こんにちは otsubo です。MySQL (InnoDB) のロックについて整理する機会があったので記事にします。
はじめに
全ての ロックタイプ を網羅するのは大変なため、
- レコードロック
- ギャップロック
- ネクストキーロック
を中心にまとめます。この3つはトランザクション内で UPDATE、DELETE、 SELECT ... FOR UPDATE / SHARE するときに獲得されるロックです。INSERT 時のインサートインテンションロックもちょっとだけ扱います。テーブルロックやメタデータロックは扱いません。
InnoDB ではクエリによって特定の「範囲」がロックされることがあります。これを知らないと思わぬ不具合に繋がります。
範囲をロックして InnoDB は何を実現したいのか、どのような仕組みでロックするのかを知っておくと開発に役立ちます。
記事を通して下記を前提とします。
- MySQL 8.0.43 with InnoDB
- Isolation level: REPEATABLE READ(デフォルト設定)
範囲がロックされる例
まず例示から入ります。例を見て驚きが大きければきっと対象読者です。
行ロックにならない例
シンプルなクエリから見ていきましょう。
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
price INT NOT NULL,
INDEX idx_price (price) -- 非ユニークインデックス
);
INSERT INTO products (id, name, price) VALUES
(1, '商品1', 100),
(2, '商品2', 200),
(3, '商品3', 300);

データ準備時点での products のプライマリキーと idx_price のイメージ
3つの商品があるテーブルで、200円の商品をロックします。次に別のセッションで100円〜300円の新商品を INSERT してロック待ちになるのはどれでしょうか?下記以外のトランザクションは実行されていないものとします。
-- session 1 価格が200円の商品をちょっと触ります。他の人は触らないでね
mysql> BEGIN;
mysql> SELECT * FROM products WHERE price = 200 FOR UPDATE;
-- session 2 新商品ができたので登録していくよ
mysql> INSERT INTO products VALUES (4, '新商品A', 100);
mysql> INSERT INTO products VALUES (5, '新商品B', 150);
mysql> INSERT INTO products VALUES (6, '新商品C', 200);
mysql> INSERT INTO products VALUES (7, '新商品D', 250);
mysql> INSERT INTO products VALUES (8, '新商品E', 300);
答えは 新商品Eを除く全てがロック待ちになる です。
ちなみに、新規追加する商品の id が4以上であれば、値段が100円〜299円の場合にロック待ちになります。しかし「ロック範囲は100円から299円」と言ってしまうとそれは誤りです。
事情を知らないと様々な疑問が浮かぶのではないでしょうか。行ロックしか知らなかった過去の自分は大混乱でした。
- 新商品C以外の
INSERTは待ってもらう必要ある? - なぜ広い範囲がロックされる?
- 「ロック範囲は100円から299円」が誤りならどこからどこまでがロック範囲?新商品AとEに差が出たのはなぜ?
急ぎ結論を知りたい人のため、多少の不正確さを承知で回答をまとめます。
- 本来は新商品C以外は
INSERTを待ってもらう必要はない- 正確には、200円の商品の追加さえ待ってもらえれば OK
- 別のトランザクションで200円の商品が
INSERTされるのを防ぐ目的で「200円の商品が新規追加されそうな範囲」をロックしたから- その結果、本来待たされなくても良いはずの
INSERTが待たされた - InnoDB の仕組み上
INSERTを待ってもらうには範囲(ギャップ)をロックするしかない
- その結果、本来待たされなくても良いはずの
- インデックス
idx_priceの(price=100, id=1) ~ (price=300, id=3)がSELECT ... FOR UPDATEのロック範囲- ロックされたのはここだけではないが、新商品の
INSERTと衝突したのはこの範囲 - 新商品Aの
idx_priceは(price=100, id=4)でロック範囲と衝突した。B, C, D も同じく - 新商品Eの
idx_priceは(price=300, id=8)でロック範囲と衝突しなかった
- ロックされたのはここだけではないが、新商品の

デッドロックで困る例
一瞬のロック待ち程度なら困らないですが、デッドロックが発生すると対処を迫られます。もう少し現実的な例を挙げます。
BlogPost has many Tags の関係で、ブログ記事のタグを更新する処理を考えます。行数の都合で BlogPost と Tag が 1:N ですが、中間テーブルを用いて N:N にしても本質は変わりません。
