Webサーバーがどのようにリクエストを並行に処理しているのか、説明できなかったのでRustでコードを書いてみる
はじめに
Webサーバーがどのように大量のリクエストを並行に処理しているのか、説明できますか?
私は今まで、実際のところどのようにこれらが実装されているのかをよくわかっておらず、ブロッキングなコードを書いてしまったりしていました🤫
結論から述べると、Webアプリケーションでは、リクエストが大量に来た場合にいかに効率よく処理するために「並行(Concurrency)」や「並列(Parallelism)」を利用しています。
今回の記事では、この並行処理が実際のところどのように動作するのか、Rustのサンプルコードを示しつつ、解説していきます。
単一スレッドによるシンプルなサーバー
最初に、単純な「1件ずつ順番にリクエストを処理するサーバー」を例に、その動作や問題点を確認します。
レストランに例えると、「店員が1人しかいないレストラン」を用いると、注文ごとに料理に取り掛かるため、待ち時間が長くなってしまうという状況です。

use std::{
io::{prelude::*, BufReader, BufWriter},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
while let Ok((stream, _)) = listener.accept() {
handle_connection(stream)
}
}
fn handle_connection(stream: TcpStream) {
let stream1 = stream.try_clone().unwrap();
let mut reader = BufReader::new(&stream);
let mut writer = BufWriter::new(&stream1);
let mut request_line = String::new();
reader.read_line(&mut request_line).unwrap();
println!("Received request: {}", request_line.trim_end());
// heavy process happening
thread::sleep(Duration::from_secs(5));
let body = "Hello";
let response = format!(
"HTTP/1.1 200 OK\r\nContent-Length: {}\r\nContent-Type: text/plain\r\n\r\n{}",
body.len(),
body
);
// Write the response to the stream and flush
writer.write_all(response.as_bytes()).unwrap();
writer.flush().unwrap();
}
コードの説明
-
TCPリスナーの生成
TcpListener::bind("127.0.0.1:7878")によりソケットを作成し、接続待ち状態とします。※なお、ソケット通信は通常のプロセス間通信と同様にシステムコール(read(), write()など)を利用して行われています。
-
リクエストの逐次処理
while let Ok((stream, _)) = listener.accept() { … }では、accept() がブロッキング呼び出しであるため、1件のリクエスト処理が完了するまで次のリクエストの受け付けは待たされることになります。
ApacheBenchによる測定例
以下のようなコマンドでこのサーバのレスポンスタイムを計測してみます。
$ ab -n 30 -c 10 http://127.0.0.1:7878/
...
Percentage of the requests served within a certain time (ms)
50% 50037
66% 50039
75% 50044
80% 50045
90% 196920
95% 196923
98% 196926
99% 196926
100% 196926 (longest request)
ここでの数値は、各リクエストの処理自体は約5秒(5000ms)であるにもかかわらず、待ち行列の影響で中位値(50%)が約50秒、さらに後半のリクエストは200秒近くかかっています!遅すぎ🙃
10並行でこの程度なので、よりアクセスの多いサイトだと耐えられないほど遅くなってしまいます。このような遅延が発生しないようにするためには、サーバを増やすこともひとつの手段です。しかしこの1スレッドで逐次的にリクエストの処理を行う方法ではサーバの能力がほぼほぼ無駄になってしまっています。現代のWebサーバーでは1台で様々なリクエストを並行に処理するための対応が行われており、これによってサーバのキャパシティを最大限活用することができます。
並行・並列プログラミング
前述した通り、現代のWebアプリケーションでは、膨大なリクエストに対して迅速に応答する必要があります。しかしながら、上記のような単一スレッドでリクエストを順次処理する方法では待ち時間が大きくなり、ユーザ体験が損なわれます。
このような問題を解決するために、Webサーバーでは多数のリクエストを1件ずつ順次処理するのではなく、マルチスレッドやノンブロッキングI/Oといった手法で処理を分散させ、複数のリクエストを同時に処理することで待ち時間を削減する工夫がされています。
マルチスレッドサーバー
ここで解決策の1つとして利用できるのがスレッドです。リクエストを受け取るスレッドとレスポンス処理をするスレッドを分けることで処理を並行に行うことが可能となります。
スレッドとはプログラムの実行単位のことを指し、同じスレッドであれば処理は逐次処理(一つずつ順番に)され、違うスレッドでは並行処理(同時に複数の処理を行う)ことが可能となります。また、同じプロセス内のスレッド同士であればメモリが共有されるため、通信も簡単に行うことが可能です。
