Python x 自作英単語学習アプリ で勉強しよう!
🤖 【プログラミング初心者向け】Python で作るAI英単語暗記アプリ
機械学習とWebアプリの基本から応用まで、楽しく学んでみませんか?今回は、Python で Streamlit を使って、AIが学習状況を分析してくれる英単語暗記アプリを作成します。辞書(dict)、if文、ループ(for文)、関数、機械学習、データ処理など、プログラミングの基本要素を実際に使いながら、インテリジェントな学習アプリの技術を身につけていきましょう。
AI、機械学習、データ分析、条件分岐、データ管理まで含む本格的なWebアプリを、ステップバイステップで学んでいきましょう。
🌟 この記事を読めば...
AIと機械学習を使ったWebアプリの技術を学べます 🎯
この記事では、単なる英単語アプリだけでなく、AIと機械学習を使ったWebアプリの基本から応用まで徹底的に学べます。例えば:
- Streamlitを使ったインタラクティブなWebアプリ作成
- 辞書(dict)を使ったデータ管理
- if文とループを使った条件分岐と繰り返し処理
- セッション状態を使ったデータの保持
- 機械学習による難易度予測と学習分析
- データ可視化による学習進捗の確認
📺 Youtube配信もチェック!
記事が難しくても大丈夫!!プログラミングの様子をYoutube Live配信でも公開しています!
- 実際のコーディングの様子が見られる
- チャットで質問もできる
- この記事の内容がより理解できる
チャンネルはこちら👇
ぜひチャンネル登録して、一緒にプログラミングを学びましょう!
💡 そもそもAI英単語アプリって❓
AI英単語暗記アプリは、機械学習を使って学習者の進捗を分析し、最適な学習方法を提案するプログラムです。
- ユーザーの学習データを分析して習得度を計算
- AIが単語の難易度を自動判定
- 学習進捗に基づいて復習すべき単語を推奨
- データ可視化で学習状況を一目で確認
📁 フォルダとファイルの作成
1. フォルダ構造
english-vocabulary-app/
├── english-study.py
├── words_data.csv
└── requirements.txt
words_data.csvは、英単語データを保存するためのCSVファイルです。以下のような情報を保存します:
- english: 英単語
- japanese: 日本語訳
- correct: 正解数
- total: 学習回数
- difficulty: AIが予測した難易度(1-5)
- last_review: 最後に学習した日時
このCSVファイルを使って:
- 追加した英単語を永続的に保存
- 学習履歴や正解率を記録
- アプリを再起動しても学習データを維持
- AIによる難易度分析の結果を保存
といった機能を実現します。
2. 必要なライブラリをインストール
まず、requirements.txtファイルに以下を書きます:
streamlit>=1.28.0
pandas>=2.0.0
numpy>=1.24.0
plotly>=5.15.0
scikit-learn>=1.3.0
⚡ AI英単語暗記アプリを作ってみよう
さっそく、english-study.py にコードを書いていきましょう!
1️⃣📱 アプリの基本設定とライブラリのインポート
# 必要なライブラリをインポート
import streamlit as st # Webアプリ作成用
import pandas as pd # データ処理用
import numpy as np # 数値計算用
import plotly.express as px # グラフ作成用
from datetime import datetime # 日時処理用
import time # 時間処理用
from sklearn.ensemble import RandomForestRegressor # 機械学習モデル用
import re # 正規表現処理用
import os # ファイル操作用
# ページ設定
st.set_page_config(
page_title="英単語暗記アプリ", # ブラウザのタブに表示されるタイトル
page_icon="📚", # ブラウザのタブに表示されるアイコン
layout="wide", # レイアウトをワイドに設定
)
# データファイルのパス
DATA_FILE = "words_data.csv"
cursor のターミナルで以下のコマンドを実行して画面表示を確認しましょう!
python -m streamlit run english-study.py
画面は特に何もないですが、ブラウザ上部のタブにページタイトルやアイコンが表示されていますね!
