Pythonで手書き数字認識AI!?
🔢 【プログラミング初心者向け】Python Streamlit x TensorFlowで作る手書き数字認識AI
機械学習の代表的なタスクである画像認識に挑戦してみませんか?今回は、Python で TensorFlow を使って、手書き数字を認識するAIアプリを作成します。MNISTデータセットを使った本格的なディープラーニングアプリを、初心者でも理解できるように詳しく解説していきます。

ディープラーニング、画像処理、CNN(畳み込みニューラルネットワーク)まで含む本格的なAIアプリを、ステップバイステップで学んでいきましょう。
🌟 この記事を読めば...
ディープラーニングと画像認識の使い方を学べます 🎯
この記事では、単なる予測アプリを作るだけでなく、ディープラーニングの基本であるCNNと画像処理を徹底的に学べます。例えば:
- 画像データの前処理と正規化
- CNN(畳み込みニューラルネットワーク)の構築
- モデルの学習と保存
- リアルタイム画像認識
- 予測確率の可視化
今この時点では❓❓だとしても!記事を読み終えたときには、
ディープラーニングの概念が理解できてます!
💡 そもそもディープラーニングって❓
**ディープラーニング(Deep Learning)**は、人間の脳の仕組みを真似たAI技術です。
- 経験を積むことで能力が向上
- AIが自動的に特徴を学習
🎯 今回の例: - AIが「描かれた線のや形の特徴」を自動学習
📁 フォルダとファイルの作成
1. フォルダ構造
mnist-project/
├── mnist.py
└── requirements.txt
2. 必要なライブラリをインストール
まず、requirements.txtファイルに以下を書きます:
streamlit>=1.28.0
tensorflow>=2.13.0
numpy>=1.24.0
matplotlib>=3.7.0
Pillow>=10.0.0
streamlit-drawable-canvas>=0.9.0
plotly>=5.15.0
これで、プロジェクトの準備が整いました!
⚡ MNIST手書き数字認識AIを作ってみよう
さっそく、mnist.py にコードを書いていきましょう!
1️⃣📱 アプリの基本設定とライブラリのインポート
まずは、アプリの基本設定と必要なライブラリのインポートから始めます。
# 必要なライブラリをインポート
import streamlit as st # Webアプリ作成用
import tensorflow as tf # 機械学習・ディープラーニング用
import numpy as np # 数値計算用
import matplotlib.pyplot as plt # グラフ描画用
from PIL import Image # 画像処理用
from streamlit_drawable_canvas import st_canvas # 描画キャンバス用
import plotly.graph_objects as go # インタラクティブグラフ用
# ===== ページ設定 =====
st.set_page_config(
page_title="MNIST手書き数字認識", # ブラウザのタブに表示されるタイトル
page_icon="🔢", # ブラウザのタブに表示されるアイコン
layout="wide", # レイアウトをワイドに設定
)
# ===== タイトルとヘッダー =====
st.title("🔢 MNIST手書き数字認識デモ") # メインタイトル
st.markdown("---") # 区切り線
cursor のターミナルで以下のコマンドを実行して画面表示を確認しましょう!
py -3.11 -m streamlit run mnist.py
💡 今回はコマンドで py -3.11 のように Pythonのバージョンを明示的に指定しています。
これは、パソコンに複数のPythonバージョン(例:3.8, 3.9, 3.10, 3.11など)がインストールされている場合でも、
必ず「Python 3.11」でアプリを実行できるようにするためです。
バージョンを指定しないと、古いバージョンで動かしてしまい、ライブラリの互換性エラーが出ることがあります。
そのため、推奨バージョンで確実に動かすために -3.11 を付けています。

2️⃣🤖 モデルのキャッシュ・セッション管理
今回、モデルの学習には5000件のデータを使うため、毎回学習させるととても時間がかかってしまいます。。
そこで、Streamlitの「キャッシュ機能」と「セッション管理」を使うことで、
一度作成したモデルを保存して再利用し、無駄な再学習を防いでアプリを高速化しています。
# ===== モデル関連の関数 =====
@st.cache_resource # キャッシュデコレータ:モデルを一度だけ読み込む
def load_model(): # モデルを読み込む関数
# モデルを読み込み(キャッシュ付き)
try:
model = tf.keras.models.load_model('mnist_model.h5') # 保存されたモデルファイルを読み込む
st.success("✅ 事前学習済みモデルを読み込みました")
return model
except:
# モデルファイルが見つからない場合の処理
st.warning("⚠️ 事前学習済みモデルが見つかりません。新規作成します...")