※ 同一 BlogPost の同時編集は考えないことにします。
CREATE TABLE blog_posts (
id INT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
content TEXT NOT NULL
);
CREATE TABLE tags (
blog_id INT,
name VARCHAR(255),
PRIMARY KEY (blog_id, name), -- プライマリキー(ユニーク)
FOREIGN KEY (blog_id) REFERENCES blog_posts(id)
);
INSERT INTO blog_posts (id, title, content) VALUES
(1, 'お料理の記事', 'お湯を注ぐと完成します'),
(2, '技術の記事', 'Tab を連打すると完成します'),
(3, '日報A', '編集中...'),
(4, '日報B', '編集中...');
INSERT INTO tags (blog_id, name) VALUES
(1, 'Cooking'),
(2, 'Copilot'),
(2, 'Programming');

データ準備時点での tags のプライマリキーのイメージ(blog_posts は変更しないため割愛)
改善前(空振り)
下記は単体では問題なく動きますが、アプリが並列に動く場合、利用者が増えると高確率でデッドロックが発生します。Rails を使っていますが、特定 ORM に固有の問題ではありません。
class BlogPost < ApplicationRecord
has_many :tags, foreign_key: :blog_id, dependent: :destroy
def update_tags(tag_names) # ['AI', 'VibeCoding'] などを受け取る
transaction do
# DELETE FROM tags WHERE blog_id = ?;
tags.delete_all # 既存のタグを全部削除する
# sleep 10
# INSERT INTO tags (name, blog_id) VALUES (?, ?), (?, ?);
tags.insert_all(tag_names.map { |tag_name| { name: tag_name } }) # 追加
end
end
end
Tag モデルも一応
class Tag < ApplicationRecord
self.primary_key = [ :blog_id, :name ]
belongs_to :blog, class_name: "BlogPost", foreign_key: :blog_id
end
同時操作を再現するため sleep 10 のコメントを外し、rails console を2つ起動して以下を実行するとデッドロックが発生します:
BlogPost.find(3).update_tags(['Tag1']) # session 1 : '日報A' にタグ付け
BlogPost.find(4).update_tags(['Tag2']) # session 2 : '日報B' にタグ付け
問題は、削除すべきタグの有無に関わらず DELETE FROM tags WHERE blog_id = ? を実行していることです。「WHERE の条件が空振りするとギャップロックが発生する」みたいな注意を聞いたことはないでしょうか。今回はそのパターンです。
この DELETE は、tags のプライマリキーの超広範囲をロックし合います。
- session 1 が
(blog_id=2, name='Programming') ~をロック- blog_id が2より大きい範囲をほぼ全部ロック
- session 2 も
(blog_id=2, name='Programming') ~をロック- ※ ギャップロック同士はコンフリクトしないのでここまでは成功します
- session 1「session 2 君がロックしているので
(blog_id=3, name='Tag1')を追加できないっす」 - session 2「session 1 君がロックしているので
(blog_id=4, name='Tag2')を追加できないっす」

DELETE ... WHERE blog_id = 3 or 4 を実行しただけで広い範囲がロックされました。これも「blog_id=3 or 4 なレコードが INSERT されうる範囲のロック」が発生しています。
空振りを回避(しても不完全)
WHERE の空振りを防げばおおむねデッドロックを回避できますが完全ではありません。
.presence で空振りを回避してみました:
transaction do
# 削除すべき tags が存在する場合のみ DELETE を実行
tags.presence&.delete_all
tags.insert_all(tag_names.map { |tag_name| { name: tag_name } })
