Vtuberのアニメーションシステム(AlterEcho)の論文に関するメモ

Vtuberに関して面白そうな論文があったので、メモとして共有させて頂ければ幸いです。これはAlterEcho: Loose Avatar-Streamer Coupling for Expressive VTubingという論文です。
図表は特に断りがない限り、論文中の図を用いています。また、参考文献のインデックスは論文中のインデックスを用いています。
INTRODUCTION
バーチャルユーチューバー(VTuber)とは、バーチャルアバターを体現し、特別にデザインされたペルソナをロールプレイするストリーマーである [33]。アニメやマンガのサブカルチャーが浸透している東アジアから始まったVTuberのコミュニティは、その後急速に拡大し、文化や言語の壁を越えて世界中の視聴者に届くようになった。VTuberのストリーミングパフォーマンスの主要因は、彼らのアニメーションアバターであり、彼らの個性や外見を魅力的だと思う視聴者を引き付けるために、彼らの人格を生き生きと描写することが必要である[33]。
しかし、VTuberの表情豊かなアバターをリアルタイムでアニメーション化することは困難である。
- 一般的なアプローチでは、ストリーマーはキーボードショートカットを使って特定のジェスチャーやアニメーションをトリガーにアバターを動かす。
- また、全身にモーションキャプチャースーツを装着し、リアルタイムに体の動きを追跡する方法もあります。しかし、この技術は高価で、着心地が悪く、広い物理的なスペースが必要だ。さらに、最も重要なことだが、このようなリアルタイム・モーションキャプチャーは、アバター・アニメーションに上限を課してしまい、せいぜいストリーマーの動きをミラーリングする程度で、それを超えることはできない。
本論文では、アバターとストリーマの結合を緩めることを中心とした新しい VTubing のアプローチを提案し、その最初の実装として AlterEchoVTubing アニメーションシステムを提案する。頭の位置・向き・顔のランドマークなどの基本的なモーションキャプチャデータ、PCのキーボードとマウスの入力イベントがキャプチャされる。映像、音声、モーションキャプチャデータ、入力イベント、希望するペルソナパラメータは,AlterEchosystemに入力され,アバターがアニメーションする(図1)。
アバターは、モーションキャプチャデータに基づいたジェスチャ(a)、音声認識、音響解析、表情認識、ペルソナパラメータに基づいた推測ジェスチャ(b、c)、ペルソナパラメータに基づいた即興のジェスチャ(d)を行う。
本研究では、VTuber、非VTuber、VTuber視聴者を対象としたオンライン調査により、AlterEchoを評価した。その結果、大多数の参加者がアルターエコーのアバターを最も魅力的で自然であり、好ましいアバターであると評価した。本研究の第2部では、シャイ/内向的から自信家/外向的な連続体にアバターを適応させるAlterEchoの能力を評価した。参加者は、シャイ/自信なしから外向的/自信ありの連続体の両端に相関する8つのペルソナ形容詞を与えられ、8つの形容詞のうち平均7.2つが正しく答えられた。
RELATED WORK
ごく最近の論文では、Lu ら [33] が VTuber の視聴者の知覚と態度が非 VTuber の視聴者のそれとどのように異なるかを明らかにし、Otmazgin [40] が日本の新興メディア産業としての VTuber がテクノロジーとファンダムを統合し、現実と仮想現実の境界をあいまいにしたことを論じ、Bredikhina [12] がアイデンティティ構築、VTuber の理由、性別表現についてVTuberに調査した結果を述べている。 しかし、VTubing に関する技術的な言説は不足している。
