はじめに
SolvioではRAGを利用したチャットボット構築の支援を多く行っています。RAGの活用方法は多岐にわたりますが、最も多いユースケースとして「社内 / 社外問い合わせに対するチャットボット」があげられます。
RAGを利用するチャットボットの場合ユーザーからの質問の自由度が高いことから、ルールベースの問い合わせチャットボットと異なり、RAGのインプットデータとして利用するデータが網羅できていないことなどから全ての質問に対して回答可能でない場合もあります。
これらの回答できない質問に対しては、保守運用のなかで担当者であるHumanが過去の履歴データをもとにRAGのインプットデータの拡充やメンテナンスを行うことが一般的です。
これらの背景のなかで、どのような手段を利用すれば、ドキュメントのメンテナンス自動的に行う仕組みを構築できるかを考えてみたいと思います。
前提条件
背景にある業務課題は上述したとおりです。利用しているサービスやクラウド環境、現行の仕組みの前提条件は以下である想定で考えてみたいと思います。
前提条件
- RAGの回答生成を行う仕組みとしてDifyを利用している
- クラウド環境はAWSを想定
- 問い合わせの担当者がRAGが生成した回答のレビューを行っており、RAGの回答が誤っていた場合は修正内容を送信する
- 修正内容はログファイルに記録されており、S3にて管理が行われている
- 想定されるデータのレイアウトは以下のようなレイアウトを想定します。
想定するログファイルのデータレイアウト
| 質問内容 | 担当部署 | RAG回答 | RAG回答正誤 | 正確な回答 | RAG更新済 |
|---|---|---|---|---|---|
| 社員カードを無くしました | 総務部 | 社員カードを紛失された場合は、速やかに総務部へご連絡ください。再発行の手続きや、必要な対応について案内を受けることができます。 また、社員カードには個人情報や入退室管理の機能が含まれている場合があるため、不正利用を防ぐためにも速やかに報告し、必要に応じてセキュリティ対策を講じることをおすすめします。 ご不明な点があれば、総務部のマニュアルやFAQを確認するか、直接お問い合わせください。 |
正解 | ||
| 経費の申請の方法に関して | 経理・財務部 | 経費の申請方法についてご案内します。経費申請は、経理・財務部のマニュアルに基づいて行われます。具体的には、申請者は必要な経費の詳細を記載し、証憑(領収書や請求書など)を添付のうえ、社内の経費申請システムまたは指定の申請書を使用して提出してください。承認フローや締め切りについては、財務管理・資金繰りのルールに従って処理されます。詳細は社内の経理・財務部マニュアルをご確認ください。 | 不正解 | 正確な経費申請の手続きとしては、最新の経費申請書を利用し、各経費項目(種類、発生理由、金額等)を明確に記入し、対応する領収書や請求書を必ず添付して提出する必要があります。申請後は、上長の承認と経理・財務部による最終確認が行われるため、申請状況の確認も重要です。 | |
| 経費の申請の仕方に関して | 経理・財務部 | 経費の申請方法についてご案内します。経費申請は、経理・財務部のマニュアルに基づいて行う必要があります。具体的には、社内の経費申請システムを使用し、必要な情報(経費の種類、金額、使用目的など)を入力し、領収書を添付して申請してください。詳細な手順については、社内の『経理・財務部マニュアル』をご参照ください。 | 不正解 | 正確な手続きは、社内経費申請システムにアクセスし、必須項目(経費の詳細、発生理由、金額など)を正確に記入し、証憑(領収書、請求書等)を添付して申請を完了させることです。申請後は、上長と経理担当者によるチェックを受け、必要に応じて追加の修正を行ってください。 | |
| 経費の申請の仕方に関して | 経理・財務部 | 経費の申請方法についてご案内します。経費申請は、経理・財務部のマニュアルに基づいて行われます。通常、申請者は経費申請フォームに必要事項を記入し、領収書などの証憑を添付して提出する必要があります。詳細な手順については、社内の経理・財務部マニュアルをご確認ください。 | 不正解 | 正確な経費申請手続きでは、専用の申請フォームに全ての必要情報(経費内容、金額、理由など)を詳細に記入し、関連する証憑を添付して提出します。提出後は、上長および経理・財務部による承認プロセスが開始されるため、進捗状況の確認とフォローアップが求められます。 | |
