はじめに
業務や学習で使う膨大な量のPDFファイルから、内容の要約や必要な箇所のみの情報を確認したいときはありませんか?
今回はAzureが提供するDocument IntelligenceのOCR機能を使って、PDFから自動でテキストを抽出し、Difyのナレッジで活用できるようにしてみました。
背景と課題
企業やチームの中には、日々蓄積される大量の資料、たとえばマニュアル、レポート、提案書、議事録などがPDF形式で保管されています。
それらの多くは、画像ベースのスキャン資料や、構造を持たない単なる文章ファイルとして存在しており、検索性・活用性に大きな課題を抱えています。
また、AIチャットボットやRAGを導入しようとした際も、以下のような問題に直面することが少なくありません。
-
情報が分散していて探しづらい
→ 数百ページの資料を目視で探すのは非効率 -
属人化により“知っている人しか分からない状態
→ ナレッジが共有されておらず、質問も人頼みになる -
AIチャットに渡す形式に整っていない
→ ファイルはあるが、セクション分けや構造がなく、精度の高い回答が難しい
これらの課題を解決するには、
ステップ1 非構造なPDFを構造化・テキスト化(OCR)
ステップ2 Difyにナレッジとしてアップロードし、チャンク化でAIが読みやすい形に整形する
ステップ3 Difyのチャット画面を通して、ユーザーの質問の対して回答できるようにLLMのプロンプトを用意する
という3ステップの仕組みが必要です。
本記事ではこのアプローチを、Azure Document Intelligence(OCR) × Dify(ナレッジベース+チャットAI) を使って構築する方法をご紹介します。
実際にやってみる
ステップ1:PDFをOCRでテキスト化する
まずは、画像ベースのPDFからテキストを抽出します。
今回は以下の内容のPDFを使用いたします。
XYZ株式会社 就業基本規程
第1章 基本方針
第1条(目的)