レストランで説明すると、店員さんが増え、それぞれが専属でお客さんの対応をします。料理を作る時間やお客さんが注文をするまでの時間など、空き時間があっても他のお客さんお対応をすることはありませんが、それぞれが別々のお客さんを対応できるのでお客さん毎の待ち時間はグッと短くなります。
スレッドプールの戦略は以下の通りです。
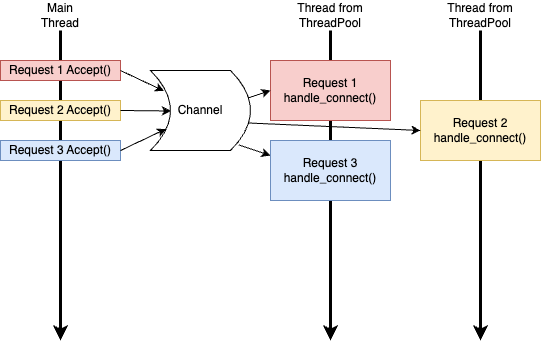
- スレッドを作るのに一定のコストがかかるため、最初からスレッドを一定数用意しておきます(この最初から用意されているスレッドの集まりがスレッドプールと呼ばれる)。
- リクエストの待受は前回同様mainスレッドで行います。
- リクエストを受け付けたら、それ以降の処理についてはスレッドプールの中の空いている(処理中でない)スレッドに担当させます。
- これにより、他のスレッドで先に到着したレスポンスを処理させつつ、mainスレッドは次のリクエストを受け取れるようになります。
use std::{
io::{prelude::*, BufReader, BufWriter},
net::{TcpListener, TcpStream},
sync::{
mpsc::{channel, Receiver, Sender},
Arc, Mutex,
},
thread,
time::Duration,
};
// 実行可能なクロージャを持つ型。
type Job = Box<dyn FnOnce() + Send + 'static>;
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Sender<Job>,
}
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
// 今回はチャネルを利用してスレッド間でジョブを送る
let (sender, receiver) = channel();
let mut workers = Vec::with_capacity(size);
let receiver = Arc::new(Mutex::new(receiver));
//スレッドプールの初期化
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
// ここでスレッドはブロックされ、チャネルからジョブが流れてくるのを待つ
let lock = receiver.lock().unwrap().recv();
match lock {
Ok(job) => {
println!("Worker {}: executing job...", id);
job();
}
Err(_) => {
println!("Worker {}: channel has disconnected, quitting", id);
break;
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}
fn main() {
let listener = TcpListener::bind("127.0.0.1:10000").unwrap();
let pool = ThreadPool::new(10);
println!("Server listening on 127.0.0.1:10000");
while let Ok((stream, _)) = listener.accept() {
pool.execute(move || {
handle_connection(stream);
});
}
}
fn handle_connection(stream: TcpStream) {
let mut request_line = String::new();
let mut reader = BufReader::new(&stream);
reader.read_line(&mut request_line).unwrap();
let stream1 = stream.try_clone().unwrap();
let mut writer = BufWriter::new(&stream1);
// some heavy process
thread::sleep(Duration::from_secs(5));
let body = "Hello";
let response = format!(
"HTTP/1.1 200 OK\r\nContent-Length: {}\r\nContent-Type: text/plain\r\n\r\n{}",
body.len(),
body
);
writer.write_all(response.as_bytes()).unwrap();
writer.flush().unwrap();
}
コードの説明
-
ThreadPool::new()
-
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}指定されたサイズ分、Worker::new() を呼び出し、各ワーカーに一意のIDを与えつつ、共有されたreceiver(ジョブのやり取りをするチャネルの出口)を渡します。
-
-
main()
-
ThreadPool::new(10)
スレッドプールを作成します。ここでは10個のワーカースレッドが作成され、同時に10件までのリクエスト処理が可能になります。
-
pool.execute(move || { handle_connection(stream); });
受け取った接続ごとに、スレッドプール内の空いているワーカーにジョブを送信します。ここで、moveクロージャによりstreamの所有権がクロージャ内に移され、handle_connection関数が呼び出されます。これにより、メインスレッドは新しい接続の受付にすぐ戻ることができるため、リクエスト受付と処理が並行して行われます。
-
実行させると以下のように出力され、違うスレッドで並列に処理が行われていることがわかります。
Server listening on 127.0.0.1:7878
Worker 0: executing job...