📝 ライブラリの詳細説明:
-
データ処理ライブラリ
-
pandas: データフレームを使った効率的なデータ処理 -
numpy: 数値計算と配列操作
-
-
可視化ライブラリ
-
plotly.express: インタラクティブなグラフ作成
-
-
機械学習ライブラリ
-
scikit-learn: 機械学習アルゴリズムの実装
-
-
その他のライブラリ
-
datetime: 日時処理 -
re: 正規表現によるテキスト処理 -
os: ファイル操作
-
2️⃣📊 データ管理関数の実装
CSVファイルを使ったデータの読み込みと保存機能を実装します。
def load_words_data():
"""CSVファイルから単語データを読み込み"""
try:
# CSVファイルが存在するかチェック
if os.path.exists(DATA_FILE):
df = pd.read_csv(DATA_FILE, encoding='utf-8')
# last_review列をdatetime型に変換
df['last_review'] = pd.to_datetime(df['last_review'])
return df
else:
# ファイルが存在しない場合は初期データを作成
return pd.DataFrame({
'english': ['apple', 'book', 'computer'], # 英単語
'japanese': ['りんご', '本', 'コンピュータ'], # 日本語訳
'correct': [0, 0, 0], # 正解数
'total': [0, 0, 0], # 総挑戦数
'difficulty': [1, 1, 2], # 難易度(1-5)
'last_review': [datetime.now()] * 3 # 最後に学習した日時
})
except Exception as e:
st.error(f"データ読み込みエラー: {e}")
# エラー時は初期データを返す
return pd.DataFrame({
'english': ['apple', 'book', 'computer'],
'japanese': ['りんご', '本', 'コンピュータ'],
'correct': [0, 0, 0],
'total': [0, 0, 0],
'difficulty': [1, 1, 2],
'last_review': [datetime.now()] * 3
})
def save_words_data(df):
"""単語データをCSVファイルに保存"""
try:
df.to_csv(DATA_FILE, index=False, encoding='utf-8')
return True
except Exception as e:
st.error(f"データ保存エラー: {e}")
return False
📝 データ管理の詳細説明:
🔍 データフレームの構造:
-
列の構成
-
english: 英単語 -
japanese: 日本語訳 -
correct: 正解回数 -
total: 総挑戦回数 -
difficulty: 難易度(1-5) -
last_review: 最後に学習した日時
-
-
エラーハンドリング
- ファイルが存在しない場合の初期データ作成
- 読み込みエラー時のフォールバック処理
-
データ型の変換
-
pd.to_datetime()で日時データを適切な型に変換
-
🔍 エンコーディング指定の重要性:
-
UTF-8エンコーディング
-
encoding='utf-8'で日本語文字を正しく処理 - 文字化けを防止し、日本語データを安全に保存・読み込み
-
-
データファイルの読み込み処理:
-
os.path.exists(DATA_FILE)でファイルの存在を確認 - 存在する場合は
pd.read_csv()でCSVファイルを読み込み - エラー時は初期データを作成
-
-
データファイルの保存処理:
-
df.to_csv()でデータフレームをCSVファイルに保存 -
index=Falseでインデックス列を除外して保存 - try-except文でエラーを捕捉
-
3️⃣🤖 機械学習による難易度予測機能の実装
単語の特徴を分析して、AIが難易度を予測する機能を実装します。
def extract_word_features(word):
"""単語の特徴量を抽出(機械学習の入力データ)"""
# 辞書(dict)を使って特徴量を管理
# 辞書は {キー: 値} の形式でデータを保存
features = {
'length': len(word), # 単語の長さ
'vowel_count': len(re.findall(r'[aeiouAEIOU]', word)), # 母音の数
'consonant_count': len(re.findall(r'[bcdfghjklmnpqrstvwxyzBCDFGHJKLMNPQRSTVWXYZ]', word)), # 子音の数
'has_double_letters': int(bool(re.search(r'(.)\1', word))), # 同じ文字の連続
}
return features
def train_difficulty_model(df):
"""難易度予測モデルの訓練(機械学習の核心部分)"""
# if文で条件分岐:データが3単語未満の場合はモデルを訓練できない
if len(df) < 3:
return None
# ステップ1: 特徴量の準備
st.info("🔍 ステップ1: 単語の特徴を調べているよ...")
# リスト(list)を使って特徴量を管理
# リストは [値1, 値2, 値3] の形式でデータを保存
features = []
# ループ(for文)で辞書の要素を順番に処理
for word in df['english']:
word_features = extract_word_features(word) #上で定義したextract_word_features関数を利用して特徴量を抽出(長さ、母音数、子音数、重複文字の有無)
features.append(list(word_features.values())) # 特徴量の値のみをリストに変換して追加(キーは不要)
X = np.array(features) # 入力データ(特徴量)をNumPy配列に変換
y = df['difficulty'].values # 正解データ(難易度)をNumPy配列に変換
# ステップ2: モデルの訓練
st.info("🤖 ステップ2: AIが学習しているよ...")
# RandomForestモデルを作成(50個の決定木を使用)
model = RandomForestRegressor(n_estimators=50, random_state=42)
# モデルにデータを学習させる
model.fit(X, y)
return model
def predict_difficulty_ml(word, model):
"""機械学習による難易度予測"""
# if文で条件分岐:モデルがない場合はデフォルト難易度1を返す
if model is None:
return 1
features = extract_word_features(word) #上で定義したextract_word_features関数を利用して特徴量を抽出
# 特徴量をNumPy配列に変換(機械学習モデルの入力形式)
X = np.array([list(features.values())])
# 予測実行:機械学習モデルを使って難易度を予測
prediction = model.predict(X)[0]
# 予測結果を1-5の範囲に制限して整数に四捨五入
return max(1, min(5, round(prediction)))
📝 機械学習の詳細説明:
🔍 特徴量エンジニアリング:
-
単語の長さ
-
length: len()関数で単語の文字数をカウント - len()は文字列の長さを返す組み込み関数
- 長い単語ほど難しい傾向を考慮
-
-
母音の数
-
vowel_count: re.findall()で母音(a,e,i,o,u)をカウント - re.findall()は正規表現パターンに一致する全ての文字列を抽出
- r'[aeiouAEIOU]'のrは生文字列(raw string)を表し、\をエスケープ不要に
- 母音が多いと発音が複雑になる可能性
-
-
子音の数
-
consonant_count: re.findall()で子音をカウント - r'[bcdfg...]'で子音のパターンを指定
- 子音の組み合わせが多いと難しくなる
-
-
同じ文字の連続
-
has_double_letters: bool()でTrue/Falseを0/1に変換 - int()でブール値を整数に変換(True→1, False→0)
- re.search()で(.)\1パターン(同じ文字の連続)を検索
- "book"のような重複文字の検出
-
🔍 特徴量リストの作成:
features.append(list(word_features.values())) は以下のような処理を行っています:
-
word_features.values()
- word_featuresは辞書型で、各特徴量を保持
- values()メソッドで辞書の値だけを取得
- 例: {'length': 4, 'vowel_count': 2, ...} → [4, 2, ...]
