はじめに
Difyを用いたRAG構築って簡単にできるの知っていますでしょうか??
しかし、デフォルトのDifyのナレッジを用いる方向だと少しドキュメントの更新などがめんどくさい、、ということがあると思います。
そのため、今回Snowflake に溜めた文書を Cortex Search でベクトル検索し、Dify のチャットボットから一発で呼び出せるツールを作りましたので共有いたします。
この記事では、FastAPI → App Runner → Dify という最小構成でシステムを作る手順と、実際にハマったポイントをお伝えいたします。
なぜ Snowflake × Dify ?
- Snowflake には Cortex Search という埋め込み+類似検索の仕組みが標準搭載。
- Dify は OpenAIのAPIKey さえ渡せば、外部 API をノーコードで呼び出し可能。
- つまり両者を繋げれば「検索+生成」がほぼ設定だけで出来る
実際にやってみると、接続情報の受け渡し で少し躓いたので、そのあたりも詳しく触れていきます。
DifyのAWS環境へのホスティングの方法や、Snowflakeでのベクトルデータ作成なども記事書いておりますのでぜひご覧ください
システム全体像

Dify が FastsAPI を呼び出し、FastAPI が Snowflake で検索して結果を返す
事前準備
| 項目 | 用途 | メモ |
|---|---|---|
| Snowflake テーブル | ドキュメント埋め込みを保存 | |
| AWS アカウント | App Runner デプロイ | Cloud Run などでも OK |
| Dify ワークスペース | カスタムツール登録 | SaaS 版 / OSS どちらでも |
テーブル作成がまだの方 は、先に以下の記事を参考に埋め込みを生成してください。
Step 1. FastAPI で検索 API を作る
まずはローカルでサクッと動くところまで。
# main.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from snowflake.snowpark import Session
app = FastAPI()
class SearchBody(BaseModel):
query: str
top_k: int = 5
# Snowflake 接続情報(Dify から JSON で渡す想定)
snowflake_account: str
snowflake_user: str
snowflake_password: str
snowflake_role: str | None = None
snowflake_warehouse: str | None = None
snowflake_database: str | None = None
snowflake_schema: str | None = None
@app.post("/snowflake_rag_search")
async def rag_search(body: SearchBody):
"""ベクトル検索のメイン処理"""
try:
session = Session.builder.configs({
"account": body.snowflake_account,
"user": body.snowflake_user,
"password": body.snowflake_password,
"role": body.snowflake_role,
"warehouse": body.snowflake_warehouse,
"database": body.snowflake_database,
"schema": body.snowflake_schema,
}).create()
except Exception as e:
raise HTTPException(status_code=400, detail=f"Snowflake 接続失敗: {e}")
# 1) クエリをベクトル化
q_vec = session.sql(
"""SELECT BUILD_TEXT_EMBEDDING('snowflake-arctic-embed-m', %(q)s) AS vec""",
params={"q": body.query}
).collect()[0]["VEC"]
# 2) 類似検索
rows = session.sql(
"""
WITH q_vec AS (SELECT %(vec)s AS vec)
SELECT d.chunk_id AS doc_id,
d.original_doc_id AS title,
LEFT(d.content, 200) AS snippet,
VECTOR_COSINE_SIMILARITY(d.embedding, q_vec.vec) AS score
FROM DOCS_CHUNKS d, q_vec
ORDER BY score DESC
LIMIT %(k)s
""",
params={"vec": q_vec, "k": body.top_k}
).to_pandas()
return rows.to_dict("records")
@app.get("/health")
async def health():
return {"status": "ok"}
ポイント
- 接続情報を リクエストボディで受け取る と、Dify の環境変数に紐付けやすい。
BUILD_TEXT_EMBEDDINGのモデル名は環境に合わせて変更可。