| 社員カードを無くしました | 総務部 | 社員カードを紛失された場合は、速やかに総務部へご連絡ください。再発行の手続きや、必要な対応について案内を受けることができます。また、社員カードには個人情報や入退室管理の機能が含まれている場合があるため、不正利用を防ぐためにも早急に報告することをおすすめします。もし、カードを紛失した場所に心当たりがある場合は、社内や立ち寄った場所を確認し、見つからない場合は総務部の指示に従ってください。 | 不正解 | 社員カードの紛失時には、まず直ちに総務部に連絡し、カードの利用停止と再発行の手続きを依頼してください。その際、紛失した状況や場所、時刻などの詳細な情報を整理して報告し、不正利用リスクを低減するための追加措置(関連システムの利用状況確認等)も実施する必要があります。 |
上記のように、RAGの回答の正誤判定は人の手によって行われており、誤った回答であった場合は正しい回答がHumanによって記載されてデータ保存されている前提で考えます。「RAG確認済」列はRAGにデータを付与するかの判定を行うために準備しました。この列がない場合、毎回全てのレコードを確認しないといけなくなるため処理が実施されたかのフラグとして利用します。(毎日実行する場合は過去24時間のみのレコードを判定するような仕組みでも良いかと思います。)
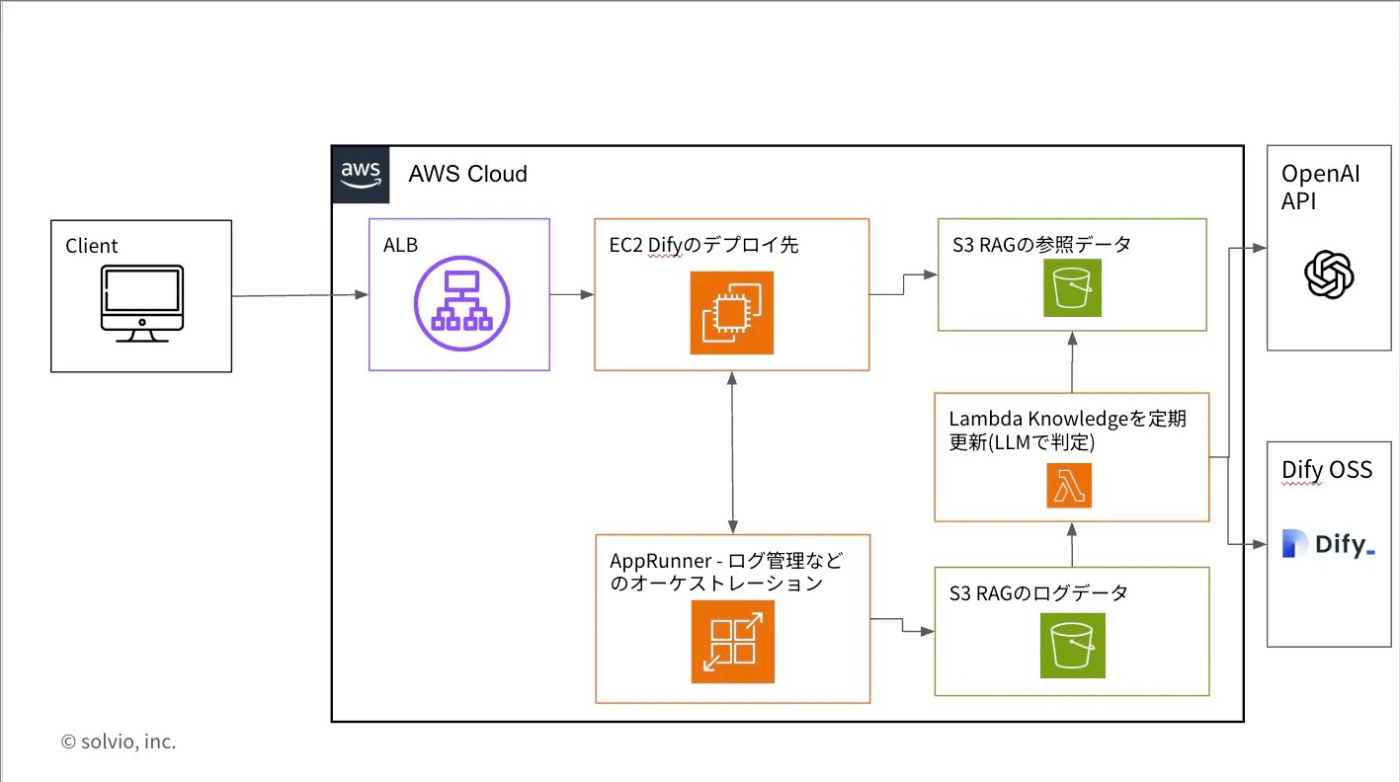
想定するアーキテクチャ
想定するアーキテクチャは以下の通りとなります。

想定する既存のRAGの参照データ
Difyのナレッジとして読み込まれているデータは以下のレイアウトを想定します。非常にシンプルなFAQデータのCSVです。これまでのご支援の中でもこのようなQA形式のデータを利用することが多かったため、こちらの利用を前提とします。
質問,回答
営業時間は何時から何時までですか?,当店の営業時間は9:00から18:00までです。
休日はいつですか?,休日は毎週日曜日と祝日です。
商品Aの価格はいくらですか?,商品Aの価格は1,000円です。
商品の返品は可能ですか?,未使用の場合、購入から7日以内であれば返品可能です。
オンライン注文はできますか?,はい、当社のウェブサイトからオンライン注文が可能です。
オンライン注文はできますか?クレジットカードで支払えますか?,はい、当社のウェブサイトからオンライン注文が可能で、主要なクレジットカードがご利用いただけます。
商品Aを購入したいのですが、送料と配送にかかる日数を教えてください。,送料は全国一律500円で、通常発送から2〜3営業日以内にお届けします。
店頭受け取りはできますか?また、支払いを現金で行うことは可能でしょうか?,はい、店頭受け取りも対応しており、現金払いも受け付けております。
商品Aの在庫を電話で確認後、ポイントプログラムを利用して購入できますか?,在庫状況はお電話で確認いただけ、購入ごとにポイントが貯まるプログラムをご用意しています。
修理サービスを依頼したいのですが、配送先の変更も可能でしょうか?,はい、修理サービスをご提供しており、発送前であれば配送先の変更も可能です。
RAGの参照データを自動更新するアプローチ
RAGの参照データに含まれるべき内容は、「想定するログファイル」に記載のある以下の条件に当てはまるものです。
参照データとして追加する条件
- RAGの回答正誤判定が誤りとして評価されている
- 現状、正しい回答ができていないため情報の更新が必要
- Humanによって、正確な回答が記載されている
- 正確な回答のみをRAGの参照情報として含めたい
上記のように更新情報として追加するべき情報の条件は明確となっているため、これらのレコードをもとにRAGの参照データとして含めれば要件を達成できそうです。
参照データをシンプルに追加するだけで課題は解決できるのか?
