Datadog で Agent Check の WARNING・ERROR ステータスを Monitor で通知したい Scrap
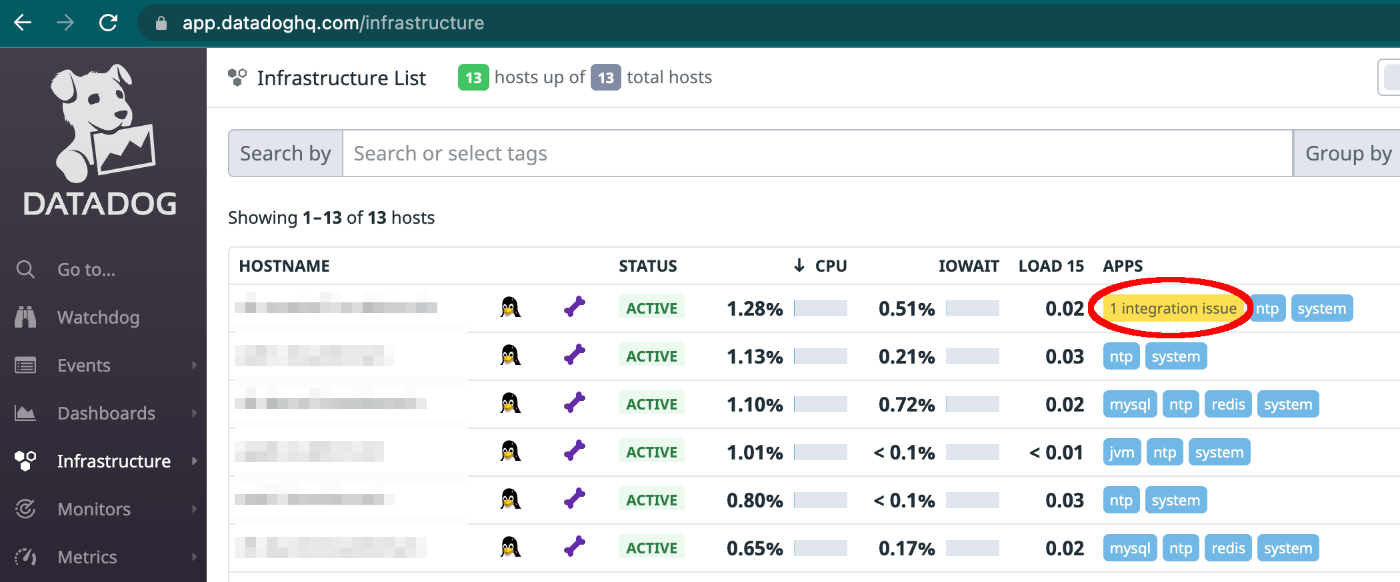
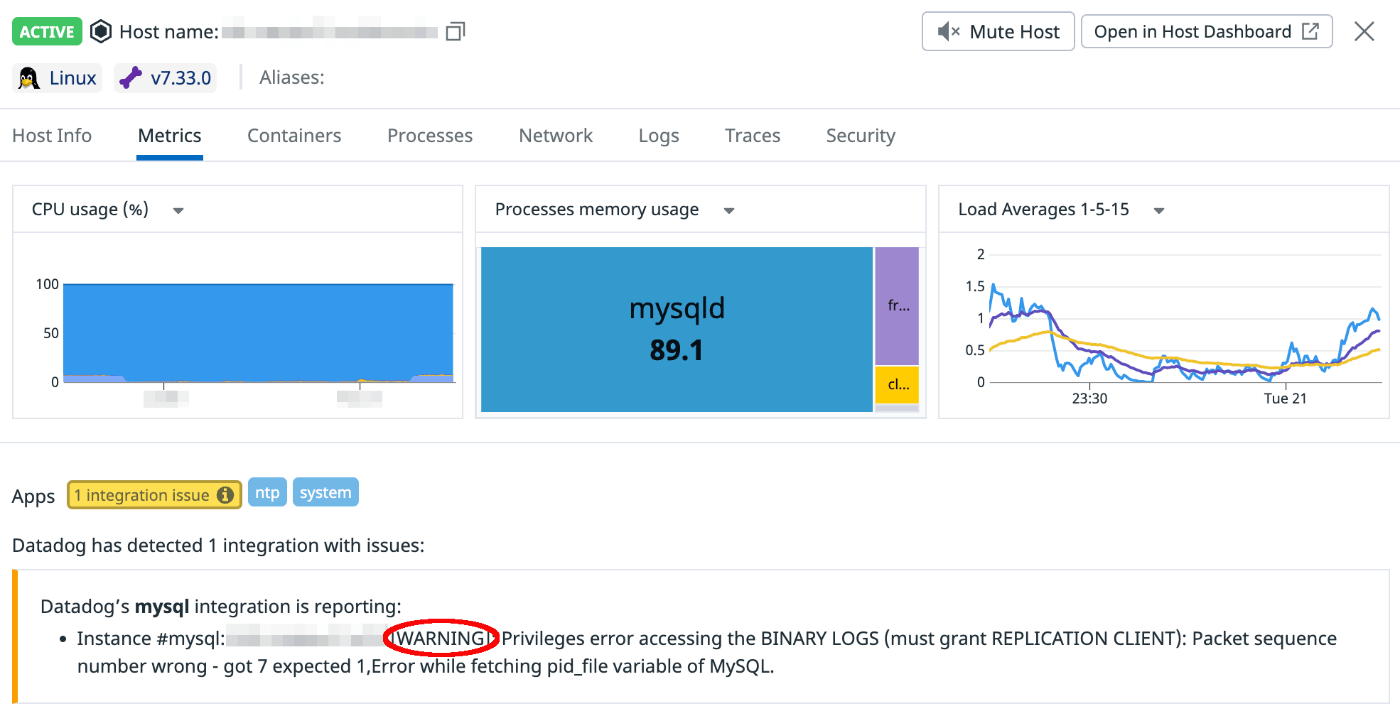
datadog.agent.up ではないんだよな・・・
sudo datadog-agent status すると WARNING が確認できるんですが・・・
問題が続く場合は、フレアで Datadog のサポートチームにご連絡ください ってかいてますがそういうことじゃなくて、 status が OK じゃないことを自分達に通知したいんですよ・・・
↓のような、ログにWARNINGやERRORを書き出して、そこから通知させるような、ちょっと頑張った手法でないと通知が実現できないのでしょうか。。。
Monitor から、拾う設定をどう組んでいけば、希望する検知ができるのかを知りたいです。。
見回した情報は↓ですが、「これだ」と思えたものは残念ながら「ない」と思っています。。
でログを datadog に転送して
で WARNING を拾う作戦
挙動の確認(サポートに聞いている)
- 指定ログのチェック頻度設定
- どれくらいの間隔で サーバー(?) に送ってるのか
- ログを上書きにしても内容をサーバーに送信するのか?
- 大した出力量ではないが蓄積時にディスク容量を圧迫するのを心配して、ログファイルを「上書き型」にしようと思っている。問題ないか
(↓と同じ)
- 指定ログのチェック頻度設定
- どれくらいの間隔で サーバー(?) に送ってるのか
ログの送信間隔は、固定の送信間隔があるというわけではなく、ほぼリアルタイムに送信が実施される、とのこと。
refs
- ログを上書きにしても内容をサーバーに送信するのか?