Step 2. Docker 化 & App Runner へデプロイ
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]
docker build --platform linux/amd64 -t snowflake-rag-search .- ECR へ push → App Runner で Port 8080 /
/healthを指定 - 数分待てば公開 URL (
https://xxxx.awsapprunner.com) が発行されます
Cloud Run などでも大丈夫です!
Step 3. OpenAPI スキーマを用意
今回使用したスキーマ
{
"openapi": "3.1.0",
"info": {
"title": "Snowflake RAG Search API",
"description": "Snowflakeに保存されたドキュメントからセマンティック検索を実行します",
"version": "1.0.0"
},
"servers": [
{
"url": "https://pqynwejdmp.ap-northeast-1.awsapprunner.com"
}
],
"paths": {
"/snowflake_rag_search": {
"post": {
"summary": "RAG検索を実行",
"description": "Snowflakeからセマンティック検索を実行し、関連するドキュメントを返します",
"operationId": "snowflake_rag_search",
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "検索したい内容を自然言語で入力"
},
"top_k": {
"type": "integer",
"description": "返す結果の最大数",
"default": 5
},
"snowflake_account": {
"type": "string",
"description": "Snowflakeアカウント識別子"
},
"snowflake_user": {
"type": "string",
"description": "Snowflakeユーザー名"
},
"snowflake_password": {
"type": "string",
"description": "Snowflakeパスワード"
},
"snowflake_role": {
"type": "string",
"description": "Snowflakeロール"
},
"snowflake_warehouse": {
"type": "string",
"description": "Snowflakeウェアハウス"
},
"snowflake_database": {
"type": "string",
"description": "Snowflakeデータベース"
},
"snowflake_schema": {
"type": "string",
"description": "Snowflakeスキーマ"
}
},
"required": ["query"]
}
}
}
},
"responses": {
"200": {
"description": "検索結果",
"content": {
"application/json": {
"schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"doc_id": {
"type": "string",
"description": "ドキュメントID"
},
"title": {
"type": "string",
"description": "ドキュメントタイトル"
},
"snippet": {
"type": "string",
"description": "ドキュメント抜粋"
},
"score": {
"type": "number",
"description": "類似度スコア"
}
}
}
}
}
}
}
}
}
}
}
}
上記を使用する場合servers.url を自分のAppRunnerなどのURLに変更することを忘れずにお願いします!
Step 4. Dify にカスタムツールを登録
- 管理画面 → ツール → カスタムツールを作成 をクリック
-
tools.yamlを貼り付ける - パラメータを環境変数に紐付ける(例:
snowflake_account → {{#env.SNOW_ACCOUNT#}}) - 保存すると、下図のようにツールが追加されます
Step 5. ワークフローで呼び出す
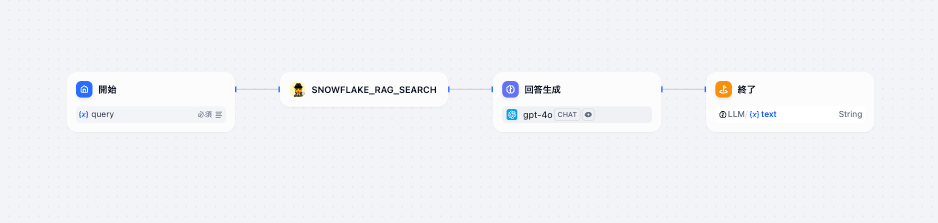
実行すると、検索結果が 回答生成 ノードのプロンプトに埋め込まれ、
OpenAIが社内ドキュメントを引用しながら回答してくれます。
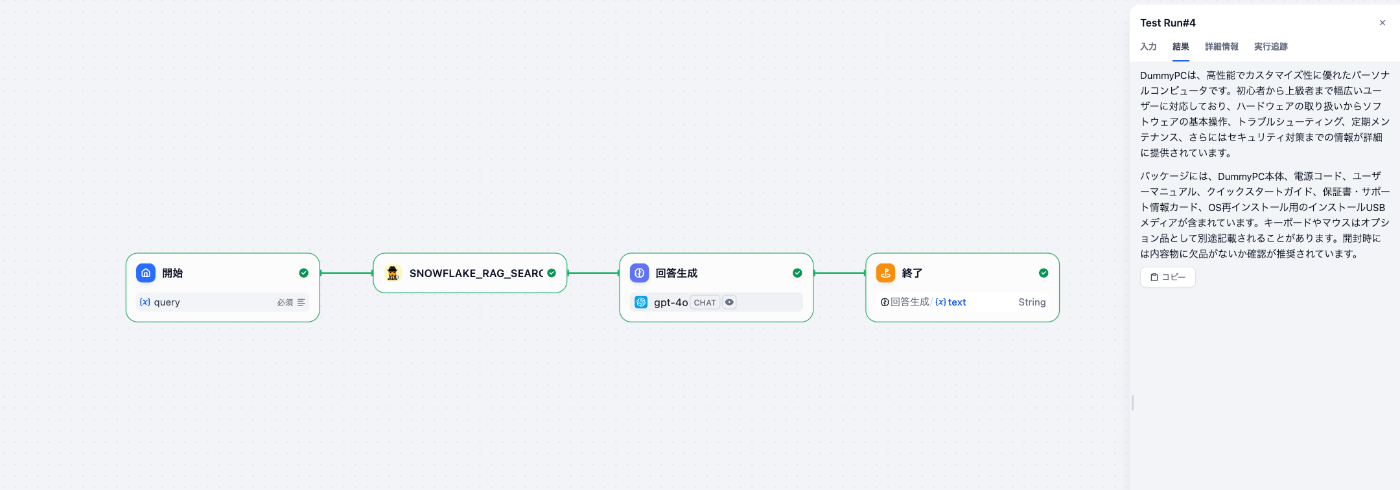

実際にsnowflakeから情報を取得して回答生成が行えていることが確認できました。
まとめ
- FastAPI で検索 API を実装
- Docker 化して App Runner へデプロイ
- OpenAPI を貼って Dify ツール化
- ワークフローに組み込めば、社内 Q&A ツールが完成
思ったより手数が少なく、"簡単に実装が行える" のが Snowflake × Dify の良さだと感じました。この記事が同じ悩みを持つ方の参考になれば幸いです!

Discussion