こんにちは、terandard です。
今回は Datadog の Monitor で API のレイテンシーを監視しようとした際にハマった話を書きます。
監視を入れた背景
弊社のバックエンドチームでは定期的に「Datadog を見る会」を開催しており、Datadog のダッシュボードや APM を見てサービスのパフォーマンスを確認しています。
普段 APM を見てパフォーマンスを確認する際は P90 Latency などの指標から異常がないかを見ています。通常よりもレイテンシーが高い場合は Trace で詳細を確認しています。
Trace では以下のように Duration が表示されているので、Duration の値が高いリクエストについて詳細を確認して原因を特定しています。
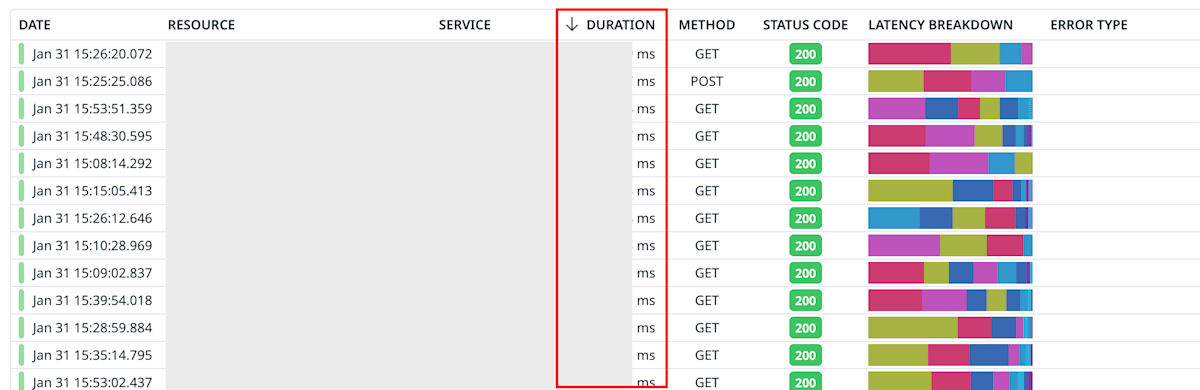
しかし普段の開発もあるので「Datadog を見る会」の時間も限られています。そのため利用頻度が高い API や最近リリースしたものなどを優先して確認しており、利用頻度が低い API などは見れていませんでした。
実際にデータ量が増えたことで意図せず遅くなっているケースがあり、「Datadog を見る会」以外でもパフォーマンス悪化に気付けるようにしたいという課題感がありました。そこで API のレイテンシーについて監視を入れて、遅いリクエストがあればアラートを出して気付けるようにしました。
今回作成したい監視設定
元々 Nginx の接続がタイムアウトした場合 (499 Client Closed Request) にはアラートが飛ぶようになっていました。しかし、前述のデータ量増加による遅延は 20 秒程度で、レスポンス自体は返すことができておりアラートは飛びませんでした。
今回はこのようなケースに気付けるように、特定のリクエストで最大 n 秒以上かかる場合にアラートを出したいです。
弊社のサービスではソーシャルログインや LINE 配信など、外部リクエストの影響で 1 秒以上かかるエンドポイントがあります。閾値が低すぎるとアラートが頻繁に飛ぶ可能性があるので、今回は以下の基準を参考に閾値を 10 秒として設定しました。
