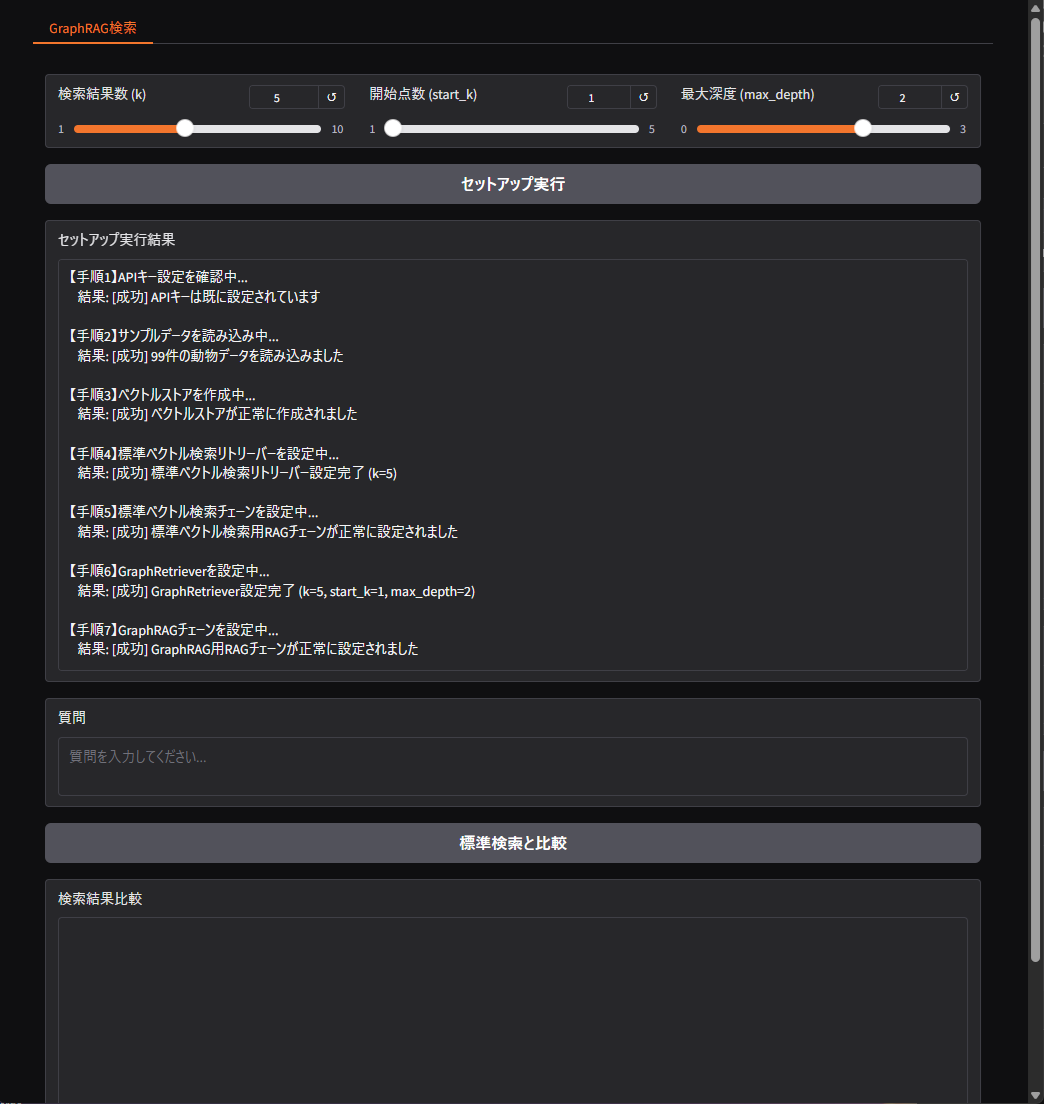
セットアップ実行
検索結果数は5、開始点数は1、最大深度は2で実行するとこうなります。
質問(ケース1)
まずは簡単な質問をします。
カピバラについて説明してください。
この質問は、単にカピバラの説明を求めるだけなので、標準ベクトル検索とGraphRAG検索で、差は出ないと考えられます。
実行すると、次のような感じに表示されます。

スクショだとスクロールが面倒なので、出力されたテキストだけ記載します。
═══════════════════════════════════════════════════════════════
【標準ベクトル検索による回答】
カピバラは、世界最大の齧歯類であり、非常に社交的な動物です。
【標準ベクトル検索で取得されたドキュメント】(5件):
• capybara: capybaras are the largest rodents in the world and are highly social animals.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['rodent', 'social', 'largest'], 'habitat': 'wetlands'}
• gorilla: gorillas are large primates known for their strength, intelligence, and family-oriented behavior.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['strength', 'intelligence', 'primate'], 'habitat': 'forest'}
• baboon: baboons are highly social primates with complex group dynamics and strong bonds.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['social', 'primates', 'group'], 'diet': 'omnivorous'}
• chimpanzee: chimpanzees are intelligent primates that share about 98% of their dna with humans.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['intelligent', 'primates', 'dna'], 'habitat': 'forest'}
• leopard: leopards are big cats known for their spotted coats and ability to climb trees.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['big cat', 'spotted coat', 'climbing'], 'habitat': 'forest'}
═══════════════════════════════════════════════════════════════
【GraphRAGによる回答】
カピバラは世界最大の齧歯類であり、非常に社交的な動物です。
【GraphRAGで取得されたドキュメント】(5件):
• capybara: capybaras are the largest rodents in the world and are highly social animals.