Worker 1: executing job...
Worker 2: executing job...
Worker 3: executing job...
Worker 4: executing job...
Worker 0: executing job...
Worker 2: executing job...
Worker 4: executing job...
Worker 1: executing job...
Worker 0: executing job...
Worker 3: executing job...
結果も以下のようにほぼレスポンスタイムは5秒(Sleepしている時間と同じ)のため、並行に稼働していることが確認できます。
$ ab -n 30 -c 10 http://127.0.0.1:7878/
Percentage of the requests served within a certain time (ms)
50% 5005
66% 5006
75% 5006
80% 5006
90% 5007
95% 5007
98% 5008
99% 5008
100% 5008 (longest request)
やったね🎉
ただ、スレッドは万能の解決策ではなく、スレッドを増やすことは以下のようなコンテキストスイッチによるコストも要求されます。
- コンテキストスイッチとはOSがタスク(スレッド/プロセス)を切り替える仕組み。
- レジスタ退避/復元、キャッシュのミスマッチ、CPUパイプラインのフラッシュなどのコストがかかる
- スレッドが増えすぎると、コンテキストスイッチ頻度が上がり、パフォーマンスが低下に繋がりかねない。
これらの多数のスレッドを管理することでサーバ自体のハードウェア性能に余裕があるにも関わらず、パフォーマンスが大きく悪化するC10k問題が起こり、対応策が求められるようになりました[1]。なお、このC10k問題がボトルネックになっていたのはいたのは10年以上前のことであり、現在はマシンスペックが上昇したことからC10kがボトルネックになるようなことはほぼないと考えて良いようです[2]。
そのため、当時スレッドを利用する以外の解決策が模索されており、Node.jsによるイベント駆動アプリケーションが10k問題に対する1つの解決策を提示しました。
イベント駆動アプリケーションについて説明をする前に、イベント駆動アプリケーションがどのように効率化するかを理解するためにCPUがどのように命令を処理するのか、IOブロッキングによって待ち時間がどのように生まれているのかを解説します。
CPUを最大限利用する
Webアプリケーションでは、計算処理と外部との通信の両方が存在します。このうち、外部との通信はCPUの待ち時間が多く、この待ち時間を他の処理に回すことで1つのスレッドで複数のリクエストを並行に処理できるようにすればひとつのスレッドを有効活用できるようになります。
ここでは、CPUがどのように命令を処理するか、その速度特性と、I/O処理との大きな差異を踏まえた上で、ブロッキングとノンブロッキングの考え方、そしてイベント駆動型の設計手法について解説します。
1. CPUがどのように命令を処理するか
CPUは、内部で「命令フェッチ」「デコード」「実行」という一連の流れで、プログラム中の命令を1命令ずつ順次実行しています。たとえば、アセンブリレベルでは以下のような命令の流れになります。
- 命令フェッチ: メモリから命令を読み出す
- 命令デコード: 読み出した命令の意味を解釈する
- 命令実行: 加算、乗算、ジャンプなどの具体的な処理を実行する
この基本動作は非常に高速で、多くのCPU命令はナノ秒(10^-9秒)単位で完了します。しかし、ネットワーク通信やディスクアクセスなどのI/O操作は、ミリ秒(10^-3秒)単位、場合によってはそれ以上の待ち時間が発生します。つまり、I/O操作中はCPUが実際の計算を行わず、ただ待機状態に入るため、CPU資源が「無駄」に使われることになります。
このようなCPUを待たせるI/O処理がある場合、そのスレッドは続きの処理をすることができず、ネットワークからの応答を待ち続けます。今回はその待ち時間でどの程度処理が可能なのか、計測してみました。
use std::time::Instant;
fn main() {
let iterations = 1_000_000;
let mut sum: u64 = 0;
let start = Instant::now();
for i in 0..iterations {
sum = sum.wrapping_add(i);
}
let duration = start.elapsed();
let nanos = duration.as_nanos();
let avg_ns = nanos as f64 / iterations as f64;
println!("100万回の加算ループでかかった時間: {} ns", nanos);