本規程は、XYZ株式会社(以下「当社」という)における日常業務の円滑な運営と、社員が公正かつ安心して働ける職場環境を整備するための根本的な方針を定めることを目的とする。
第2条(対象)
この規程は、当社に雇用される全ての社員に適用されるものとする。
第2章 勤務に関する取り決め
第3条(所定労働時間)
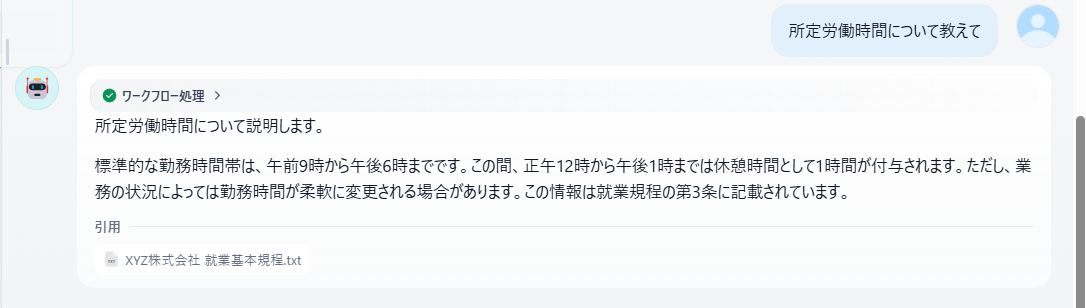
標準的な勤務時間帯は、午前9時より午後6時までの間とする。
正午12時から午後1時までは、休憩時間として1時間を付与する。
ただし、業務の状況により、勤務時間を柔軟に変更する場合がある。
第4条(休暇制度)
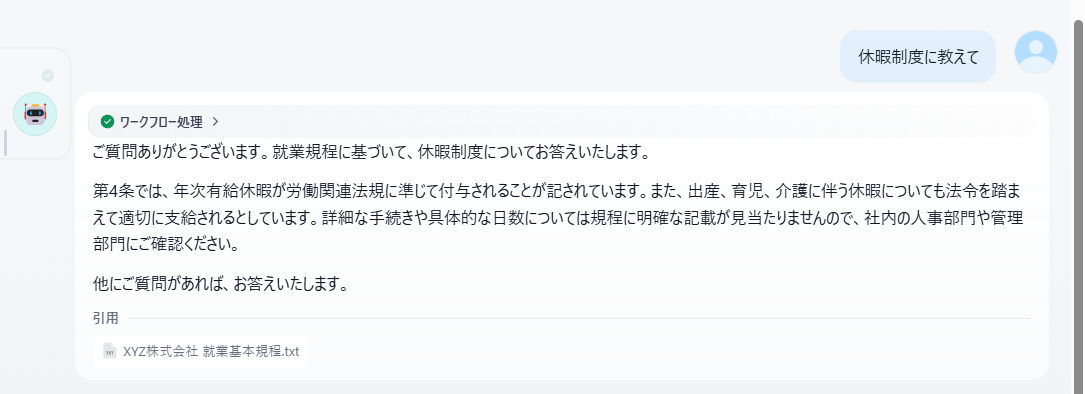
年次有給休暇は、労働関連法規に準じて付与される。
出産・育児・介護などに伴う休暇についても、法令を踏まえて適切に支給される。
第3章 職務の遂行
第5条(職務上の姿勢)
社員は担当業務に対し真摯な態度で取り組み、生産性と品質の両立を図ること。
社内資産および社外秘情報については、厳重に管理し、不適切な使用を一切行ってはならない。
第6条(報告と連絡)
業務に関わる重要な事項は、発見次第速やかに上長に伝達することを基本とする。
第4章 職場における配慮事項
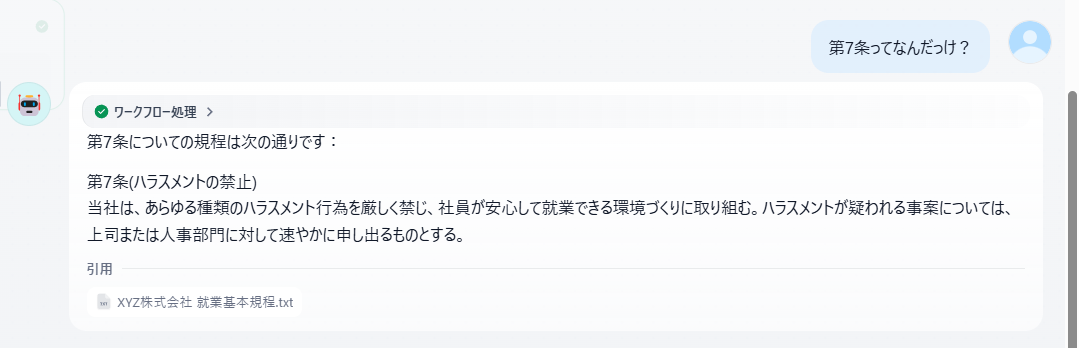
第7条(ハラスメントの禁止)
当社は、あらゆる種類のハラスメント行為を厳しく禁じ、社員が安心して就業できる環境づくりに取り組む。
ハラスメントが疑われる事案については、上司または人事部門に対して速やかに申し出るものとする。
第8条(安全および健康管理)
会社は、従業員が安全かつ健康的に業務に従事できる環境を確保するため、必要な措置を講じる。
社員は、社内の安全衛生に関するルールを遵守し、自身および他者の安全に配慮した行動をとること。
第5章 懲戒に関する事項
第9条(懲戒措置)
社員が本規程に反する行為を行った場合、当社は事実の内容に応じて懲戒処分を行う権利を有する。