end
下記では削除すべき tags があるため空振りしませんがデッドロックが発生します:
BlogPost.find(1).update_tags(['Noodle']) # session 1 : 'Cooking' を削除して 'Noodle' を追加
BlogPost.find(2).update_tags(['AI']) # session 2 : 'Copilot', 'Programming' を削除して 'AI' を追加
問題は DELETE FROM tags WHERE blog_id = ? の検索条件が unique search condition ではないことです。検索に使われるのは確かに tags のプライマリキー(ユニークなキー)なのですが、検索条件が blog_id のみなので行ロックではなく範囲にロックがかかります。ロック種別の決定方法 で詳しく説明します。

行ロックの使用
上のデッドロックまでしっかり回避したい場合は、ユニークキーの全てのカラムを検索条件に指定します。可読性は落ちますが、こうすると (blog_id=2, name='Copilot') と (blog_id=2, name='Programming') などの行ロックのみがかかります。範囲はロックされないため、異なる blog_id とのデッドロックが回避できます。
transaction do
# DELETE FROM tags WHERE blog_id = 2 AND name IN ('Copilot', 'Programming');
tags.where(name: tags.map(&:name)).presence&.delete_all
tags.insert_all(tag_names.map { |tag_name| { name: tag_name } })
end
Rails なら destroy_all を使って1件ずつタグを削除することでもデッドロックは回避できます。どうするかは可読性やパフォーマンスとの兼ね合いになると思います。

なぜ「範囲」がロックされるのか、なぜ行ロックのみで済む場合があるのか、以降でロックの目的と InnoDB がロックを実現する仕組みを見ていきます。
ロックの目的
そもそもロックによって実現したいことは何でしょうか。特に、すでにあるレコードだけではなく「範囲」にロックが必要になるのはなぜでしょうか。
アノマリー
複数のトランザクションが同時に実行されて起こる不整合の総称をアノマリーと言います。
ロックによって実現したいのは、トランザクションが一度検索した範囲(商品の例だと price=200 にヒットする範囲)に対して別のトランザクションが何かしらの変更を加えてしまうアノマリーを防止することです。特に、InnoDB の REPEATABLE READ 分離レベルでは「ファントム行」に関するアノマリーを防止します。
「ファントム行」とは、あるトランザクションが検索した(あるいは変更を加えた)範囲内に、別のトランザクションが INSERT する行のことです。「ファントム行」に対して UPDATE や DELETE[1] を適用してしまうと、以下のような不整合が発生します。
-- session 1
mysql> BEGIN;
mysql> SELECT * FROM products WHERE price = 200;
/* 売れ残りばかりなので半額にしちゃお (discount は割引金額) */
+----+--------------+-------+----------+
| id | name | price | discount |
+----+--------------+-------+----------+
| 1 | 売れ残り | 200 | 0 |
| 2 | 訳あり | 200 | 0 |
+----+--------------+-------+----------+
-- session 2
mysql> INSERT INTO products VALUES (3, '新商品', 200, 0);
-- session 1
mysql> UPDATE products SET discount = 100 WHERE price = 200;
mysql> COMMIT;
mysql> SELECT * FROM products WHERE price = 200;
+----+--------------+-------+----------+
| id | name | price | discount |
+----+--------------+-------+----------+
| 1 | 売れ残り | 200 | 100 |
| 2 | 訳あり | 200 | 100 |
| 3 | 新商品 | 200 | 100 | -- !!??
+----+--------------+-------+----------+
新商品まで半額になってしまいました。session 1 視点では、200円の商品は売れ残りと訳あり商品のみだったのに。これが新商品 (id=3) という「ファントム行」に UPDATE が適用された状況です。