return create_model()
@st.cache_resource # キャッシュデコレータ:モデル作成を一度だけ実行
def create_model(): # モデルを作成する関数
with st.spinner("🤖 モデルを学習中..."): # スピナー:処理中の表示
progress_bar = st.progress(0) # プログレスバーを作成(0%から開始)
status_text = st.empty() # 空のテキストエリアを作成(後で更新)
status_text.text("📊 MNISTデータセットを読み込み中...")
# tf.keras.datasets.mnist.load_data():MNISTデータセットを読み込み
# Return(戻り値):(学習データ, 学習ラベル), (テストデータ, テストラベル)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
progress_bar.progress(20) # プログレスバーを20%に更新
status_text.text("🔧 データを前処理中...")
# 画像データを4次元配列に変換し、0-1の範囲に正規化
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255.0
# tf.keras.utils.to_categorical():数字を箱に分ける
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
progress_bar.progress(40) # プログレスバーを40%に更新
# ===== モデル構築 =====
status_text.text("🏗️ モデルを構築中...")
# tf.keras.Sequential():層を順番に積み重ねるモデルを作成
model = tf.keras.Sequential([
# 第1層:畳み込み層(32個のフィルター、3x3のカーネルサイズ)
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
# 第2層:プーリング層(2x2のウィンドウで最大値を取得)
tf.keras.layers.MaxPooling2D((2, 2)),
# 第3層:畳み込み層(64個のフィルター、3x3のカーネルサイズ)
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
# 第4層:プーリング層(2x2のウィンドウで最大値を取得)
tf.keras.layers.MaxPooling2D((2, 2)),
# 第5層:平坦化層(2次元データを1次元に変換)
tf.keras.layers.Flatten(),
# 第6層:全結合層(128個のニューロン、ReLU活性化関数)
tf.keras.layers.Dense(128, activation='relu'),
# 第7層:ドロップアウト層(20%のニューロンを無効化して過学習を防ぐ)
tf.keras.layers.Dropout(0.2),
# 第8層:出力層(10個のニューロン、softmax活性化関数で確率分布を出力)
tf.keras.layers.Dense(10, activation='softmax')
])
# compile()メソッド:モデルの学習方法を設定
model.compile(optimizer='adam', # 学習の進め方を決める(今回はAdamを使用)
loss='categorical_crossentropy', # 予測と正解の差を計算する方法(今回はcategorical_crossentropy(分類問題用))
metrics=['accuracy']) # 学習成果の評価方法(今回はaccuracy(正解率)を使用)
progress_bar.progress(60) # プログレスバーを60%に更新
status_text.text("🎯 モデルを学習中...")
# fit()メソッド:モデルにデータを学習させる
model.fit(
x_train[:5000], y_train[:5000], # 学習データを5000件に制限(高速化のため)
batch_size=128, # 一度に処理するデータ数
epochs=3, # エポック数(学習回数)を3回に制限(高速化のため)
validation_data=(x_test[:1000], y_test[:1000]), # テストデータの最初の1000件を検証データとして使用(過学習の監視用)
verbose=0 # 学習中の進捗状況を表示しない(1または2にすることで表示可能)
)
progress_bar.progress(90) # プログレスバーを90%に更新
status_text.text("💾 モデルを保存中...")