-
list()による変換
- values()の結果をリスト型に変換
- 機械学習モデルが扱いやすい形式に整形
- 順序付けられた特徴量のリストを作成
-
features.append()
- 変換したリストをfeaturesリストに追加
- 全単語の特徴量を1つのリストにまとめる
- 例: [[4, 2, ...], [5, 3, ...], ...]
-
処理の流れ
word_features = {'length': 4, 'vowel_count': 2, 'consonant_count': 2, 'has_double_letters': 1} values = word_features.values() # dict_values([4, 2, 2, 1]) feature_list = list(values) # [4, 2, 2, 1] features.append(feature_list) # features = [[4, 2, 2, 1], ...]
🎯 RandomForestの利点:
- 精度の高さ:複数の決定木の組み合わせで予測精度を向上
- 過学習の防止:アンサンブル学習で安定した予測
- 特徴量の重要度:どの特徴が予測に重要かを分析可能
🔍 特徴量の配列変換:
X = np.array([list(features.values())]) は以下のような処理を行っています:
-
特徴量の取り出し
- features.values()で辞書から値のみを取得
- 例: {'length': 4, 'vowel_count': 2, ...} → dict_values([4, 2, ...])
-
リスト化とネスト
- list()で値をリストに変換: [4, 2, ...]
- []で囲んでネストされたリスト作成: [[4, 2, ...]]
- 機械学習モデルが要求する2次元配列の形式に
-
NumPy配列への変換
- np.array()でNumPy配列に変換
- 形状: (1, 特徴量の数)の2次元配列
- 例: array([[4, 2, 2, 1]])
-
処理の具体例
features = {'length': 4, 'vowel_count': 2, 'consonant_count': 2, 'has_double_letters': 1} values = features.values() # dict_values([4, 2, 2, 1]) values_list = list(values) # [4, 2, 2, 1] nested_list = [values_list] # [[4, 2, 2, 1]] X = np.array(nested_list) # array([[4, 2, 2, 1]])
この形式は機械学習モデルのpredict()メソッドが要求する入力形式に合致しており、1つの単語の予測に使用できます。
4️⃣📈 学習進捗分析機能の実装
学習データを分析して、習得度を計算し、AIが復習を推奨する機能を実装します。
def calculate_score(correct, total):
"""習得度計算(正答率ベース)"""
# if文で条件分岐:学習回数が0回の場合は0点
if total == 0:
return 0
# 正答率を計算(正解数 ÷ 総挑戦数)
accuracy = correct / total
# 正答率を100点満点に変換して小数点第1位で四捨五入
return round(accuracy * 100, 1)
# セッションステートの初期化(アプリのデータ保存場所)
# 辞書(dict)を使って単語データを管理
# 辞書は {キー: 値} の形式でデータを保存
if 'words_df' not in st.session_state:
st.session_state.words_df = load_words_data()
# 現在の問題を保存するセッション状態
if 'current_study_word' not in st.session_state:
st.session_state.current_study_word = None
📝 学習分析の詳細説明:
🔍 習得度計算のロジック:
-
正答率ベース
- 正解数 ÷ 総挑戦数で習得度を算出
- 0-100点のスコアで表現
-
セッション状態の活用
- ページをリロードしてもデータが保持
- リアルタイムで学習進捗を更新
-
条件分岐による処理
- 学習回数が0の場合は0点を返す
- エラーを防止する安全な処理
-
round()メソッドの使用
- 小数点以下の桁数を指定して四捨五入
- 第1引数: 四捨五入する数値
- 第2引数: 小数点以下の桁数
例
score = 85.6789
rounded = round(score, 1) # 85.7 (小数点第1位まで)
- 第2引数を省略すると整数に四捨五入
score = 85.6789
rounded = round(score) # 86
5️⃣🎨 メインUIの実装(単語追加機能)
ユーザーが新しい単語を追加できる機能を実装します。
# メインタイトル
st.title("🤖 英単語暗記アプリ")
st.write("AIがお手伝いする楽しい英単語学習ツールだよ!")
# --- 入力セクション(単語追加機能) ---
st.header("1️⃣ 新しい単語を追加しよう!")
# 2列レイアウトで入力フォームを作成
col1, col2 = st.columns(2)
with col1:
new_english = st.text_input("英単語", placeholder="例: beautiful")
with col2:
new_japanese = st.text_input("日本語", placeholder="例: 美しい")
# ボタンがクリックされたときの処理
if st.button("➕ 追加する!"):
# if文で条件分岐:英単語と日本語の両方が入力されているかチェック
if new_english and new_japanese:
# AIによる難易度予測
df = st.session_state.words_df.copy()
# スピナー(ローディング表示)でAI分析中を表示
with st.spinner("AIが単語の難しさを調べているよ..."):
# 機械学習モデルを訓練して難易度を予測
difficulty_model = train_difficulty_model(df)
predicted_difficulty = predict_difficulty_ml(new_english, difficulty_model)
# 上で定義したextract_word_features関数を利用し、特徴量の表示
features = extract_word_features(new_english)
# 新しい単語のデータを作成
new_row = pd.DataFrame({
'english': [new_english], # 英単語
'japanese': [new_japanese], # 日本語訳
'correct': [0], # 正解数(初期値0)
'total': [0], # 総挑戦数(初期値0)
'difficulty': [predicted_difficulty], # AI予測難易度
'last_review': [datetime.now()] # 追加日時
})
# 既存のデータフレームに新しい行を追加
st.session_state.words_df = pd.concat([st.session_state.words_df, new_row], ignore_index=True)
# 上で定義したsave_words_data関数を利用し、データをCSVファイルに保存
if save_words_data(st.session_state.words_df):
st.success(f"✅ '{new_english}'を追加したよ!難しさレベル: {predicted_difficulty}")
st.info(f"📊 単語の特徴: {features['length']}文字, 母音{features['vowel_count']}個, 子音{features['consonant_count']}個")
st.info("💾 データを保存したよ!")
else:
st.warning("⚠️ データの保存に失敗しちゃった...")
