こんにちは、terandard です。
弊社では Datadog を用いてアプリケーションやサーバーの監視を行っています。
以前からリクエストがスパイクした際にアプリケーション全体が遅延する問題があったので、Datadog Continuous Profiler を使用して調査したことについて紹介します。
背景
リクエストがスパイクするとアプリケーション全体が遅延する問題がありました。

リクエスト全体のリクエスト数とレイテンシー
特に処理に時間がかかっていたリクエストについて Datadog APM で状況を確認すると、下図のように空白期間があったり mysql2 や faraday の実行時間が長いことがわかりました。

例1: 謎の空白期間がある

例2: mysql2 の実行時間が長い、HTTP リクエスト以前の faraday の実行時間が長い
しかし RDS のスロークエリログを確認しても遅いクエリはなく、アプリケーション側での問題であることがわかりました。
これ以上は情報が無く、どこに問題があるのかわからない状態でした。
そこで RubyKaigi2024 で Datadog の Profiler についてのセッションを聞き、Continuous Profiler を試してみることにしました。
Datadog Continuous Profiler とは
CPU 使用率やメモリなどの情報がメソッド単位で可視化されるので、ボトルネックの調査に利用できます。さらに Trace と紐づいているので、特定のリクエストについてどのメソッドにリソースを割いているかが分かるようになります。また同時刻の他の puma スレッドの情報も確認することができます。
導入における負荷のオーバーヘッドは低く、実際に試したところ CPU 使用率が 2~3% 増加した程度でした。
Datadog Continuous Profiler を用いて調査
再度処理に時間がかかっていたリクエストについて、Datadog Continuous Profiler で詳細を調査しました。特に前述した空白期間や mysql2 などの実行時間が長い時間帯に何が起きているかを確認しました。
すると、下図のように CPU リソースをほぼ使用していないことがわかりました。CPU リソースを使用していないので、その時間帯は Ruby コードを実行していないことになります。

特定のリクエストにおけるプロファイル結果
そこでその時間帯の他のスレッドの情報を確認すると、別のスレッドが Ruby コードを実行していることがわかりました。つまり他のスレッドで Ruby コードを実行しているため、このスレッドは Ruby コードを実行できない状態になっていました。
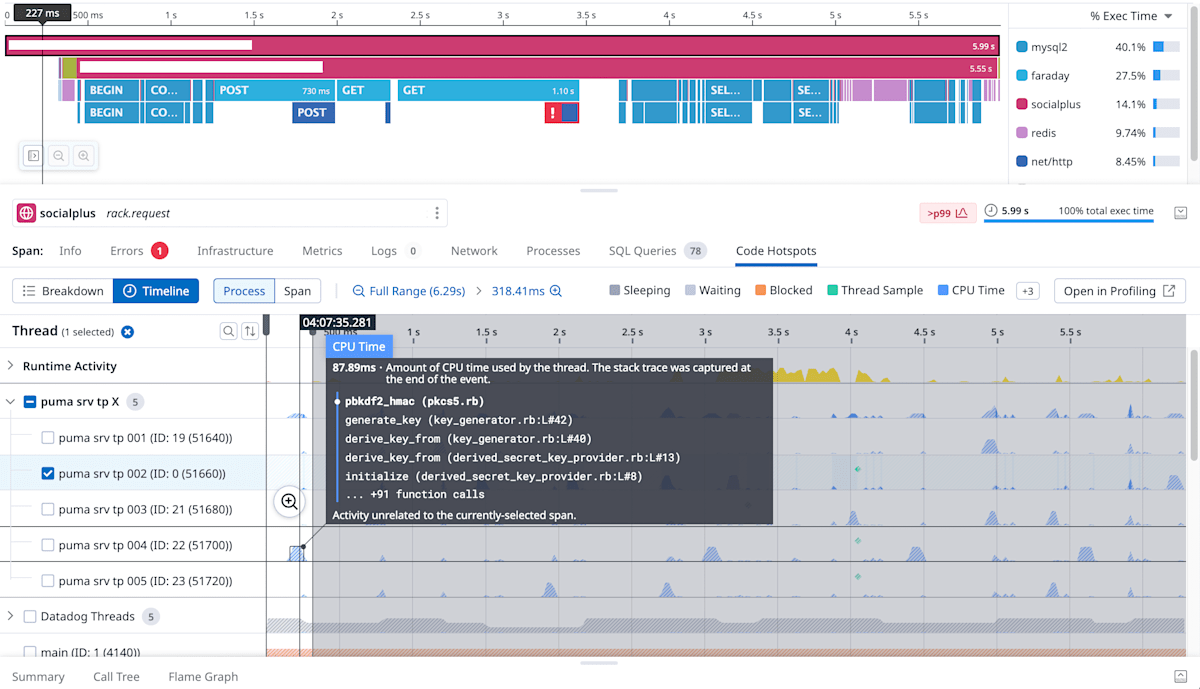
puma の別スレッドを含めたプロファイル結果
これは Ruby の Global VM Lock (GVL) という仕組みによるものです。
Ruby の GVL について
複数のスレッドが同時に処理を行う際、互いに影響を及ぼす可能性があります。
これを防ぐために Ruby では Global VM Lock (GVL) という仕組みを用いて、一度に1つのスレッドしか Ruby コードを実行できないようにしています。
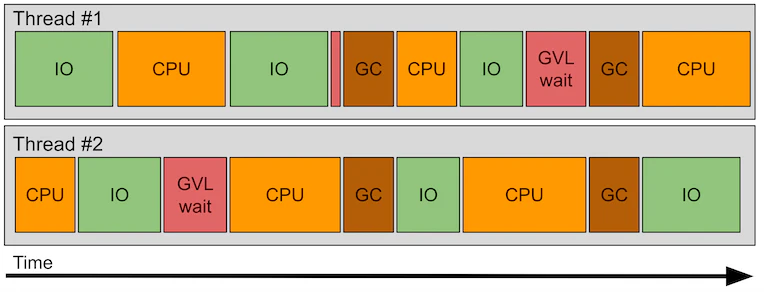
参考:https://shopify.engineering/ruby-execution-models
リクエストが増えると、複数のスレッドで処理する割合が増えてきます。
すると複数のスレッドで処理する際に GVL のせいで待ち時間が増えるため、全体的にリクエストが遅延していました。
対策
原因が分かったので、いくつか対策を検討しました。
- 時間がかかっている処理を高速化する
- puma のスレッド数を減らす
- サーバの台数を増やす
1. 時間がかかっている処理を高速化する
そもそも処理に時間がかかっているから他のスレッドを待たせているので、高速化することで GVL の影響を減らすことが期待できます。
Profiler によって今回処理に時間がかかっていたところは自分たちで実装したロジックであることがわかりました。そこでロジックを見直して高速化することにより、リクエスト全体の処理時間を 4 倍高速化することができました。

