マテリアルズ・インフォマティクス (MI) のサーベイ素材
MIという言葉の定義
Materials informatics is a field of study that applies the principles of informatics and data science to materials science and engineering to improve the understanding, use, selection, development, and discovery of materials. The term "materials informatics" is frequently used interchangeably with "data science", "machine learning", and "artificial intelligence" by the community. This is an emerging field, with a goal to achieve high-speed and robust acquisition, management, analysis, and dissemination of diverse materials data with the goal of greatly reducing the time and risk required to develop, produce, and deploy new materials, which generally takes longer than 20 years.
DeepL翻訳
マテリアルズ・インフォマティクスは、情報科学とデータサイエンスの原理を材料科学と工学に応用し、材料の理解、利用、選択、開発、発見の向上を目指す研究分野です。マテリアルズ・インフォマティクスという用語は、この分野では「データサイエンス」、「機械学習」、「人工知能」と互換的に使用されることがよくあります。これは、一般的に20年以上もの長い年月を要する新素材の開発、生産、展開に必要な時間とリスクを大幅に削減することを目標に、多様な素材データの高速かつ堅牢な取得、管理、分析、普及を実現することを目指す新興分野です。
マテリアルズ・インフォマティクスは、材料科学と情報科学の融合分野とも呼ばれ、両分野の技術発展によりその応用が加速している。スーパーコンピュータの高性能化と材料科学データベースの大規模化に牽引され、膨大なデータを高速に扱える環境が整い、材料情報学の活用を後押ししている。
ビジネスシーン
調査機関による大規模レポート
Precedence Research (2024)
- 2024〜2033年の市場予測
- 無償公開範囲が他レポートと比較すると多めで助かった
有償で読めてないもの
㈱シーエムシー・リサーチ (2024)
- 日本語のサーベイでは最も網羅されていそう?
RESEARCH AND MARKETS (2024)
レビュー論文・スライド
| お気に入り | タイトル | 所属機関 | Year | 国内動向 | 海外動向 | 技術動向 | 備考 |
|---|---|---|---|---|---|---|---|
| マテリアルズインフォマティクスの国際的な活用動向|海外での実用化例を紹介 | - (Hakky Handbook) | 2024 | ✕ | ◯ | ✕ | ||
| ◎ | マテリアルズ・インフォマティクスの発展と今後の展望 | JST研究開発戦略センター (CRDS) | 2022 | △ | △ | ◯ | 自動化・自律化の事例が豊富。それ以外も充実している |
| 鉄鋼分野における深層学習技術の活用の現状 (鉄鋼材料・製造プロセスにおけるデータサイエンス活用の新展開) | 日本製鉄(株)技術開発本部 | 2022 | ◯ | ✕ | ◯ | タイトルのとおり鉄鋼分野×Deep LearningがメインのためMIからは少し離れる | |
| ◯ | マテリアルズ・インフォマティクスの最新動向と今後の展望 | みずほリサーチ&テクノロジーズ 情報通信研究部 / 環境エネルギー第一部 | 2021 | ◯ | ◯ | ✕ | 「3. 安全性の側面からのMI活用動向」があまり他にはない視点 |
| ◯ | マテリアルズ・インフォマティクスによる材料開発 | 三井住友銀行 コーポレート・アドバイザリー本部 企業調査部 | 2019 | ◯ | ◯ | ✕ | P18以降の取り組み方向性の整理が参考になる |
| ◯ | 海外R&D政策動向「希少資源戦略」と「データ駆動型材料開発」 | JST研究開発戦略センター (CRDS) | 2018 | ✕ | ◯ | ✕ | P2の「各国の動向まとめ」のサマリー表だけですでに有益 |
News
R&Dシーン
レビュー論文・記事
General
- 2023年にScientific Reportsで発表されたダウンロード数の多いMIの研究論文top100