{'_depth': 0, '_similarity_score': np.float64(0.39108863963083496), 'type': 'mammal', 'number_of_legs': 4, 'keywords': ['rodent', 'social', 'largest'], 'habitat': 'wetlands'}
• crocodile: crocodiles are large reptiles with powerful jaws and a long lifespan, often living over 70 years.
{'_depth': 1, '_similarity_score': np.float64(0.19050276796459897), 'type': 'reptile', 'number_of_legs': 4, 'keywords': ['reptile', 'jaws', 'long lifespan'], 'habitat': 'wetlands'}
• frog: frogs are amphibians known for their jumping ability and croaking sounds.
{'_depth': 1, '_similarity_score': np.float64(0.1655925823302462), 'type': 'amphibian', 'number_of_legs': 4, 'keywords': ['jumping', 'croaking', 'amphibian'], 'habitat': 'wetlands'}
• crane: cranes are large, elegant birds known for their elaborate courtship dances.
{'_depth': 1, '_similarity_score': np.float64(0.12539105810127615), 'type': 'bird', 'number_of_legs': 2, 'keywords': ['elegant', 'courtship', 'dance'], 'habitat': 'wetlands'}
• newt: newts are small amphibians known for their ability to regenerate limbs and tails.
{'_depth': 1, '_similarity_score': np.float64(0.12451898036377396), 'type': 'amphibian', 'number_of_legs': 4, 'keywords': ['regeneration', 'amphibian', 'small'], 'habitat': 'wetlands'}
═══════════════════════════════════════════════════════════════
標準ベクトル検索とGraphRAGで、取得されたドキュメントには差がありますが、カピバラが最も類似度が高いドキュメントとして検索されているのは同じです。そして、LLMからの回答も同じです。
よって、想定どおりです。
質問(ケース2)
次は、ちょっと込み入った質問をします。
カピバラと同じ生息地の、他の動物を教えてください。
この質問は、質問文自体にカピバラの生息地はどこかは記載されていないため、標準ベクトル検索では上手く検索できないと考えられます。
一方、GraphRAGでは 生息地(habitat) のメタデータを活用して、グラフベース検索が実施できるはずなので、検索できると考えられます。
実際に実行すると、次のようになりました。
═══════════════════════════════════════════════════════════════
【標準ベクトル検索による回答】
カピバラと同じ生息地の動物として、メタデータに「habitat: wetlands」と記載されている動物はありません。ただし、カピバラは湿地帯に生息しているため、湿地帯に生息する他の動物も考えられますが、提供されたコンテキストにはその情報が含まれていません。
【標準ベクトル検索で取得されたドキュメント】(5件):
• capybara: capybaras are the largest rodents in the world and are highly social animals.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['rodent', 'social', 'largest'], 'habitat': 'wetlands'}
• baboon: baboons are highly social primates with complex group dynamics and strong bonds.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['social', 'primates', 'group'], 'diet': 'omnivorous'}
• chimpanzee: chimpanzees are intelligent primates that share about 98% of their dna with humans.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['intelligent', 'primates', 'dna'], 'habitat': 'forest'}
• gorilla: gorillas are large primates known for their strength, intelligence, and family-oriented behavior.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['strength', 'intelligence', 'primate'], 'habitat': 'forest'}
• lemur: lemurs are primates native to madagascar, known for their large eyes and social behavior.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['primates', 'madagascar', 'social'], 'diet': 'omnivorous'}
═══════════════════════════════════════════════════════════════
【GraphRAGによる回答】
カピバラと同じ生息地の動物には、クロコダイル、イモリ、カエル、ツルなどがあります。
【GraphRAGで取得されたドキュメント】(5件):
• capybara: capybaras are the largest rodents in the world and are highly social animals.
