ドーモ、株式会社ソーシャルPLUS CTO の サトウリョウスケ (@ryosuke_sato) です ✌︎('ω')✌︎
弊社では Ruby on Rails で実装された Web サービスが 4 つあり、いずれも kubernetes (以下 k8s) でコンテナを管理しています。 k8s で管理するようになってから暫くはオートスケーリングさせずに Node や Pod の台数を固定して運用していたんですが、昨年の後半から徐々にオートスケールを使った運用にシフトさせて行きました。
puma や nginx といった pod は特に問題なくオートスケールできていたんですが、 sidekiq の worker pod だけはスケールイン・アウトが安定せず、ジョブの queuing が少しスパイクするとすぐに MAXPODS の台数 (弊社の場合は 100 台) まで増えてしまい、 DB や Redis へのアクセスが集中することでサービス全体が不安定になる、という状態が続いていました。
色々と課題について整理して対応していったところ、ようやく安定稼働させることが出来るようになったのでブログで紹介させて頂きたいと思います。
オートスケールさせたら大変なことになった
冒頭で触れた通り Sidekiq worker の Pod に HPA (HorizontalPodAutoscaler) を設定したら、ちょっとジョブが溜まっただけですごい勢いでスケールアウトするようになりました 😇
- 変更前
- Sidekiq Worker Pod 数は固定 (18台)
- 実行戦略は Priority (優先度) を定義し、実行が遅れても良いジョブとそうでないジョブで分ける
- 優先度の低い queue の worker は、優先度の高い queue の処理も受け持つ
- 変更後
- ジョブの待ち数に応じて Pod 数を増減 (MINPODS 3 / MAXPODS 100)
- 実行戦略は変更なし
- 何が起こったか
- 少しの負荷で Pod 数が最大値まで増えてしまう
- 最大 100 pods まで増えるので RDS の負荷が高騰し、サービス全体が不安定になる
Sidekiq の実行戦略というのは sidekiq.yml に設定するこういうやつです:
---
queues:
- high
- default
- low
例えば夜間バッチ処理で実行するようなジョブは queue_as :low という風に定義して、他に優先するジョブがある場合はそちらが先に処理されるようにしていました。
class MyBatchJob < ApplicationJob
queue_as :low
end
元々は sidekiq worker の Pod 数が固定だったので、ジョブが queue に溜まった時に優先度の高いジョブが滞らないよう、各 queue の worker は以下のように動作するようにしていました:
- high-queue-worker:
- high-queue のジョブのみ実行
- default-queue-worker:
- high-queue, default-queue のジョブを実行
