はじめに
生成AIを活用することができるローコード / ノーコードツールにはナレッジと呼ばれる機能があります。ナレッジを利用することで簡単に社内データなどを参照可能なRAGを構築することができます。このナレッジにはAPIが準備されており、RAGで利用するデータの更新をAPI経由などで実施することが可能です。API経由で更新が可能となることで、Lambdaの定期実行などを利用すると自動で参照データを更新することができます。
この記事では、 DifyのKnowledge-base APIを利用してDifyのナレッジ(RAG)に対する操作を試してみます。
前提条件
この記事の内容はDify公式が提供するAPIリファレンスをもとに作成しています。この記事の解説範囲は、実務で使うことが多いナレッジに対してのドキュメントの追加と更新に限るため、ナレッジの削除やチャンクの追加などその他の機能を利用したい場合は公式ページを参照してください。
Knowledge-base APIを利用して、ナレッジのデータを更新する
ナレッジを更新するための手順は2つのステップで実施可能です。
- 対象となるナレッジのIDを取得する。
- ナレッジの参照データを更新する。
1. 対象となるナレッジのIDを取得する。
まずは、更新対象となるナレッジのIDを取得します。IDを取得するためのエンドポイントとして、 /datasetsが用意されており、こちらを利用することでナレッジの一覧を取得することができます。Pythonでの実装例は以下の通りです。
import requests
# --- 設定 ---
API_KEY = "YOUR_API_KEY" # ご自身のAPIキーに置き換えてください
DEFAULT_DATASET_ID = "YOUR_DATASET_ID" # 更新対象のデータセットIDに置き換えてください
# SaaS番を利用している場合は、https://api.dify.ai/v1/ がBASE_URLとなります。
# セルフホスティングしている場合は、デプロイ先のURLを設定してください。
BASE_URL = "YOUR_BASE_URL"
HEADERS = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
def list_datasets(page=1, limit=20):
url = f"{BASE_URL}/datasets?page={page}&limit={limit}"
response = requests.get(url, headers=HEADERS)
if response.status_code == 200:
datasets_data = response.json().get("data", [])
if datasets_data:
print("知識ベース一覧:")
for ds in datasets_data:
dataset_id = ds.get("id")
name = ds.get("name")
print(f" Dataset ID: {dataset_id}, Name: {name}")