println!("1回あたり約 {:.2} ns", avg_ns);
println!("計算結果 (最適化防止用): {}", sum);
// 例:ネットワークI/O待ち時間20µs(20,000 ns)の間に実行可能な回数
let iterations_possible = 20000.0 / avg_ns;
println!("20µsの待ち時間中に実行可能なループ回数の概算: {:.0}回", iterations_possible);
}
100万回の加算ループでかかった時間: 13503041 ns
1回あたり約 13.50 ns
計算結果 (最適化防止用): 499999500000
20µsの待ち時間中に実行可能なループ回数の概算: 1481回
この結果から、私のPC上では20µsのネットワーク待ち時間で1481回の加算ループ実行が可能であることがわかりました。こうしてみると圧倒的にI/O処理が遅く、CPU資源の無駄が発生していることがわかりますね。今回利用したPCよりも性能が良い(命令を早く実行できる)CPUの場合、同じ時間でより多くの計算が可能ですが、ネットワーク待ち時間はPCの性能には依存せずある程度一定です。そのため、ネットワーク待ち時間で行える処理の大きさは性能の良いサーバではより大きくなるものと想定できます。
この大きな時間差が、I/O待ち時間を有効活用する設計(ノンブロッキング、イベント駆動)が重要な理由となります。
2. ブロッキング vs. ノンブロッキング[3]
では、どのようにすればI/O待機中の時間を有効活用できるのでしょうか?その回答としては単純で、I/O待機中も利用できるデータがない場合にはすぐリターンを行い、ネットから受け取るデータの必要な作業を一時中断して他の作業を行います。これをブロッキングに対してノンブロッキングと呼びます。外部からデータを受け取ったらそこから処理を再開することで、待機時間もタスク処理を続行できます。
例えば電子レンジでお弁当を温めている間に、電子レンジの前で待ち続けるのがブロッキングです🍱。この待ち時間を利用して別の作業(皿を出す、飲み物の用意をする)などを進め、お弁当が温まるまで時間を有効活用することがノンブロッキングです🍵。
ブロッキング

-
定義:
ブロッキング処理とは、I/O操作(例:ネットワークからの応答待ち、ファイルの読み込み)が完了するまで、呼び出し元の処理が停止してしまう状態を指します。
-
問題点:
たとえば、1件のリクエストでネットワークからの応答待ち中、同じスレッドは何もできず待機状態になります。
ノンブロッキング

-
定義:
ノンブロッキング処理では、I/O操作を発行しても、その完了を待たずにすぐに次の処理に移ります。必要なデータが揃っていない場合は、処理を一時中断し、後で再開します。
-
メリット:
ノンブロッキングの設計では、1つのスレッドで多数のI/O待ちを効率的に管理でき、CPUがアイドル状態にならず、他の処理を並行して実行できるため、システム全体のリソースを有効活用できます。
-
具体的な動作
- データがない場合プログラムは「データがない」という状態を受け取り、すぐに制御を戻します。この間に他のタスクやイベントを処理できます。
- データがある場合I/O操作が完了したら、対応するイベントがイベントキューに追加されるなどし、コールバック関数が呼び出されて処理が進みます。
このノンブロッキングを実現しているNode.jsで利用されているのが、イベント駆動アプローチです。nginxやNettyなどでも利用されています。
イベント駆動(Event-driven)の考え方

図の解説:イベント駆動モデルの流れ
-
Event Queue(イベントキュー)「イベントキュー」は、発生したイベントを一時的に保管し、順番に処理する先入先出のキュー(行列)です。たとえば、ネットワークからデータが届いたり、新しい接続が発生したとき、これらの「イベント」がキューに追加されます。図では複数のイベントがキューに並び、イベントスレッドがループ処理で「Pop Event」し、1つずつ取り出し、処理(Handle Event)します。これにより、複数のイベントが同時に発生しても順番に処理される仕組みが実現されます。
-
データ
各イベントには「接続情報」「現在の状態」など、処理に必要な情報が含まれています。たとえば、クライアントのIPアドレスや現在の接続状況のステータスなどがデータとして渡されます。 -
Handle Event(イベントの処理)
イベントキューから取り出されたイベントは、イベントループの中でハンドラ関数(handle_readやhandle_writeなど)によって処理されます。この処理の流れは以下のように分かれます:-
データがある場合
ネットワークソケットやファイルからデータを受信できる場合、
readやwrite関数がそのデータを処理します。このとき、受信データに基づいて次のアクションが決まります(例:レスポンスの送信など)。 -
データがない場合(非ブロッキング動作)