# 現在の問題をリセットして新しい単語も学習できるようにする
st.session_state.current_study_word = None
time.sleep(0.5) # 0.5秒待機
st.rerun() # 画面を更新
画面を更新して確認しましょう!

📝 UI実装の詳細説明:
-
2列レイアウト
-
st.columns(2)で画面を2分割 - 英単語と日本語を横並びで入力
-
-
AI分析の可視化
-
st.spinner()でローディング表示 - ユーザーに処理状況を伝える
-
-
データフレーム操作
-
pd.concat()で新しい行を追加 -
ignore_index=Trueでインデックスを再設定
-
6️⃣📚 学習セクションの実装
英単語の練習機能を実装します。
# --- 学習セクション(英単語学習機能) ---
st.header("2️⃣ 英単語を練習しよう!")
# if文で条件分岐:単語データが存在する場合のみ学習モードを表示
if len(st.session_state.words_df) > 0:
df = st.session_state.words_df.copy()
# 各単語の習得度を計算
# correct: 正解数, total: 学習回数から
# calculate_score関数を使って0-100の習得度スコアを算出
df['score'] = df.apply(lambda x: calculate_score(x['correct'], x['total']), axis=1)
# 現在の問題が設定されていない場合のみ新しい問題を選択
if st.session_state.current_study_word is None:
# 習得度の低い単語からランダムに選択(学習効率と多様性のバランス)
# 習得度が50%未満の単語があれば、その中からランダム選択
# なければ全単語からランダム選択
low_score_words = df[df['score'] < 50]
if len(low_score_words) > 0:
study_word = low_score_words.sample(n=1).iloc[0]
else:
study_word = df.sample(n=1).iloc[0]
# セッション状態に現在の問題を保存
st.session_state.current_study_word = study_word
else:
# 既存の問題を使用
study_word = st.session_state.current_study_word
# 問題表示
st.subheader(f"問題: {study_word['english']}")
st.write(f"難しさレベル: {'⭐' * study_word['difficulty']}")
# ユーザーの回答入力
user_answer = st.text_input("日本語訳を入力:", key="study_answer_input")
# 答え合わせボタンがクリックされたときの処理
if st.button("🔍 答え合わせ"):
# if文で条件分岐:正解か不正解かを判定
if user_answer.strip().lower() == study_word['japanese'].strip().lower():
# 正解の場合
word_idx = study_word.name
st.session_state.words_df.loc[word_idx, 'correct'] += 1 # 正解数を増やす
st.session_state.words_df.loc[word_idx, 'total'] += 1 # 総挑戦数を増やす
st.session_state.words_df.loc[word_idx, 'last_review'] = datetime.now() # 学習日時を更新
# 上で定義したsave_words_data関数を利用し、データをCSVファイルに保存
if save_words_data(st.session_state.words_df):
st.success("✅ 正解だよ!すごいね!")
else:
st.warning("⚠️ データの保存に失敗しちゃった...")
# 現在の問題をリセットして次の問題を準備
st.session_state.current_study_word = None
time.sleep(1) # 1秒待機
st.rerun() # 画面を更新
else:
# 不正解の場合
word_idx = study_word.name
st.session_state.words_df.loc[word_idx, 'total'] += 1 # 総挑戦数のみ増やす
st.session_state.words_df.loc[word_idx, 'last_review'] = datetime.now() # 学習日時を更新
# 上で定義したsave_words_data関数を利用し、データをCSVファイルに保存
if save_words_data(st.session_state.words_df):
st.error(f"❌ 不正解だよ。正解は「{study_word['japanese']}」だったよ。")
else:
st.warning("⚠️ データの保存に失敗しちゃった...")
# 現在の問題をリセットして次の問題を準備
st.session_state.current_study_word = None
time.sleep(2) # 2秒待機
st.rerun() # 画面を更新
これで英単語の問題を解く箇所ができたはずです!

📝 学習機能の詳細説明:
🔍 適応的学習システム:
-
習得度ベースの単語選択
- 最も習得度の低い単語を優先的に出題
-
リアルタイムデータ更新
- 正解・不正解に応じてデータを即座に更新
- 学習進捗をリアルタイムで反映
-
ユーザビリティの向上
- 正解時は短い待機時間
- 不正解時は長めの待機時間で復習を促す
📝 loc[]の詳細説明:
-
データフレームの行選択
-
df.loc[行インデックス]: 指定した行のデータを取得 -
df.loc[word_idx]: word_idxで指定した単語の行を選択
-
-
列の更新
-
df.loc[行インデックス, '列名']: 特定のセルを更新 - 例:
words_df.loc[word_idx, 'correct'] += 1で正解数を1増やす
-
-
複数列の同時更新
- 1行の複数列を一度に更新可能
- 例: 正解数、総数、最終学習日を同時に更新
-
条件付き更新
- 条件に合致する行のみを更新
- 正解/不正解で異なる更新処理を実行
7️⃣🤖 AI分析セクションの実装
AIが学習状況を分析して、復習すべき単語を推奨する機能を実装します。
# --- AI分析セクション(学習データ分析機能) ---
st.header("3️⃣ 🤖 AIが学習状況をチェックしてくれるよ!")