else:
print("知識ベースが見つかりませんでした。")
return datasets_data
else:
print(f"知識ベース一覧の取得に失敗しました: {response.status_code} {response.text}")
return []
上記を実行すると、以下のような結果が出力されます。
知識ベース一覧:
Dataset ID: 0765a15a-f970-44bf-8595-xxxxxxxxxxxx
Dataset Name: PCマニュアルのナレッジ
Dataset ID: c798558b-4570-4193-9814-xxxxxxxxxxxx
Dataset Name: 商品マスタCSV_ナレッジ
Dataset ID: 7d041b83-49bb-4cc3-82ae-xxxxxxxxxxxx
Dataset Name: 広報部のナレッジ
Dataset ID: 17cbb41b-26c3-447e-a396-xxxxxxxxxxxx
Dataset Name: 法務部のナレッジ
Dataset ID: ec39f88c-2383-46ef-9653-xxxxxxxxxxxx
Dataset Name: 経理部のナレッジ
Dataset ID: 5d8b9fd4-660b-4fd8-8ecc-xxxxxxxxxxxx
Dataset Name: 人事部のナレッジ
Dataset ID: 6d3b984e-f126-44ad-9990-xxxxxxxxxxxx
Dataset Name: 情報システム部のナレッジ
Dataset ID: 4dbacf09-e198-4eb4-aef0-xxxxxxxxxxxx
Dataset Name: 総務部のナレッジ
管理画面上から存在するナレッジを確認すると以下のようになります。
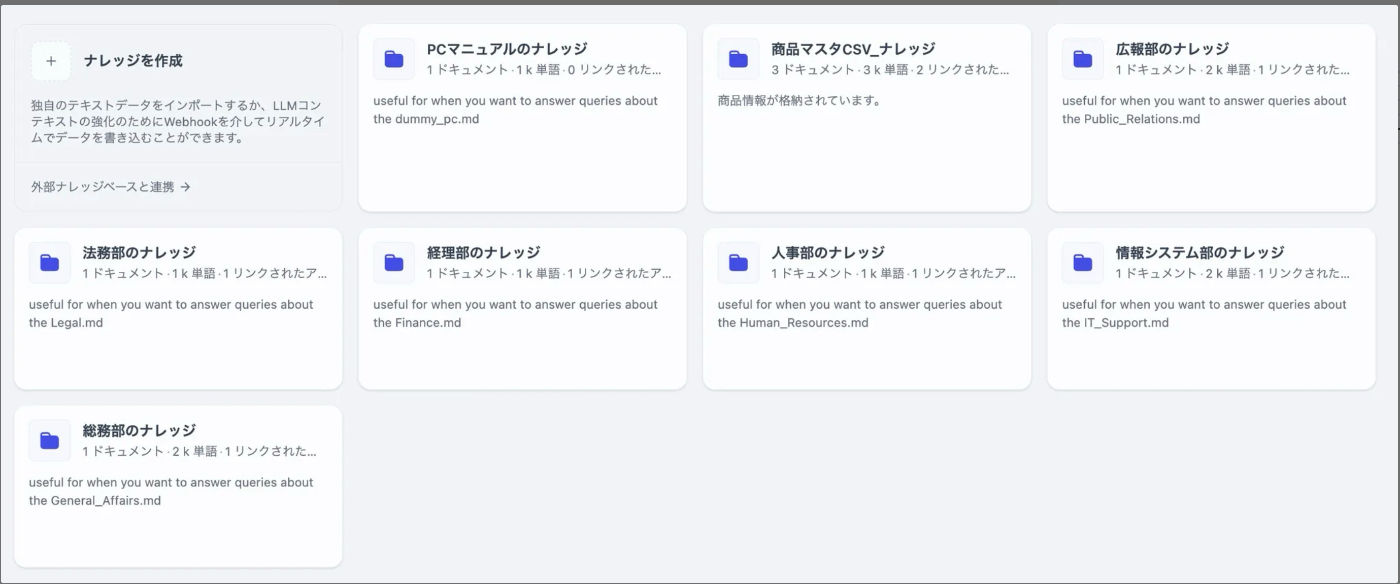
APIからの出力結果と一致していることが確認できます。
利用する際の注意点として、APIを経由して取得できるナレッジは、自身に対して参照可能な権限がついているナレッジと管理者が作成したナレッジのみとなります*1。
*1については、公式ドキュメントでは自分が作成したナレッジと自分に対して参照権限が付与されているナレッジのみが表示されると記載されていますが、2025/02/14時点では管理者が作成したナレッジと自分に対して参照権限が付与されているナレッジのみが表示されるようです。
このあたりは環境依存の可能性もあるため、ご自身の環境で挙動を確認された方が安心かと思います。
上記の手順で、対象となるナレッジのIDを取得することができました。次は、取得したIDを利用してナレッジの参照データを更新してみます。
2. ナレッジの参照データを更新する。
ナレッジの参照データを更新するためのエンドポイントとして、 /datasets/{dataset_id}/documentsが用意されており、こちらを利用することでナレッジの参照データを更新することができます。
既に存在するドキュメントの内容を更新したい場合は?