- 0.1秒:システムが即時にレスポンスしていると感じる時間(結果を表示する以外に特段行うべきことはない)
- 1.0秒:ユーザーの思考が邪魔されないと感じる限界の時間で、これ以上は遅延を感じ始める。
- 10秒:ダイアログを出しているときにユーザーに対して注意を引く時間の限界。「処理中」を表すインジケータの表示時間
Datadog の Monitor で API のレイテンシーを監視する
弊社では Terraform で Datadog の監視設定を管理しています。しかし query の条件などをいきなり書くことは難しいので、UI で作成して export することにしました。
早速 Datadog の Monitor で監視設定を作ってみます。
普段の運用から「おそらく Duration に関するメトリクスがあるだろう」と思いフォームに入力すると trace.rack.request.duration が出てきました。
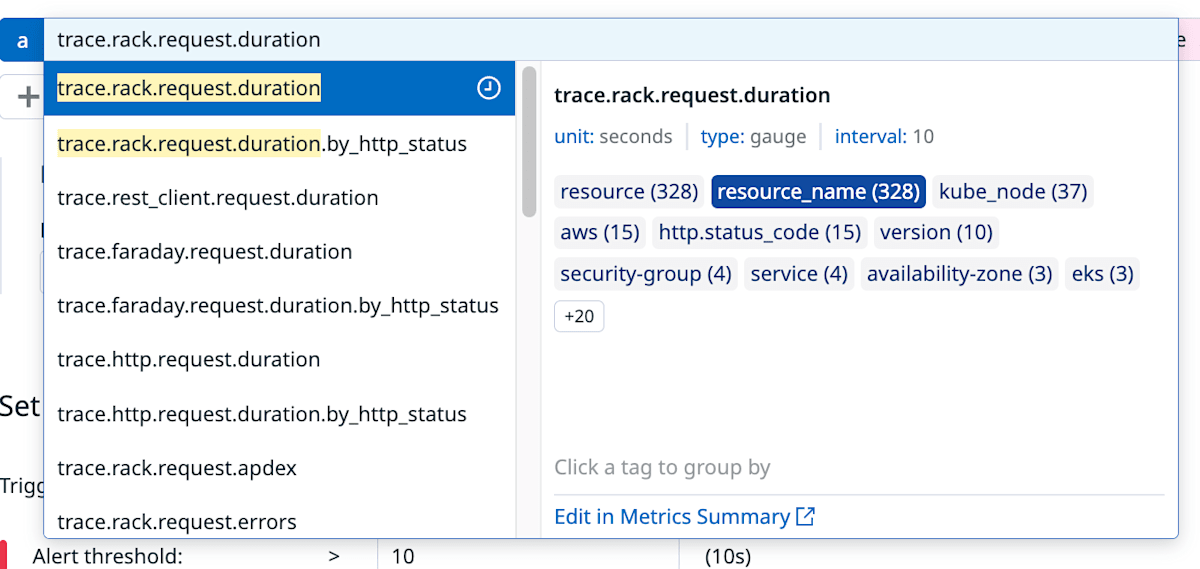
これの Max を監視することで、最大10秒かかるリクエストがあればアラートを出せそうだと考えました。
エンドポイント毎にアラートを設定したかったので、max_by resource_name を使いました。表示されているグラフを見てみるとそれっぽいものになっており、良さそうです。
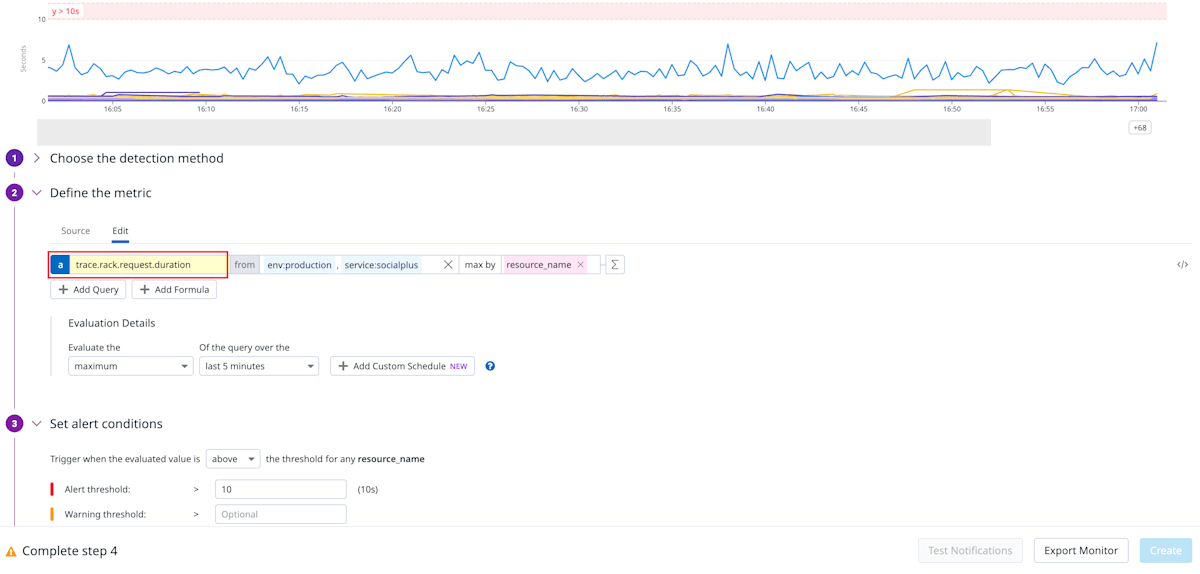
しかし普段より高いレイテンシーとなっており、APM の Trace と照らし合わせると該当するリクエストが見つかりませんでした。
Duration について
ここでドキュメントを見てみると、Duration について以下のように記載されていました。
trace.<SPAN_NAME>.duration
収集サービスで見られる子スパンを含む、時間間隔内のスパンのコレクションの合計時間を測定します。