ここが肝です。非ブロッキングモードでは、データがまだ届いていない場合でも処理が停止(ブロッキング)しません。代わりに、エラーではなく「今は処理できない」という状態(
WouldBlockエラー)が返されます。そして、イベントスレッドは次のイベントをキューから取り出し、処理を続けます。一方、ネットワークからのデータが利用できるようになったタイミングで、ネットワークからのデータの処理が必要なイベントは再び「イベントキュー」に登録され、順番がくれば処理を再開できるようになります。
-
コードでの実装例とイベント駆動の解釈
以下のRustコードでは、epollを活用してイベント駆動型サーバーを構築しています。このサーバーはクライアントとの通信を非同期に処理し、IO待ちの時間も別の処理を走らせることが可能です。
use nix::fcntl::{fcntl, FcntlArg, OFlag};
use nix::sys::epoll::{
epoll_create1, epoll_ctl, epoll_wait, EpollCreateFlags, EpollEvent, EpollFlags, EpollOp,
};
use std::collections::HashMap;
use std::io::{Read, Write};
use std::net::{TcpListener, TcpStream};
use std::os::unix::io::{AsRawFd, RawFd};
const BUFFER_SIZE: usize = 1024;
const ADDRESS: &str = "127.0.0.1:7878";
/// 指定したファイルディスクリプタを非ブロッキングモードに設定する
fn set_nonblocking(fd: RawFd) -> nix::Result<()> {
let flags = fcntl(fd, FcntlArg::F_GETFL)?;
let new_flags = OFlag::from_bits_truncate(flags) | OFlag::O_NONBLOCK;
fcntl(fd, FcntlArg::F_SETFL(new_flags))?;
Ok(())
}
/// 各接続の状態を表す
enum ConnectionState {
/// クライアントからのデータを待っている状態
Reading,
/// クライアントから受け取ったメッセージに基づいてレスポンス送信中の状態
Writing,
}
/// サーバー本体。listener と、接続ごとに TcpStream と状態を保持する HashMap を持つ
struct Server {
listener: TcpListener,
connections: HashMap<RawFd, (TcpStream, ConnectionState)>,
}
impl Server {
/// 指定アドレスでサーバーを生成。listener を非ブロッキングに設定する
fn new(addr: &str) -> std::io::Result<Self> {
let listener = TcpListener::bind(addr)?;
set_nonblocking(listener.as_raw_fd()).expect("failed to set nonblocking");
Ok(Server {
listener,
connections: HashMap::new(),
})
}
/// listener に対して accept を試み、接続があれば非ブロッキングに設定後、HashMap に登録し epoll に読み込みイベントを追加する
fn accept_connection(&mut self, epoll_fd: RawFd) {
loop {
match self.listener.accept() {
//accept()が完了(クライアントとの接続が完了)できた場合
Ok((stream, addr)) => {
println!("Connected to {}", addr);
let fd = stream.as_raw_fd();
set_nonblocking(fd).expect("failed to set nonblocking");
self.connections.insert(fd, (stream, ConnectionState::Reading));
//FlagをEPOLLIN(読み込み)にしてイベント作成
let mut event = EpollEvent::new(EpollFlags::EPOLLIN, fd as u64);
epoll_ctl(epoll_fd, EpollOp::EpollCtlAdd, fd, &mut event)
.expect("epoll_ctl add failed");
}
Err(ref e) if e.kind() == std::io::ErrorKind::WouldBlock => {