既にナレッジに存在しているデータを更新したい場合は、以下のようにリクエストを行うことで更新が可能です。ユースケースとしては、DifyのKnoeledge上に存在するFAQデータなどを定期更新する際などに利用する際に利用するようなイメージです。
■ナレッジのファイルを更新する関数
def update_document_with_file(dataset_id, document_id, file_path, file_name, indexing_technique="high_quality", process_rule=None):
if process_rule is None:
process_rule = {
"rules": {
"pre_processing_rules": [
{"id": "remove_extra_spaces", "enabled": True},
# {"id": "remove_urls_emails", "enabled": True}
],
"segmentation": {
"separator": "###",
"max_tokens": 500
}
},
"mode": "custom"
}
url = f"{BASE_URL}/datasets/{dataset_id}/documents/{document_id}/update-by-file"
config = {
"name": file_name,
"indexing_technique": indexing_technique,
"process_rule": process_rule
}
headers_for_file = {
"Authorization": f"Bearer {API_KEY}"
}
files = {
"data": (None, json.dumps(config), "text/plain"),
"file": (file_path, open(file_path, "rb"), "application/octet-stream")
}
response = requests.post(url, headers=headers_for_file, files=files)
if response.status_code == 200:
print(f"ドキュメント {document_id} のファイル更新に成功しました。")
return response.json()
else:
print(f"ドキュメント {document_id} のファイル更新に失敗しました: {response.status_code} {response.text}")
return None
document_idはAPI経由で確認することも可能ですが、URLからも確認することもできます。
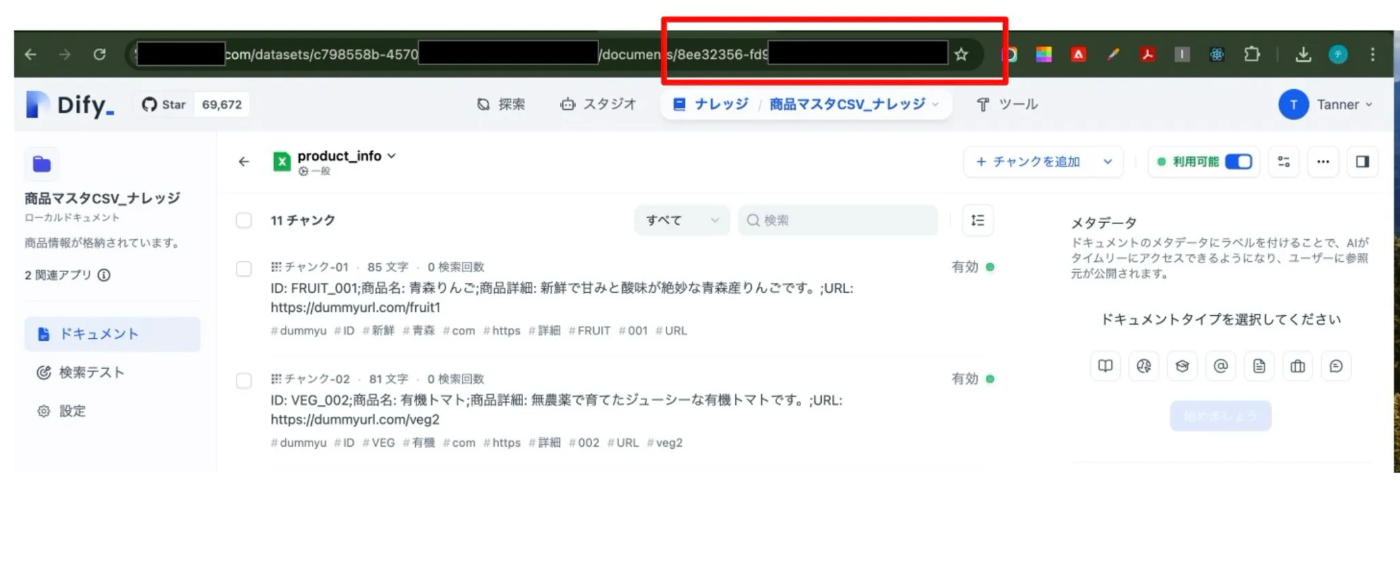
一部マスキングを行っていますが、ナレッジ以下のドキュメントページを開いた際の/documents 以下がドキュメントIDとなります。
関数の実行
def main():
# 対象のデータセットID(実際のIDに置き換えてください)
dataset_id = "YOUR_DATASET_ID"
file_path = "product_info.csv"
# 既存ドキュメントのファイルアップロードによる更新(CSVファイルなど)
# 対象のドキュメントIDを実際のIDに置き換えてください
document_id = "YOUR_DOCUMENT_ID"
result = update_document_with_file(
dataset_id=dataset_id,
document_id=document_id,
file_name="product_info",
file_path=file_path
)
print(result)
if __name__ == "__main__":
main()
成功すると以下のようにレスポンスが表示されます。