# save()メソッド:学習済みモデルをファイルに保存
model.save('mnist_model.h5') # 「mnist_model.h5」というファイルに保存
progress_bar.progress(100) # プログレスバーを100%に更新
status_text.text("✅ モデル学習完了!")
st.success("🎉 モデルの準備が完了しました!")
return model
# ===== モデル読み込み =====
# st.session_state:ページを更新してもデータを保持するStreamlitの機能
# モデルを一度だけ読み込むための条件分岐
if 'model' not in st.session_state:
st.session_state.model = load_model()
📝 モデル管理・キャッシュの詳細説明:
-
@st.cache_resourceでモデルの再学習・再読み込みを防止し、アプリの高速化・安定化を実現します。 -
st.session_stateでページリロード時もモデルを保持し、無駄な再計算を防ぎます。 - モデルがなければ自動で新規学習し、以降は保存済みモデルを使い回します。
📝 関数の詳細説明:
- def:関数を定義するPythonのキーワード(defineの略)
- 関数は「def 関数名():」の形式で定義します。(今回は def load_model():)
- 関数を定義することで、同じ処理を何度も書く必要がなくなり、コードの再利用性が高まります。
- 関数の名前は目的や意図が明確になるようにしましょう!
- return:関数の処理結果を返すキーワード(例:return model)
- returnを使うことで、関数内で計算した結果を他の場所で使えるようになります。
📝 CNNモデル構造の詳細説明:
CNN(畳み込みニューラルネットワーク)は、画像認識に特化したディープラーニングモデルです。
🔍 CNNの基本構造:
-
畳み込み層(Conv2D):画像の特徴を抽出
- フィルター(カーネル)を使って画像のパターンを検出
- エッジ、角、テクスチャなどの特徴を学習
-
プーリング層(MaxPooling2D):情報を圧縮
- 画像サイズを小さくして計算量を削減
- 重要な特徴を残しながら次元を削減
-
平坦化層(Flatten):2次元→1次元変換
- 畳み込み層の出力を全結合層用に変換
-
全結合層(Dense):最終的な分類
- 抽出された特徴を使って数字を分類
- 最後の層で0-9の確率を出力
🎯 今回のモデル構造:
- 入力:28×28×1(グレースケール画像)
- 畳み込み層×2 + プーリング層×2
- 全結合層×2(128ユニット + 10ユニット)
- 出力:10クラス(数字0-9の確率)
💡 CNNの利点:
- 画像の位置やサイズの変化に強い
- 自動的に特徴を学習
- 手書き数字認識に最適
❓ なぜ畳み込み層が2つ必要なのか
畳み込み層を複数重ねることで、より高度な特徴を学習できます:
🔍 第1層(32フィルター):
- 基本的な特徴を検出
- エッジ、線、角などの単純なパターン
- 例:数字の縦線、横線、斜め線
🔍 第2層(64フィルター):
- 第1層の出力を組み合わせて複雑な特徴を検出
- より抽象的なパターンを学習
- 例:数字の輪郭、曲線、複雑な形状
🎯 具体例:
- 1層だけ:基本的な線は検出できるが、複雑な数字の形状は認識困難
- 2層:基本的な線を組み合わせて、数字全体の形状を認識可能
👀 人間の目と同じ仕組み!
人間が数字を見るとき:
- まず「線」や「曲がり」に気づく
- それを組み合わせて「形」として理解する
- 最終的に「これは8だ!」と判断する
CNNも同じです!
💡 CNNモデル構造をわかりやすく図解化


📝 モデル作成・学習処理の詳細説明:
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255.0
引数の意味:
-
-1:データの数を自動計算(バッチサイズ) -
28, 28:画像の縦横サイズ(28x28ピクセル) -
1:チャンネル数(グレースケール画像なので1) -
astype('float32'):32ビット浮動小数点に変換 -
/ 255.0:0-1の範囲に正規化(元は0-255)
例:
- 入力:x_train[0] = [
[0, 255, 128, ...], # 1行目(28個の数字)
[255, 0, 255, ...], # 2行目(28個の数字)
... # 28行分ある
] - 出力:x_train[0] = [
[0.0, 1.0, 0.5, ...], # 1行目(255で割って0-1に)
[1.0, 0.0, 1.0, ...], # 2行目(255で割って0-1に)
... # 28行分ある
]
❓ 正規化って?