RAGの回答ログデータから「参照データとして追加する条件」に該当するレコード情報のみをRAGのインプットデータに追加すれば、理屈としては自動更新ができそうです。
ただ、実際の運用を考えると、以下のような課題が発生することが想定されます。
運用面で想定される課題
- Humanによって「正しい回答」が記載されたが、既に回答可能なRAGのインプットデータは存在している
- 利用者からの質問をもとに実施するRAGの検索が期待通り動作しなかっただけで、実はデータは存在しているためRAGの参照として追加するべきではない
- RAGによる回答の一部のみが誤っており、新たに質問と回答としてレコードを追加するのではなく部分的に情報が更新されるべき
- RAGの回答が完全な誤りではなく、部分的に誤りが発生している場合はデータの追加ではなく、更新されるべき
上記の2つの課題が主に想定されます。2の部分更新についての実現方法については、まだ明確な改善案が思い浮かんでいないため今後の宿題事項として、「1. Humanによって「正しい回答」が記載されたが、既に回答可能なRAGのインプットデータは存在している」場合の対策を考慮したうえで、自動更新の仕組みを構築したいと思います。
RAGの参照データを自動更新させる場合の処理の流れ
RAGの参照データを自動更新させる場合の流れは以下です。
INPUT:
- 既存のログファイル(上記の想定するログファイル)
- ログからは「参照データとして追加する条件」に一致するもののみを抽出する
- 既存のRAGの参照データをDifyのKnowledge-baseから取得する(上記の想定する既存のRAGの参照データ)
- このデータに対してレコードの追加を行う
PROCESS:
- 既存のログファイルから該当条件のレコードをLambda経由で取得
- 既存のRAGが参照しているデータの内容を確認し、情報の重複判定を行う
- 既に回答可能なRAGのインプットデータが存在しているかの判定を行う
- 情報が重複していない追加するべきデータを追記した新たなRAG参照CSVを作成する
- DifyのKnowledge-base APIを利用して情報の更新を行う
- バックアップを目的にS3にも最新化されたRAG参照のCSVファイルを配置する
OUTPUT:
- 最新化されたRAGの参照ファイルがDifyのKnowledgeとして登録される
- 最新化された各ファイルがS3に配置される
上記の流れで実現したいと思います。情報の重複判定がどの精度でできるかが大切になりそうです。
RAGのインプットデータに対する自動更新のタイミングはLambdaを定期実行することで更新を行う想定です。即時反映も仕組みとしては可能ですが、DifyのKnowledgeが更新された際には検索インデックスの再作成が必要となるためダウンタウンが発生します。運用を考えると夜間の定期実行が望ましいと思われるため以下の設計とします。
自動更新の仕組みを考慮した設計
仕様の検討:既に回答可能なRAGのインプットデータが存在しているかの判定を行う
更新対象として判断されるログファイルの情報は条件が明確であるためレコードをパースすることで対応が可能となりそうです。
ただ、「これらのレコードの情報が既存のRAGが参照するCSVファイルに含まれているか」の判定についてはいくつかのアプローチがあると考えました。
1. RAGの参照ファイルであるCSVの情報の全てと参照データに含めるべきかのレコードを1度のプロンプトで与えてLLMによって判定を行う
実施例

ChatGPTの画面から簡易的に検証を行ったところ判定自体は正しくできていそうでした。ただ、RAGのインプットとして利用されるCSVファイルのレコード数が増加していくと、いつかはToken limitを超えてしまう問題があります。さらに、判定を行うたびに全てのレコードを記載する必要があるため利用Token数が高くなってしまいお財布にも優しくありません。
この方針はシンプルではありますが、大規模なRAGを利用する際には現実的ではないのでDropします。
2. 既存のRAGが参照するインプットデータと類似度判定を行い、Top n 件との比較を行い判定する ★今回はコチラの仕様
RAGの参照データを全て含めて判定させることはデータ量の問題から厳しいため類似度判定を行い、その結果をもとにTop n件(今回は5件で検証)の既存データと判定させるようにします。今回はDifyのナレッジを利用しているため、チャンク情報が取得できるAPIから該当レコードの情報を取得してその内容を利用しようと思います。検証結果は以下のようになります。
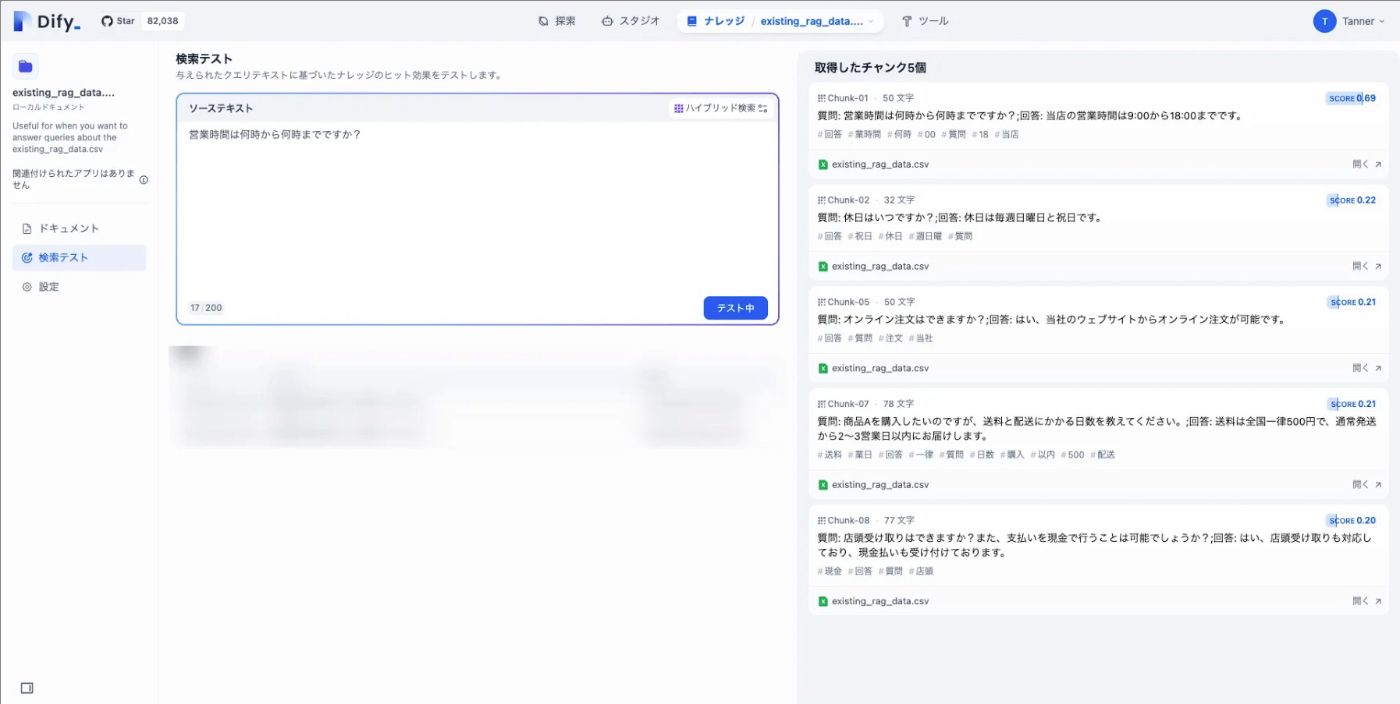
DifyのKnowledgeに対して検索を行ったところ関連情報がHitしていることが確認できました。特定のScore以上をしきい値とするような仕様も検討できますが、今回はよりシンプルに類似度のトップ5件を対象とする形で実装し、データの追加が必要であるかの類似度判定はLLMを利用して行います。
仕様が明確になってきたので、実装してみましょう!