{'document': {'id': '8ee32356-fd90-460e-9480-xxxxxxxx', 'position': 2, 'data_source_type': 'upload_file', 'data_source_info': {'upload_file_id': 'cc71613c-aada-43c3-b6e1-xxxxxxxx'}, 'data_source_detail_dict': {'upload_file': {'id': 'cc71613c-aada-43c3-b6e1-xxxxxxxx', 'name': 'product_info.csv', 'size': 1295, 'extension': 'csv', 'mime_type': 'application/octet-stream', 'created_by': '23e3e618-52fc-4b8e-8653-xxxxxxxx', 'created_at': 1740030421.292328}}, 'dataset_process_rule_id': '5a4d452c-9803-4393-a5dd-xxxxxxxx', 'name': 'product_info', 'created_from': 'web', 'created_by': 'b5e50d5c-8bf5-4474-acb6-xxxxxxxx', 'created_at': 1739928235, 'tokens': 743, 'indexing_status': 'waiting', 'error': None, 'enabled': True, 'disabled_at': None, 'disabled_by': None, 'archived': False, 'display_status': 'queuing', 'word_count': 953, 'hit_count': 0, 'doc_form': 'text_model'}, 'batch': 'xxxxxxxx'}
ナレッジに対して新たなファイルを追加したい場合は?
ナレッジに対して新たなファイルを追加したい場合は、以下のようにリクエストを行うことで更新が可能です。
■ナレッジに新たなファイルを追加する関数
def add_document_with_file(dataset_id, file_path):
url = f"{BASE_URL}/datasets/{dataset_id}/document/create-by-file"
# 参考ドキュメントに合わせた設定情報
config = {
"indexing_technique": "high_quality",
"process_rule": {
"rules": {
"pre_processing_rules": [
{"id": "remove_extra_spaces", "enabled": True},
{"id": "remove_urls_emails", "enabled": True}
],
"segmentation": {
"separator": "###",
"max_tokens": 500
}
},
"mode": "custom"
}
}
# multipart/form-data 形式で、"data" に JSON文字列、"file" にファイルを指定
files = {
"data": (None, json.dumps(config), "text/plain"),
"file": (file_path, open(file_path, "rb"), "application/octet-stream")
}
headers_for_file = {
"Authorization": f"Bearer {API_KEY}"
}
response = requests.post(url, headers=headers_for_file, files=files)
if response.status_code == 200:
print("ドキュメントの追加に成功しました。")
return response.json()