- データを一定の範囲(今回は0-1)に収める処理
- 正規化しないと、以下のような問題が起きます:
- 学習が不安定になる(大きな数値による計算エラー)
- 処理が遅くなる(大きな数値の計算は重い)
- 精度が下がる(数値の範囲がバラバラで比較が難しい)
`tf.keras.utils.to_categorical(y_train, 10)`
引数(カッコの中身)の意味:
- 第1引数:y_train → 変換したい数字の配列(例:[5, 2, 8, 1, ...])
- 第2引数:10 → 箱の数(0-9の10個の数字なので10)
例: - 入力:y_train = [5, 2, 8]
- 出力:
5 → [0,0,0,0,0,1,0,0,0,0] # 6番目の箱(インデックス5)に1
2 → [0,0,1,0,0,0,0,0,0,0] # 3番目の箱(インデックス2)に1
これで一番難しい箇所が出来上がりました!!
あと少しです!!
3️⃣🎨 描画キャンバスの実装
ユーザーが数字を描けるキャンバスを実装します。
# st.columns():画面を複数のカラムに分割
col1, col2 = st.columns([1, 1]) # 1:1の比率で2つのカラムを作成
with col1:
st.header("✏️ 数字を描いてください") # 左カラムのヘッダー
# ===== 描画設定 =====
stroke_width = 15 # 線の太さ(ピクセル単位)
stroke_color = "#000000" # 線の色をカラーコードで指定(今回は黒)
# ===== 描画キャンバス =====
canvas_result = st_canvas(
fill_color="rgba(255, 255, 255, 0.0)", # 透明な塗りつぶし
stroke_width=stroke_width, # 線の太さ
stroke_color=stroke_color, # 線の色
background_color="#FFFFFF", # 背景色(白)
background_image=None, # 背景画像なし
update_streamlit=True, # 描画時にStreamlitを更新
height=400, # キャンバスの高さ
width=400, # キャンバスの幅
drawing_mode="freedraw", # 描画モード
point_display_radius=0, # ポイント表示半径
key="canvas", # キャンバスの一意識別子
)
実際に数字を描いてみましょう!
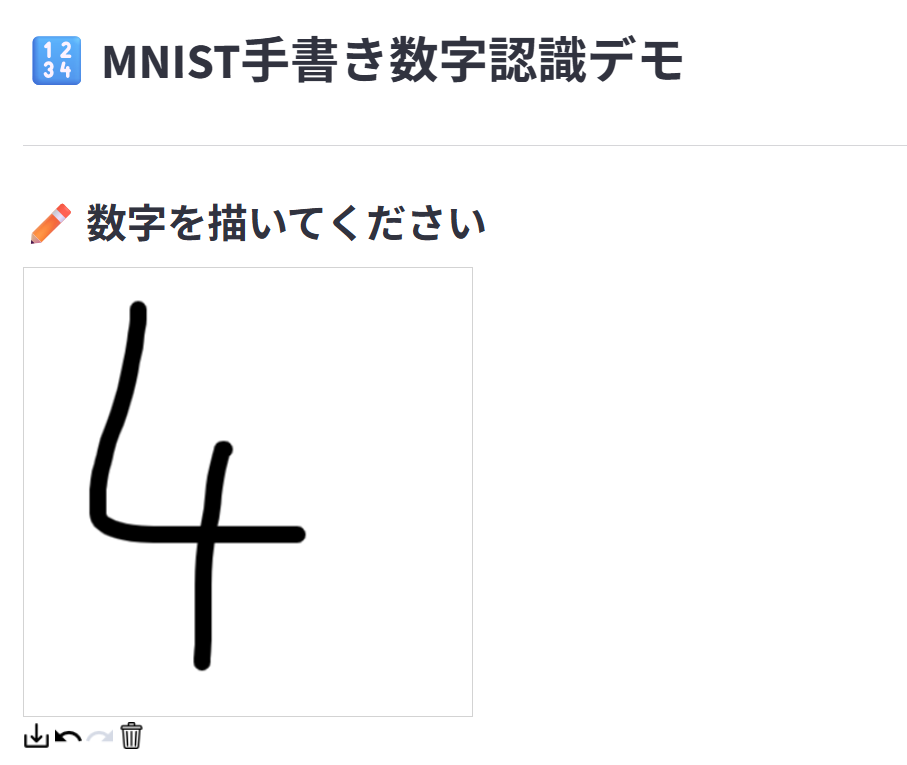
📝 描画キャンバスの詳細説明:
-
st_canvas()でマウスやタッチで自由に描画可能。 -
streamlit-drawable-canvasライブラリを使い、リアルタイムで画像データを取得できます。
4️⃣🔧 画像前処理機能
描画された画像をMNIST形式に変換する前処理機能を実装します。
# ===== 画像前処理関数 =====
def preprocess_image(image_data):
# 描画された画像を28x28に前処理
if image_data is None: # 描画データがない場合
return None # 処理しない
# ===== PILイメージに変換 =====
# Image.fromarray():numpy配列からPILイメージを作成
# astype('uint8'):データ型を8ビット符号なし整数に変換
img = Image.fromarray(image_data.astype('uint8'))