改善対応リリース前後のリクエスト全体のレイテンシー
また現在 Ruby 3.2 を使用しているので、Ruby 3.3 に上げて YJIT による高速化も検討しています。
2. puma のスレッド数を減らす
スレッド数が多いため GVL の影響を受けやすいと考え、スレッド数を減らすことで GVL の影響を減らすことが期待できます。
Rails 7.2 から puma のデフォルトスレッド数が 5 → 3 に変更される予定なので、それに合わせてスレッド数を減らすことも検討しています。
3. サーバの台数を増やす
サーバの台数を増やすことでマルチスレッドで処理する割合が減り、GVL の影響を受けにくくなることが期待できます。
元々頻繁にスケールアウトしていたのでインフラチームに相談し、デフォルトのサーバの台数を増やしてもらいました。デフォルトのサーバの台数を増やした後は負荷が分散され、スケールアウトする頻度も減りました。
まとめ
Datadog Continuous Profiler を用いて Ruby の GVL によるボトルネックを発見し、対策を行うことでリクエスト全体の処理時間を 4 倍高速化することができました。
またリクエストがスパイクした際にアプリケーション全体が遅延する問題も解消し、ユーザーにより良い体験を提供できるようになりました。
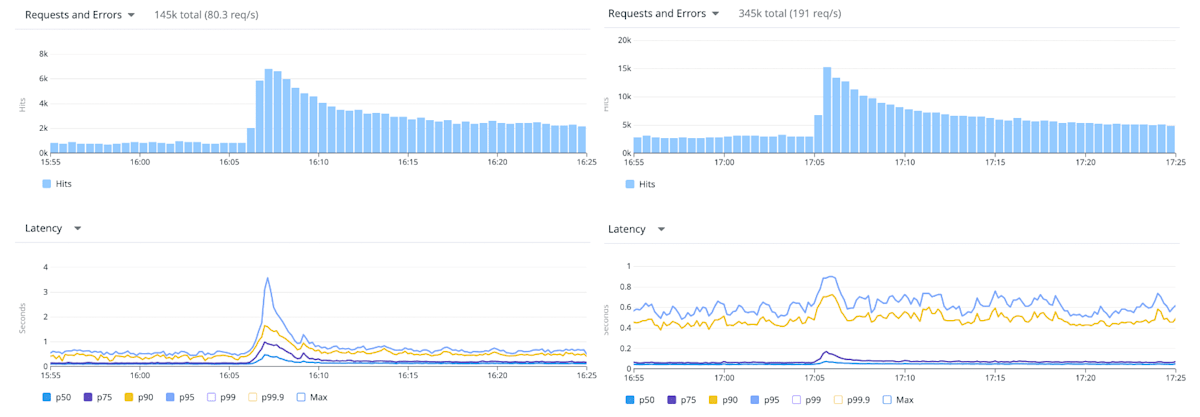
パフォーマンス改善前後におけるスパイク発生時のレイテンシー比較
今回の経験を通して、Datadog Continuous Profiler はアプリケーションのボトルネックを発見するのに非常に有用であることがわかりました。
一方で Profiler を用いてボトルネックを発見しても、それが何故発生するかについて説明するにはより専門的な知識が必要だったので、今後も学習を続けていきたいと思います。
参考
- Continuous Profiler | Datadog
- To Thread or Not to Thread: An In-Depth Look at Ruby’s Execution Models|Shopify Engineering
- Optimizing Ruby: Building an Always-On Production Profiler | RubyKaigi 2024
- Set a new default for the Puma thread count · Issue #50450 · rails/rails
- Rubyのスケール時にGVLの特性を効果的に活用する(翻訳)|TechRacho by BPS株式会社

Discussion