else:
print(f"ドキュメントの追加に失敗しました: {response.status_code} {response.text}")
return None
関数の実行
def main():
dataset_id = "your_data_set_id"
file_path = "demo_file.csv"
result = add_document_with_file(DATASET_ID, file_path)
if result:
print("レスポンス内容:")
print(result)
if __name__ == "__main__":
main()
成功すると以下のようにレスポンスが表示されます
ドキュメントの追加に成功しました。
{'document': {'id': '988dcacb-b9d3-4916-bdb2-xxxxxxxx', 'position': 4, 'data_source_type': 'upload_file', 'data_source_info': {'upload_file_id': '0e786452-3456-46f2-8a7c-xxxxxx'}, 'data_source_detail_dict': {'upload_file': {'id': '0e786452-3456-46f2-xxxxxxxx', 'name': 'demo_file_2.csv', 'size': 1295, 'extension': 'csv', 'mime_type': 'application/octet-stream', 'created_by': '23e3e618-52fc-4b8e-8653-9a8b8030b16b', 'created_at': 1740025132.068692}}, 'dataset_process_rule_id': 'dd9ab987-2913-4b29-8404-c0dd8dc9019c', 'name': 'demo_file_2.csv', 'created_from': 'api', 'created_by': 'b5e50d5c-8bf5-44xxxxxxxxxxx', 'created_at': 1740025132, 'tokens': 0, 'indexing_status': 'splitting', 'error': None, 'enabled': True, 'disabled_at': None, 'disabled_by': None, 'archived': False, 'display_status': 'indexing', 'word_count': 863, 'hit_count': 0, 'doc_form': 'text_model'}, 'batch': '20250xxxxxxxxxxx'}
管理画面から確認すると、以下のようにドキュメントが追加されていることが確認できます。
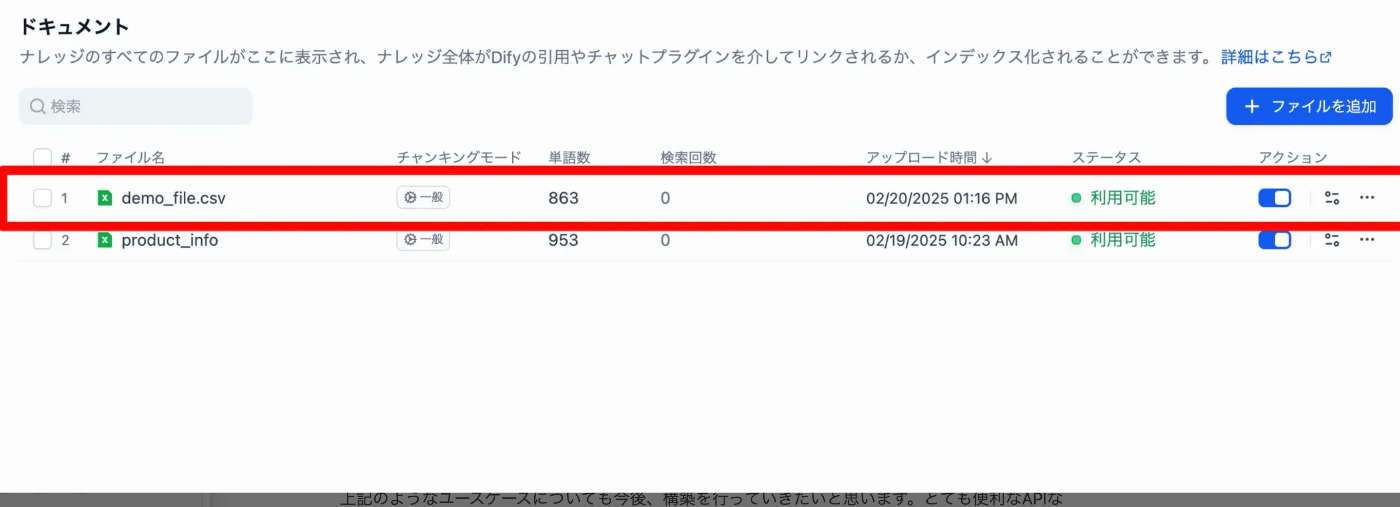
こちらでドキュメントの更新 / 追加は完了です。
まとめ
DifyのKnowlegebaseを管理することができるAPIの提供が開始されたことで、より利便性が高まりました。FAQデータなどを利用してRAGの体験を構築する場合、実運用を考えるとこれらの処理をLambdaなどから定期実行することになるかと思います。
上記のようなユースケースについても今後、構築を行っていきたいと思います。とても便利なAPIなのでDifyを使ってRAGを構築されている方は是非試してみてください!
最後に宣伝
Solvio株式会社は、生成AIを軸に企業の課題解決を行う会社です。これまでの支援の中でもHumanが行っていた業務を生成AIエージェントに置き換えて、業務効率を高めた事例もあります。少人数のチームであるためリソースに限りはありますが、生成AIを活用して業務改善を行いたい企業の方がいらっしゃればお気軽にご連絡いただけると幸いです!私が直接対応させていただきますw
お問い合わせページ:

Discussion