処分の種類としては、口頭注意、減給処分、一定期間の就業停止、懲戒解雇などがある。
第6章 本規程の変更等
第10条(見直しおよび改訂)
この規程の改正または廃止は、必要性が認められた場合に、経営会議の承認を経て実施される。
付則
この規程は、2024年5月18日より施行する。
--------------------------------------------------------------------------------
この「就業基本規程」は、すべての社員が業務を円滑に行い、安心して働くための共通ルールです。
社員は本規程の内容をよく理解し、常にこれを意識した行動を心がけることが求められます。
ディレクトリ構成は以下のようにします。
ディレクトリ構成
project/
├── pdf/ # 入力PDF
├── ocr_merged_pdf/ # 出力テキスト
├── .env # APIキー設定
└── ocr_extract.py # OCRスクリプト
OCRでPDFからテキストを抽出するPythonスクリプト
Azure Document IntelligenceのOCR機能を使って、フォルダ内のPDFをすべてテキスト化し .txt に保存するスクリプトです。
import os
from pathlib import Path
from io import BytesIO
import fitz # PyMuPDF
from dotenv import load_dotenv
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.core.credentials import AzureKeyCredential
# 環境変数の読み込み(Azureのエンドポイントとキー)
load_dotenv()
client = DocumentIntelligenceClient(