{'_depth': 0, '_similarity_score': np.float64(0.3941721982268529), 'type': 'mammal', 'number_of_legs': 4, 'keywords': ['rodent', 'social', 'largest'], 'habitat': 'wetlands'}
• crocodile: crocodiles are large reptiles with powerful jaws and a long lifespan, often living over 70 years.
{'_depth': 1, '_similarity_score': np.float64(0.2129868588113395), 'type': 'reptile', 'number_of_legs': 4, 'keywords': ['reptile', 'jaws', 'long lifespan'], 'habitat': 'wetlands'}
• frog: frogs are amphibians known for their jumping ability and croaking sounds.
{'_depth': 1, '_similarity_score': np.float64(0.18733894803800244), 'type': 'amphibian', 'number_of_legs': 4, 'keywords': ['jumping', 'croaking', 'amphibian'], 'habitat': 'wetlands'}
• newt: newts are small amphibians known for their ability to regenerate limbs and tails.
{'_depth': 1, '_similarity_score': np.float64(0.18700512133676128), 'type': 'amphibian', 'number_of_legs': 4, 'keywords': ['regeneration', 'amphibian', 'small'], 'habitat': 'wetlands'}
• crane: cranes are large, elegant birds known for their elaborate courtship dances.
{'_depth': 1, '_similarity_score': np.float64(0.14329800911921964), 'type': 'bird', 'number_of_legs': 2, 'keywords': ['elegant', 'courtship', 'dance'], 'habitat': 'wetlands'}
═══════════════════════════════════════════════════════════════
標準ベクトル検索の結果を見ると、取得されたドキュメントで 生息地(habitat) が 湿地帯(wetlands) であるドキュメントは、カピバラしか取得できていません。
そして回答も、提供されたコンテキストにはその情報が含まれていません となっています。
一方、GraphRAG検索の結果を見ると、取得されたドキュメントの全てで、生息地(habitat) が 湿地帯(wetlands) となっています。
そして回答も、クロコダイル、イモリ、カエル、ツルなどがありますとなっており、正しく回答ができています。
つまり、グラフベース検索の効果が出ています。やったぜ。
質問(ケース3)
最後に、GraphRAG検索でも上手くいかなかったケース。
カピバラとは異なる生息地の、動物を教えてください。
同じではなく異なるものを答えてもらいます。
═══════════════════════════════════════════════════════════════
【標準ベクトル検索による回答】
ゴリラは森林に生息しています。
【標準ベクトル検索で取得されたドキュメント】(5件):
• capybara: capybaras are the largest rodents in the world and are highly social animals.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['rodent', 'social', 'largest'], 'habitat': 'wetlands'}
• gorilla: gorillas are large primates known for their strength, intelligence, and family-oriented behavior.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['strength', 'intelligence', 'primate'], 'habitat': 'forest'}
• lemur: lemurs are primates native to madagascar, known for their large eyes and social behavior.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['primates', 'madagascar', 'social'], 'diet': 'omnivorous'}
• baboon: baboons are highly social primates with complex group dynamics and strong bonds.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['social', 'primates', 'group'], 'diet': 'omnivorous'}
• hippopotamus: hippopotamuses are large semi-aquatic mammals known for their massive size and territorial behavior.
{'type': 'mammal', 'number_of_legs': 4, 'keywords': ['massive', 'semi-aquatic', 'territorial'], 'habitat': 'rivers'}
═══════════════════════════════════════════════════════════════
【GraphRAGによる回答】
カピバラの生息地は湿地帯ですが、異なる生息地の動物としては、例えば「サバンナに生息するライオン」や「山岳地帯に生息するヤギ」などがあります。
【GraphRAGで取得されたドキュメント】(5件):
• capybara: capybaras are the largest rodents in the world and are highly social animals.
{'_depth': 0, '_similarity_score': np.float64(0.35521445665708806), 'type': 'mammal', 'number_of_legs': 4, 'keywords': ['rodent', 'social', 'largest'], 'habitat': 'wetlands'}
• crocodile: crocodiles are large reptiles with powerful jaws and a long lifespan, often living over 70 years.
{'_depth': 1, '_similarity_score': np.float64(0.2113797400355154), 'type': 'reptile', 'number_of_legs': 4, 'keywords': ['reptile', 'jaws', 'long lifespan'], 'habitat': 'wetlands'}
• frog: frogs are amphibians known for their jumping ability and croaking sounds.