Lambda関数を実装する
実装するにあたり仮想環境やパッケージ管理のツールとしてはuvを利用しています。主要なファイルを含めた全体の構成は以下のようになりました。tmp フォルダの役割としては、ファイルの更新を行う際に一時的に作成されるCSVの保存先として利用します。
.
├── README.md
├── tmp
├── app
│ ├── __init__.py
│ ├── main.py
│ ├── prompts
│ │ └── judge_data_update_to_rag.md
│ └── utils
│ ├── __init__.py
│ └── data_services.py
├── lambda_function.py
├── pyproject.toml
├── requirements.txt
└── uv.lock
4 directories, 10 files
それぞれの役割と実装内容について解説します。
lambda_function.py はLambdaのエントリーポイントです。このファイルがLambda経由で読み込まれ、 app/main.pyを呼び出します。ローカルでの動作確認を行うことを目的に、以下のように実装しました。
import json
from app.main import main
def lambda_handler(event, context):
try:
# プロジェクトのメイン処理を実行
result = main() # main() が処理の開始関数の場合
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json; charset=utf-8'
},
'body': json.dumps({'message': '処理が正常に完了しました', 'result': result}, ensure_ascii=False)
}
except Exception as e:
return {
'statusCode': 500,
'headers': {
'Content-Type': 'application/json; charset=utf-8'
},
'body': json.dumps({'message': '処理中にエラーが発生しました', 'error': str(e)}, ensure_ascii=False)
}
# スクリプトが直接実行された場合に実行される
if __name__ == "__main__":
# lambda_handler関数を呼び出し、結果を表示
result = lambda_handler(None, None)
print(json.dumps(result, ensure_ascii=False, indent=2))
続いて、主な処理を実施する /app/main.py の実装内容についてです。生成AIに指示を与えるためのプロンプトは prompts以下の特定ファイルの内容を読み取り、 create_dynamic_prompt_from_file の関数を利用して動的に作成を行います。 S3からのファイルの読み取りやアップデートなどデータ管理に関連する処理については、 utils/data_service.py のファイルに主な処理はまとめる形としました。Difyのエンドポイントなどの情報や、S3の情報については .env から環境変数として読み取りを行います。
import logging
import os
from typing import List
import pandas as pd
from dotenv import load_dotenv
from openai import OpenAI
from app.utils.data_services import (
get_existing_rag_data_from_dify_knowledge_base, load_csv_from_s3,
retrieve_chunks_from_knowledge_base, update_knowledge_document_with_file,
upload_csv_to_s3)
# ロガーの設定
logging.basicConfig(
level=logging.ERROR,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
)
logger = logging.getLogger(__name__)
# .env ファイルを読み込む
load_dotenv()
# 環境変数から設定を読み込む
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
DIFY_BASE_URL = os.getenv("DIFY_BASE_URL")
DIFY_API_KEY = os.getenv("DIFY_API_KEY")
DIFY_DATASET_ID = os.getenv("DIFY_DATASET_ID")
DIFY_DOCUMENT_ID = os.getenv("DIFY_DOCUMENT_ID")
S3_FEEDBACK_BUCKET_NAME = os.getenv("S3_FEEDBACK_BUCKET_NAME")
S3_FEEDBACK_FILE_NAME = os.getenv("S3_FEEDBACK_FILE_NAME")
S3_RAG_BUCKET_NAME = os.getenv("S3_RAG_BUCKET_NAME")
S3_RAG_FILE_NAME = os.getenv("S3_RAG_FILE_NAME")
GPT_MODEL_NAME = os.getenv("GPT_MODEL_NAME")
# 一時ファイルの保存先
TMP_DIR = os.getenv('TMP_DIR', '/tmp')
# 必須である環境変数が設定されているか確認
required_env_vars = [
"OPENAI_API_KEY", "DIFY_BASE_URL", "DIFY_API_KEY",
"DIFY_DATASET_ID", "DIFY_DOCUMENT_ID",
"S3_FEEDBACK_BUCKET_NAME", "S3_FEEDBACK_FILE_NAME",
"S3_RAG_BUCKET_NAME", "S3_RAG_FILE_NAME", "GPT_MODEL_NAME"
]
missing_vars = [var for var in required_env_vars if os.getenv(var) is None]
if missing_vars:
error_message = f"必要な環境変数が設定されていません: {', '.join(missing_vars)}"
logger.error(error_message)
raise ValueError(error_message)
client = OpenAI(
api_key=OPENAI_API_KEY
)
# ベースプロンプトファイルを読み込み、プレースホルダに埋め込む関数
def create_dynamic_prompt_from_file(base_prompt_path: str, existing_chunks: List[str], operation_log_qa: str) -> str:
"""
base_prompt_path: マークダウン形式のベースプロンプトファイルのパス
existing_chunks: 既存の問い合わせデータ(Top5など)
operation_log_qa: 新規問い合わせデータのログや利用履歴
戻り値: 埋め込み後の最終プロンプト文字列
"""
# ベースとなるプロンプトファイルを読み込み
with open(base_prompt_path, "r", encoding="utf-8") as f:
base_prompt = f.read()
# knowledge_base_target_chunks がリストの場合は連結
if isinstance(existing_chunks, list):
existing_data_str = "\n".join(existing_chunks)
else:
existing_data_str = str(existing_chunks)
operation_log_str = str(operation_log_qa)
# .format()を使ってプレースホルダに埋め込み
final_prompt = base_prompt.format(
existing_rag_chunks_top_5=existing_data_str,
operation_log_qa=operation_log_str
)
return final_prompt
# RAG改善用の参照データを抽出する関数
def extract_rag_reference_data_from_operation_feedback(df: pd.DataFrame) -> pd.DataFrame:
