はじめに
いきなりですがコードのレビューをしてもらう・する際に、こんなことを思ったことありませんか?
- 「レビューに時間がかかりすぎる」
- 「コード規約を守っているかどうか、チェック漏れがある」
- 「レビュアーによって指摘がまちまち」
- 「ジュニアエンジニアが規約を覚えるための負担が大きい」
こうした問題を解決するために、今回はGitHub Actions × RAG (Retrieval Augmented Generation) を用いて、コードレビューを自動化する取り組みを行いました。
この記事では、実装内容や検証結果、そして今後の展望についてご紹介します。
背景と課題
コードレビューの現状
-
レビュー工数が大きい
大規模プロジェクトやレビュー頻度が多い現場では、レビュアーがロジックや設計だけでなく、命名規則やコメントの付与、不要なコードがないかなどを細かくチェックしなければなりません。 -
コード規約の徹底が難しい
リントツールではカバーしきれない細やかな規約や「こうするのがベスト」というベストプラクティスを常に意識するのは、レビュアーにとって負担です。 -
属人性や基準のブレ
レビュアーやチームメンバーによって指摘基準が異なり、「Aさんは指摘するけどBさんはスルー」といった状況が発生しがちです。 -
ジュニアエンジニアの育成コスト
新人や未経験エンジニアがコード規約・ベストプラクティスを身につけるためには、レビューのたびに指摘を受けるプロセスが必要ですが、指摘する側にかかる負担も小さくはありません。
解決したい問題
- レビュアーの工数を減らす
- 属人性の低減
- コード規約の網羅的かつ一貫した適用
- 本質的なロジックレビューへの集中
RAG(Retrieval Augmented Generation)とは?
RAGは、大規模言語モデル(LLM)があらかじめ学習していない情報を外部ドキュメントから取得し、回答を補強する手法です。具体的には以下の流れを指します。
-
検索・抽出 (Retrieval)
社内のドキュメント、コード規約、最新情報などを、検索エンジンやベクトルデータベースを用いて抽出します。 -
回答の補強 (Augmented Generation)
抽出したテキストをLLMの入力として追加し、通常のLLM応答に対して不足している部分を補います。 -
実践例
たとえば、社内で運用している独自のコードガイドラインやセキュリティルールを取り込み、LLMにその規約を踏まえたうえで指摘させることが可能になります。
GitHub Actions × RAGによるコードレビュー自動化の構築
全体フロー
- Pull Request作成/更新 → GitHub Actionsがトリガー
プルリクが新しく作られる、または更新されるたびに、ワークフローが自動的に実行されます。 - 差分(diff)の取得
Actions上でgit diff origin/main...HEADを実行し、変更箇所の差分テキストを取得します。 - RAGでコード規約を照合
LlamaIndexなどを用いて、あらかじめインデックス化してあるガイドラインやドキュメントから、今回の差分に関連する部分を抽出します。 - LLM (OpenAI)へのプロンプト送信
抽出したガイドラインと変更差分を組み合わせてプロンプトを生成し、コードレビューコメントを出力します。 - PRへのコメント投稿 & アクション自動適用
- 「Approve」
- 「Request Changes」
- 「Comment」
のいずれかに振り分け、PR画面上にコメントとして投稿します。

実装の紹介
以下に示すのは、GitHub ActionsでAIレビューを行うPythonスクリプトとワークフローの例です。
スクリプト例:run_ai_review.py
# coding: utf-8
import os
import json
import subprocess
from pathlib import Path
import requests
from openai import OpenAI
from llama_index.core import StorageContext, load_index_from_storage
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI as LlamaOpenAI
import re
PROJECT_ROOT = Path(__file__).resolve().parent.parent
PROMPT_TEMPLATE_PATH = PROJECT_ROOT / "prompts/code_review_prompt.md"
PROMPT_CLASSIFICATION_PATH = PROJECT_ROOT / "prompts/classification_prompt.md"
GUIDELINES_PATH = PROJECT_ROOT / "doc/code-guidelines.md"
INDEX_PATH = PROJECT_ROOT / "indexes"
def load_file(file_path):
try:
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
except FileNotFoundError:
print(f"File not found: {file_path}")
return None
def load_index():
try:
storage_context = StorageContext.from_defaults(persist_dir=str(INDEX_PATH))
index = load_index_from_storage(storage_context)
print("Index loaded successfully.")
return index
except Exception as e:
print(f"Error loading index: {e}")
return None
def split_diff_by_file(diff_text):
file_diffs = {}
lines = diff_text.splitlines()
current_file = None
current_lines = []
for line in lines:
if line.startswith("diff --git a/"):
if current_file and current_lines:
file_diffs[current_file] = "\n".join(current_lines)
match = re.match(r"^diff --git a/(.+?) b/(.+)$", line)
if match:
filename = match.group(1)
current_file = filename
current_lines = [line]
else:
current_file = None
current_lines = []
else:
if current_file is not None:
current_lines.append(line)
if current_file and current_lines:
file_diffs[current_file] = "\n".join(current_lines)
return file_diffs
def generate_review(client, prompt):
try:
review_response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a great code reviewer."},
{"role": "user", "content": prompt},
],
temperature=0.0,
max_tokens=800,
)
content = review_response.choices[0].message.content.strip()
return content
except Exception as e:
print(f"Error generating review: {e}")
return "Failed to generate review."