{'_depth': 1, '_similarity_score': np.float64(0.20479202801452734), 'type': 'amphibian', 'number_of_legs': 4, 'keywords': ['jumping', 'croaking', 'amphibian'], 'habitat': 'wetlands'}
• newt: newts are small amphibians known for their ability to regenerate limbs and tails.
{'_depth': 1, '_similarity_score': np.float64(0.18534795764591627), 'type': 'amphibian', 'number_of_legs': 4, 'keywords': ['regeneration', 'amphibian', 'small'], 'habitat': 'wetlands'}
• crane: cranes are large, elegant birds known for their elaborate courtship dances.
{'_depth': 1, '_similarity_score': np.float64(0.1395212230121794), 'type': 'bird', 'number_of_legs': 2, 'keywords': ['elegant', 'courtship', 'dance'], 'habitat': 'wetlands'}
═══════════════════════════════════════════════════════════════
標準ベクトル検索の結果を見ると、取得されたドキュメントの中に、 生息地(habitat) が 湿地帯(wetlands) ではない、ゴリラ(gorilla) と カバ(hippopotamus) があります。
恐らくこのドキュメントが含まれたのはたまたまですが、たまたま含まれていたおかげで、回答はゴリラは森林に生息しています。と答えられた模様です。たまたま。
カバは検索順位が低くて無視されたのか?ゴリラ推しなのか?
一方、GraphRAG検索の結果を見ると、取得されたドキュメントの全てで、生息地(habitat) が 湿地帯(wetlands) となっています。
結果、LLMは自分の知識を総動員してサバンナに生息するライオンと山岳地帯に生息するヤギを答えてきました。
おい!コンテキストのみに基づいて質問に答えてくださいって言っただろ!!!
GraphRetrieverでは、一致するものベースの検索を行っている模様です。
まぁ普通に考えると、一致していないのであれば関係性がないので、関係性に基づいた検索で引っかけることはできないということなのでしょう。多分ね。
こういうケースは、LLMに対する質問を複数回投げかけるアプローチが有効だと思われます。
Agentic-RAGとかね。
多分ね。
詳しくないけど。
5. 動的Edge検索拡張
ここで、GraphRAG検索用レトリーバーを思い出してください。(再掲します)
def setup_graph_retriever(self, k: int = 5, start_k: int = 1, max_depth: int = 2) -> str:
"""GraphRetrieverを設定"""
try:
# GraphRetrieverを作成
self.graph_retriever = GraphRetriever(
store=self.vector_store,
edges=[("habitat", "habitat")],
strategy=Eager(k=k, start_k=start_k, max_depth=max_depth)
)
return f"[成功] GraphRetriever設定完了 (k={k}, start_k={start_k}, max_depth={max_depth})"
except Exception as e:
return f"[エラー] GraphRetriever作成エラー: {str(e)}"
edgesには("habitat", "habitat")しか指定していませんので、現在は 生息地 (habitat) に関してしかグラフベースの検索ができません。これって不便じゃね?
これを、ユーザーからの質問に応じて動的にedges指定ができたら便利だよね。
やってみましょう。
EdgeSelectionクラス
動的にedgesを判断するのは、LLMにやってもらおうと思います。
edgesの形式で回答してもらいたいので、まずは回答形式を定義するEdgeSelectionクラスを作成するよ。
class EdgeSelection(BaseModel):
"""edgesの選択結果を表すモデル"""
edges: List[List[str]] = Field(
description="選択されたedgeのリスト。各edgeは2つの文字列からなる配列",
min_items=1,
max_items=5
)
edgesの形式で回答してもらいたいと言いながら、List[List[str]]になってるやんけ!