endpoint=os.getenv("AZURE_DOC_INTELLIGENCE_ENDPOINT"),
credential=AzureKeyCredential(os.getenv("AZURE_DOC_INTELLIGENCE_KEY"))
)
# フォルダ指定
input_dir = Path("pdf")
output_dir = Path("ocr_merged_pdf")
output_dir.mkdir(exist_ok=True)
# ファイルごとにOCR処理
for pdf_path in input_dir.glob("*.pdf"):
doc = fitz.open(pdf_path)
all_text = ""
for i in range(len(doc)):
buf = BytesIO()
doc.extract_page(i).save(buf) # ページ単位でin-memory処理
buf.seek(0)
result = client.begin_analyze_document(
model_id="prebuilt-layout",
body=buf,
locale="ja-JP"
).result()
for line in result.pages[0].lines:
all_text += line.content + "\n"
with open(output_dir / f"{pdf_path.stem}.txt", "w", encoding="utf-8-sig") as f:
f.write(all_text)
print(f"✅ {pdf_path.name} → {output_dir/f'{pdf_path.stem}.txt'}")
コード解説
-
PyMuPDF (fitz)
- PDFをページ単位で操作
- 各ページを1ページずつ画像としてバイナリ化し、OCRに送信
-
Azure DocumentIntelligenceClient
- Azure OCRを使用して画像から文字を抽出
-