- low-queue-worker:
- high-queue, default-queue, low-queue のジョブを実行
この戦略のまま HPA を設定するとどうなったかというと、全ての queue の処理を担当する low-queue-worker が心電図のようなグラフを描くオートスケーリング無双が始まったのです ⚔️
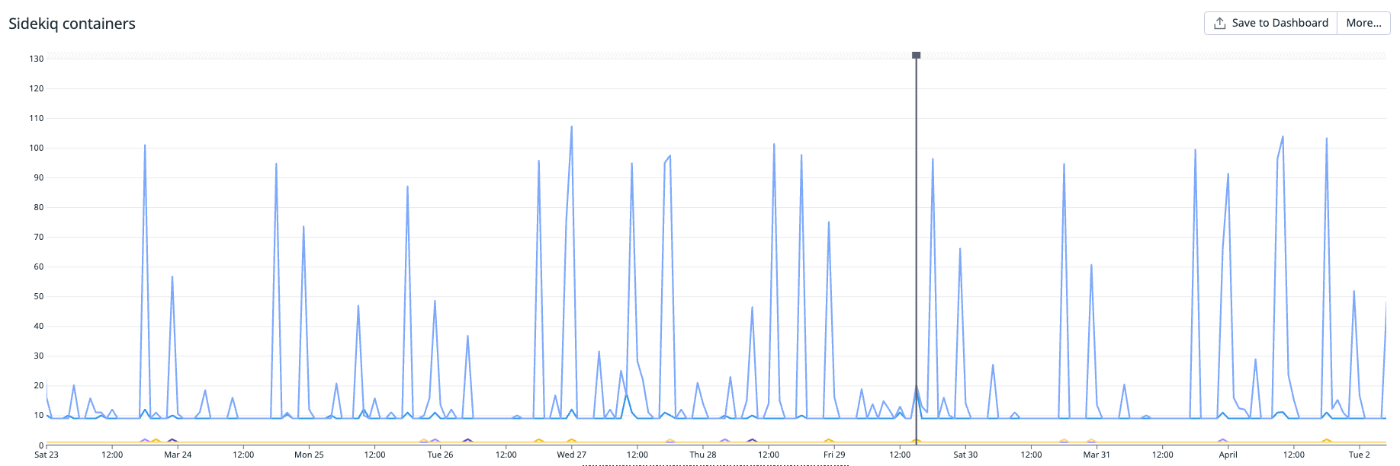
どうしてこうなった /(^o^)\
HPA の振る舞いが想定と違っていた
公式ドキュメントによると HPA のアルゴリズムは以下のように定義されています:
アルゴリズムの詳細
最も基本的な観点から言えば、HorizontalPodAutoscalerコントローラーは、理想のメトリクス値と現在のメトリクス値との間の比率で動作します:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]たとえば、現在のメトリクス値が
200mで、理想の値が100mの場合、レプリカの数は倍増します。なぜなら、200.0 / 100.0 == 2.0だからです。現在の値が50mの場合、レプリカの数は半分になります。なぜなら、50.0 / 100.0 == 0.5だからです。コントロールプレーンは、比率が十分に 1.0 に近い場合(全体的に設定可能な許容範囲内、デフォルトでは 0.1 )には、任意のスケーリング操作をスキップします。
実はもう少し下まで読むと behavior フィールドという項目があり、スケールイン・アウトの細かい設定はそちらで定義すると書かれています。当初 spec.behavior の設定は意識していなかったんですが、デフォルトだと 15 秒間隔でスケールイン・アウトが実行される設定になっています:
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
15 秒だと sidekiq worker pod が立ち上がってからジョブが消化される前に次のスケールアウトが実行されてしまう可能性が高いです。
閾値となる「ジョブの待ち数」の設定が難しい
「ジョブの待ち数」は queue に入れられてから処理が始まっていないジョブの数です。ラーメン屋で例えると、まだ入店できずに外で並んでいるお客さんの数です。行列が一定の閾値を超えるとスケールアウトが始まります 🍜
例えば 10k を閾値とした場合、5k のジョブがキューイングされてもスケールアウト対象とはなりません。むしろ閾値より小さいので MINPODS で定義されている数までスケールインされるはずです。一方で、突発的に 100k のジョブがキューイングされると、一気に 10 倍の pods 数までスケールアウトしようとするはずです。実際には Node が足りずに徐々にスケールアウトする動作になるんですが、最終的には MAXPODS まで増えてしまいます。
じゃあ適切な値はどこなのか?となるんですが、それはアプリケーション側の実装に大きく依存するので実測してみないと正直わからないです。ラーメン屋の例えで言えば、入店して5分で食べ終わる客もいれば、1時間経っても食べ終わらない客もいるので、 10 人以下の行列なのにいつまで経っても入店できない、というケースも考えられます。