これは、後に構造化出力を行う際にwith_structured_outputを使用するためです。
JSONにはTupleの概念がなく、 配列(Array) として表現されるため、Listの方が良いのです。
ありがとうclaude-4-sonnet様
max_itemsは適当です。6つ以上の関係性が必要になる質問があったら教えてください(
動的Edge判定
ユーザーからの質問に応じて、動的にedgesを判断する処理を作成するよ。
def llm_determine_edges(self, question: str) -> List[Tuple[str, str]]:
"""LLMを使用してedgesを動的に決定"""
try:
# with_structured_outputを使用してLLMチェーンを作成
structured_llm = self.llm.with_structured_output(EdgeSelection)
edge_prompt = ChatPromptTemplate.from_template("""
質問の内容を分析し、最適なグラフ検索のエッジを決定してください。
利用可能なエッジタイプ:
1. habitat: 生息地に関する探索
2. origin: 起源に関する探索
3. type: 種類に関する探索
4. number_of_legs: 足の数に関する探索
5. keyword: 特徴に関する探索
質問内容から判断して、最も関連性の高いエッジを1-3個選択してください。ただし、重複したエッジは選択しないでください。
各エッジは同じタイプを2回繰り返した形式で指定してください。
質問: {question}
例:
- 生息地に関する質問: [["habitat", "habitat"]]
- 起源に関する質問: [["origin", "origin"]]
- 種類に関する質問: [["type", "type"]]
- 足の数に関する質問: [["number_of_legs", "number_of_legs"]]
- 特徴に関する質問: [["keyword", "keyword"]]
- 複合的な質問: [["habitat", "habitat"], ["origin", "origin"]]
""")
# 構造化されたLLMチェーンを実行
edge_chain = edge_prompt | structured_llm
result = edge_chain.invoke({"question": question})
# 結果をTupleのリストに変換
edges = []
for edge in result.edges:
if len(edge) == 2:
edges.append(tuple(edge))
return edges
except Exception as e:
# エラーなので空を返す
return []
構造化出力用のLCELチェインを作成して、実行しています。
利用可能なエッジタイプを載せていますが、本当はここも動的にやるべきなんでしょうね。すんまそん。
回答はEdgeSelectionの形式なので、edgesの形式になるように変換をかけています。
コンストラクタ
コンストラクタを微調整するよ。
def __init__(self):
"""コンストラクタ"""
self.embeddings: Optional[OpenAIEmbeddings] = None
self.vector_store: Optional[InMemoryVectorStore] = None
self.graph_retriever: Optional[GraphRetriever] = None
self.graph_chain = None
self.standard_retriever = None
self.standard_chain = None
+ self.dynamic_graph_retriever: Optional[GraphRetriever] = None
+ self.dynamic_chain = None
self.llm: Optional[ChatOpenAI] = None
self.documents: List[Document] = []
# OpenAI APIキーの存在確認
if os.getenv('OPENAI_API_KEY'):
try:
# エンベディングモデルとLLMを初期化
# (これらは自動的に環境変数 OPENAI_API_KEY を参照)
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
self.llm = ChatOpenAI(model="gpt-4.1-nano", temperature=0)
logger.info("OpenAI APIキーを確認し、モデルを初期化しました")
except Exception as e:
logger.warning(f"OpenAIモデル初期化エラー: {e}")
else:
logger.warning("OPENAI_API_KEY環境変数が設定されていません")
動的Edge検索用のレトリーバーとチェインを保持できるようにします。
それだけ!
動的Edge検索用レトリーバー作成
動的Edge検索用のレトリーバーを作成するよ。
def setup_dynamic_graph_retriever(
self,
edges: List[Tuple[str, str]],
k: int = 5,
start_k: int = 1,
max_depth: int = 2
) -> str:
"""動的edgesを使用したGraphRetrieverを設定"""
try:
# 動的GraphRetrieverを作成
self.dynamic_graph_retriever = GraphRetriever(
store=self.vector_store,
edges=edges,
strategy=Eager(k=k, start_k=start_k, max_depth=max_depth)
)
return f"[成功] 動的GraphRetriever設定完了 (edges={edges}, k={k}, start_k={start_k}, max_depth={max_depth})"
except Exception as e:
return f"[エラー] 動的GraphRetriever作成エラー: {str(e)}"
GraphRAG検索用レトリーバーのedgesを引数化して指定できるようにしただけです。
動的Edge検索用チェイン作成
動的Edge検索用のLCELチェインを作成するよ。
def setup_dynamic_chain(self) -> str:
"""動的edges用のRAGチェーンを設定"""
try:
# プロンプトテンプレートを作成
prompt = ChatPromptTemplate.from_template("""
以下のコンテキストのみに基づいて質問に答えてください。
コンテキスト: {context}
質問: {question}
回答: """)
def format_docs(docs: List[Document]) -> str:
"""ドキュメントをフォーマット"""