Current VTubing Solutions
- Full-body motion capture
モーションキャプチャシステム[6, 7]→高価・キーボードやマウス入力の際には問題が生じる
VRヘッドセット[47]→精度が低く、常にコントローラーを持っていなければならない - Head/Facial motion capture
FaceRig[18]などを用いた2D表現→キーボードショートカットでのアニメーションはゲームに集中している際などには使いづらい
Conventional Streaming vs. VTubing
ストリーマーの実際の姿とその複雑で暗黙の人格に興味を持つ のに対して[22] 、VTuberの視聴者は、しばしばアニメやコミックのサブ カルチャーからインスピレーションを得ている単純で「フラット」で明確な VTuber という人格のフィクション、すなわちステレオタイプな外観と人格特性に惹き付けられる。
また,VTuberコミュニティは,ストリーマーの行動や特徴よりもアバターの「要素」 [19] を重視するため,VTuberに創造的な表現の自由を与えている。したがって,これらのニュアンスは,当然,従来のストリーミングと VTubing との技術要件の相違を意味する. 完璧なモーションキャプチャを実現しても、VTuberの理想的な支援にはならない。このように、VTuberのペルソナをより効果的に実現するためには、ストリーマーの動作という現実を捉えるだけでなく、アバターがストリーマーの動作とは異なる動作をするという現実を超えることが必要である。
THE AlterEcho VTUBING ANIMATION SYSTEM
Design: Challenges, Requirements, and Approach
VTuberの観客は,アバターの動きや表情が自然であることを望んでいる [28]。しかし、驚くような出来事と、ストリーマーがホットキーを押してショックの表情や顔を覆うボディ・ジェスチャーなどのアバター反応を引き起こすことができる時間との間に、避けられない遅れがある。アバターの反応の遅れは不気味の谷現象[43]を促進する重要な要因であり、視聴者の興味を失わせる自然でないパフォーマンスにつながる可能性がある。また、ペルソナに応じた行動を行えることも長時間の配信などで一貫した行動を行うために重要である。
そのため、VTuberのアニメーションシステムは、以下の要件を満たすように設計される必要がある。
- 自動化:ストリーマーが明示的に介入しなくても、アバターアニメーションが生成されること。
- 低コスト:安価でコンパクトなコンポーネントで構成されること。
- 現実世界と仮想世界の差異に対応すること:現実世界によって制御される仮想世界に適したアニメーションを生成する。
- 適応的であること:アバターペルソナは、ストリーマーが好みに応じて設定できるようにパラメータ化されるべきである。
本論文では、ストリーマとアバターの結合を緩めるというアイデアに基づき、上記の要件を満たすように設計されたVTuberアバターアニメーションシステム、AlterEchoを提案する。- ストリーマの動作を安価な携帯電話でキャプチャし、キャプチャした動作を単純にアバターへリターゲットするのではなく、ストリーマの動作や発話、仮想環境(現実世界とは大きく異なる可能性がある)、指定したアバターのペルソナパラメータも考慮して、アニメーションを生成している。
Architecture