一度調整しても、新しい機能を追加した際に再度調整が必要になる可能性もあります。
sidekiq worker pod のオートスケールは特殊
Sidekiq worker 以外にも puma や nginx もオートスケールに対応させていますが、こちらは CPU やメモリの使用率を指標としたオートスケールで問題なく動作してくれました。そもそも k8s でオートスケールさせる対象って puma や nginx みたいなプロセスを想定して作ってあると思うんですよね。 puma も nginx もリクエストからレスポンスを返すまでが基本数秒以内で、どんなに長くても 60 秒でタイムアウトするようになっています。Pod にかかる負荷から何倍にスケールアウトさせれば良いかが分かりやすいです。
一方で sidekiq worker は、実行されるジョブの実装によって CPU やメモリの使用率が大きく異なるため、これらをオートスケールの指標にしても期待する動きになってくれません。それに元々非同期に処理されることが前提なので、 多少の遅れは許容できるが、極端な遅れ (所謂 queue が詰まった状態) は許容できない というアプリケーションレイヤーの指標が必要になってきます。
程よく良い感じに queue に積まれたジョブを捌く必要がある、という何ともふんわりした要件なので、適切な sidekiq worker pod の数を定義するのが難しいと思います。
現状の実行戦略もオートスケールと合っていない
前述の「優先度の低い queue の worker は、優先度の高い queue の処理も受け持つ」という振る舞いは pod 数が固定であるが故に採用していた戦略です。負荷に応じてオートスケールできるなら、他の queue の処理を受け持つ必要はもう無いですよね。
加えて、現状だとジョブの実装が 100 種類近くあったりするので、その中で優先度が高いジョブってなんだっけ?という気もしていきます。もはや現場のエンジニアの経験と勘に頼らざるを得ない状態です。なのでこのあたりから問題解決に取り組む必要がありそうだなーと思いました。
現状の課題まとめ
- HPA の spec.behavior の設定
- 少なくともデフォルトの 15 秒間隔は短すぎる
- Sidekiq のオートスケール指標
- CPU やメモリの使用率ではうまく機能しない
- 「ジョブの待ち数」を指標とすると閾値の設定が難しい
- sidekiq worker 実行戦略
- pod 数が固定である前提の戦略なので変更が必要
- そもそも「優先度」という概念が曖昧
課題への対応
前置きが長くなりましたが、ここからが解決編です。いっちょやってみっか!!
Sidekiq のオートスケール指標を変更
まずは「ジョブの待ち時間」という指標を変えるところから考えます。従来の指標のおさらいです:
従来の指標
- ジョブの待ち数
- 行列のできるラーメン店で 10 人超えたら座席と店員を増やすイメージ