SELECT ... FOR UPDATE でロックしていれば、最初の例で見たように price=200 を含む範囲への INSERT はロック待ちになるため意図せぬ変更を防止できました。
「ファントム行」が厄介なのは、既存のレコード id=1, id=2 を行ロックしても発生を防ぐことができない点です。特定範囲への INSERT を何かしらの方法で待ってもらわなければ防止できません(既存のレコードが UPDATE、 DELETE されるのを防ぎたいだけなら行ロックのみで十分です)。
「ファントム行」以外のアノマリーの解説は、他の方がまとめてくださっている記事に譲ります。また、各トランザクション分離レベルによって許容するアノマリーが異なります。
ロックの仕組み
InnoDB は、アノマリーを防ぐために、アノマリーが発生しうる「範囲」をロックします。そして、ロック同士のコンフリクトによって順番待ちを実現しています。ロックがコンフリクトすると、後からロックを獲得しようとした方が待たされます。
ロック種別
ロックには種別があり、どれとどれがコンフリクトするか決まっています。ドキュメントを見ていただく方が早い気もしますがこの記事と関連が強い部分をピックアップします。

(hoge=30, id=2) に対するレコードロック、ギャップロック、ネクストキーロック
レコードロック
いわゆる行ロックです。インデックスレコード( idx_foo や PRIMARY のノード1つ)をロックします。ギャップはロックしません。既存のレコードが DELETE や UPDATE されるのを防止する役割を持ちます。レコードロックだけではファントム行の INSERT は防げません。
ギャップロック
インデックスレコード同士の隙間(ギャップ)をロックします。「インデックスレコード同士の」という部分がポイントで、任意の範囲をロックできるわけではありません。インサートインテンションロックとコンフリクトするので INSERT を防ぐ役割を持ちます。
ネクストキーロック
レコードロックと、当該レコードの前のギャップのロックです。「ネクスト」と名前に入っていますが「前の」ギャップです。InnoDB は、特定範囲をロックするために、その範囲を覆うようなインデックスレコードにネクストキーロックをかけていくという基本動作をします。
インサートインテンションロック
INSERT しようとするギャップに対するロックです。ギャップロックとコンフリクトします。特定範囲への INSERT を待ってもらうという目的を達成するための手段が「ギャップロックとインサートインテンションロックのコンフリクト」でした。範囲はギャップロックと同じなので図からは省略しました。
「ネクストキーロック要らなくない?」と思いませんでしたか。レコードロック + ギャップロックで実現できますよね。しかし、InnoDB で「普通のロック」といえばネクストキーロックを指します。深くは立ち入りませんが、ネクストキーロックの特殊系(レコードのみ ver.・ギャップのみ ver.)としてレコードロック・ギャップロックがあるイメージです。InnoDB はロックを獲得する際、基本はネクストキーロックをかけ、特定条件を満たしたとき(レコードのみ・ギャップのみで十分と確信できるとき)のみ特殊系のロックを使います。定義部分のソースコード に丁寧なコメントがあります。
ロック種別の決定方法
アノマリーを防止するためにロックすべき範囲はどこでしょうか。身も蓋もないことを言えば、真の意味でロックすべき範囲は WHERE で指定した範囲ピッタリのはずです。
しかし、InnoDB は器用に任意の範囲をロックできません。ロックできるのはインデックスレコードとその隙間のみです。そのため上記のロック種別を使い分けて、真にロックすべき範囲をカバーするという手法をとります。
使われるロック種別がどれになるのかは、ドキュメントの REPEATABLE READ 分離レベルで説明されている内容がとても大事です。
For locking reads (
SELECTwithFOR UPDATEorFOR SHARE),UPDATE, andDELETEstatements, locking depends on whether the statement uses a unique index with a unique search condition, or a range-type search condition.
- For a unique index with a unique search condition, InnoDB locks only the index record found, not the gap before it.
- For other search conditions, InnoDB locks the index range scanned, using gap locks or next-key locks to block insertions by other sessions into the gaps covered by the range. For information about gap locks and next-key locks, see Section 17.7.1, “InnoDB Locking”.