"""
RAG回答が不正解で、正確な回答が存在するデータを抽出し、
RAGシステム改善のための参照データセット(質問内容と正確な回答のみ)を作成する関数
Args:
df: 元のデータフレーム
Returns:
RAG参照用データフレーム(質問内容と正確な回答のみを含む)
"""
# 不正解かつ正確な回答が存在し、RAG更新済が1でない行のみをフィルタリング
# テストを目的に更新済みの条件分岐についてはコメントアウト
filtered_df = df[(df["RAG回答正誤"] == "不正解") & (df["正確な回答"].notna())
# & (df["RAG更新済"] != 1)
]
# 必要な列のみを選択
result_df = filtered_df[["質問内容", "正確な回答"]]
return result_df
def query_gpt_chat(model: str, developer_content: str, user_content: str) -> str:
# メッセージリストの準備
messages = [
{
"role": "developer",
"content": developer_content
},
{
"role": "user",
"content": user_content
}
]
# 推論の実行
response = client.responses.create(
model=model,
input=messages
)
return response.output_text
def main():
# operation_feed_back_dataのデータフレームを取得
operation_feed_back_df = load_csv_from_s3(S3_FEEDBACK_BUCKET_NAME, S3_FEEDBACK_FILE_NAME)
rag_reference_data_from_feedback_df = extract_rag_reference_data_from_operation_feedback(operation_feed_back_df)
# print(rag_reference_data_from_feedback_df)
dify_knowledge_download_path = os.path.join(TMP_DIR, "dify_knowledge_base_file.csv")
rag_feedback_log_path = os.path.join(TMP_DIR, "rag_feedback_log.csv")
# ナレッジベースから既存のRAGデータを取得
existing_rag_data_from_dify_knowledge_base = get_existing_rag_data_from_dify_knowledge_base(
base_url=DIFY_BASE_URL,
api_key=DIFY_API_KEY,
dataset_id=DIFY_DATASET_ID,
document_id=DIFY_DOCUMENT_ID,
download_path=dify_knowledge_download_path
)
dify_knowledge_base_file_df = pd.read_csv(dify_knowledge_download_path)
dify_knowledge_base_file_df.to_csv(dify_knowledge_download_path, index=False)
# ナレッジベース更新の必要性を追跡するフラグ
needs_knowledge_base_update = False
update_append_rows = []
for index, row in rag_reference_data_from_feedback_df.iterrows():
search_item = str(row["質問内容"]) + " " + str(row["正確な回答"])
# print(search_item)
knowledge_base_target_chunks = retrieve_chunks_from_knowledge_base(
base_url=DIFY_BASE_URL,
api_key=DIFY_API_KEY,
dataset_id=DIFY_DATASET_ID,
search_method="hybrid_search",
query=search_item,
top_k=5
)
judge_prompt = create_dynamic_prompt_from_file(
base_prompt_path="app/prompts/judge_data_update_to_rag.md",
existing_chunks=knowledge_base_target_chunks,
operation_log_qa=search_item
)
judge_result = query_gpt_chat(
model=GPT_MODEL_NAME,
developer_content=judge_prompt,
user_content="TrueかFalseかを返してください。"
)
# Trueの場合、レコードをCSVに追記する
if judge_result.strip() == "True":
# 更新フラグをTrueに設定
update_append_rows.append(row)
needs_knowledge_base_update = True
# 更新されたCSVファイルを使ってDifyのナレッジベースを更新
try:
# 少なくとも1つのTrueの判定があった場合のみ更新処理を実行
if needs_knowledge_base_update:
dify_knowledge_base_file_df = pd.read_csv(dify_knowledge_download_path)
update_append_df = pd.DataFrame(update_append_rows)
update_append_df.columns = ['質問', '回答']
updated_rag_df = pd.concat([dify_knowledge_base_file_df, update_append_df], ignore_index=True)
updated_rag_df_cleaned = updated_rag_df.drop_duplicates()
updated_rag_df_cleaned.to_csv(dify_knowledge_download_path, index=False)
# Difyナレッジベースを更新
update_result = update_knowledge_document_with_file(
base_url=DIFY_BASE_URL,
api_key=DIFY_API_KEY,
dataset_id=DIFY_DATASET_ID,
document_id=DIFY_DOCUMENT_ID,
file_path=dify_knowledge_download_path,
file_name="dify_knowledge_base_file.csv"
)
print("ナレッジベースの更新結果:", update_result)
operation_feed_back_df["RAG更新済"] = 1
operation_feed_back_df.to_csv(rag_feedback_log_path, index=False)
# S3バケット内のCSVファイルも更新
s3_update_knowledge_base_file = upload_csv_to_s3(
bucket_name=S3_RAG_BUCKET_NAME,
key=S3_RAG_FILE_NAME,
csv_file_path=dify_knowledge_download_path
)
# S3フィードバックファイルも更新
s3_update_operation_feed_back = upload_csv_to_s3(
bucket_name=S3_FEEDBACK_BUCKET_NAME,
key=S3_FEEDBACK_FILE_NAME,
csv_file_path=rag_feedback_log_path
)
if s3_update_knowledge_base_file and s3_update_operation_feed_back:
print("S3バケット内のCSVファイルが正常に更新されました。")
else:
print("S3バケット内のCSVファイルの更新に失敗しました。")
else:
print("Trueの判定が見つからなかったため、ナレッジベースの更新はスキップされました。")
# RAGの更新がなくても、確認済みフラグをたてたファイルをアップロード
operation_feed_back_df["RAG更新済"] = 1