# 学習データをコピーして習得度を計算
df = st.session_state.words_df.copy()
df['習得度'] = df.apply(lambda x: calculate_score(x['correct'], x['total']), axis=1)
# if文で条件分岐:最低3回学習したらAI分析開始
if df['total'].sum() >= 3: # 最低3回学習したらAI分析開始
# AI推奨復習(学習進捗に基づく復習提案)
st.subheader("🗓️ AIからの復習アドバイス")
# 2列レイアウトで復習情報を表示
col1, col2 = st.columns(2)
with col1:
st.write("🔴 もう一度練習した方がいい単語")
# 習得度50%未満の単語を抽出して習得度順にソート
weak_words = df[df['習得度'] < 50].sort_values('習得度')
# if文で条件分岐:要復習単語があるかチェック
if len(weak_words) > 0:
# ループ(for文)で辞書の要素を順番に処理
for _, word in weak_words.iterrows():
st.write(f"• {word['english']}")
else:
st.write("すごい!復習が必要な単語はないよ!")
with col2:
st.write("🟢 よくできている単語")
# 習得度80%以上の単語を抽出
strong_words = df[df['習得度'] >= 80]
# if文で条件分岐:習得済み単語があるかチェック
if len(strong_words) > 0:
# ループ(for文)で辞書の要素を順番に処理
for _, word in strong_words.iterrows():
st.write(f"• {word['english']}")
else:
st.write("まだ完璧に覚えた単語はないよ。頑張ろう!")
else:
# 学習データが不足している場合の案内
st.info("AI分析には最低3回の学習データが必要だよ!もっと練習してみてね!")
復習すべき単語が表示される箇所ができました!

※実際の初期状態では表示される単語は apple, book, computerのみです。
📝 AI分析の詳細説明:
🔍 iterrowsメソッドの詳細:
-
基本的な使い方
- DataFrameの各行を1行ずつ処理するためのメソッド
-
for index, row in df.iterrows():の形式で使用 -
index: 行のインデックス番号 -
row: 各行のSeriesオブジェクト
-
特徴と利点
- 行ごとのデータにアクセスが容易
-
row['列名']で各列の値を取得可能 - 処理内容を柔軟にカスタマイズ可能
-
使用例
# weak_wordsの各行に対して処理 for _, word in weak_words.iterrows(): st.write(f"• {word['english']}")-
_: インデックスを使用しない場合の慣習的な記法 -
word: 各行のデータを含むSeries
-
-
注意点
- 大量データの処理には比較的時間がかかる
- パフォーマンスが重要な場合は他の方法を検討
🔍 習得度計算の詳細:
-
df.apply()の使い方- データフレームの各行に対して関数を適用
-
axis=1で行方向に処理を実行
-
calculate_score関数の役割- 正解数(
correct)と総挑戦数(total)から習得度を計算 - 0-100点のスコアを返す
- 正解数(
-
ラムダ関数の使用
- 無名関数とも呼ばれる一時的な関数
-
lambda 引数: 処理の形式で記述 - 単純な処理を1行で書ける便利な関数
lambda x: calculate_score(x['correct'], x['total'])- 各行のデータを
calculate_score関数に渡す
-
計算結果の格納
- 計算された習得度を新しい列'習得度'に保存
- リアルタイムで学習進捗を反映
8️⃣📊 データ可視化セクションの実装
Plotlyを使ったインタラクティブなグラフで学習進捗を見える化しましょう!
# --- グラフセクション(学習データ可視化機能) ---
st.header("4️⃣ 📊 学習の進み具合を見てみよう!")
# if文で条件分岐:学習データが存在する場合のみグラフを表示
if df['total'].sum() > 0:
# グラフ: 単語別習得度(棒グラフ)
st.subheader("📊 各単語のでき具合")
# Plotlyを使って習得度の棒グラフを作成
fig1 = px.bar(df, x='english', y='習得度',
title="各単語のでき具合(100点満点)",
color='習得度',
color_continuous_scale='RdYlGn') # Red-Yellow-Green のグラデーションカラースケール。
st.plotly_chart(fig1, use_container_width=True) # グラフを画面幅いっぱいに表示
else:
# 学習データが不足している場合の案内
st.info("学習データがまだないよ。上の練習モードで勉強してみてね!")
実際に、単語を追加したり、単語問題を回答したりして棒グラフを確認してみましょう!

📝 データ可視化の詳細説明:
🔍 Plotlyの活用:
-
インタラクティブグラフ
- ホバーで詳細情報を表示
- ズーム・パン機能で詳細確認
-
カラースケール
-
RdYlGn(赤-黄-緑)で習得度を視覚化
-
-
レスポンシブデザイン
-
use_container_width=Trueで画面幅に合わせて調整
-
9️⃣📋 データ管理セクションの実装
データの保存、読み込み、リセット機能を実装します。
# --- 現在のデータ表示(学習データ一覧) ---
st.header("📋 今までに覚えた単語一覧")
# データ管理ボタン
col1, col2, col3 = st.columns(3)
with col1:
if st.button("💾 データを保存"):
# セッションステートの単語データをCSVファイルに保存。成功したらTrue、失敗したらFalseを返す
if save_words_data(st.session_state.words_df):
st.success("✅ データを保存したよ!")
else:
st.error("❌ データの保存に失敗しちゃった...")
with col2:
if st.button("🔄 データを読み込み直す"):
# 上で定義したload_words_data関数を利用し、セッションステートの単語データを最新のCSVファイルから読み込み直す
st.session_state.words_df = load_words_data()
st.success("✅ データを読み込み直したよ!")