def determine_action(client, review_content):
try:
action_prompt = load_file(PROMPT_CLASSIFICATION_PATH).format(review_content=review_content)
action_response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a great code reviewer."},
{"role": "user", "content": action_prompt},
],
temperature=0.0,
max_tokens=100,
)
action_content = action_response.choices[0].message.content.strip()
return action_content
except Exception as e:
print(f"Error determining action: {e}")
return "Comment"
def main():
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
GITHUB_TOKEN = os.environ.get("GITHUB_TOKEN")
repo = os.environ.get("GITHUB_REPOSITORY")
event_path = os.environ.get("GITHUB_EVENT_PATH")
if not all([OPENAI_API_KEY, GITHUB_TOKEN, repo, event_path]):
print("Required environment variables are not set.")
return
client = OpenAI(api_key=OPENAI_API_KEY)
subprocess.run(["git", "fetch", "origin", "main"], check=True)
diff_result = subprocess.run(
["git", "diff", "origin/main...HEAD"], capture_output=True, text=True
)
diff_text = diff_result.stdout.strip()
if not diff_text:
print("No diff to review.")
return
file_diff_map = split_diff_by_file(diff_text)
if not file_diff_map:
print("No file-level diffs found.")
return
prompt_template = load_file(PROMPT_TEMPLATE_PATH)
if not prompt_template:
return
index = load_index()
if not index:
return
Settings.llm = LlamaOpenAI(api_key=OPENAI_API_KEY, temperature=0.0)
Settings.chunk_size = 1024
query_engine = index.as_query_engine()
file_reviews_map = {}
for filename, filediff in file_diff_map.items():
query = (
f"Below is the diff of file '{filename}'. "
"Please give me the relevant code guidelines in Japanese:\n"
f"{filediff}"
)
try:
response = query_engine.query(query)
retrieved_guidelines = str(response)
prompt = prompt_template.format(
diff_text=filediff,
code_guidelines=retrieved_guidelines
)
file_review = generate_review(client, prompt)
file_reviews_map[filename] = file_review
except Exception as e:
print(f"Error querying LlamaIndex: {e}")
file_reviews_map[filename] = "Failed to generate review."
review_content = "Nakamura Code Rabbit Review\n# Issues and Fix Suggestions\n"
for filename, review_text in file_reviews_map.items():
review_content += f"\n### {filename}\n{review_text}\n"
action = determine_action(client, review_content)
print(f"Action: {action}\nReview Content: {review_content}")
with open(event_path, "r", encoding="utf-8") as f:
payload = json.load(f)
if "pull_request" not in payload:
print("Not a pull_request event.")
return
pr_number = payload["pull_request"].get("number")
if not pr_number:
print("No PR number found.")
return
if action == "Comment":
post_comment_to_pr(repo, pr_number, review_content, GITHUB_TOKEN)
elif action == "Approve":
approve_pr(repo, pr_number, GITHUB_TOKEN)
post_comment_to_pr(repo, pr_number, review_content, GITHUB_TOKEN)
elif action == "Request changes":
request_changes_to_pr(repo, pr_number, review_content, GITHUB_TOKEN)
else:
post_comment_to_pr(repo, pr_number, review_content, GITHUB_TOKEN)
def post_comment_to_pr(repo, pr_number, body, token):
url = f"https://api.github.com/repos/{repo}/issues/{pr_number}/comments"
headers = {
"Authorization": f"token {token}",
"Accept": "application/vnd.github.v3+json",
}
data = {"body": body}
resp = requests.post(url, headers=headers, json=data)
if resp.status_code == 201:
print("Comment posted successfully.")
else:
print(f"Failed to post comment: {resp.status_code} - {resp.text}")
def approve_pr(repo, pr_number, token):
url = f"https://api.github.com/repos/{repo}/pulls/{pr_number}/reviews"
headers = {
"Authorization": f"token {token}",
"Accept": "application/vnd.github.v3+json",
}
data = {"event": "APPROVE"}
resp = requests.post(url, headers=headers, json=data)
if resp.status_code == 200:
print("PR approved successfully.")
else:
print(f"Failed to approve PR: {resp.status_code} - {resp.text}")
def request_changes_to_pr(repo, pr_number, body, token):
url = f"https://api.github.com/repos/{repo}/pulls/{pr_number}/reviews"
headers = {
"Authorization": f"token {token}",
"Accept": "application/vnd.github.v3+json",
}
data = {"body": body, "event": "REQUEST_CHANGES"}
resp = requests.post(url, headers=headers, json=data)
if resp.status_code == 200:
print("Request changes successfully.")