operation_feed_back_df.to_csv(rag_feedback_log_path, index=False)
s3_update_operation_feed_back = upload_csv_to_s3(
bucket_name=S3_FEEDBACK_BUCKET_NAME,
key=S3_FEEDBACK_FILE_NAME,
csv_file_path=rag_feedback_log_path
)
if s3_update_operation_feed_back:
print("S3バケット内のフィードバックファイルが正常に更新されました。")
else:
print("S3バケット内のフィードバックファイルの更新に失敗しました。")
except Exception as e:
print(f"ナレッジベース更新中にエラーが発生しました: {e}")
環境変数を定義する .env の情報は以下のようになります。実際に利用される際には自身の情報に書き換えを行ってください。
# OpenAI API Key
OPENAI_API_KEY=your-openai-api-key
# Dify設定
DIFY_BASE_URL=https://example.com/v1
BASE_URL_DL=https://example.com/
DIFY_API_KEY=your-dify-api-key
DIFY_DATASET_ID=your-dataset-id
DIFY_DOCUMENT_ID=your-document-id
# S3バケット設定
S3_FEEDBACK_BUCKET_NAME=feedback-bucket-name
S3_FEEDBACK_FILE_NAME=feedback-file.csv
S3_RAG_BUCKET_NAME=rag-bucket-name
S3_RAG_FILE_NAME=rag-file.csv
# GPTモデル設定
GPT_MODEL_NAME=gpt-4o
プロンプトの内容は以下のようになります。今回は検証であるため簡易的な内容にとどめていますが、精度向上を行う場合はこの内容をプロンプトエンジニアリングする形になります。ただ、これまでの検証ではHumanの目で見ても違和感のない判定が行われていました。
あなたの役割は、問い合わせデータに追加すべき情報が存在するかどうかを判定することです。
以下の2つの情報を比較してください。
1. 既存の問い合わせデータ(ボットの参照データ)
{existing_rag_chunks_top_5}
2. 利用履歴の抜粋
{operation_log_qa}
利用履歴の抜粋にあるレコードのうち、既存の問い合わせデータに含まれていないものがひとつでもあれば「True」を返してください。
すべて既存の問い合わせデータに含まれていれば「False」を返してください。
**出力は「True」または「False」のみ**とし、理由や説明は不要です。
最後にS3とのやりとりやDifyとのやりとりを実施している utils/data_services.py の内容についてです。DifyのKnowledgeに関わるAPIとして、/upload-fileのエンドポイントと/retrieveのエンドポイントを利用しています。
/upload-fileの利用目的としては、最新化したCSVをアップロードするために利用しています。 /retrieveのエンドポイントは利用ログからRAGの参照ファイルに追記が必要であるか類似度判定するために既存のKnowledgeのチャンクを取得するために利用しています。詳細については公式ドキュメントをご確認ください。
import http.client as http_client
import json
import logging
import os
from io import StringIO
from pathlib import Path
from typing import Any, Dict, List, Optional
import boto3
import pandas as pd
import requests
from dotenv import load_dotenv
# 環境変数を読み込む
load_dotenv()
def get_existing_rag_data_from_dify_knowledge_base(base_url: str, api_key: str, dataset_id: str, document_id: str, download_path: str) -> str:
"""
base_url : Dify APIのベースURL (例: https://api.dify.ai/v1)
api_key : DifyにアクセスするためのAPIトークン
dataset_id : 取得対象のDataset(=Knowledge)のID
document_id : 取得対象のDocument ID
download_path: ダウンロードしたファイルを保存するパス(デフォルトはカレントディレクトリにdownloaded_fileとして保存)
"""
# 1. アップロードファイル情報を取得するエンドポイント
url = f"{base_url}/datasets/{dataset_id}/documents/{document_id}/upload-file"
# 2. GETリクエスト用ヘッダー作成
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# 3. ファイル情報を取得
response = requests.get(url, headers=headers)
# ステータスコードが200以外の場合は例外を投げる
if response.status_code != 200:
response.raise_for_status()
# 4. レスポンスからJSONをパースし、download_urlを取得
data = response.json()
# print(data)
base_url_dl = os.environ.get("BASE_URL_DL")
download_url = base_url_dl + data.get("download_url")
print(download_url)
if not download_url:
raise ValueError("download_url が取得できませんでした。")
# 5. ダウンロードURLからファイルを取得
file_response = requests.get(download_url, stream=True) # 大きいファイルを扱う場合はstream=True推奨
if file_response.status_code != 200:
file_response.raise_for_status()
# 6. ファイルを保存
with open(download_path, "wb") as f:
for chunk in file_response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
print(f"ファイルをダウンロードしました: {os.path.abspath(download_path)}")
# 必要に応じて、ファイルの中身をここで処理したり、関数の戻り値にしたりする
# 例: 関数としてはダウンロードしたファイルのローカルパスを返す
return os.path.abspath(download_path)
def load_csv_from_s3(bucket_name: str, key: str) -> pd.DataFrame:
"""
指定した S3 バケットから CSV ファイルを取得し、pandas DataFrame として返却する関数
:param bucket_name: バケット名
:param key: バケット内のオブジェクトキー (例: 'data/sample.csv')
:return: CSV を読み込んだ pandas DataFrame
"""
# 東京リージョン(ap-northeast-1)を指定して S3 クライアントを生成
s3_client = boto3.client('s3', region_name='ap-northeast-1')
# S3 からファイルを取得
response = s3_client.get_object(Bucket=bucket_name, Key=key)
# バイナリストリームを文字列に変換し、pandasで読み込み
body = response['Body'].read().decode('utf-8') # CSVのエンコーディングが異なる場合は適宜変更してください
df = pd.read_csv(StringIO(body))
return df