- ただし、入店して5分で食べ終わる客もいれば、1時間経っても食べ終わらない客もいるので、 10 人以下の行列なのにいつまで経っても入店できない場合がある
ラーメン屋さんに並んでる人の数を指標にしても、お店の回転率が悪いと上手くいかないことが分かります。では、並んでる人の「待ち時間」を指標にしてみたらどうでしょうか? 「入店まで 60 分待ち」 ってなってたらスケールアウトしなきゃ!って気持ちになりますよね?(知らんけど)
この課題に取り組んでいるときに海外のブログも色々読み漁っていたんですが、その中で queue latency というワードが目に止まりました。調べてみると Sidekiq が提供する API にそのような値があるようです:
Sidekiq::Queue#latency で定義されるその値は 「現在時刻 - 最も古いジョブがキューに入れられた時刻」 で表されます。 #set(wait: 1.week) などを使った予約ジョブは対象に含まれないので、正に期待していたラーメン屋で一番待ってる人の待ち時間です。整理すると次のようになります:
新しい指標
- queue latency
- 行列のできるラーメン店で、先頭の客が 10 分以上待たされている場合に座席と店員を増やすイメージ
- 入店中の客が中々食べ終わらない場合でも座席と店員が増えるので、いつでも 10 分くらいで入店できる状態を維持できる
どうやったか
弊社のスーパーエンジニア(現在育休中)が作った datadog-sidekiq という go で実装されたメトリクス送信バッチ処理がありまして、以前から k8s のメトリクスにはこのスクリプトを利用していました。
今回の対応では前述の Sidekiq::Queue#latency に相当する処理を go で実装し、 datadog-sidekiq に組み込む形で実現しました。
OSS なのでどなたでもご利用いただけるんですが、スーパーエンジニア曰く、メンテナンスが辛いのである日突然 OSS じゃなくなるかもしれない、とのことでした 🙏
やってることは単純なので、 Sidekiq::Queue#latency の実装を見れば自前でも再現できると思います。
sidekiq worker 実行戦略を変更
改めて従来の実行戦略をおさらいしてみましょう:
従来の実行戦略
- high-queue-worker:
- high-queue のジョブのみ実行
- default-queue-worker:
- high-queue, default-queue のジョブを実行
- low-queue-worker:
- high-queue, default-queue, low-queue のジョブを実行
- その他:
- delivery-queue など特定の目的専用の queue と worker が存在している
Pod 数が固定であることを前提とした戦略で、「優先度」という概念の元、優先度の高いジョブが滞らないよう優先道路を設けるようなアプローチでした。ただし、負荷に応じてオートスケールできるなら、他の queue の処理を受け持つ必要は無いです。