# ===== グレースケール変換 =====
# convert('L'):カラー画像をグレースケールに変換
img = img.convert('L')
# ===== 28x28にリサイズ =====
# resize((28, 28), Image.LANCZOS):画像を28x28ピクセルにリサイズ
img = img.resize((28, 28), Image.LANCZOS)
# ===== numpy配列に変換 =====
# np.array():PILイメージをnumpy配列に変換
img_array = np.array(img)
# ===== 値を反転 =====
# 255 - img_array:白背景・黒文字 → 黒背景・白文字に変換
# MNISTデータセットは黒背景・白文字なので、合わせる必要がある
img_array = 255 - img_array
# ===== 正規化 =====
# ピクセル値を0-1の範囲に正規化
img_array = img_array.astype('float32') / 255.0
# ===== 形状を調整 =====
# reshape(1, 28, 28, 1):バッチサイズ1の4次元配列に変換
# (バッチ数, 高さ, 幅, チャンネル数)
img_array = img_array.reshape(1, 28, 28, 1)
return img_array
📝 画像前処理の詳細説明:
-
PIL- Python Imaging Library の略で、画像処理のための強力なライブラリです。画像の読み込み、変換、保存などの基本的な画像操作が可能です。 -
グレースケール- カラー画像を白黒の濃淡だけの画像に変換する処理です。MNISTデータセットはグレースケール画像なので、この変換が必要です。 -
LANCZOS- 画像をリサイズする際の高品質なアルゴリズムです。画質を維持しながら画像サイズを変更できます。 -
255 - img_array- 画像の色を反転させる処理です。255から各ピクセル値を引くことで、白背景・黒文字を黒背景・白文字に変換します。これはMNISTデータセットの形式に合わせるために必要です。
5️⃣📊 前処理画像の表示
前処理された画像を右カラムに表示します。
with col2:
st.header("🔧 前処理された画像") # 右カラムのヘッダー
# ===== 前処理された画像の表示 =====
if canvas_result.image_data is not None:
# 4️⃣で定義したpreprocess_image()関数を呼ぶ
processed_img = preprocess_image(canvas_result.image_data)
if processed_img is not None:
# matplotlibで画像を表示
fig, ax = plt.subplots(figsize=(3, 3)) # 3x3インチの図を作成
ax.imshow(processed_img.reshape(28, 28), cmap='gray') # グレースケールで画像表示
ax.axis('off') # 軸を非表示
st.pyplot(fig) # matplotlibの図をStreamlitに表示
数字がどのように認識されているか見てみましょう!