st.rerun()
with col3:
# リセット確認用のセッション状態
if 'show_reset_confirm' not in st.session_state:
st.session_state.show_reset_confirm = False
if not st.session_state.show_reset_confirm:
if st.button("🗑️ データをリセット", type="secondary"):
# リセット確認画面を表示するフラグをTrueに設定
st.session_state.show_reset_confirm = True
st.rerun()
else:
st.write("⚠️ 本当にリセットする?")
col_yes, col_no = st.columns(2)
with col_yes:
if st.button("✅ はい、リセットする", type="primary"):
# セッションステートの単語データを初期状態にリセット
st.session_state.words_df = pd.DataFrame({
'english': ['apple', 'book', 'computer'],
'japanese': ['りんご', '本', 'コンピュータ'],
'correct': [0, 0, 0],
'total': [0, 0, 0],
'difficulty': [1, 1, 2],
'last_review': [datetime.now()] * 3
})
# save_words_data関数を利用し、リセット後のデータをCSVファイルに保存
save_words_data(st.session_state.words_df)
# リセット確認画面を非表示に戻す
st.session_state.show_reset_confirm = False
st.success("✅ データをリセットしたよ!")
st.rerun()
with col_no:
if st.button("❌ いいえ、キャンセル"):
# リセット確認画面を非表示に戻す
st.session_state.show_reset_confirm = False
st.rerun()
# 表示用のデータフレームをコピーして習得度と正答率を計算
display_df = st.session_state.words_df.copy()
display_df['習得度'] = display_df.apply(lambda x: calculate_score(x['correct'], x['total']), axis=1)
display_df['正答率(%)'] = display_df.apply(lambda x: round(x['correct']/x['total']*100) if x['total'] > 0 else 0, axis=1)