else:
print(f"Failed to request changes: {resp.status_code} - {resp.text}")
if __name__ == "__main__":
main()
ワークフロー例:.github/workflows/ai-review.yml
name: AI Review Reusable
on:
workflow_call:
secrets:
OPENAI_API_KEY:
required: true
permissions:
contents: write
pull-requests: write
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- name: Check out AI Review Script (Public repo)
uses: actions/checkout@v3
with:
repository: shonakamura000/ai-code-review
ref: feat-review-classification
path: ai_review_repo
- name: Check out caller repo
uses: actions/checkout@v3
with:
repository: ${{ github.repository }}
ref: ${{ github.event.pull_request.head.sha }}
path: caller
fetch-depth: 0
- name: Debug directory structure
run: |
echo "Listing directory structure..."
ls -R
echo "Done listing directory structure."
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: "3.9"
- name: Debug Secrets
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
echo "Debugging secrets..."
if [ -z "$OPENAI_API_KEY" ]; then
echo "Error: OPENAI_API_KEY was not passed."
exit 1
fi
echo "OPENAI_API_KEY is set."
if [ -z "$GITHUB_TOKEN" ]; then
echo "Error: GITHUB_TOKEN is not passed."
exit 1
fi
echo "GITHUB_TOKEN is set."
- name: Install dependencies
run: |
pip install openai requests llama-index
- name: Verify Python Packages
run: |
pip list
- name: Run AI Review
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
echo "Running AI Review script..."
cd caller
python ../ai_review_repo/src/scripts/run_ai_review.py
実際のレビュー
ここから実際のレビューを紹介していきます
今回レビュー対象にしたのは以下のプログラムです
- 5つのファイルでのコード変更があるプログラム
- 言語に関して、Pythonを利用してのコーディング
1. レビュー例(関数間に空白がなく、読みづらい)


実際にレビューを行なっていきました。
今回は、関数間に空行がなく読みづらくなっていた点を指摘されています。
そのためPRはRequested Changesを評価されています。
自分がたまに行なってしまうミスです。
2.レビュー例(機密情報のハードコーディング)
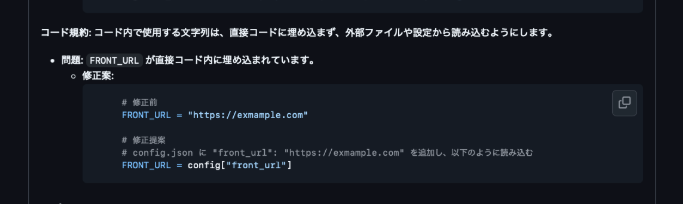
今回はURLなどの情報をハードコーディングしていたために指定されています。
どのようなコード規約を参照し、また、どのように改善すれば良いのかまで記述していることがわかると思います。
現状の評価(Good Points)
-
コスト感に関して
コストに関して、1PRに対して平均約五円程度のコストとなっておりました
(IN:4000、OUT:1000、TOTAL:5000 token)
こちらに関して、エンジニアが手動でやる時と比べて時間給換算すると大幅に削減できているのではないでしょうか?? -
時間に関して
時間に関して、平均1分前後にて処理を行うことができました。
こちらに関して、人間が行うとするとまずコードを読み、そこからレビューを作成する工程がかかってしまうのでそちらに比べて大幅に削減ができているのではないかと思います。
現状の評価(Negative Points)
-
変更点が多い時の挙動に関して
コードの変更量が多くなったときに全体を通したレビューができていないことがありました。
こちらに関しては、Diffごとにレビューを行い、最終的に統合したレビューをPRに対して投稿するといったような対応で改善していきたいと思います。 -
言語に対する精度に関して
Python以外の言語に対する精度が変わる可能性があることが考えられました。
今回使用したOpenAIのモデルでは特にPythonが得意と言われており、それ以外の言語ではどういった挙動をするか今回検証することができませんでした。
こちらに関して、追加で検証を行い問題があった場合には言語ごとにモデルを変更するなど対処していきたいと思っております。
今後の発展
-
自動修正PR:
AIが出した修正案にて自動PR提出まで行なってくれるようなコミュニティ専属のレビュアーのような動きができるようになるとさらに効率化が図れるのではないかと考えております。 -
教育用システムとしての方向
新卒・未経験エンジニア向けの「AIコードメンター」システム化を作成し、まだコーディングをあまりやったことない人向けのツールとしてのシステム化が図れるのではないかと考えました。
まとめ
AIによるコードレビューの導入は、人間が注力すべきロジックや設計面のレビューを効率化し、表層的なチェックを自動化する上で非常に有効でした。
これにより、エンジニアは高レイヤーな検証作業に時間を費やせるようになり、生産性を高めることが期待できます。ぜひ試してみてください!

Discussion