① Head and Face Mocap・Facial Expression Recognition
【Head and Face Mocap】
ARKit[3]で頭部位置・姿勢・顔のランドマークを取得
【Facial Expression Recognition】
ARkitの顔データから作成した独自のSVMモデル(ARkitのデータを入力とすると精度がいいらしい)で認識。
②Speech Recognition・Acoustic Analysis
言葉の情報と音量の大きさとピッチを取っている
④・⑦Gesture Triggering(Tethered Gestures・Inferred gestures・Impromptu gestures)
ジェスチャーのトリガーは行動や、入力されたペルソナのパラメータ値に依存する。ペルソナはエネルギーの大きさ
ジェスチャーはいかに述べる前提条件が満たされたときに起こる。また、条件が3つ存在し、それぞれが出すか出さないかを判定しているので、競合している場合には優先度順で決定する(後述)。
基本的にジェスチャーは予め登録されていて、それから選択されているっぽい。
【Tethered gestures】
モーションキャプチャとキーボードとマウス入力に応じた動きを担当する。
キーボード・マウスはそれぞれ1対1対応しており、操作に応じてアバタが動く。またVtuberがマウスやキーボードから離れると同じく離れる動作が発生する。

【Inferred gestures】
音声・表情・ペルソナのデータからジェスチャーを決定する部分を担当する。
- Iconic gestures
特定のキーワードが発言された際、ジェスチャーがトリガーされる。例えば、「well」/「ok」と言ったときにアバターが肩をすくめたり、「wait」と叫んだ後に数秒以上の間を置いたときにアバターが両手で頭を掴んでイライラしているように見せる。 - Beat gestures
ビートジェスチャーは、ある閾値より大きい音量の単語が発話されたときに確率P_{\beta} t_{\beta} P_{\beta} β_t K_e K_x - Emotion gestures
喜び、悲しみ、怒りなどの感情ジェスチャは、MLモデルによって分類・フィルタリングされたニュートラルな表情からの変化によりトリガされる。
各ジェスチャーには、

【Impromptu gestures】
また、ストリーマとは独立したジェスチャーを確率

⑨・ⓐ・ⓑ・ⓒAnimation integration(Timing・Conflict Resolution・Execution)
ジェスチャーのタイミングを計り、衝突を解決しながらジェスチャーを実行すべきかどうかを判断する必要がある。
【Timing】
ジェスチャーの開始時刻は、その前提条件が満たされたときに決定される。また、ビートジェスチャーと発話との同期をよくするために、オフセットを適用することもできる。非復帰型ジェスチャー(継続時間が決まっていない)の追跡を行い、指定された時間閾値(たとえば、ビートジェスチャーの場合は3秒)を超えて持続する場合は、外とする姿勢部分の初期化を行う。
【Arbitration】
クールダウン期間を決定する。また、ジェスチャーの候補に対し、Ththered、Emotion、Iconic、ビート、Impromptuの順に優先順位が高くなり、競合が解消される。
【Execution】
顔の表情は、モーションキャプチャのデータから補間し、
また、Inferred gestureが発生する確率
経験的に
RESULTS AND DISCUSSION
結果の部分はわりかし雑になってしまっています...
User Study
315人の参加者を対象に、AlterEchotoで制作したアニメーションと他の2つのアプローチで制作したアニメーションを比較し、AlterEchoのアバターペルソナ変更能力を評価するユーザースタディを実施した。
参加者のうち84人が女性、200人が男性。 VTuberが56 名、その他のストリーマーやビデオコンテンツクリエイターが49 名、コンテンツ制作に関わらない視聴者が210名だった。


Comparison to other approaches
Conditions
VTubing では,チャットとゲームが主な活動であるため[28]、経験豊富なVTuberと契約し、VTuberがコンピュータゲームをプレイするLet's Plays Sessionを行った。3つの条件のアニメーションを作成した。