📝 前処理画像表示の詳細説明:
-
matplotlibで前処理後の28x28画像をグレースケールで表示。 - 軸を非表示にして、手書き数字の形状を直感的に確認できます。
6️⃣🔮 予測機能の実装
AIによる予測機能を実装します。
st.markdown("---") # 区切り線
st.header("🤖 AI予測結果") # 画面下部のヘッダー
if st.button("🔍 予測する", type="primary"): # st.button():ボタンを作成し、ボタンが押された場合、以下の処理を実行
# キャンバスに描画データがある場合のみ処理を実行
if canvas_result.image_data is not None:
# 4️⃣で定義したpreprocess_image()関数を呼ぶ
processed_img = preprocess_image(canvas_result.image_data)
# preprocess_image関数の戻り値がある場合のみ処理を実行
if processed_img is not None:
# ===== 予測実行 =====
with st.spinner("🤔 AIが考え中..."): # スピナーで処理中を表示
# predict()メソッド:モデルで予測を実行
predictions = st.session_state.model.predict(processed_img, verbose=0) # verbose=0:学習中の進捗状況を表示しない
# np.argmax():確率が最も高いクラスのインデックスを取得
predicted_digit = np.argmax(predictions[0])
# np.max():最も高い確率値を取得
confidence = np.max(predictions[0])
st.success(f"**予測結果: {predicted_digit}**") # 予測結果を表示
st.info(f"確信度: {confidence:.2%}") # 確信度をパーセントで表示
st.subheader("📊 各数字の予測確率")
# ===== Plotlyで棒グラフ =====
# go.Figure():Plotlyの図を作成
fig = go.Figure(data=[
# go.Bar():棒グラフを作成
go.Bar(
x=list(range(10)), # x軸:0-9の数字
y=predictions[0], # y軸:各数字の予測確率
