Rails/MySQL 8パフォーマンスチューニングを経て得た知見とこれから挑戦したいこと
こんにちは、k0iです。
この記事は、Money Forward Engineering 1 Advent Calendar 2023 22日目の投稿です。
前回は@fujiyamaorangeさんの記事でした。
fujiyamaorangeとk0iは同じ福岡拠点、Pay事業本部で働いてます。興味のある方は是非!
はじめに
皆さん、パフォーマンスチューニングは得意でしょうか? 私はとても苦手です......
「推測するな、計測せよ」と巷ではよく言われるものの、VMを使う言語のパフォーマンス解析は難しく[1]、YARVを通して実行されるrubyも一筋縄では行かないですよね。
今回の記事はそんなパフォチュー素人の私がMySQLやRailsのパフォーマンスチューニングを通して得た素人なりの知見と、改善を通して見えてきた来年やりたいことについて書こうと思います。
MySQL 8
Explain Analyzeも見る
重そうなクエリがあった場合、まずは実行計画をチェックすると思います。
簡単なクエリなら実行計画だけでも十分なのですが、Extra欄に下のような
「あ...これ...なんだったっけ...?」
となるような表記がたまに現れたりしますよね。
-
Using Intersect...(Index Merge) -
Using index for group-by (scanning)(Loose Index Scanの特殊系)
そんなときExplain Analyzeを使うと実際にSQLを実行し、かかった時間を計測してくれます。
Long Running Transactionsが発生したとき、idleを意識する
本番環境でLock Wait Timeoutが起きて、確認してみるとtransactionが長時間実行されていた......という事件は稀によくありますよね。
information_schema.INNODB_TRX等を見て原因を特定できない場合、以下の4種類のServer Events[2]を保存しているperformance_schemaを利用する方法があります。
- Transactions ( events_transactions_* )
- Statements ( events_statements_* )
- Stages ( events_stages_* )
- Waits ( events_waits_* )
Transactionは複数Statementsを持ち、Statementsは複数StagesやWaitsに分割されるといったように、これらのEventsには「緩い」親子関係があります。

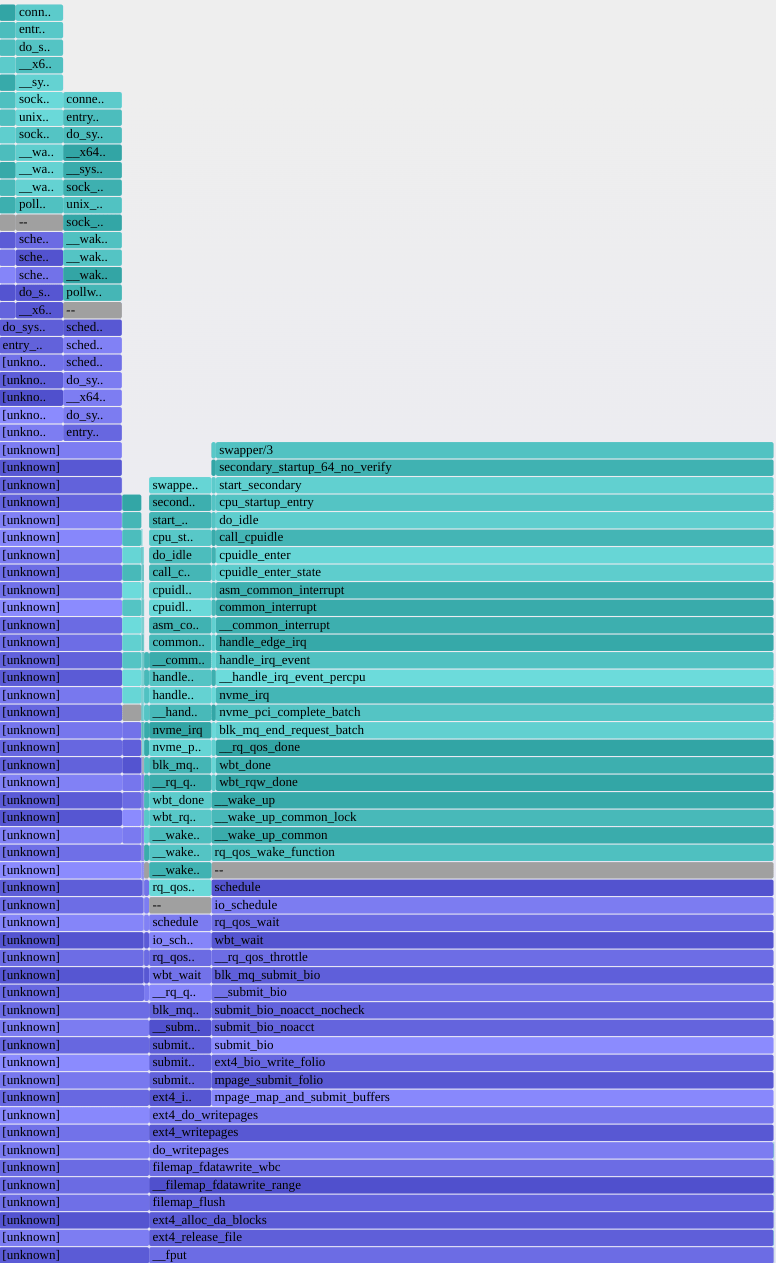
上の画像では、Transaction(Event ID:651332 ~ 651542)が3つのStatementsから構成され、更に各種StatementsがStageやWaitsに分かれています[3]。
つまるところ、このテーブルを頑張って読み解くと、Transactionsがどのように時間を消費したのかを可視化できます。
ここまでの情報だと、
「いやいや、別にこんな面倒なことしなくてもSlow Queryをモニタリングして、適宜改善していけば自ずとtransaction実行時間も改善するでしょ~」