formatted_docs = []
for doc in docs:
doc_text = f"動物: {doc.id}\n"
doc_text += f"説明: {doc.page_content}\n"
doc_text += f"メタデータ: {doc.metadata}"
formatted_docs.append(doc_text)
return "\n\n".join(formatted_docs)
# 動的edges用RAGチェーンを作成
self.dynamic_chain = (
{"context": self.dynamic_graph_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| self.llm
| StrOutputParser()
)
return "[成功] 動的edges用RAGチェーンが正常に設定されました"
except Exception as e:
return f"[エラー] 動的edgesRAGチェーン作成エラー: {str(e)}"
特に言うことなし。
動的Edge検索
実際に、動的Edge検索を行う処理を作成するよ。
def query_with_dynamic_edges(
self,
question: str,
k: int = 5,
start_k: int = 1,
max_depth: int = 2
) -> Tuple[str, str]:
"""LLMベースの動的edgesでGraphRAG検索を実行"""
try:
if not question.strip():
return "質問を入力してください", ""
# LLMを使用してedgesを動的に決定
dynamic_edges = self.llm_determine_edges(question)
if not dynamic_edges:
return "[エラー] エッジの選択に失敗しました", ""
# 動的GraphRetrieverを設定
setup_result = self.setup_dynamic_graph_retriever(dynamic_edges, k, start_k, max_depth)
if "[エラー]" in setup_result:
return f"[エラー] リトリーバー設定エラー: {setup_result}", ""
# 動的RAGチェーンを設定
chain_result = self.setup_dynamic_chain()
if "[エラー]" in chain_result:
return f"[エラー] チェーン設定エラー: {chain_result}", ""
# 関連ドキュメントを取得
docs = self.dynamic_graph_retriever.invoke(question)
# 取得されたドキュメント情報
doc_info_list = []
for doc in docs:
doc_text = f"• {doc.id}: {doc.page_content}\n"
doc_text += f" {doc.metadata}"
doc_info_list.append(doc_text)
doc_info = "\n".join(doc_info_list)
# RAGチェーンで回答生成
answer = self.dynamic_chain.invoke(question)
# 結果のフォーマット
edges_info = f"[統計] LLMベース動的edges選択結果:\n"
edges_info += f" 選択されたedges: {dynamic_edges}\n"
edges_info += f" パラメータ: k={k}, start_k={start_k}, max_depth={max_depth}"
result_info = f"{edges_info}\n\n取得されたドキュメント ({len(docs)}件):\n{doc_info}"
return answer, result_info
except Exception as e:
return f"[エラー] エラー: {str(e)}", ""
これも特に言うことなし。
これで動的Edge検索の処理が完成しました!
動的Edge検索(UI側)
app.pyの方に、動的Edge検索のアクションを実装するよ。
def handle_dynamic_search(question: str, k: int, start_k: int, max_depth: int) -> tuple[str, str]:
"""動的Edge検索を実行し、結果を整形して返す"""
try:
if not question.strip():
return "質問を入力してください", ""
# LLMベースの動的edges検索を実行
answer, info = graphrag_class.query_with_dynamic_edges(
question=question,
k=k,
start_k=start_k,
max_depth=max_depth
)
return answer, info
except Exception as e:
return f"動的検索中にエラーが発生しました:\n{str(e)}", ""
graphrag.pyのquety_with_dynamic_edgesを呼び出すだけです。
UI調整
動的Edge検索用のUIを作成するよ。
def create_main_interface() -> gr.Blocks:
"""メインインターフェースを作成"""
with gr.Blocks(title="LangChain GraphRAG") as demo:
with gr.Tab("GraphRAG検索"):
# セットアップ
with gr.Column():
with gr.Row():
k_input = gr.Slider(1, 10, value=5, step=1, label="検索結果数 (k)")
start_k_input = gr.Slider(1, 5, value=1, step=1, label="開始点数 (start_k)")
max_depth_input = gr.Slider(0, 3, value=2, step=1, label="最大深度 (max_depth)")
setup_all_button = gr.Button("セットアップ実行", size="lg")
setup_status = gr.Textbox(
label="セットアップ実行結果",
lines=10,
interactive=False
)
# 検索
with gr.Column():
question_input = gr.Textbox(
label="質問",
placeholder="質問を入力してください...",
lines=2
)
with gr.Row():
compare_button = gr.Button("標準検索と比較")
# 比較結果表示エリア
comparison_output = gr.Textbox(
label="検索結果比較",
lines=12,
interactive=False
)
+ with gr.Tab("動的Edge検索"):