# 予測された数字は赤、それ以外は薄い青で表示
marker_color=['red' if i == predicted_digit else 'lightblue' for i in range(10)]
)
])
# update_layout():グラフのレイアウトを設定
fig.update_layout(
title="予測確率分布", # グラフのタイトル
xaxis_title="数字", # x軸のタイトル
yaxis_title="確率", # y軸のタイトル
showlegend=False, # 凡例を非表示
height=300 # グラフの高さ
)
st.plotly_chart(fig, use_container_width=True) # Plotlyの図をStreamlitに表示
else:
st.warning("⚠️ 画像の前処理に失敗しました")
else:
st.warning("⚠️ まず数字を描いてください")
予測を実行してみましょう!
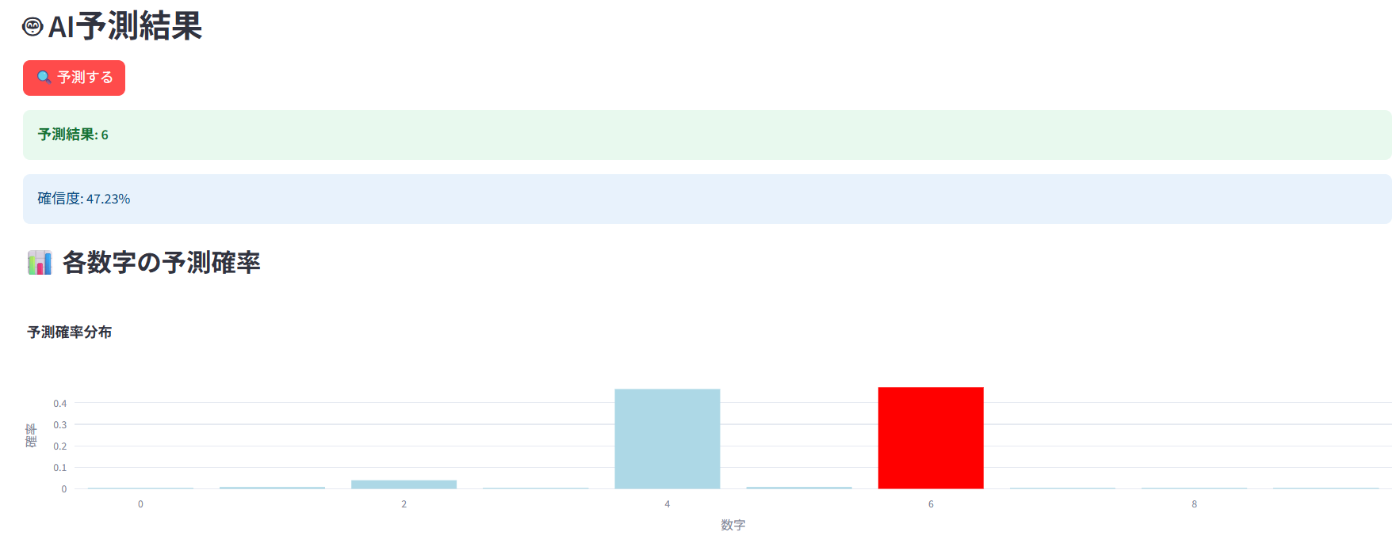
📝 予測機能の詳細説明:
-
model.predict()で前処理済み画像を入力し、各数字(0-9)の確率を出力。 - Plotlyで各数字の予測確率を棒グラフで可視化し、予測結果を赤色でハイライトします。
-
go.Bar()- 棒グラフを作成するPlotlyの関数
その他の主要なPlotlyグラフ👇-
go.Scatter()- 折れ線グラフ・散布図 -
go.Pie()- 円グラフ -
go.Histogram()- ヒストグラム
-
📝 marker_colorの詳細説明:
marker_color=['red' if i == predicted_digit else 'lightblue' for i in range(10)]
これは「リスト内包表記(List Comprehension)」という書き方です。
分解して理解しましょう!:
1. 基本的な構造:
marker_color = [色 for i in range(10)]
2. 条件分岐を追加:
marker_color = ['red' if i == predicted_digit else 'lightblue' for i in range(10)]
3. 同じ処理をfor文で書くと:
marker_color = []
for i in range(10):
if i == predicted_digit:
marker_color.append('red')