Duration は合計時間を測定するため、一定の時間内に大量のリクエストがある場合はその分だけ増加します。表示されたグラフの値が Trace と合致しなかったのはこのためでした。
今回は特定のリクエストで最大 10 秒以上かかる場合にアラートを出したかったので、Duration は使用できませんでした。
最終的に作成した監視設定
Duration 以外のメトリクスを調べてみると trace.rack.request がありました。
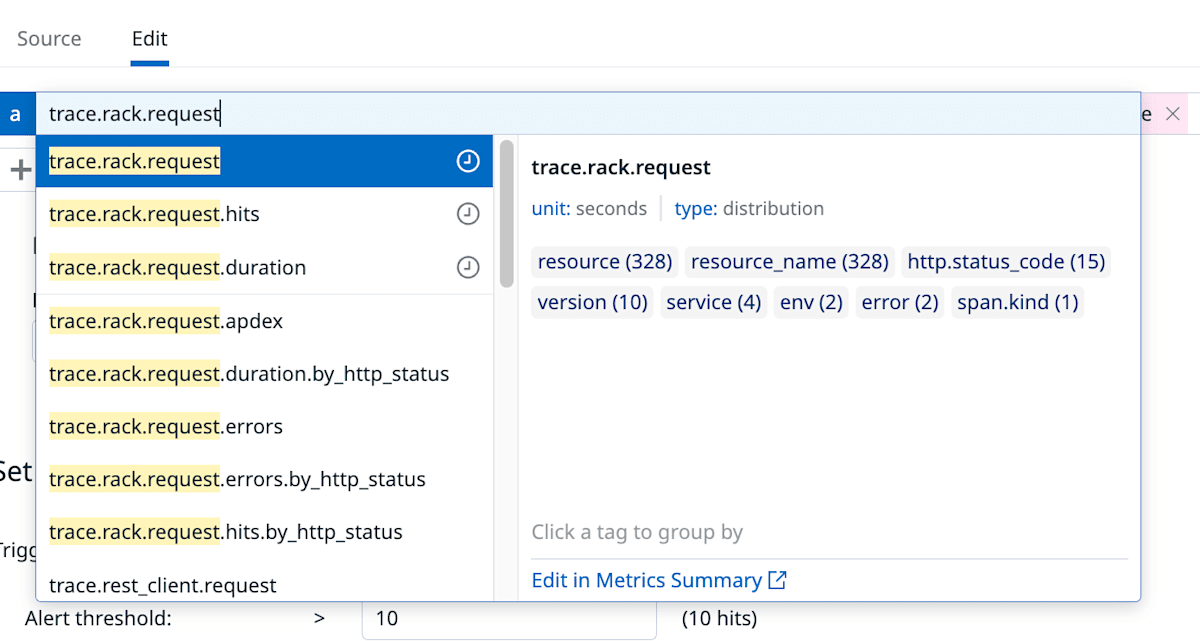
日本語のドキュメントには記載がありませんでしたが、英語版のドキュメントには以下のように記載されています。
trace.<SPAN_NAME>
Represent the latency distribution for all services, resources, and versions across different environments and second primary tags.
表示されているグラフを見てみると、trace.rack.request.duration よりも低い値になっており、APM の Trace と照らし合わせると該当するリクエストが見つかりました。従ってこちらのメトリクスで良さそうです。

これで export して Terraform に反映し、API のレイテンシーを監視することができるようになりました。
まとめ
Duration は合計時間を測定するため、一定の時間内に大量のリクエストがある場合はその分だけ増加します。そのため、特定のリクエストのレイテンシーを測定したい場合は使用できません。
trace.<SPAN_NAME>.duration
収集サービスで見られる子スパンを含む、時間間隔内のスパンのコレクションの合計時間を測定します。
今回のような用途では trace.rack.request を使用しましょう。
またドキュメントはしっかり読みましょう。日本語のドキュメントには記載がない場合があるので、英語版も見てみると良いかもしれません。

Discussion