def upload_csv_to_s3(bucket_name: str, key: str, csv_file_path: str) -> bool:
"""
ローカルのCSVファイルをS3にアップロードして既存のファイルを更新する関数
:param bucket_name: バケット名
:param key: バケット内のオブジェクトキー (例: 'data/sample.csv')
:param csv_file_path: アップロードするCSVファイルのローカルパス
:return: アップロードが成功した場合はTrue、失敗した場合はFalse
"""
try:
# 東京リージョン(ap-northeast-1)を指定して S3 クライアントを生成
s3_client = boto3.client('s3', region_name='ap-northeast-1')
# ファイルをS3にアップロード
with open(csv_file_path, 'rb') as file:
s3_client.put_object(
Bucket=bucket_name,
Key=key,
Body=file,
ContentType='text/csv'
)
print(f"CSVファイル '{csv_file_path}' がS3バケット '{bucket_name}' の '{key}' に正常にアップロードされました。")
return True
except Exception as e:
print(f"S3へのアップロード中にエラーが発生しました: {e}")
return False
def retrieve_chunks_from_knowledge_base(base_url: str, api_key: str, dataset_id: str, query: str, search_method: str, top_k: int) -> List[str]:
"""
Knowledge Baseからチャンクを取得する関数。
引数:
base_url (str): APIのベースURL
api_key (str): API認証用のキー
dataset_id (str): Knowledge BaseのID
query (str): 検索クエリー
search_method (str): 検索方式(例: "keyword_search", "semantic_search", "full_text_search", "hybrid_search")
top_k (int): 取得する結果数
戻り値:
records以下の各segment["content"]を要素とするリスト(正常時)。
API呼び出し失敗時はNoneを返す。
"""
url = f"{base_url}/datasets/{dataset_id}/retrieve"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"query": query,
"retrieval_model": {
"search_method": search_method,
"reranking_enable": False,
"reranking_mode": None,
"reranking_model": {
"reranking_provider_name": "",
"reranking_model_name": ""
},
"weights": None,
"top_k": top_k,
"score_threshold_enabled": False,
"score_threshold": None
}
}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
# print("Knowledge chunks retrieved successfully.")
data = response.json()
# records 以下の segment.content を取り出してリストに格納する
if "records" in data and isinstance(data["records"], list):
contents = []
for record in data["records"]:
segment = record.get("segment")
if segment and "content" in segment:
contents.append(segment["content"])
return contents
# records が無い場合や空の場合は空リストを返すなど好きに扱う
return []
else:
print(f"Failed to retrieve knowledge chunks: {response.status_code} {response.text}")
return None
def update_knowledge_document_with_file(base_url: str, api_key: str, dataset_id: str, document_id: str, file_path: str, file_name: str, indexing_technique: str = "high_quality", process_rule: Optional[Dict[str, Any]] = None) -> None:
if process_rule is None:
process_rule = {
"rules": {
"pre_processing_rules": [
{"id": "remove_extra_spaces", "enabled": True},
# {"id": "remove_urls_emails", "enabled": True}
],
"segmentation": {
"separator": "¥n",
"max_tokens": 500
}
},
"mode": "custom"
}
url = f"{base_url}/datasets/{dataset_id}/documents/{document_id}/update-by-file"
config = {
"name": file_name,
"indexing_technique": indexing_technique,
"process_rule": process_rule
}
headers_for_file = {
"Authorization": f"Bearer {api_key}"
}
files = {
"data": (None, json.dumps(config), "text/plain"),
"file": (file_path, open(file_path, "rb"), "application/octet-stream")
}
try:
response = requests.post(url, headers=headers_for_file, files=files)
response.raise_for_status()
print(f"ドキュメント {document_id} のファイル更新に成功しました。")
return response.json()
except requests.exceptions.HTTPError as http_err:
print(f"HTTPエラーが発生しました: {http_err}")
print(f"ステータスコード: {response.status_code}, レスポンス内容: {response.text}")
except requests.exceptions.RequestException as req_err:
print(f"リクエストエラーが発生しました: {req_err}")
except Exception as err:
print(f"予期しないエラーが発生しました: {err}")
return None
上記の内容が主要な実装内容になります!ここまでの内容をローカルで実行すると期待通りの動作が確認できたため、LambdaへのDeployを行っていきます。
LambdaへのDeployを行う
LambdaへのDeploy方法としては、アップロードするためのZipファイルを作成し、そのファイルをマネジメントコンソール上からアップロードする形で行います。
Zipファイルを作成するためのコマンドは以下です。
# 利用しているパッケージを取り込む
uv pip install --python-platform x86_64-manylinux2014 --python 3.12 --target packages -r requirements.txt
# packagesフォルダへ移動
cd packages
# deployment_package.zipに利用しているパッケージを固める
zip -r ../deployment_package.zip .
# ルートへ移動
cd ..