テキスト保存形式
- 出力時は
utf-8-sigエンコーディングを使用 - W文字化けを防止
- 出力時は
Difyのナレッジベースにアップロードする準備として
このコードを使えば、複数のPDFを一括でOCR→テキスト化→保存までシンプルに実現できます。
実際にテキスト化したのが、以下になります。
xYz 株式会社 就業基本規程
第 1章 基本方針
第1条(目的)
本規程は、xYz 株式会社(以下「当社」という)における日常業務の円滑な運営と、社員が公正
かつ安心して働ける職場環境を整備するための根本的な方針を定めることを目的とする。
第2条(対象)
この規程は、当社に雇用される全ての社員に適用されるものとする。
第2 章 勤務に関する取り決め
第3条(所定労働時間)
標準的な勤務時間帯は、午前 9 時より午後 6 時までの間とする。
正午 12 時から午後 1 時までは、休憩時間として 1時間を付与する。
ただし、業務の状況により、勤務時間を柔軟に変更する場合がある。
第4条(休暇制度)
年次有給休暇は、労働関連法規に準じて付与される。
出産·育児·介護などに伴う休暇についても、法令を踏まえて適切に支給される。
第 3 章 職務の遂行
第5条(職務上の姿勢)
社員は担当業務に対し真摯な態度で取り組み、生産性と品質の両立を図ること。
社内資産および社外秘情報については、厳重に管理し、不適切な使用を一切行ってはならない。
第6条(報告と連絡)
業務に関わる重要な事項は、発見次第速やかに上長に伝達することを基本とする。
第 4章 職場における配慮事項
第7条(ハラスメントの禁止)
当社は、あらゆる種類のハラスメント行為を厳しく禁じ、社員が安心して就業できる環境づくり
に取り組む。
ハラスメントが疑われる事案については、上司または人事部門に対して速やかに申し出るものと
する。
第8条(安全および健康管理)
会社は、従業員が安全かつ健康的に業務に従事できる環境を確保するため、必要な措置を講じ
る。