また、「優先度」という尺度もエンジニアの主観によるものなので、ジョブが増えてくると段々定義が難しくなるという課題もありました。
前述の queue latency という指標を設けることで、以下のような戦略を取ることができるようになりました:
新しい実行戦略
- fast-worker:
- fast-queue のジョブのみ実行
- Enqueue から 1 ~ 5 分以内にジョブが実行されることを目標とする
- normal-worker:
- normal-queue のジョブのみ実行
- Enqueue から 5 ~ 15 分以内にジョブが実行されることを目標とする
- slow-worker:
- slow-queue のジョブのみ実行
- Enqueue から 15 ~ 45 分以内にジョブが実行されることを目標とする
- その他 worker:
- 廃止
なんということでしょう。「優先度」という曖昧な尺度が一変、具体的な「許容できる待ち時間」という尺度に生まれ変わりました ✨ もうエンジニアの勘と経験に頼る必要はありません。ジョブの要件として、この処理はどれくらい実行開始まで遅れても許容できるか、を考えれば良いのです。また、他の queue の処理を受け持つこともなく、オートスケールによる結果も想像しやすくなっています。
また、k8s のマニュフェストがシンプルになる、という嬉しい副作用もありました。元々ソーシャルPLUS では sidekiq を使う Rails アプリケーションが 3 つ、staging と production に存在していたんですが、サービス固有の worker pod も存在していたので共通化が難しい状態でした。
新しい実行戦略ではサービス毎に異なる HPA を定義する必要がなく、すべて同じ behavior を定義すれば良くなったので、細かい設定が不要になりました。差分としては minReplicas と maxReplicas が異なるくらいです。
HPA の spec.behavior の設定
指標と戦略を整えたので、あとはいよいよ期待する「待ち時間」に沿ってスケールイン・アウトするようにパラメータを調整するだけです 🔧
最初は意気揚々と k8s の manifest にそれらしい値を設定して staging にデプロイして動作確認、という流れで試していました:
- staging デプロイ
- Job を大量に queuing するスクリプトを実行
- 数時間放置
- 結果を確認
これだと意味わかんないくらい時間かかるので、1回でやめました 😇
大学の研究室では「こういう時はシミュレーター作って実験しろ」と教わったので、Google Spread Sheet で HPA の設定に基づいたシミュレーションを行うことにしました。一見複雑そうなものでも案外スプシの関数をゴニョゴニョして四則演算を駆使するだけでもシミュレートできるものです。
以下が今回の検証で使用した k8s manifest に設定している HPA の設定です。
実際にはシミュレーションで結果を確認しながら色々調整を加えました。
| Queue name | fast-queue | normal-queue | slow-queue |