# lambdaのエントリーポイントとなるファイルを追加
zip -g deployment_package.zip lambda_function.py
# app以下のファイルを固める
zip -r deployment_package.zip app
上記を実行すると必要な情報が含まれた deployment_package.zip が作成されます。このzipファイルをS3経由でLambdaへDeployを行えば問題なく動作することが確認できました。
実際に実行してDifyのKnowledgeが更新されるかを確かめる
ここまでの実装内容を実際に動かしてみましょう。まず、実行前のDifyのKnowledgeの内容は以下のようになります。「実行前のDifyのKnowledge」には10件のチャンクが登録されています。このKnowledgeに対して、ユーザーの利用ログから自動登録が可能であるかを試してみます。
実行前のDifyのKnowledge
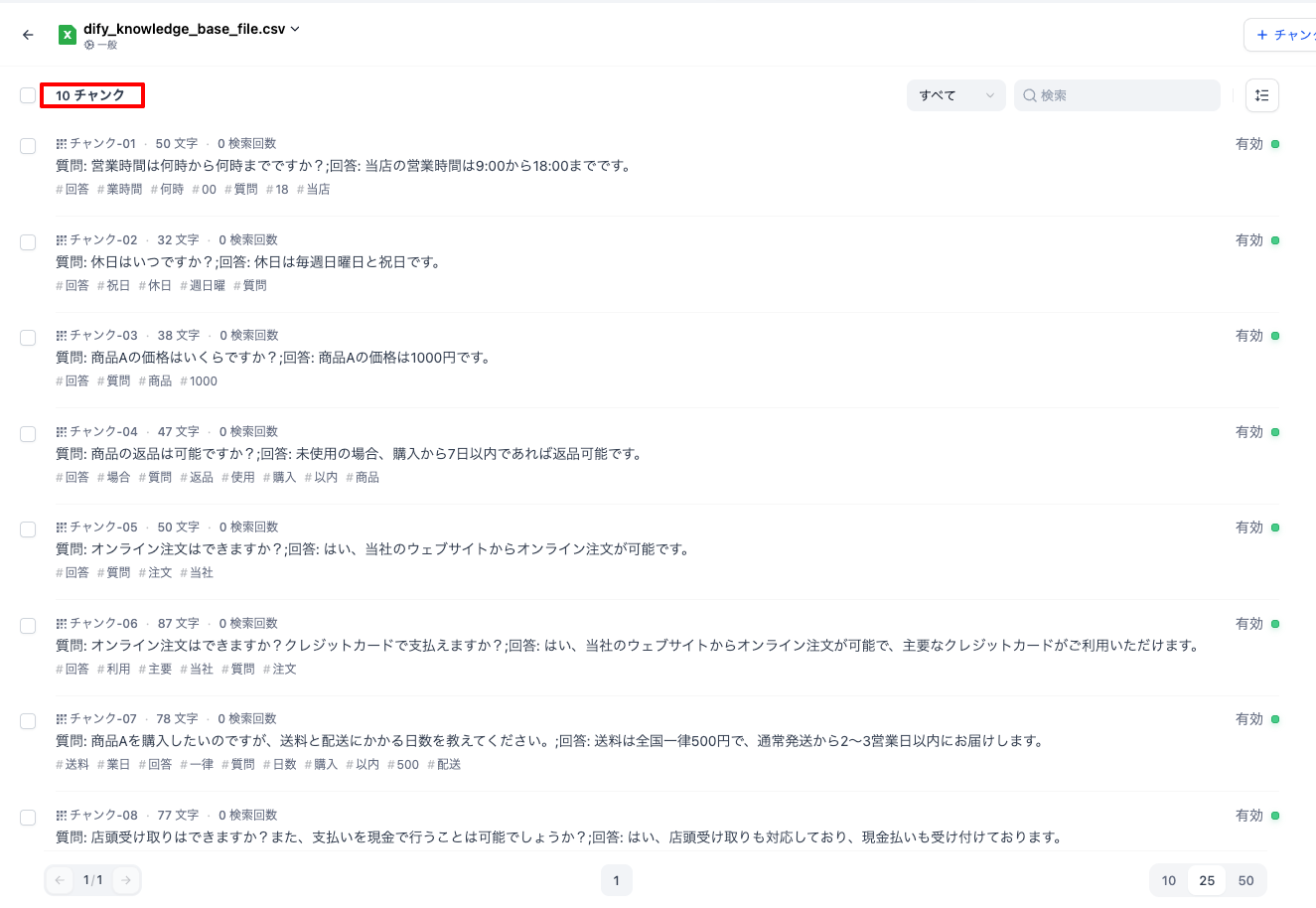
現在、10件のチャンクが存在するDifyのKnowledgeに対して、Lambdaのテスト実行を行います。
外部のAPIを利用していることもあり、Lambdaのデフォルトのタイムアウト(3秒)ではタイムアウトが発生します。そのため、Lambdaの設定からタイムアウトまでの時間を伸ばすようにしてください。(私は念の為5分に設定しています)

ログをみると成功していたため、Difyの対象となるナレッジを確認してみましょう。

上記のように更新対象であったチャンクが追加され、検索可能になることが確認できました。
これで、DifyのKnowledge-baseを自動更新することができました。
おわりに
RAGを利用したチャットボット構築の場合、データの修正や追加などHumanによる運用保守が必要となることが多いですが、今回の仕組みをうまく利用すれば運用コストを抑えたRAGの活用が可能になりそうです!
今回はDifyを前提に構築しましたが、同様の仕組みはAWS,Azure,Google Cloudを用いたRAG環境でも実現可能かと思います。今後の課題としては一部ソースコードにおいてBoolの取り扱いが文字列になっていることやその他可読性が低い部分については実運用に向けては改善する必要があります。追加で部分的な誤りがあるRAGの参照データをどのように取り扱えばよいかについても検討していきたいと思います。
RAGの運用を効率化したい方は是非、試してみてください!
最後に宣伝
Solvio株式会社は、生成AIを軸に企業の課題解決を行う会社です。これまでの支援の中でもHumanが行っていた業務を生成AIエージェントに置き換えて、業務効率を高めた事例もあります。少人数のチームであるためリソースに限りはありますが、生成AIを活用して業務改善を行いたい企業の方がいらっしゃればお気軽にご連絡いただけると幸いです!
お問い合わせページ:

Discussion