社員は、社内の安全衛生に関するルールを遵守し、自身および他者の安全に配慮した行動をとる
こと。
第5章 懲戒に関する事項
第9条(懲戒措置)
社員が本規程に反する行為を行った場合、当社は事実の内容に応じて懲戒処分を行う権利を有す
る。
処分の種類としては、口頭注意、減給処分、一定期間の就業停止、懲戒解雇などがある。
第 6章 本規程の変更等
第10条(見直しおよび改訂)
この規程の改正または廃止は、必要性が認められた場合に、経営会議の承認を経て実施される。
付則
この規程は、2024 年5月18日より施行する。
締めの言葉
この「就業基本規程」は、すべての社員が業務を円滑に行い、安心して働くための共通ルールで
す。
社員は本規程の内容をよく理解し、常にこれを意識した行動を心がけることが求められます。
ステップ2:Difyにナレッジとしてアップロードし、チャンク化でAIが読みやすい形に整形する。
ステップ1で出力したテキスト化したファイルをDifyのナレッジベース(Knowledge Base)にそのままアップロードし、チャンク化を行いAIチャットから質問できる情報源として活用できるようにさせます。
まず、Difyの「ナレッジ」を選択し、「ナレッジベースを作成」を押下します。
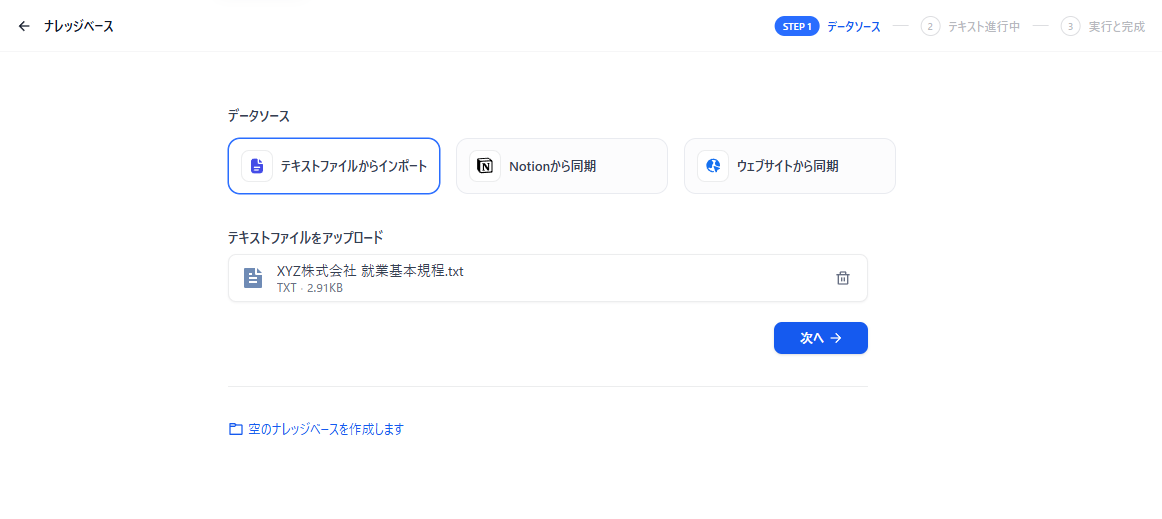
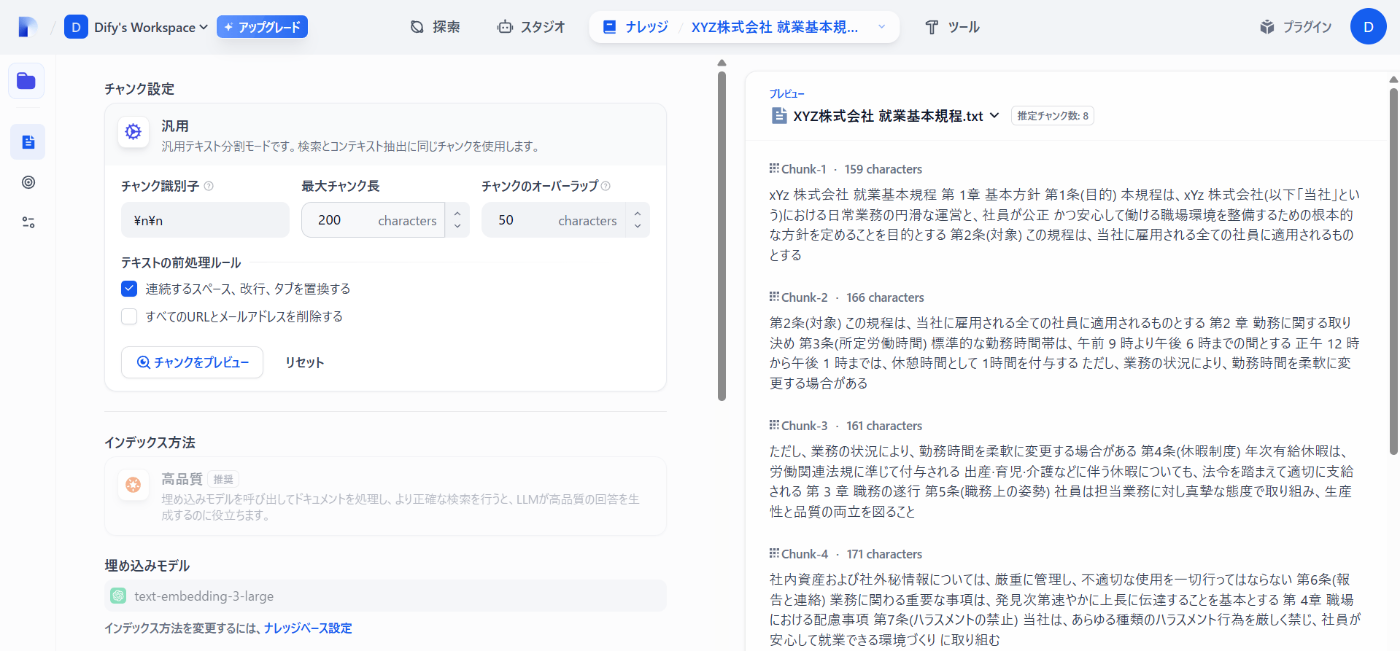
そして、先ほどテキスト化したファイルをアップロードします。
次にチャンク設定を行います。
ここの設定が回答の精度を高める上で非常に重要なステップになります。
まずはデフォルトの設定で一度「チャンクをプレビュー」を押下してみましょう。
以下のプレビュー結果が表示されます。
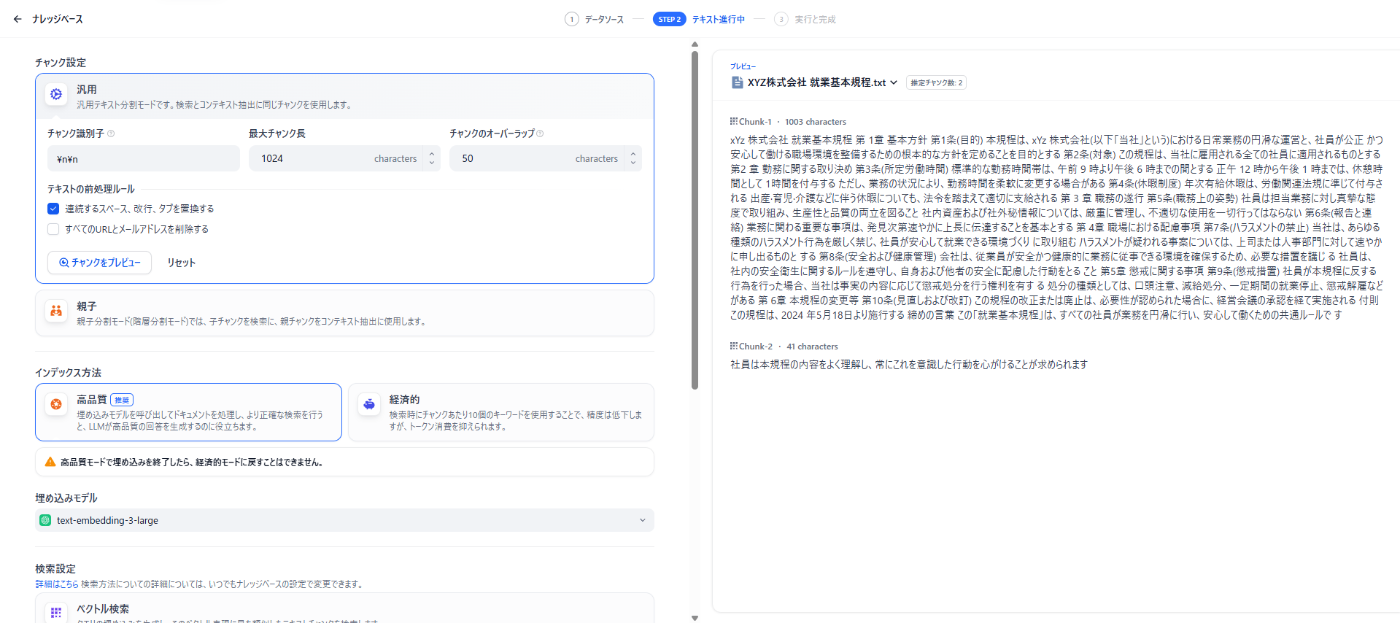
うまくチャンク化できていないため、Chank-1のテキストが非常に長い文になってしまっています。
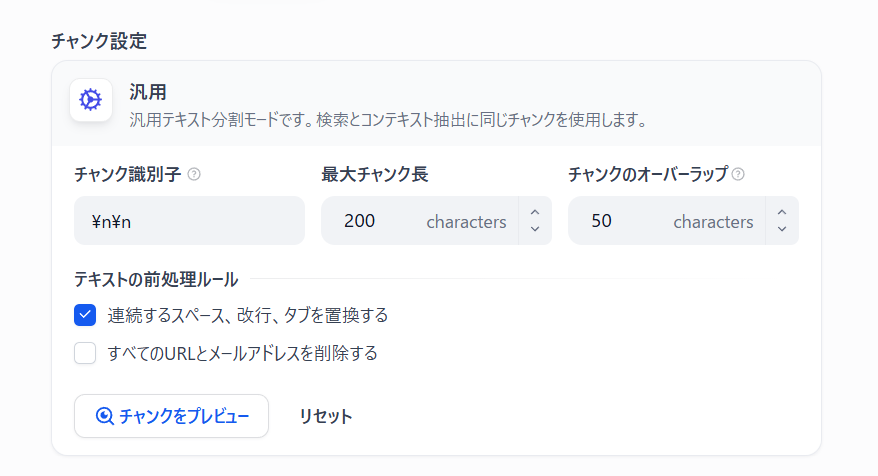