else:
marker_color.append('lightblue')
🎉 完成!
おめでとうございます!
今回出来上がった画面はこちらです 👇
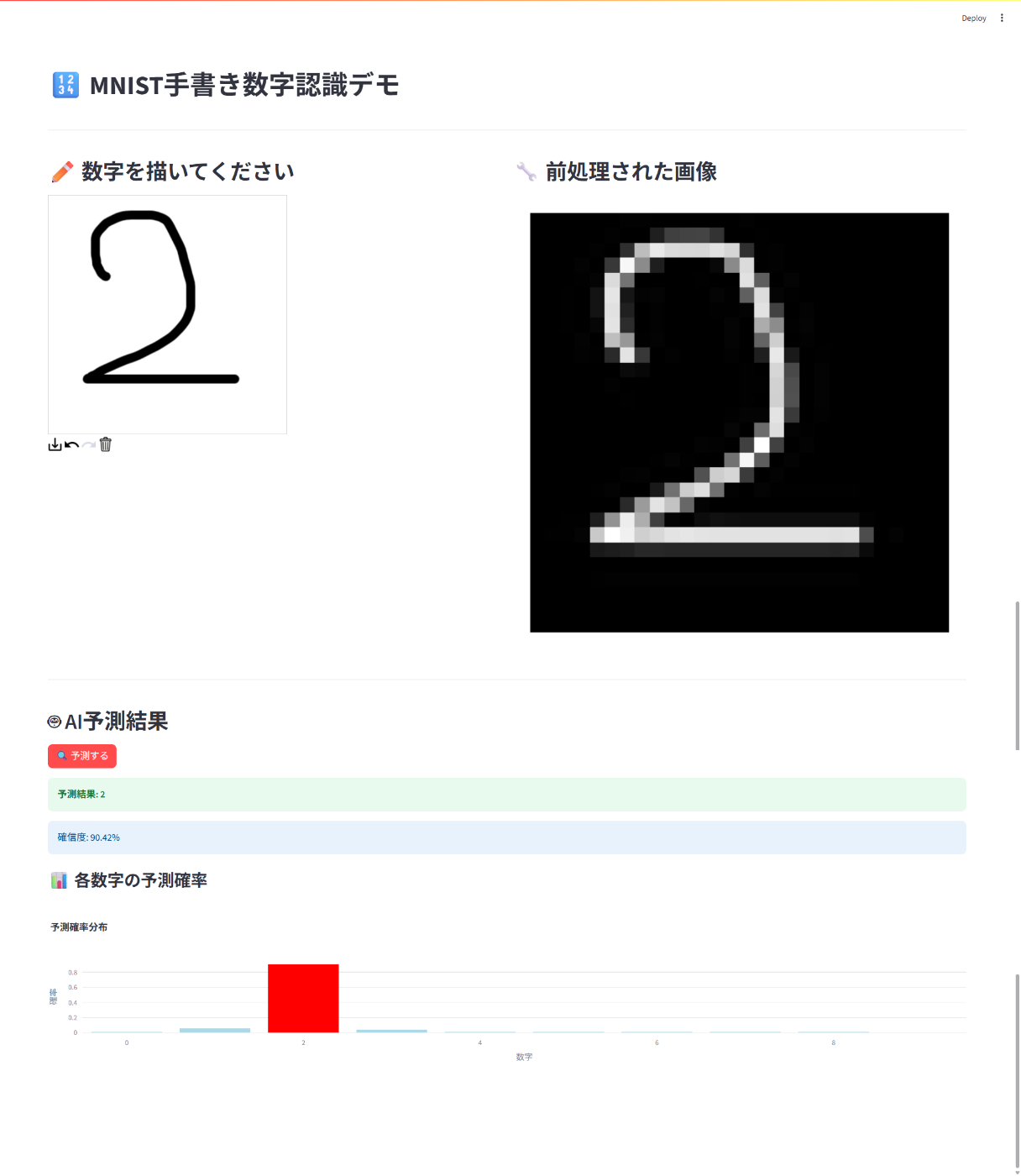
実際に様々な数字を描いて予測を試してみましょう!!
🎯 まとめ:MNIST手書き数字認識AIで学んだこと
今回作成したMNIST手書き数字認識AIは、以下のような多くの重要な概念が含まれています:
- 画像処理 - PILを使った画像の前処理と変換
- ディープラーニング - TensorFlowを使ったCNNモデル構築
- データ前処理 - 正規化とワンホットエンコーディング
- リアルタイム予測 - 描画と同時の予測実行
- 可視化 - Plotlyを使った美しいグラフ表示
今回のMNIST手書き数字認識AIの特徴:
- CNNモデル - 畳み込みニューラルネットワークによる高精度認識
- リアルタイム描画 - マウスやタッチでの自由な数字描画
- 画像前処理 - 自動的な28x28形式への変換
- 予測確率表示 - 各数字の確率を詳細表示
- 視覚的フィードバック - 前処理画像と予測結果の表示
🚀 次のステップ
今回学んだディープラーニングを応用して、以下のような機能を追加してみましょう:
- データ拡張 - 回転・拡大縮小による学習データ増強
- モデル改善 - より深いネットワークやアーキテクチャの変更
- 転移学習 - 事前学習済みモデルの活用
- リアルタイム学習 - ユーザーの描画データで継続学習
- 多クラス分類 - 文字や記号の認識への拡張
ディープラーニングは、このように少しずつ機能を追加していくことで、どんどん面白くなります!今回学んだCNNと画像処理は、AI開発の基本中の基本なので、しっかりと理解しておきましょう!
🎓 プログラミング学習におすすめ
プログラミング未経験の方には CyTech(サイテック) がおすすめです!
CyTech は、未経験から IT エンジニアを目指す人向けのオンライン学習プラットフォームで、基礎から実務レベルのスキルを最短 10 ヶ月で習得できるカリキュラムを提供しています。
HTML/CSS/JavaScript/PHP/SQL/Git などのプログラミング言語に加え、デザイン、英語なども学べる総合的なプラットフォームです。
今後随時学習できるプログラミング言語増加予定!
エンジニア学習にお困りの方はまずは CyTech 無料カウンセリングでお悩み解消!
Discussion