- C1(モーキャプデータを直接反映)
- C2(VmagicMirror[8])
- C3(AlterEcho)
Experimental procedure
動画視聴し、その後「アバターが魅力的だった」(表3のEngaging)、「アバターが自然だった」(Natu-ral)、「このアバターをストリーミングやVTubingで使用してもよい」(Preferable)を1(強く反対)〜5(強く賛成)のリッカート尺度で回答。また、アバターが「最も魅力的」、「最も自然」、「好ましい」と思うアニメーションを選択。
Results and discussion
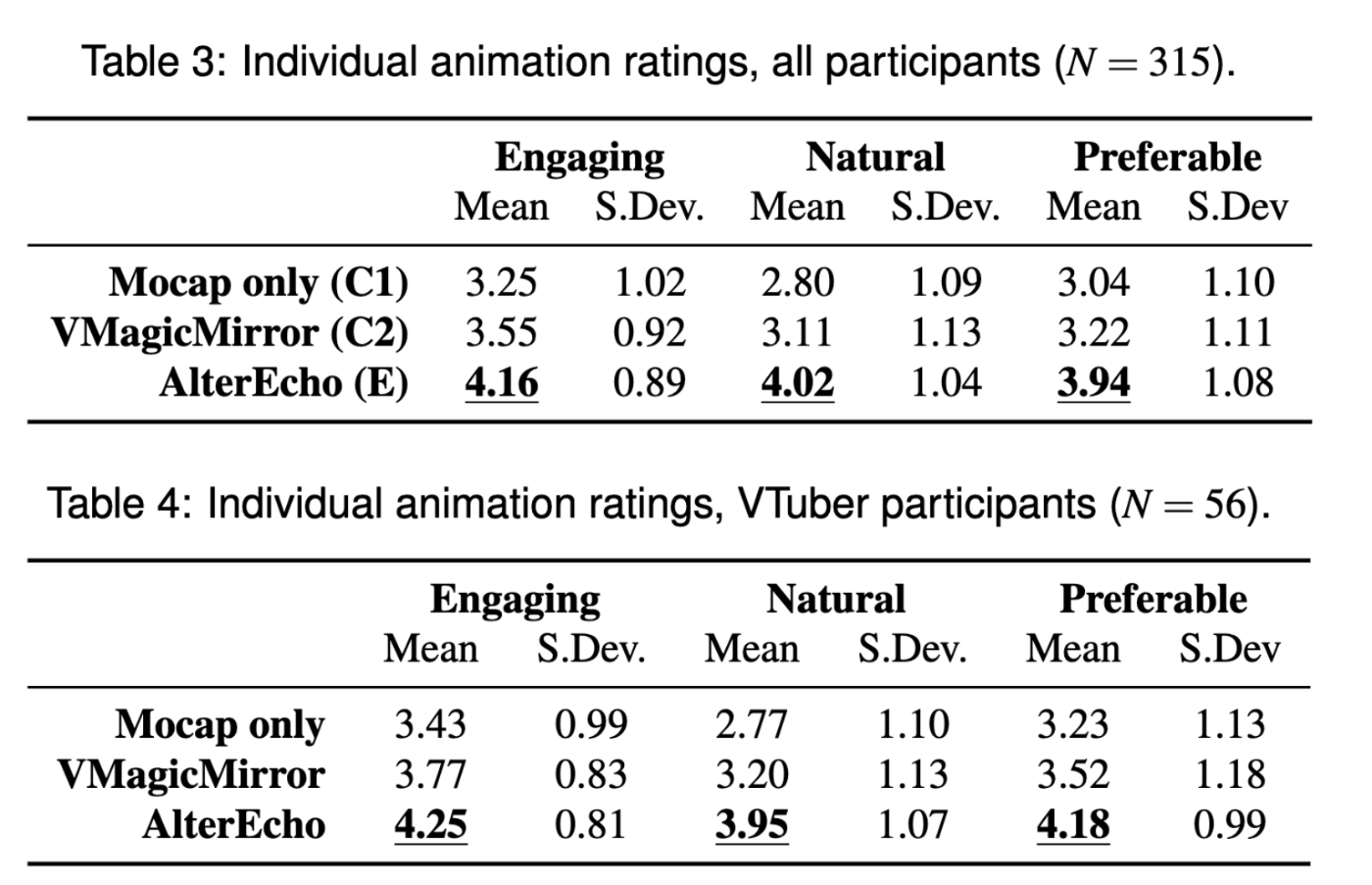
表3はアニメーションの個人評価、表4はVtuber経験者の参加者の評価。結果AlterEchoが最も高い結果を得られた。

ポストフック分析の結果も、それぞれの郡に有意差が見られた。

参加者の大多数は、AlterEchoのアニメーションが最も魅力的で、最も自然であり、好ましいアバターであると回答している。AlterEchoでは、ペルソナのパラメータを調整することで、ジェスチャーの頻度や種類を簡単に変えることができますが、非定型VTuber向けのアバタージェスチャーの量や種類の「スイートスポット」については、今後の研究によって明らかにする必要がある。また、音声によるジェスチャー合成など、機械学習によるジェスチャー生成技術を導入する方法もある[1]。
Avatar Persona Modulation
第二部では、AlterEchoのペルソナパラメータ化の有効性を評価した。
条件
第一部の調査で使用したソースマテリアルから40秒間のセグメントを抽出し、
実験方法
「内気」、「内向的」、「控えめ」、「自信なさげ」、「外向的」、「前向き」、「好感が持てる」、「威圧的」、「フレンドリー」、「傲慢」などを選択した。
Results and discussion

4つの「内気な/内向的な」形容詞と4つの「積極的な/控えめな」形容詞の正答率を示している。 8つの形容詞のうち7つは90%以上の確率で正しく正解し、8つすべての形容詞を正しく正解した参加者は59%に上った。
Discussion