このままだとAIが質問に対して知識探索をした際に質問意図にそぐわない回答が返ってしまうため、以下の設定を行い、AIが読みやすい形に整えてあげましょう。
- 最大チャンク長→200
-
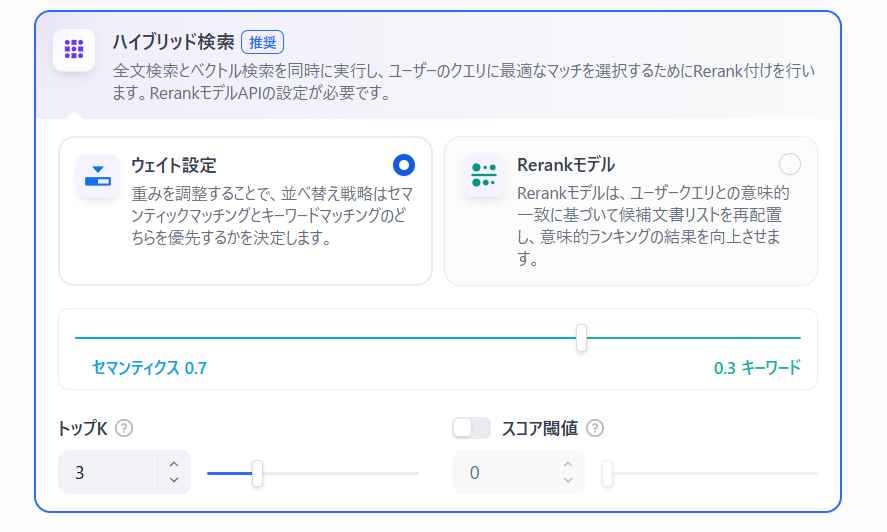
ベクトル検索→ハイブリッド検索
###チャンク識別子
テキストを「意味のかたまり(チャンク)」に分けるための**区切りルール。
\n\n(空行)で分けるため、段落ごとにチャンク化が可能。
###最大チャンク長
1つのチャンク(意味のまとまり)に含める文字数の上限のこと
長すぎると検索が遅くなり、短すぎると文脈が切れて精度が落ちる。
また、検索設定がデフォルトだと「ベクトル検索」に設定されていますが、
今回は「ハイブリッド検索」に設定しましょう。
-
ベクトル検索
- 文章の意味的な近さに基づいて検索を行う手法です。
AIが文章をベクトルと呼ばれる意味を考慮した数値の配列に変換し、
文章同士の関連度合を定量的に評価します。
- 文章の意味的な近さに基づいて検索を行う手法です。
-
全文検索
- 文章に含まれる単語を手がかりに検索する手法です。
-
ハイブリッド検索
- ベクトル検索と全文検索を組み合わせた検索方法です。
意味的な類似性と単語の一致の両方を考慮することで、正確な検索が可能になる。
- ベクトル検索と全文検索を組み合わせた検索方法です。
-
TopK
- 検索結果の上位何件のデータをAIに渡すかを決める設定
- 数が多いと情報が増えるが、不要な情報も混ざりやすくなる
-
スコア閾値
- 検索結果の関連度スコアがこの値未満なら無視される
- 高くしすぎると結果が出ない、低すぎると関係ない情報も出る
どうでしょうか??
デフォルトの設定に比べて、かなり意味のまとまりことにチャンク化ができてそうです。
これなら回答の精度も期待できそうです。
これでナレッジ化し、実際にAIに質問してみましょう!