という気持ちになると思います。
ここで注目したいのがEVENT_NAME: idleのWaitsです。
idleというのはMySQL Socketの状態[4]で、clientからrequestが送られてくるのを待っている間に生じます。
Statementを実行した後、responseを返却。次のrequestが来るまでの間なので、Statement中ではなく、Statements間に発生します。
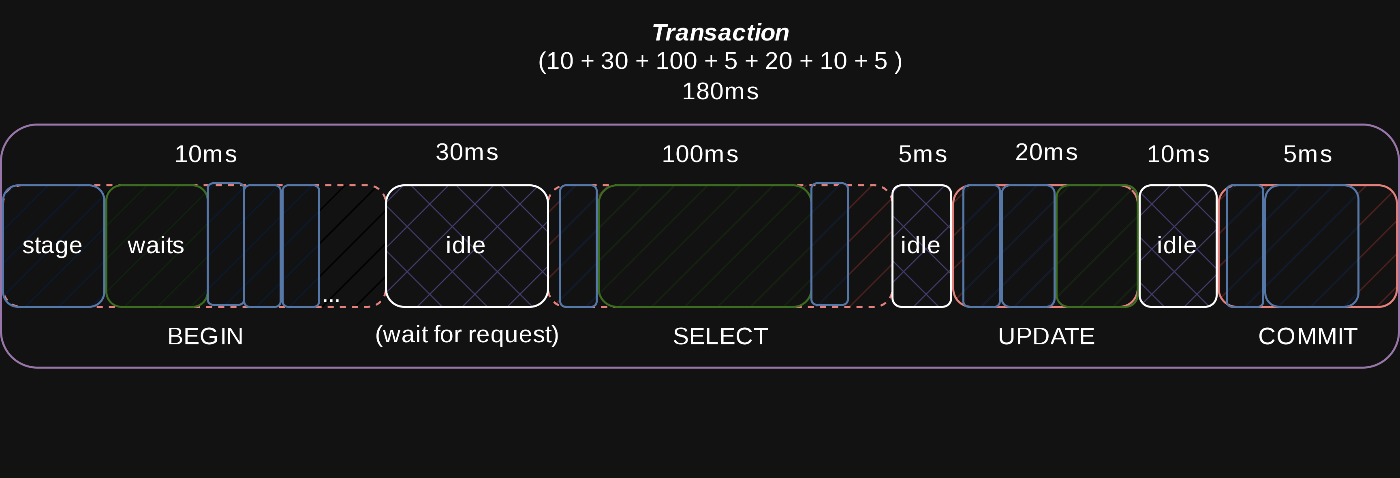
つまり各Statementの実行時間自体は短くても、with_lockの中等で重たい処理をしている場合はその間idle状態になるので、transactionの実行時間も長くなってしまいます。
# accounts_controller.rb
def update
account = Account.find(params[:id])
# mimic heavy logic
fibbonaci = ->(num) {
num < 2 ? num : fibbonaci.call(num - 1) + fibbonaci.call(num - 2)
}
account.with_lock do
puts fibbonaci.call(35)
account.amount += 1
puts fibbonaci.call(35)
account.save
puts fibbonaci.call(35)
end
redirect_to account_path(params[:id])
end
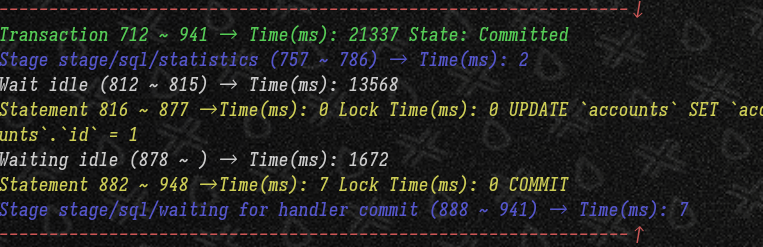
statementsの実行時間は短いものの、idle状態で時間を消費している

Long Running Transactionのせいで後続はtimeoutしてしまった( innodb_lock_wait_timeout=1 )
idleの嫌なところは、重いクエリをモニタリングするだけでは可視化できないところです。
実行時間が長いトランザクションがあり、sys.innodb_lock_waitsで原因の特定が困難な場合は各eventsテーブルを用いてtransactionを可視化すると何かヒントがあるかもしれません。
Rails
rbtraceを使う
本番環境で問題が起こった際、該当箇所をローカルで検証したり、custom spanやtraceに包んで再デプロイすることはよくあるとおもいます。
rbtraceは本番環境での利用が想定されていて、更にRailsの場合Gemfileに入れておくだけでよいので導入が簡単かつ再デプロイすること無くボトルネックの特定が可能です。

100ms以上かかっているメソッドを表示してみる
解決例: CSVエクスポート機能
私の携わっているサービスで、CSVエクスポート機能のパフォーマンスが落ちており、実際にrbtraceを用いて調査しました。
# 100ms以上かかっているメソッドを列挙
rbtrace --pid $RAILS_PID --slow 100
100ms以上かかっているメソッドを列挙してみるとデータをCSV Rowに変換するArray#mapに時間がかかっており、その半分以上の時間をDelegator#method_missingに費やしていました.