- 大した出力量ではないが蓄積時にディスク容量を圧迫するのを心配して、ログファイルを「上書き型」にしようと思っている。問題ないか
ログは tail して送信するようなので、おそらく「問題ある」(ちゃんと検知されない、かも)。
ログローテーションをちゃんと考えて設定・運用する必要がありそう。
参考情報として、agent.log 減らしたい場合は log_processing_rules のパラメータを調整して不要なログレベルの項目を除外できるらしい。
refs
チェック頻度もそんなに高くない(1時間に1回、を今のところ想定)が、ログ送信にかかる料金が少々心配なので、アプローチを変えてみる。
カスタムメトリクスを↑の頻度で送信する、だとどうか。
この場合、スクリプトを組む必要はある。大したプログラムにはならない予想だが・・・
頻度低め(1時間に1回)でカスタムメトリクスを送る、作戦
そもそもカスタムメトリクスとは何ぞ、から。(Mackerel で少々心得はあるつもり)
気になるのは料金。Logs よりはかかるまいと想定。
スクリプトの書き方は↓を見るのかな
カスタムメトリクスの課金体系について問い合わせ
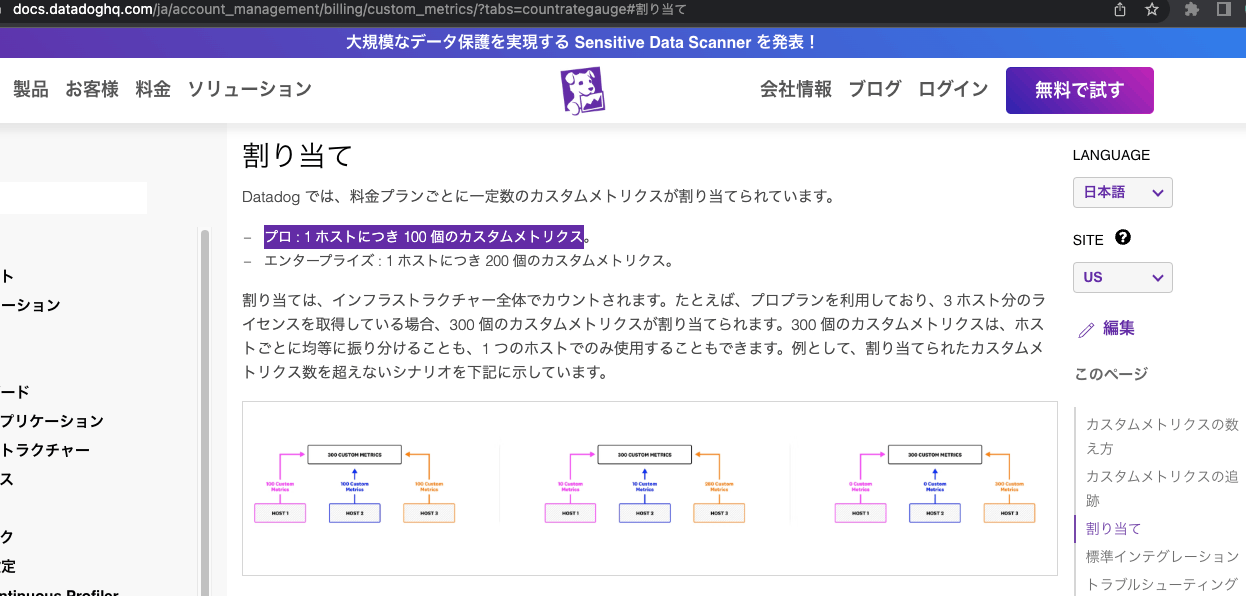
- 「プロ : 1 ホストにつき 100 個のカスタムメトリクス」となっているのですが、現時点でいくつのカスタムメトリクスが使用されているのかを確認する方法はあるでしょうか。
- 「100 個のカスタムメトリクス」を超過した場合の料金体系はどのようになっているのでしょうか。
datadog-agent status -j で得られる出力の
- runnerStats
- Checks
- cpu
- disk
- file_handle
- http_check
- io
- load
- memory
- mysql
- network
- ntp
- uptime
- Checks
のような 各 check の配下に mysql:XXXXXXXXXXXXXXXX # 16桁
みたいに コンポーネント:識別名:ID という感じで階層があってこの配下に [1]
- LastError
- LastWarnings
- TotalErrors
- TotalWarnings
という項目がある。
TotalWarnings > 0 だったら 1
TotalErrors > 0 だったら 2
という感じで、Error・Warning があるかどうかのカスタムメトリックを作れそう。
このフォーマット公開されてないかなあ・・・
変わったらスクリプトも調整しなけりゃならなくなるところが懸念
(まず変わらないだろうとは予想するというかとりあえず願う)
さあいってみようか。
-
「識別名」は、各チェック(たとえば http_check)が複数ある場合に入るみたい ↩︎
Error・Warning があるかの判定スクリプト
import sys,json,pprint
ERROR_EXIST = 2
WARN_EXIST = 1
pp = pprint.PrettyPrinter(indent=2)
with open(sys.argv[1], "r") as file:
dict = json.load(file)
ret = {}
errors = []
warnings = []
checks = dict["runnerStats"]["Checks"]
for check_name, check_results in checks.items():
#pp.pprint(check_name)
for check_id, check_values in check_results.items():
#pp.pprint(check_id)
for key, value in check_values.items():
if key == "TotalErrors":
if value > 0:
ret["check_status"] = ERROR_EXIST
errors.append(check_id)
elif key == "TotalWarnings":
if value > 0:
if ret["check_status"] != ERROR_EXIST:
ret["check_status"] = WARN_EXIST
warnings.append(check_id)
ret["errors"] = errors
ret["warnings"] = warnings
pp.pprint(ret)
結果サンプル
{ 'check_status': 2,
'errors': ['cpu', 'mysql:XXXXXXXXXXXXXXXX'],
'warnings': ['cpu']}
try-catch で強化版
import sys,json,pprint
ERROR_EXIST = 2
WARN_EXIST = 1