ステップ3:Difyのチャット画面を通して、ユーザーの質問の対して回答できるようにLLMのプロンプトを用意する
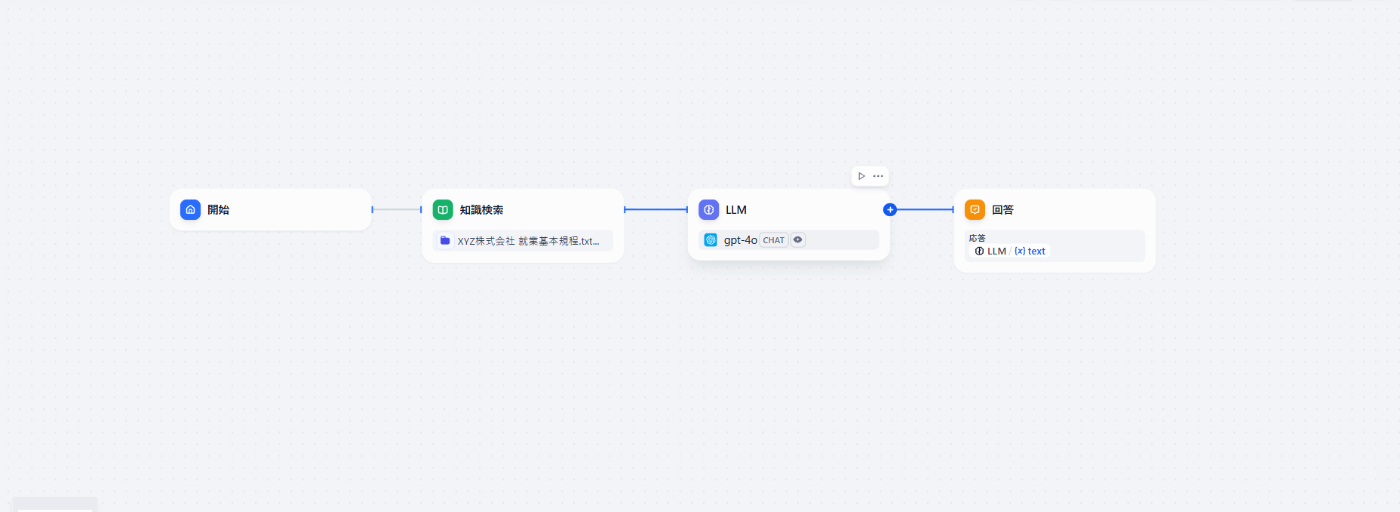
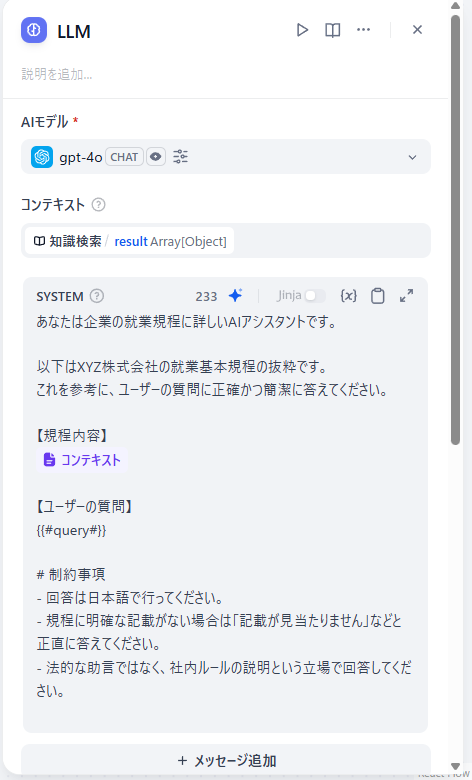
Difyの「チャットフロー」を作成し、以下のようにノードを配置していきます。
LLMのプロンプトとパラメータは以下のように設定します。
AIモデルには「gpt-4」を使用します。
あなたは就業規程に基づいて回答するアシスタントです。
以下の規程に基づき、{{#sys.query#}}に答えてください。
【規程】
{{#context#}}
# 制約事項
- 回答は日本語で行ってください。
- 規程に明確な記載がない場合は「記載が見当たりません」などと正直に答えてください。
- 法的な助言ではなく、社内ルールの説明という立場で回答してください。
検証
プレビューボタンを押下し質問していきます。
ここから実際の回答結果を紹介していきます。
今回質問したのは以下になります。
- 質問1:「休暇制度に教えて」
- 質問2:「第7条ってなんだっけ?」
- 質問3:「所定労働時間について教えて」
質問1:「休暇制度に教えて」
質問2:「第7条ってなんだっけ?」
質問3:「所定労働時間について教えて」
どうでしょうか!!!
質問に対してナレッジの内容を基に適切に回答できているのが確認できます。
おわりに
今回紹介した手法を使えば、これまで検索に時間をかけていた就業規程や社内マニュアル、技術資料などをナレッジベース化することによって、いつでも瞬時にRAG(検索拡張生成)を通してチャットできる情報へと生まれ変わりました。
これにより、業務中にたびたび発生していた、資料管理などといった検索時間を大幅に削減でき、社員一人ひとりが本来集中すべき業務できるようになるのではないでしょうか?
今後は、このナレッジベースをさらに発展させ、FAQ自動生成などにも取り込んでいきたいと思います!

Discussion