ユニークなインデックスを使い、ユニークインデックスを一意に特定できる検索条件の場合のみ行ロック、それ以外は全てギャップまたはネクストキーロックです。ユニークインデックスを一意に特定できる検索条件とは、複合ユニークキーの場合は全てのカラムを指定した検索ということです。該当部分のソースコード に同様のコメントがあります。
ロック範囲の確認方法
あるクエリを実行した時のロック範囲を確認してみましょう。performance_schema.data_locks テーブルを検索すると、獲得済みのロックと待ち状態のロックを表示できます。
扱うテーブルは、最初の具体例 の商品テーブルです。
まず、プライマリキーでの検索です。ポイントは INDEX_NAME=PRIMARY, LOCK_MODE=X,REC_NOT_GAP, LOCK_DATA=3 あたりです。REC_NOT_GAP はレコードロック(行ロック)を表します。PRIMARY インデックスの id=3 のレコードに排他レコードロックがかかっているのがわかります。
id はプライマリキーなので id=3 の商品は他に存在できません。id=3 への変更さえ保護できれば良いので、レコードロックのみでアノマリーが防止できます。
mysql> BEGIN; SELECT * FROM products WHERE id = 3 FOR UPDATE;
mysql> SELECT OBJECT_NAME, INDEX_NAME, LOCK_TYPE, LOCK_MODE, LOCK_DATA, LOCK_STATUS, ENGINE_TRANSACTION_ID AS TX_ID FROM performance_schema.data_locks WHERE LOCK_TYPE = 'RECORD';
+-------------+------------+-----------+---------------+-----------+-------------+-------+
| OBJECT_NAME | INDEX_NAME | LOCK_TYPE | LOCK_MODE | LOCK_DATA | LOCK_STATUS | TX_ID |
+-------------+------------+-----------+---------------+-----------+-------------+-------+
| products | PRIMARY | RECORD | X,REC_NOT_GAP | 3 | GRANTED | 22065 |
+-------------+------------+-----------+---------------+-----------+-------------+-------+
続いて非ユニークインデックスでの検索です。最初の具体例で扱ったクエリです。
1行目と2行目は idx_price へのロック、最終行は PRIMARY へのロックです。
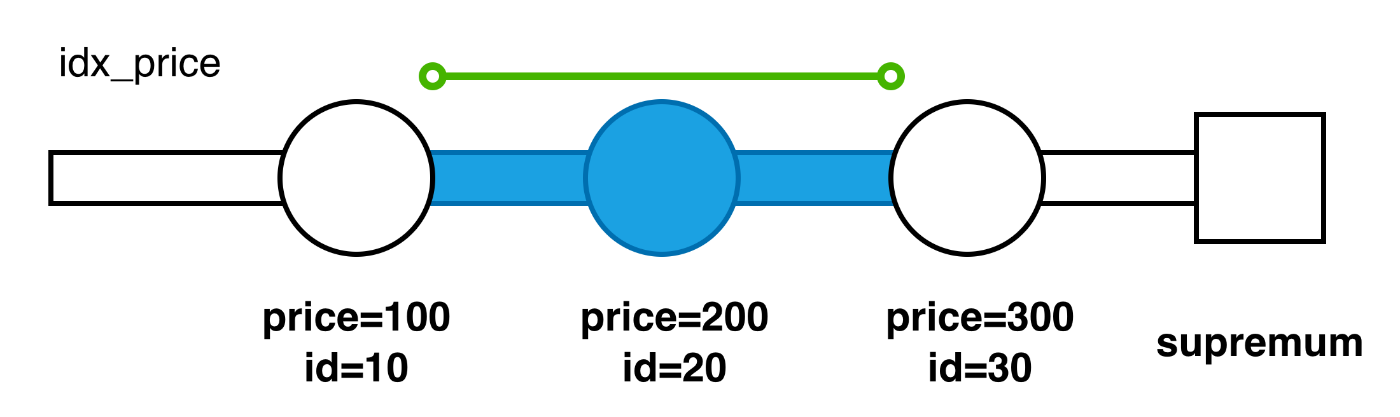
1行目 X,GAP は (price=300, id=3) の前のギャップへのロックを表します。
2行目 X は (price=200, id=2) へのネクストキーロックを表します。( GAP や REC_NOT_GAP などがついていなければネクストキーロックです。)
最終行は id=2 のレコードの行ロックです。
mysql> BEGIN; SELECT * FROM products WHERE price = 200 FOR UPDATE;
mysql> SELECT OBJECT_NAME, INDEX_NAME, LOCK_TYPE, LOCK_MODE, LOCK_DATA, LOCK_STATUS, ENGINE_TRANSACTION_ID AS TX_ID FROM performance_schema.data_locks WHERE LOCK_TYPE = 'RECORD';
+-------------+------------+-----------+---------------+-----------+-------------+-------+
| OBJECT_NAME | INDEX_NAME | LOCK_TYPE | LOCK_MODE | LOCK_DATA | LOCK_STATUS | TX_ID |
+-------------+------------+-----------+---------------+-----------+-------------+-------+
| products | idx_price | RECORD | X,GAP | 300, 3 | GRANTED | 22066 |
| products | idx_price | RECORD | X | 200, 2 | GRANTED | 22066 |
| products | PRIMARY | RECORD | X,REC_NOT_GAP | 2 | GRANTED | 22066 |