// 受付可能な接続はこれ以上ない
break;
}
Err(e) => {
eprintln!("Accept error: {}", e);
break;
}
}
}
}
/// 接続されたソケットから読み込みを行う。読み込み成功時は状態を Writing に変更し、epoll イベントを EPOLLOUT に切り替える
fn handle_read(&mut self, fd: RawFd, epoll_fd: RawFd) {
if let Some((stream, state)) = self.connections.get_mut(&fd) {
let mut buf = [0u8; BUFFER_SIZE];
match stream.read(&mut buf) {
Ok(0) => {
println!("Connection closed: fd {}", fd);
epoll_ctl(epoll_fd, EpollOp::EpollCtlDel, fd, None)
.expect("epoll_ctl del failed");
self.connections.remove(&fd);
}
Ok(_) => {
println!("Received message on fd {}", fd);
*state = ConnectionState::Writing;
let mut event = EpollEvent::new(EpollFlags::EPOLLOUT, fd as u64);
epoll_ctl(epoll_fd, EpollOp::EpollCtlMod, fd, &mut event)
.expect("epoll_ctl mod failed");
}
Err(ref e) if e.kind() == std::io::ErrorKind::WouldBlock => {
// 読み込み可能なデータがない
}
Err(e) => {
eprintln!("Read error on fd {}: {}", fd, e);
epoll_ctl(epoll_fd, EpollOp::EpollCtlDel, fd, None)
.expect("epoll_ctl del failed");
self.connections.remove(&fd);
}
}
}
}
/// ソケットへの書き込みを行う。メッセージをパースしてレスポンス文字列を生成し、送信後は状態を Reading に戻して EPOLLIN イベントに切り替える
fn handle_write(&mut self, fd: RawFd, epoll_fd: RawFd) {
if let Some((stream, state)) = self.connections.get_mut(&fd) {
if let ConnectionState::Writing = state {
let body = "Hello";
let response = format!(
"HTTP/1.1 200 OK\r\nContent-Length: {}\r\nContent-Type: text/plain\r\n\r\n{}",
body.len(),
body
);
println!("Sending response to fd {}: {}", fd, response.trim());
match stream.write(response.as_bytes()) {
Ok(_) => {
*state = ConnectionState::Reading;
let mut event = EpollEvent::new(EpollFlags::EPOLLIN, fd as u64);
epoll_ctl(epoll_fd, EpollOp::EpollCtlMod, fd, &mut event)
.expect("epoll_ctl mod failed");
}
Err(ref e) if e.kind() == std::io::ErrorKind::WouldBlock => {
// 書き込み可能になるまで待つ
}
Err(e) => {
eprintln!("Write error on fd {}: {}", fd, e);
epoll_ctl(epoll_fd, EpollOp::EpollCtlDel, fd, None)
.expect("epoll_ctl del failed");
self.connections.remove(&fd);
}
}
}
}
}
}
fn main() {
// サーバー作成
let mut server = Server::new(ADDRESS).expect("Failed to create server");
println!("Server listening on {}", ADDRESS);
// epoll インスタンスの作成