# データフレームを表示(指定した列のみ表示)
st.dataframe(display_df[['english', 'japanese', 'correct', 'total', '正答率(%)']], use_container_width=True)
# データファイル情報
st.info(f"📊 今までに覚えた単語の数: {len(st.session_state.words_df)}個")
単語問題を回答し、表がどのように変化するか確認しましょう!

また、各ボタンも押して画面の変化やwords_data.csvの中身の変化も確認しておきましょう!
📝 データ管理の詳細説明:
🔍 安全なデータ操作:
-
確認ダイアログ
- リセット前に確認画面を表示
- 誤操作を防止
-
エラーハンドリング
- 保存・読み込み時のエラー処理
- ユーザーへの適切なフィードバック
-
データの整合性
- 計算された列(習得度、正答率)の表示
- リアルタイムでのデータ更新
📊 データフレームの表示と計算について
🔍 表示用データフレームの作成:
-
習得度の計算
display_df['習得度'] = display_df.apply(lambda x: calculate_score(x['correct'], x['total']), axis=1)-
calculate_score関数を使って各単語の習得度を計算 - 正解数(correct)と総挑戦数(total)から0-100のスコアを算出
- 例:正解3回/挑戦5回 → 習得度60点
- display_df.apply()で各行に対して処理を実行
- lambda関数で各行のデータを受け取り、calculate_score()に渡す
- axis=1で行方向に処理を実行し、結果を'習得度'列として追加
-
-
正答率の計算
display_df['正答率(%)'] = display_df.apply( lambda x: round(x['correct']/x['total']*100) if x['total'] > 0 else 0, axis=1 )- display_df.apply()で各行に対して処理を実行
- lambda関数で各行のデータを受け取り、正答率を計算
- if x['total'] > 0で総挑戦数が0より大きい場合のみ計算
- axis=1で行方向に処理を実行し、結果を'正答率(%)'列として追加
- 正解数(correct)÷総挑戦数(total)×100で%を計算(例:正解2回/挑戦4回 → 正答率50%)
- round()関数で小数点以下を四捨五入(例:50.5% → 51%)
- else 0 で未挑戦(total=0)の場合は0%を表示
単語の追加、問題の回答を複数回行って、グラフや表の変化も見てみましょう!
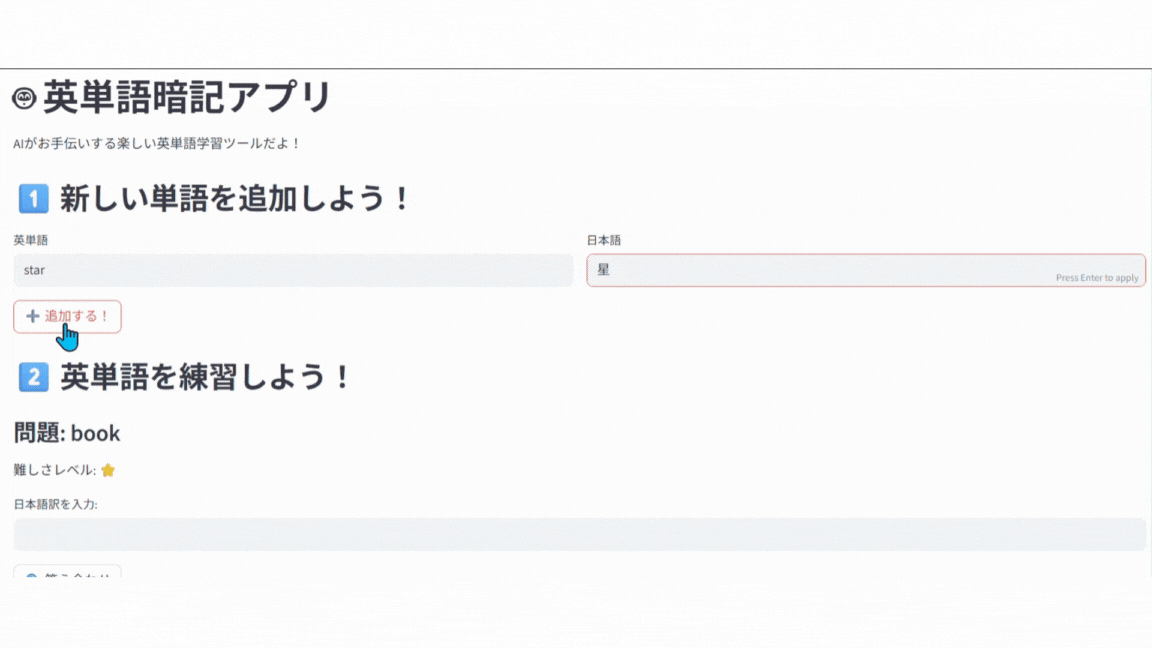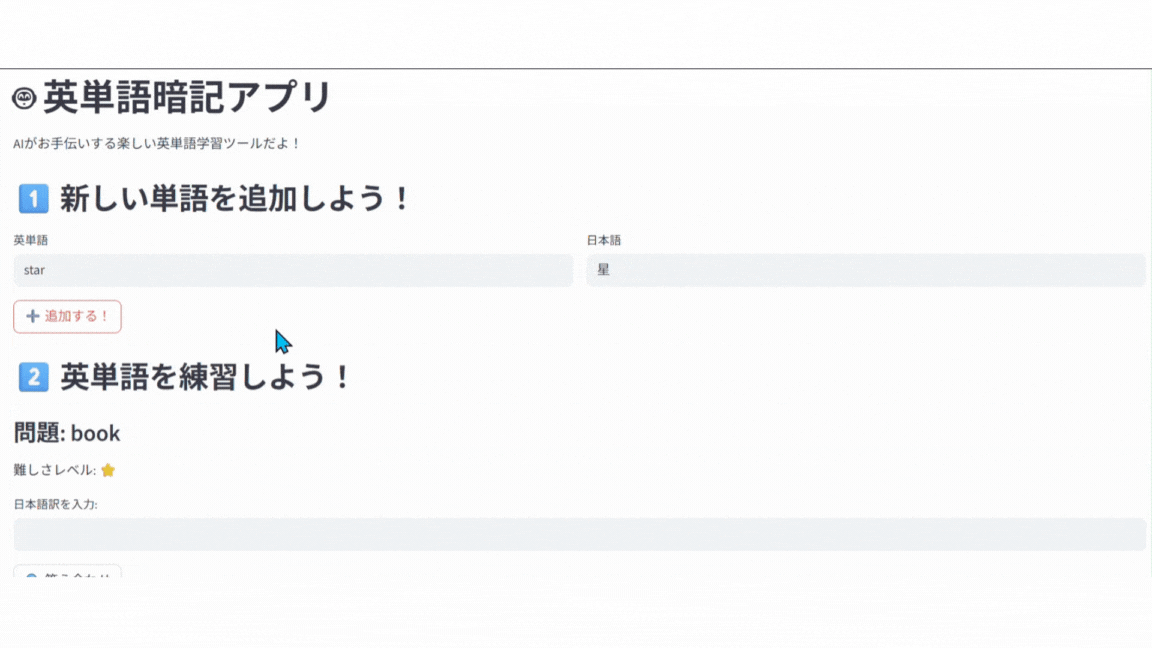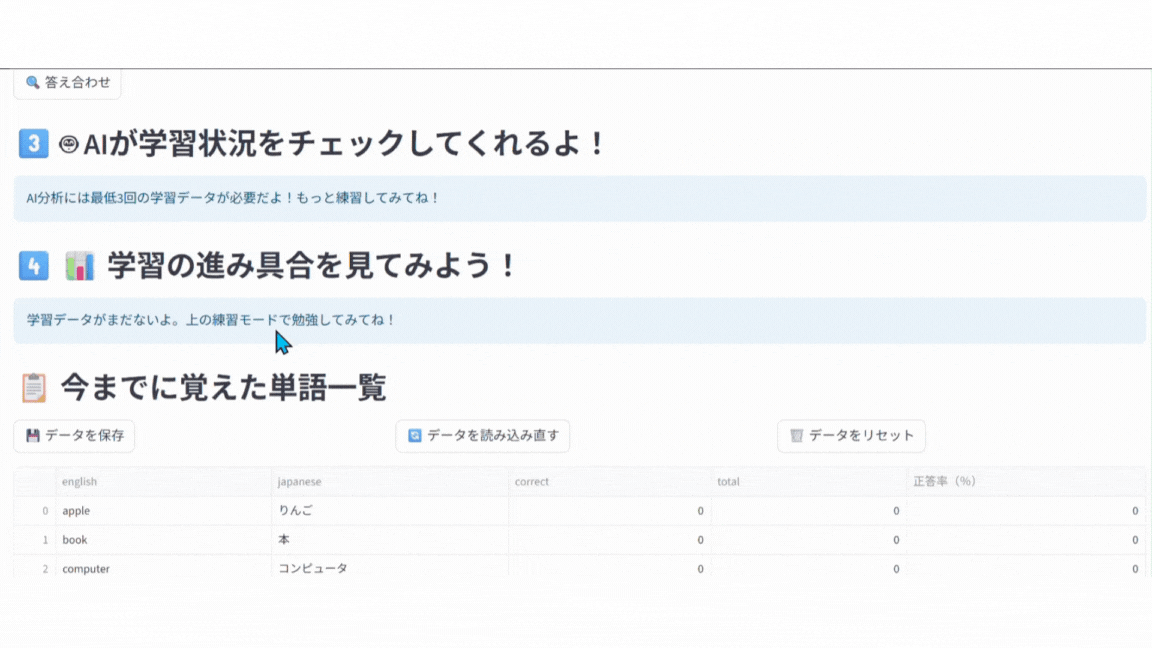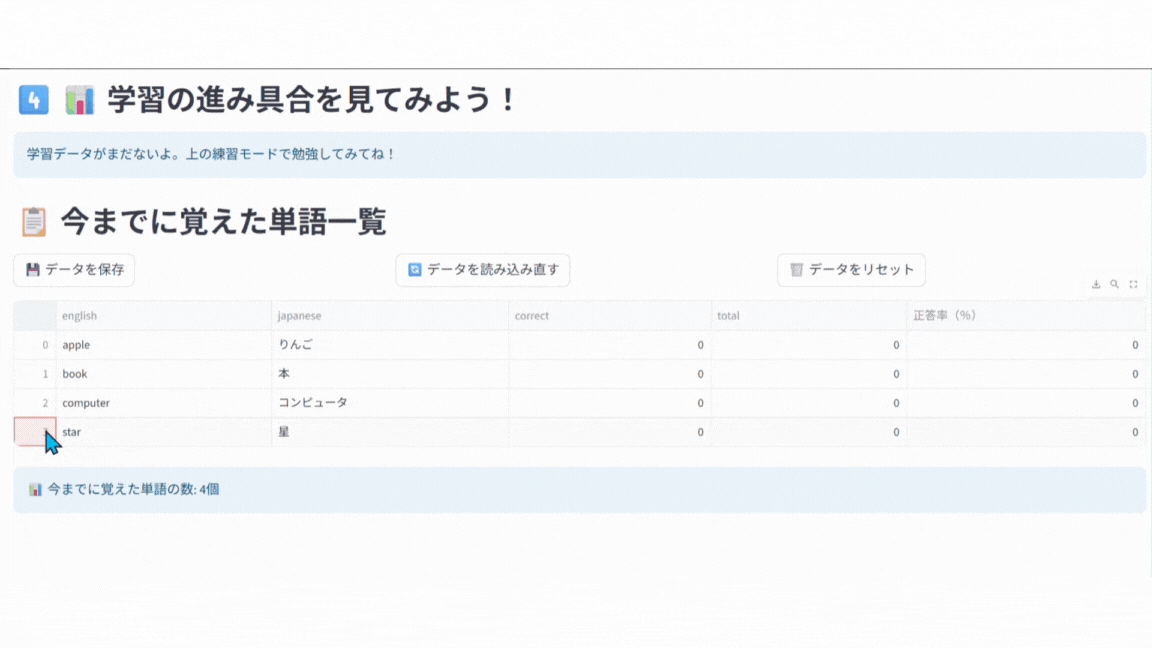