+-------------+------------+-----------+---------------+-----------+-------------+-------+
ロック範囲を図に示します。想像より広い範囲がロックされたと思うかもしれません。この範囲が妥当なのかを考えてみます。
検索条件は price=200 でした。price はユニークではないため、何も対策しなければ他のトランザクションが200円の商品を INSERT できます。これを防ぐには「200円の商品が INSERT され得るギャップ」をロックする必要があります。

「 (price=200, id=2) の前にも入るの? 」と思うかもしれませんが、たとえば INSERT INTO products (id, name, price) VALUES (-1, '新商品', 200); みたいに idx_price のソート順で (price=200, id=2) より前になる場合は前のギャップに入ります。(id は INT なので負の値もあり得ます。)
そのため図の範囲は、idx_price インデックスにロックをかけてファントム行を防ぐために必要な最小限のロック範囲ということになります。(厳密には INSERT だけ防ぎたければ行ロックは不要ですが、 UPDATE や DELETE ももちろん防ぎたいため行ロックがかかるのも妥当です。)ロック範囲がどれか一つでも欠けると何かしらのアノマリーが発生します。
ロック待ちになった状態も確認します。200円の新商品を (price=200, id=2) ~ (price=300, id=3) のギャップに追加しようとして、インサートインテンションロックがギャップロックとコンフリクトしています。コンフリクトしたため LOCK_STATUS=WAITING になっています。
-- session 1
mysql> BEGIN; SELECT * FROM products WHERE price = 200 FOR UPDATE;
-- session 2
mysql> INSERT INTO products (id, name, price) VALUES (999, '新商品', 200);
-- session 1
mysql> SELECT OBJECT_NAME, INDEX_NAME, LOCK_TYPE, LOCK_MODE, LOCK_DATA, LOCK_STATUS, ENGINE_TRANSACTION_ID AS TX_ID FROM performance_schema.data_locks WHERE LOCK_TYPE = 'RECORD';
+-------------+------------+-----------+------------------------+-----------+-------------+-------+
| OBJECT_NAME | INDEX_NAME | LOCK_TYPE | LOCK_MODE | LOCK_DATA | LOCK_STATUS | TX_ID |
+-------------+------------+-----------+------------------------+-----------+-------------+-------+
| products | idx_price | RECORD | X,GAP | 300, 3 | GRANTED | 22067 |
| products | idx_price | RECORD | X | 200, 2 | GRANTED | 22067 |
| products | idx_price | RECORD | X,GAP,INSERT_INTENTION | 300, 3 | WAITING | 22068 |
| products | PRIMARY | RECORD | X,REC_NOT_GAP | 2 | GRANTED | 22067 |
+-------------+------------+-----------+------------------------+-----------+-------------+-------+
ロック範囲の一覧
ロック範囲をいくつかまとめてみます。覚えるというより、アノマリーを防ぐために必要な最小限の範囲を考え、それを InnoDB がカバーしてくれているんだなと考えると納得しやすいと思います。
対象データは 最初の商品テーブル です。説明の都合でプライマリーキーの id を10刻みにしましたが、深い意味はなくギャップを作りたかっただけです。
mysql> SELECT * FROM products;
+----+---------+-------+
| id | name | price |
+----+---------+-------+
| 10 | 商品1 | 100 |
| 20 | 商品2 | 200 |
| 30 | 商品3 | 300 |
+----+---------+-------+
スペースの都合で BEGIN; SELECT * FROM products WHERE ... FOR UPDATE; の WHERE ... 部分だけを掲載します。また、idx_price で検索すると範囲内の PRIMAY にも行ロックがかかりますが図は省略しています。