確かに該当箇所ではSimpleDelegatorを用いて、CSV用のメソッドを生やしていましたが、SimpleDelegatorにwrapするのが本当にボトルネックなのか...?と疑問に感じたので、rbtraceに--firehoseフラグを渡してメソッドの中をすべてみることにしました。
その結果、Delegator#method_missingの先でActiveRecord::Associations::Association#reloadが呼ばれており、そこに時間がかかっていました。
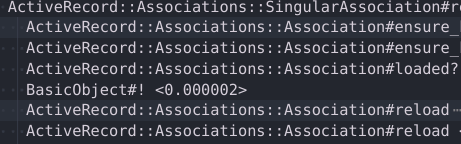
ローカルで当該部分のコードを実行したところ結局はpreload漏れで当該のモデルでN+1が発生していた。というオチでした。
rbperfやoffwaketimeを使って可視化する
rbtrace以外にも、On-CPUなTaskについてはrbperf、Off-CPUなTaskについてはoffcputimeやoffwaketimeを使うことでコードを変更すること無く全体感を把握できます。
sudo su
rbperf record --pid $RAILS_PID --duration 10 cpu
offwaketime -f -p $RAILS_PID > out.stacks
flamegraph.pl --color=chain --countname=us < out.stacks > out.svg
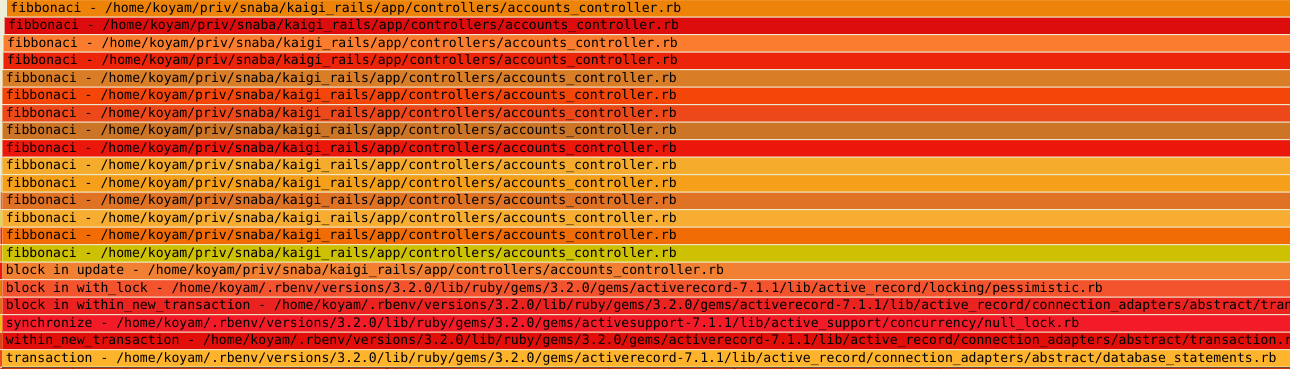
rbperf: fibonacciがCPUを占有している
offwaketime: 左はMySQLへのQuery、右はFile.writeのためにOff-CPUになっている
来年挑戦したいこと
Dynamic Instrumentationの知見を深める
ソフトウェアが実行中に動的にInstrumentation Pointを追加することをDynamic Instrumentationと言います[5]。
チームで監視ツールとして利用しているdatadogはベータ機能としてdynamic instrumentationを用意していますが、残念ながら現状rubyには対応していません。
(rbtrace等素晴らしいツールのお陰で現状全く困ってはいないものの)uprobeを使うことでrubyでもそれっぽいことは可能です。

new_callinginfoにuprobeを設定し、callされた際にmethod_idを出力する

gdb上で確認すると、mid(0x5881)と出力結果(decimal:22657)が一致している
ruby内部のC言語の関数ですが、TracePoint.new{}.enable(target:)ではとれない(とれないよね?)argumentsの中身をpeekできました。:tada: :tada: :sugoi:
とはいえこの方法だとargsがoptimized outされないようにoptflagsをいじらないといけなかったり、一方Static InstrumentationのUSDTはというとこの変更によってTracePointをenableにしないとmethod__entryとmethod__returnを拾うことができなかったりと、結局色々下準備が必要なので中々前途多難な印象....