+ with gr.Row():
+ k_input_2 = gr.Slider(1, 10, value=5, step=1, label="検索結果数 (k)")
+ start_k_input_2 = gr.Slider(1, 5, value=1, step=1, label="開始点数 (start_k)")
+ max_depth_input_2 = gr.Slider(0, 3, value=2, step=1, label="最大深度 (max_depth)")
+
+ # 動的edges検索セクション
+ with gr.Row():
+ dynamic_question = gr.Textbox(
+ label="質問",
+ placeholder="LLMベース動的edges検索で質問を入力...",
+ lines=2,
+ scale=3
+ )
+
+ with gr.Column(scale=1):
+ gr.Markdown("**検索方法**: LLMベース動的Edges")
+ dynamic_search_button = gr.Button("動的Edges検索", variant="primary")
+
+ # 検索結果表示
+ dynamic_answer = gr.Textbox(
+ label="回答",
+ lines=6,
+ interactive=False
+ )
+
+ dynamic_info = gr.Textbox(
+ label="LLMベース動的Edges選択結果とドキュメント",
+ lines=10,
+ interactive=False
+ )
# 一括セットアップ機能
setup_all_button.click(
fn=handle_setup,
inputs=[k_input, start_k_input, max_depth_input],
outputs=[setup_status]
)
compare_button.click(
fn=handle_comparison,
inputs=[question_input],
outputs=[comparison_output]
)
+ dynamic_search_button.click(
+ fn=handle_dynamic_search,
+ inputs=[dynamic_question, k_input_2, start_k_input_2, max_depth_input_2],
+ outputs=[dynamic_answer, dynamic_info]
+ )
return demo
別のタブで実装しました。
検索結果数 (k)、開始点数 (start_k)、最大深度 (max_depth) は動的Edge検索でも指定できるようにします。
6. テスト
セットアップ
動的Edge検索をする場合も、一度セットアップの実行が必要です。
ブラウザからアクセスし、実際に実行すると、次のようになります。

セットアップが完了したので、動的Edge検索を試してみましょう!
動的Edge検索タブ表示
動的Edge検索タブを選択すると、次のような感じに表示されます。

質問(ケース1)
次のような質問をしてみます。
蟹と同じ生息地の、他の動物を教えてください。
GraphRAG検索で実施したケース2の質問を、カピバラから蟹に変更したものですね。
animalsデータセットに存在するドキュメント数の都合上、変更しています。
この質問の場合は、質問文から「生息地に関してグラフ検索するのが最適」とLLMが判断してくれるはずです。
(つまり、edgesが("habitat", "habitat")となるはず)
実際に実行すると、次のようになりました。
蟹と同じ生息地の動物には、バラクーダやアホウドリなどがあります。
[統計] LLMベース動的edges選択結果:
選択されたedges: [('habitat', 'habitat')]
パラメータ: k=5, start_k=1, max_depth=2
取得されたドキュメント (3件):
• crab: crabs are crustaceans with hard shells and pincers, commonly found near coastal areas.
{'_depth': 0, '_similarity_score': np.float64(0.41514439754131205), 'type': 'crustacean', 'number_of_legs': 8, 'keywords': ['hard shell', 'pincers', 'coastal'], 'habitat': 'marine'}
• barracuda: the barracuda is a fierce predatory fish with sharp teeth and streamlined bodies.
{'_depth': 1, '_similarity_score': np.float64(0.1818930304289077), 'type': 'fish', 'number_of_legs': 0, 'keywords': ['predatory', 'sharp teeth', 'streamlined'], 'habitat': 'marine'}
• albatross: the albatross is a large seabird with the longest wingspan of any bird, allowing it to glide effortlessly over oceans.
{'_depth': 1, '_similarity_score': np.float64(0.1648397512291), 'type': 'bird', 'number_of_legs': 2, 'keywords': ['seabird', 'wingspan', 'ocean'], 'habitat': 'marine', 'tags': [{'a': 5, 'b': 8}, {'a': 8, 'b': 10}]}
選択されたedgesは[('habitat', 'habitat')]となり、想定どおりです。
取得されたドキュメントは全て 生息地(habitat) が 海(marine) であり、こちらも想定どおりです。
そのため、質問に対する回答も正しくできています。
とりあえず、質問文から動的にedgesを判断することはできていますね。
質問(ケース2)
次は、edgesが 生息地(habitat) 以外になるケースを質問してみます。
蟹と同じ種類の、他の動物を教えてください。
こちらは、edgesが("type", "type")となるはずです。
蟹と同じ種類の動物には、ロブスターがあります。
[統計] LLMベース動的edges選択結果:
選択されたedges: [('type', 'type')]
パラメータ: k=5, start_k=1, max_depth=2
取得されたドキュメント (2件):
• crab: crabs are crustaceans with hard shells and pincers, commonly found near coastal areas.