PRIMARY での検索
右端の supremum は「これより大きい値は無い」ような値を表した擬似的なインデックスレコードで、このレコードにロックをかけることで特定行より右を全てロックします。
また、緑色の数直線らしきものは、アノマリーを発生させないために必要である(と自分が考える)最小限の範囲です。
| クエリ | ロック範囲 |
|---|---|
WHERE id = 20 |
 |
WHERE id = 25 |
 |
WHERE id BETWEEN 15 AND 25 |
 |
WHERE id > 25 |
 |
idx_price での検索
| クエリ | ロック範囲 |
|---|---|
WHERE price = 200 |
 |
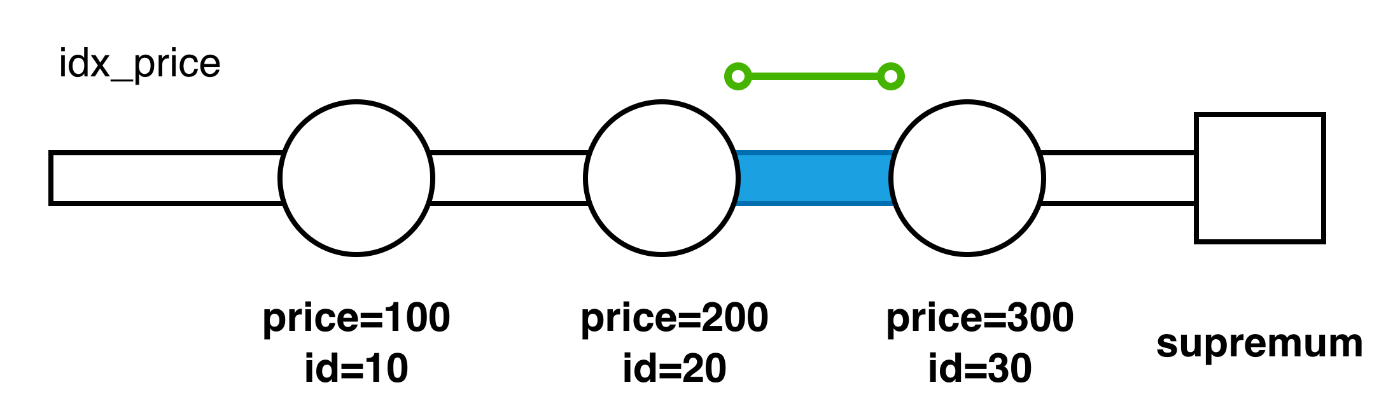
WHERE price = 250 |
 |
WHERE price BETWEEN 150 AND 250 |
 |
概ね必要と考えられる最小限の範囲がロックされました。一番最後の例 WHERE price BETWEEN 150 AND 250 について、右端の (price=300, id=30) はネクストキーロックではなくギャップロックでも良いような気がしますが、なぜギャップロックにならない(あるいはできない)のかは分かりませんでした。詳しい方がいたら教えていただきたいです。
ロック獲得の仕組み
InnoDB は検索時に訪問したインデックスレコードにロックをかけることで、真に必要なロック範囲をカバーします。「検索にヒットした」ではなく「訪問した」インデックスというのがポイントです。検索の動作(実行計画)が意図どおりでないと思わぬ範囲がロックされます。
クラスタインデックスとセカンダリインデックス
検索の動作を知るためにはデータ構造を知る必要があります。これまでインデックスレコードという言葉でまとめて説明してきましたが、InnoDB には2種類のインデックスがあります。
- クラスタインデックス:プライマリキーとそれに紐づく実データを格納する木構造
- セカンダリインデックス:それ以外のインデックスとプライマリキーのセットを格納する木構造
「検索が遅いのでインデックスを作成しよう」と言った時に指しているのはセカンダリインデックスです。どちらも B+Tree という木構造で、インデックスを増やすたびに新たな B+Tree が作成されます。レコードの実データやインデックスの内容は、木構造の末端であるリーフノードに格納されます。
セカンダリインデックス idx_price で検索した時の動作を、クラスタインデックス PRIMARY も合わせて図に表してみます。詳細な仕組みには立ち入りませんが、実際のインデックスレコードの訪問順は下記です。
(price=200, id=20)(id=20)-
(price=300, id=30)(ここで検索範囲外に出たと分かって検索を終了)

下記の data_locks と順番が異なりますが内容は一致しています。
idx_price は訪問時にネクストキーロックをかけ、 PRIMARY は訪問時にレコードロックをかけます。検索範囲 BETWEEN 150 AND 250 の範囲外まで訪れないと範囲外に出たことがわからない、かつ、検索範囲をカバーするには (300, 30) の手前のギャップをロックしたいという事情をうまく組み合わせて必要範囲のロックが実現されています。
mysql> BEGIN; SELECT * FROM products WHERE price BETWEEN 150 AND 250 FOR UPDATE;
mysql> SELECT OBJECT_NAME, INDEX_NAME, LOCK_TYPE, LOCK_MODE, LOCK_DATA, LOCK_STATUS, ENGINE_TRANSACTION_ID AS TX_ID FROM performance_schema.data_locks WHERE LOCK_TYPE = 'RECORD';
+-------------+------------+-----------+---------------+-----------+-------------+-------+
| OBJECT_NAME | INDEX_NAME | LOCK_TYPE | LOCK_MODE | LOCK_DATA | LOCK_STATUS | TX_ID |
+-------------+------------+-----------+---------------+-----------+-------------+-------+
| products | idx_price | RECORD | X | 200, 20 | GRANTED | 22599 |
| products | idx_price | RECORD | X | 300, 30 | GRANTED | 22599 |
| products | PRIMARY | RECORD | X,REC_NOT_GAP | 20 | GRANTED | 22599 |