rbperfはどうやってrubyのメソッド名を引っ張ってきているのか気になるところです。
「ebpfを用いてより効率的にrubyのmethodをinstrumentできると便利やなぁ」とワクワクしているので、来年はrbperfの実装を読んで引き続き知見を深めつつ、rubyのDynamic Instrumentation周りのOSSにコントリビュートしたいなと密かに思っています。
継続的Profilingを導入する
そもそもの話、問題が起きてから調査するのではなく、常日頃から本番環境で継続的にプロファイリングをすることが大切だということを痛感しました。
継続的プロファイリングとは、本番環境で実行中のアプリケーションをプロファイリングすることです。このアプローチにより、本番環境の正確な予測負荷テストとベンチマークの開発が不要になります。継続的なプロファイリングに関する調査で、その高い正確性と費用対効果が証明されています。
https://cloud.google.com/profiler/docs/concepts-profiling?hl=ja
pyroscopeやdatadogのContinuous Profilerを用いて常日頃からデータを蓄積し、決まったスパンでプロファイリング結果を精査し、パフォーマンス改善に繋げていくような習慣を醸成していきたいです。
まとめ
「推測するな、計測せよ」とはよく言うものの今までの私は
- どうせActiveRecordのインスタンス化に時間がかかってるんでしょ~?(見当外れ)
- Qiitaに書いてあった。ここをpluckに直せば早くなる(ならない)
等客観的な指標を欠き、まさに「推測」しながら開発であったり、パフォーマンス改善に臨んで来た部分が少なからずあります。
パフォーマンスチューニングに素人ながら携われたことで改めて「計測」の大切さが身に沁みました。
今一度、この機会に自分の開発への姿勢をしっかりと見直そうと思いました。
-
Virtual machines are typically the most difficult of the language types to observe. By the time the program is executing on-CPU, multiple stages of compilation or interpretation may have passed, and information about the original program may not be readily available.
System Performances, 2nd Edition ↩︎ -
The Performance Schema monitors server events. An “event” is anything the server does that takes time and has been instrumented so that timing information can be collected. In general, an event could be a function call, a wait for the operating system, a stage of an SQL statement execution such as parsing or sorting, or an entire statement or group of statements. Event collection provides access to information about synchronization calls (such as for mutexes) file and table I/O, table locks, and so forth for the server and for several storage engines.
Chapter 1 MySQL Performance Schema ↩︎ -
WaitsやStagesは、1 Statementに対して膨大な量になるため、所要時間が10micro sec以上のものに絞って出力しています。(milli secに直しているので0msになっちゃってますが...) ↩︎
-
The socket status, either IDLE or ACTIVE. Wait times for active sockets are tracked using the corresponding socket instrument. Wait times for idle sockets are tracked using the idle instrument.
A socket is idle if it is waiting for a request from the client. When a socket becomes idle, the event row in socket_instances that is tracking the socket switches from a status of ACTIVE to IDLE. The EVENT_NAME value remains wait/io/socket/*, but timing for the instrument is suspended. Instead, an event is generated in the events_waits_current table with an EVENT_NAME value of idle.
When the next request is received, the idle event terminates, the socket instance switches from IDLE to ACTIVE, and timing of the socket instrument resumes.
10.3.5 The socket_instances Table ↩︎ -
Dynamic instrumentation creates instrumentation points after the software is running, by modifying in-memory instructions to insert instrumentation routines.
System Performances, 2nd Edition ↩︎
Discussion