let epoll_fd = epoll_create1(EpollCreateFlags::empty()).expect("Failed to create epoll");
// 新しい接続を待機する用に EPOLLIN イベントを登録
let listen_fd = server.listener.as_raw_fd();
let mut event = EpollEvent::new(EpollFlags::EPOLLIN, listen_fd as u64);
epoll_ctl(epoll_fd, EpollOp::EpollCtlAdd, listen_fd, &mut event)
.expect("epoll_ctl add failed");
let mut events = vec![EpollEvent::empty(); 1024];
// メインのイベントループ
loop {
let nfds = epoll_wait(epoll_fd, &mut events, -1).expect("epoll_wait failed");
for i in 0..nfds {
let fd = events[i].data() as RawFd;
if fd == listen_fd {
// 新しい接続要求
server.accept_connection(epoll_fd);
} else {
// 既存接続のイベント
let event_flags = events[i].events();
if event_flags.contains(EpollFlags::EPOLLIN) {
server.handle_read(fd, epoll_fd);
}
if event_flags.contains(EpollFlags::EPOLLOUT) {
server.handle_write(fd, epoll_fd);
}
}
}
}
}
1. イベントキューの役割
コード内でepoll_waitがイベントキューとして機能します。以下の流れでイベントが処理されます:
-
イベント登録:
接続時にファイルディスクリプタ(FD)を
epoll_ctlを通じてEPOLLIN(読み取り可能イベント)に登録。ファイルディスクリプタとは接続先のストリームを表す整数値のことで、ここでは個々のクライアントと接続しているそれぞれのソケットを指します。[4] -
イベント待機:
epoll_waitがブロックし、登録済みのFDで新しいイベント(読み取りや書き込み可能状態など)が発生するまで待機。 -
イベント処理:
発生したイベントに基づき、
handle_readやhandle_write関数が実行されます。
2. コールバックの実行
イベント駆動モデルにおけるコールバックは、状態ごとに異なる動作を定義しています:
-
接続受け入れ (
accept_connection): 新しいクライアント接続を受け入れる際のコールバック。 -
データ読み込み (
handle_read): クライアントからのデータ読み取り時に実行。 -
データ書き込み (
handle_write): クライアントへのレスポンス送信時に実行。
3. 非ブロッキングの活用
すべてのファイルディスクリプタ(ソケット)はO_NONBLOCKフラグを使用して非ブロッキングモードに設定されています。この設定により、読み取り・書き込み時にデータがなくても待機せずすぐに制御が戻ります。
まとめ
この記事では、Webアプリケーションにおけるリクエスト処理を効率化する技術について、自分の理解を深めるために整理しました。単一スレッドでの課題から始まり、マルチスレッドやノンブロッキングI/O、イベント駆動モデルの利点と実装例を具体的に学び直すことで、システム設計の本質を改めて実感しました。
特に、Rustを使ったepollの実装を通して、イベントループやコールバックの仕組みを理論だけでなくコードで確認できたことで、実際の動作をイメージしやすくなりました。一方で、スレッドやイベント駆動にはコードが複雑になり読みにくくなってしまうという欠点があり、それを補完する技術としてAsyncやCoroutineといった非同期ライブラリがあります。今後はこのような非同期ライブラリの実装についても学んでいけたらな〜と思っています😎
参考文献
- Webサーバーアーキテクチャ進化論2023:より低レイヤのSocketの動作などまで解説されている非常にためになる記事です!今回の記事よりもかなり幅広く&深く解説されており、参考にさせていただきました。
- なっとく!並行処理プログラミング:Pythonで並行プログラミングについて優しく解説されています。英語になってしまいますがWeb版はコードがコピペ可能&コード中のコメントも読みやすいためおすすめです。
- 並行プログラミング入門―Rust、C、アセンブリによる実装からのアプローチ:こちらは並行プログラミングがCPUやアセンブリでどのように実装されているかまでに踏み込んでおり、コード例も多く非常に勉強になりました。Github上でコードも読めます。
Discussion