|---|---|---|---|
| spec.minReplicas | 9 | 9 | 9 |
| spec.maxReplicas | 100 | 100 | 100 |
| spec.external.metrics.target.value | 60 | 300 | 900 |
| spec.behavior.scaleUp.policies.periodSeconds | 60 | 120 | 300 |
| spec.behavior.scaleUp.policies.value [%] | 1.0 | 0.75 | 0.5 |
| spec.behavior.scaleUp.stabilizationWindowSeconds | 0 | 0 | 0 |
| spec.behavior.scaleDown.policies.periodSeconds | 300 | 300 | 300 |
| spec.behavior.scaleDown.policies.value [%] | 0.5 | 0.3 | 0.2 |
| spec.behavior.scaleDown.stabilizationWindowSeconds | 60 | 300 | 900 |
シミュレーション結果
以下がシミュレーションの結果です。前述の HPA の設定値に加えて Sidekiq の concurrency (並列数) を 5 、 1 つのジョブの実行にかかる処理時間を 10 sec と仮定してシミュレートしています。今回は 10k のジョブが突発的にエンキューされた場合に目標時間内にスケールアウトできることをゴールに設定しています。
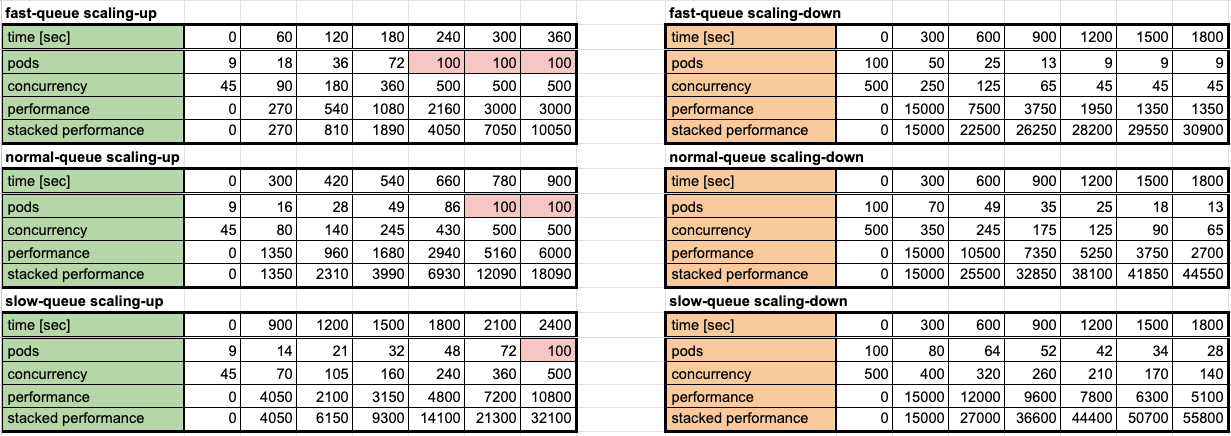
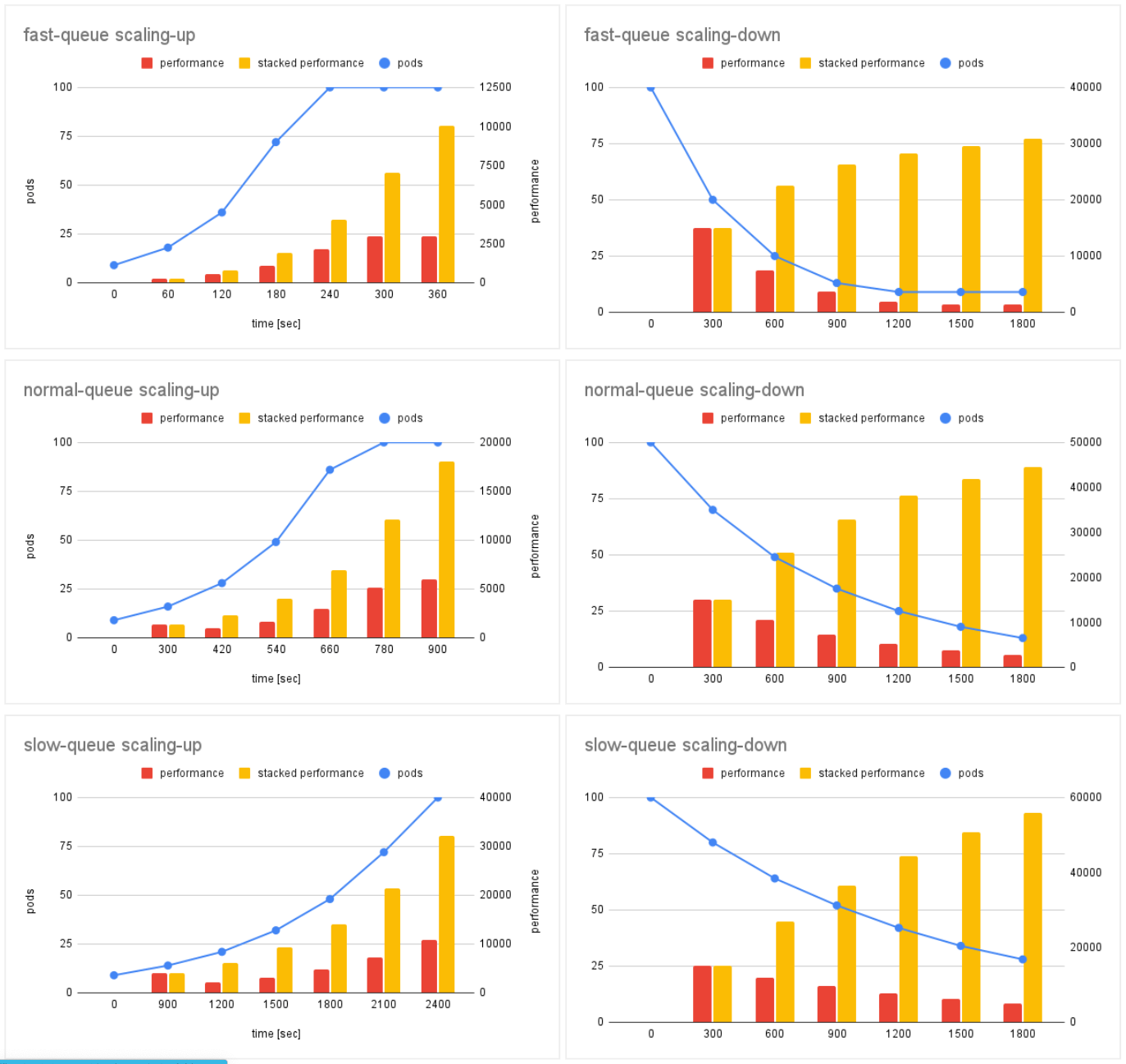
minReplicas = 9 で maxReplicas = 100 なので、シミュレート結果も 9 から始まって 100 で頭打ちになっています。 performence は単位時間内に処理できたジョブの数 (単位時間 / ジョブの処理時間 (10sec)) で、stacked performance は time = 0 からトータルで処理できたジョブの数を示しています。
理論上 10,000 件のジョブを処理するのに fast-queue worker は約 360 sec、 normal-queue worker は約 700 sec で slow-queue worker は約 1600 sec かかるのね、ということが分かります。その際に必要な pods などから消費するリソースなんかも想像できますね。マシンリソース消費して速く終わらせるのか、節約してゆっくり実行するのか、アプリケーションに求められる要件に合わせて使い分ける感じになるかと思います。
実機で検証
シミュレーションの結果から、理論上の動作はイメージできました。実際に動かしてみてシミュレートした内容通りに動くのかを確認したいと思います。Node のオートスケールが入るとややこしくなるので、Node 台数は 100 台に固定してあります。