EXCEPTION_OCCUR = -1
pp = pprint.PrettyPrinter(indent=2)
with open(sys.argv[1], "r") as file:
dict = json.load(file)
ret = {}
errors = []
warnings = []
try:
checks = dict["runnerStats"]["Checks"]
for check_name, check_results in checks.items():
for check_id, check_values in check_results.items():
for key, value in check_values.items():
if key == "TotalErrors":
if value > 0:
ret["check_status"] = ERROR_EXIST
errors.append({check_id:check_values["LastError"]})
elif key == "TotalWarnings":
if value > 0:
if ret["check_status"] != ERROR_EXIST:
ret["check_status"] = WARN_EXIST
warnings.append({check_id:check_values["LastWarnings"]})
ret["errors"] = errors
ret["warnings"] = warnings
except Exception as e:
ret["check_status"] = EXCEPTION_OCCUR
ret["exceptions"] = repr(e)
pp.pprint(ret)
コードをまとめた
カスタムメトリクスが取れれば、Monitor は容易に設定できると思う。
TotalWarnings > 0 だったら 1
TotalErrors > 0 だったら 2
のような判断だと、過去のエラーを拾ってしまって発報するので考え直している。
LastError が ""
LastWarnings が []
を基準にしてはどうか、と考えているのだが、リセットタイミングが不明なので問い合わせると同時に
ソースを追う。
が、Go ヨクワカラナイ ので、↓の c.Run() の中身はどこにいくのかがわからず・・・
Check ごとに Run の内容が違いそうではある・・・
datadog-agent 7.38.0 以降から(2022/8/14時点の最新は 7.38.2)、どうもカスタム Agent Check が機能しなくなってしまっていることに気がついて issue を上げた。
7.37.1 では期待動作する。
Contact Support にも投げたが、コメント入るのは月曜になってからと予想している。
相変わらず、リセットタイミングが不明で困っている中でこうなって、気分的にはしんどい。。
Amazon Linux WorkSpaces 環境、だいたい毎週日曜未明に強制アップデートがかかるので、
そのたびにダウングレードしないと Alert 発報される(No data)
ダウングレード手順は
- sudo yum remove -y datadog-agent
- ansible-playbook -c local site.yml -K
- (site.yml は↓のような内容。前提として
ansible-galaxy install datadog.datadog実行済みで ~/.ansible ディレクトリにいる、と想定)
- (site.yml は↓のような内容。前提として
- hosts: localhost
roles:
- { role: datadog.datadog, become: yes }
vars:
datadog_api_key: "${YOUR_API_KEY}"
datadog_agent_version: "7.37.1"
TotalWarnings > 0 だったら 1
TotalErrors > 0 だったら 2のような判断だと、過去のエラーを拾ってしまって発報するので考え直している。
これ、そんなことなくて、発生してはすぐにおさまるエラーだったための勘違いだった。
他の方法もあるようだけど、
"datadog.agent.check_status".over("*").by("check","host").last(6).count_by_status()
の Query で Monitor して、細かいエラーを拾ってしまうのには、Trigger the alert after selected consecutive failures: を MAX の 5 にして(5分続いたら通知、になる)、それでも発報するようであれば Renotification (再通知) での長め間隔の通知にする、という方針に収まりました。