{'_depth': 0, '_similarity_score': np.float64(0.4167374577567048), 'type': 'crustacean', 'number_of_legs': 8, 'keywords': ['hard shell', 'pincers', 'coastal'], 'habitat': 'marine'}
• lobster: lobsters are marine crustaceans known for their hard shells and pincers, often found on the seafloor.
{'_depth': 1, '_similarity_score': np.float64(0.3780809056343427), 'type': 'crustacean', 'number_of_legs': 10, 'keywords': ['marine', 'pincers', 'seafloor'], 'diet': 'carnivorous'}
選択されたedgesは[('type', 'type')]となり、想定どおりです。
取得されたドキュメントは全て 種類(type) が 甲殻類(crustaceans) であり、こちらも想定どおりです。
そのため、質問に対する回答も正しくできています。
よさげ!!!
質問(ケース3)
次は、複合的なedgesとなるような質問をしてみます。
蟹と同じ生息地、または同じ種類の、他の動物を教えてください。
ケース1とケース2のOR条件ですね。
蟹と同じ生息地(海洋)にいる動物として、ロブスターやバラクーダ、アホウドリ(海鳥)などがあります。
また、種類(甲殻類)としては、ロブスターも蟹と同じく甲殻類に属します。
[統計] LLMベース動的edges選択結果:
選択されたedges: [('habitat', 'habitat'), ('type', 'type')]
パラメータ: k=5, start_k=1, max_depth=2
取得されたドキュメント (5件):
• crab: crabs are crustaceans with hard shells and pincers, commonly found near coastal areas.
{'_depth': 0, '_similarity_score': np.float64(0.4292299698403932), 'type': 'crustacean', 'number_of_legs': 8, 'keywords': ['hard shell', 'pincers', 'coastal'], 'habitat': 'marine'}
• lobster: lobsters are marine crustaceans known for their hard shells and pincers, often found on the seafloor.
{'_depth': 1, '_similarity_score': np.float64(0.36814249468674887), 'type': 'crustacean', 'number_of_legs': 10, 'keywords': ['marine', 'pincers', 'seafloor'], 'diet': 'carnivorous'}
• barracuda: the barracuda is a fierce predatory fish with sharp teeth and streamlined bodies.
{'_depth': 1, '_similarity_score': np.float64(0.18796797598153847), 'type': 'fish', 'number_of_legs': 0, 'keywords': ['predatory', 'sharp teeth', 'streamlined'], 'habitat': 'marine'}
• albatross: the albatross is a large seabird with the longest wingspan of any bird, allowing it to glide effortlessly over oceans.
{'_depth': 1, '_similarity_score': np.float64(0.14965235470389615), 'type': 'bird', 'number_of_legs': 2, 'keywords': ['seabird', 'wingspan', 'ocean'], 'habitat': 'marine', 'tags': [{'a': 5, 'b': 8}, {'a': 8, 'b': 10}]}
• fish: fish are aquatic animals with gills, commonly found in both freshwater and marine environments.
{'_depth': 2, '_similarity_score': np.float64(0.24839386472829672), 'type': 'fish', 'number_of_legs': 0, 'keywords': ['aquatic', 'gills', 'marine'], 'habitat': 'water'}
選択されたedgesは[('habitat', 'habitat'), ('type', 'type')]となり、想定どおりです。
取得されたドキュメントは、ケース1で取得したものと、ケース2で取得したものの両方が含まれています。
ただし、どちらにも含まれていなかった 魚 (fish) も取得されました。なぜでしょうね。
説明文には 海 (marine) が含まれているし、類似度的に引っかかったんでしょうかね。
同じ生息地に関する回答は、 ロブスター (lobster) が追加されました。 ロブスター (lobster) は同じ種類のグラフ検索として取得したドキュメントのはずですが、説明文に 海 (marine) が含まれており類似度も高いので、回答に含められたのでしょうかね?
同じ種類に関する回答は、 蟹 (crab) が追加されました。
おい!他の動物を教えてくださいって言っただろ!!!
ちょっと微妙な結果ですが、OR条件なグラフベース検索自体は動作していそうです。
ちなみに、AND条件はできないっぽいです。(実装を見た限りは)
7. まとめ
LangChainのGraphRetrieverを使用したGraphRAG検索を試してみました。
メタデータを整備すれば、既存のベクトルストアにおいても適用できるのは素晴らしいと思います。
一方で、edgesの指定方法については結構混乱しました。というか今も完全には分かっていません(
へっぽこエンジニアが使用するには難度が高めだと思います。
きっと、さらに詳しいことは、素晴らしいエロい人が教えてくれると思います。
初記事がこんなんでいいのか・・・?
それでは。
ちぇけら
Discussion