動作確認用のジョブ
処理の内容はとてもシンプルで、引数で受け取った時間だけ sleep するだけです。
class SleepingJob < ApplicationJob
queue_as :normal
# 指定された時間だけ sleep する。
#
# @param sleep_second [Float] sleep する秒数
def perform(sleep_second)
sleep(sleep_second)
end
end
実験では 10,000 件のジョブが一度に投下されたケースを想定してみました。
ジョブの実行時間は 10 sec に設定しています。
実験用スクリプト
10_000.times do
SleepingJob.set(queue: :fast).perform_later(10.0)
SleepingJob.set(queue: :normal).perform_later(10.0)
SleepingJob.set(queue: :slow).perform_later(10.0)
end
実験結果
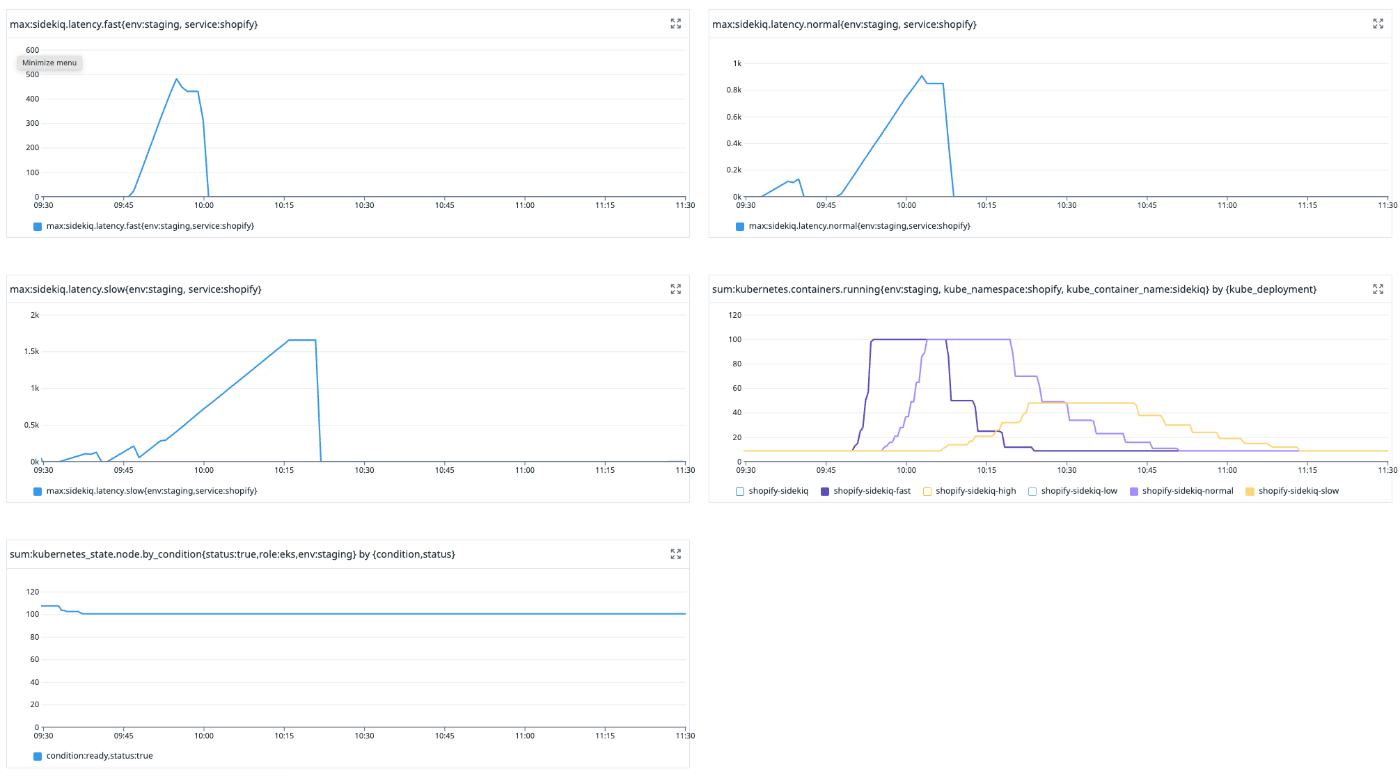
実験の時に撮ったスクショが雑なのでちょっと見づらいですが、左上の sidekiq.latency.fast が fast-queue に積まれたジョブの queue latency です。右下の kubernetes.container.running にそれぞれの sidekiq worker pod の台数の推移がグラフ化されています。
Node 台数を固定して理想的な状態を作っているとはいえ、思っていた以上にシミュレーション通りの結果になりました。今後オートスケールの調整をする際もシミュレーションの結果を信用して良さそうです。
それから
実機でも期待通りの結果が得られることがわかったので、後日全てのサービスに展開しました。
4/3(水) に適用したんですが、この日を境に sidekiq worker pods の台数がめっちゃ落ち着いているのがわかると思います。

比べてみると before の状態がヤバ過ぎですね。before の状態でもサービスが止まるほど影響はなかったので普通に稼働していたんですが、解消するまでは心臓に悪い日々が続いていました 😇
本当に解消して良かった 😌
しかし今改めて思えば MAXPODS の値を減らすくらいはしておいても良かったかもしれない。。
自分もまだまだ詰めが甘いですね 🍭
まとめ
長くなりましたが、 sidekiq worker のオートスケール問題に根っこから向き合い、無事に安定稼働させることができました。個人的に難易度高いなーと感じたのは、バックエンドとインフラの両方の知見がないと解消できない課題であった点です。自分もインフラはそれほど詳しくないのですが、バックエンドの実装はよく理解していたので、インフラチームと協力し合うことで何とか乗り切れました 🤝
対応中、細かい点で色々ハマりどころもあったんですが、ただでさえ長文になっているので今回は省略しました。もし質問などあればコメント欄にて頂ければと思います 🙏

Discussion