🎉 完成!
画面全体が👇のようになっていれば成功です!

おめでとうございます!
実際に様々な英単語を追加して、AIの難易度予測と学習分析を試してみましょう!!
🎯 まとめ:AI英単語暗記アプリ
このAI英単語暗記アプリでは、以下の重要な技術要素を学びました:
-
CSVデータ管理
- Pandasを使ったデータフレーム操作
- 単語データの保存と読み込み
- データの追加・更新処理
-
機械学習による難易度予測
- 特徴量抽出(文字数、母音数、子音数)
- RandomForestClassifierによる学習
- 新規単語の難易度予測
-
セッション管理
- st.session_stateによる状態管理
- 学習中の単語情報の保持
- ページ更新時のデータ永続化
-
習熟度計算と分析
- 正解率に基づく習得度スコア計算
- 学習履歴のトラッキング
- 習熟度に基づく出題アルゴリズム
🚀 次のステップ
今回学んだAIと機械学習の技術を応用して、以下のような機能を追加してみましょう:
-
自然言語処理 - より高度な単語分析
-
深層学習統合 - より精度の高い難易度予測
-
データベース連携 - より大規模な単語データの管理
-
音声認識 - 発音練習機能の追加
-
ゲーミフィケーション - 学習を楽しくする機能
-
インタラクティブ要素 - 学習体験の向上
- 正解時の演出効果(紙吹雪アニメーション、祝福メッセージ)
- 背景音楽や効果音の追加(正解時のファンファーレ、BGM)
- 英文での問題出題(例:"What is the Japanese meaning of 'beautiful'?")
- 正解時のモチベーション向上メッセージ("Great job!", "Keep it up!")
- スコアに応じた称号システム("Word Master", "Language Expert")
-
マルチメディア対応 - より豊かな学習環境
- 単語に関連する画像表示
- 発音音声の再生機能
- アニメーションによる視覚的フィードバック
- インタラクティブなフラッシュカード
-
学習分析の視覚化 - モチベーション維持
- 学習進捗のグラフ表示
- 週間・月間の学習統計
- 目標達成度のトラッキング
- パーソナライズされた学習アドバイス
などなど、自身が学習継続できるような楽しいアプリを作成してみてください!
🎓 プログラミング学習におすすめ
プログラミング未経験の方には CyTech(サイテック) がおすすめです!
CyTech は、未経験から IT エンジニアを目指す人向けのオンライン学習プラットフォームで、基礎から実務レベルのスキルを最短 10 ヶ月で習得できるカリキュラムを提供しています。
HTML/CSS/JavaScript/PHP/SQL/Git などのプログラミング言語に加え、デザイン、英語なども学べる総合的なプラットフォームです。
今後随時学習できるプログラミング言語増加予定!
エンジニア学習にお困りの方はまずは CyTech 無料カウンセリングでお悩み解消!
Discussion