+-------------+------------+-----------+---------------+-----------+-------------+-------+
実行計画に応じたロック
「訪問した」インデックスレコードがロックされることを確認するため下記2つを試してみます。
FORCE INDEX によって idx_price を使わずにプライマリキーで検索:
mysql> BEGIN; SELECT * FROM products FORCE INDEX (PRIMARY) WHERE price = 200 FOR UPDATE;
セカンダリインデックスが無いカラムで検索。
mysql> BEGIN; SELECT * FROM products WHERE name = '商品2' FOR UPDATE;
上記は両方とも PRIMARY の全範囲をロックします。商品テーブルに対する変更は全てブロックされるため、本番環境でやったら大惨事です。使えるインデックスが無い、もしくはインデックスヒントなどによって使えない場合はクラスタインデックスの全範囲を訪問して条件に合うレコードを探します。全範囲を訪問する過程で全てのレコードにネクストキーロックをかけます。
mysql> SELECT OBJECT_NAME, INDEX_NAME, LOCK_TYPE, LOCK_MODE, LOCK_DATA, LOCK_STATUS, ENGINE_TRANSACTION_ID AS TX_ID FROM performance_schema.data_locks WHERE LOCK_TYPE = 'RECORD';
+-------------+------------+-----------+-----------+------------------------+-------------+-------+
| OBJECT_NAME | INDEX_NAME | LOCK_TYPE | LOCK_MODE | LOCK_DATA | LOCK_STATUS | TX_ID |
+-------------+------------+-----------+-----------+------------------------+-------------+-------+
| products | PRIMARY | RECORD | X | supremum pseudo-record | GRANTED | 22611 |
| products | PRIMARY | RECORD | X | 10 | GRANTED | 22611 |
| products | PRIMARY | RECORD | X | 20 | GRANTED | 22611 |
| products | PRIMARY | RECORD | X | 30 | GRANTED | 22611 |
+-------------+------------+-----------+-----------+------------------------+-------------+-------+

まとめ
- 「ファントム行」をはじめとするアノマリーを防ぐのがロックの目的です
- 目的達成のために、InnoDB はインデックスレコードやギャップをロックします
- ロックの仕組み上、真に必要なロック範囲より広い範囲がロックされることがあります
- インデックスレコードをロックする挙動を正しく理解して、必要最小限の範囲をロックするように心がけましょう
参考資料
多くの部分を参考にさせていただきました。本記事の MySQL とバージョンが異なるためロック範囲の例は少し異なります。
さらに InnoDB の内部動作を詳しく知りたい人向け。本記事では INSERT 時の詳細に立ち入らず、ギャップロックとインサートインテンションロックがぶつかる程度の説明しかしませんでしたが本当はもっと複雑です。特に INSERT 時のロックは Implicit lock(暗黙のロック)という挙動をするため観察しづらく、別の操作に起因して performance_schema.data_locks 上に突然現れたりします。 INSERT は複雑と知っておくだけでも調査に役立つと思います。
おわりに
範囲のロックについて整理しました。調査を通して、ロック範囲が意図したものかどうか、意図しない場合に内部で何が起こっていそうか少しずつ見通せるようになった気がします。
-
ややこしいため詳細は省略しますが、トランザクション内に
SELECTしか無い場合はロックをかけなくてもファントム行の問題が防止されます。これは MVCC というロックとは別の仕組みで実現されています。トランザクション内でSELECTを実行すると、検索したデータのスナップショットが保持されるような仕組みになっているため、同じ検索条件なら何度SELECTしても同じ結果になります。ただし、UPDATEやDELETEはスナップショットに対して実行されるわけではないためロックが必要です。詳細はドキュメントの Note 部分。 https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html ↩︎

Discussion