- ”Machine Learning”キーワードを含むうち、最も人気だったのはシステム計算科学センター (CCSE) 所属の方らが執筆したこれ
Badini et al. (2023)
ABstract(DeepL翻訳)
材料設計における人工知能(AI)アルゴリズムの統合は、材料特性を予測し、特徴を強化した新材料を設計し、直感を超えた新たなメカニズムを発見する力により、材料工学の分野に革命をもたらしている。さらに、複雑な設計原理を推測し、試行錯誤的な実験よりも迅速に高品質な候補材料を特定するために使用することができる。このような観点から、ここでは、最適化された特性を持つ新規材料の探索サイクルの各段階を、これらのツールによってどのように加速し、充実させることができるかを説明する。まず、機械学習(ML)、ディープラーニング、材料インフォマティクスツールなど、材料設計における最先端のAIモデルについて概説する。これらの方法論は、膨大な量のデータから意味のある情報を抽出することを可能にし、研究者が材料特性、構造、組成内の複雑な相関関係やパターンを発見することを可能にする。次に、AIを活用した材料設計の包括的な概要を説明し、その潜在的な将来性を強調する。このようなAIアルゴリズムを活用することで、研究者は幅広い材料特性を含むデータベースを効率的に検索・分析し、特定の用途に有望な候補を特定することができる。この能力は、医薬品開発からエネルギー貯蔵に至るまで、材料性能が極めて重要な様々な産業において大きな意味を持つ。結局のところ、AIベースのアプローチは、材料の理解と設計に革命をもたらし、イノベーションと進歩が加速する新時代の到来を告げるものである。
畑中 (2019) → 「データを蓄積する仕組み」のパートが有益
"化学におけるマテリアルズインフォマティクスの現状と課題"
Damewood et al. (2023)
Abstract(DeepL翻訳)
ハイスループットなデータ生成手法と機械学習(ML)アルゴリズムは、組成、構造、特性の関係を学習し、その関係を設計に利用することによって、計算材料科学の新時代をもたらした。しかし、このような関係を構築するためには、材料データを機械学習モデルで処理可能な、表現と呼ばれる数値形式に変換する必要がある。材料科学におけるデータセットの形式(画像からスペクトルまで)、サイズ、忠実度は様々である。また、予測モデルの対象範囲や性質も様々である。ここでは、機械学習モデルの入力または出力として材料を使用することを可能にする表現を構築するためのコンテキスト依存の戦略についてレビューする。さらに、最新のML技術がどのようにデータから表現を学習し、タスク間で化学的・物理的情報を伝達できるかについても議論する。最後に、まだ十分に解決されておらず、さらなる研究が必要である、インパクトの大きい疑問について概説する。
Li et al. (2023)
Abstract(DeepL翻訳)
データ集約的な科学研究手法の実装ツールとして、機械学習(ML)は、新素材の研究開発(R&D)サイクルを効果的に半分またはそれ以上に短縮することができる。MLは、特に理論計算や実験的特性評価から得られる大量の材料データの処理と分類において、他の科学研究技術との組み合わせで大きな可能性を示す。新素材の探索を加速するためには、材料インフォマティクスの研究思想を体系的に理解することが非常に重要である。ここでは、材料インフォマティクスにおいて最も一般的に用いられているMLモデリング手法を、古典的な事例を交えて包括的に紹介する。次に、ペロブスカイト、触媒、合金、二次元材料、高分子などの一般的な材料系における新しい加工-構造-物性-性能(PSPP)関係に焦点を当てた予測モデルの最新の進歩をレビューする。さらに、材料インフォマティクスの新たな研究の方向性として、インバースデザイン、ML原子間ポテンシャル、ミクロトポグラフィ特性評価支援など、材料研究技術の革新における最近の先駆的研究を要約する。最後に、材料情報学の分野における将来の革新と発展に関する最も重要な課題と展望を包括的に提供する。この総説は、材料インフォマティクスの応用に対する批判的で簡潔な評価と、材料科学者が必要な材料や技術に基づいてモデリング手法を選択するための体系的で首尾一貫した指針を提供するものである。
Methods, progresses, and opportunities of materials informatics
生成AI系
Fan et al. (2024)
Abstract(DeepL翻訳)
グラフは、ソーシャルネットワーク、知識グラフ、分子探索などの様々な領域において、複雑な関係を表現する上で重要な役割を果たしている。ディープラーニングの出現により、グラフニューラルネットワーク(GNN)はグラフ機械学習(グラフML)の基礎として登場し、グラフ構造の表現と処理を容易にしている。近年、LLMは言語タスクにおいてかつてない能力を発揮し、コンピュータビジョンやレコメンダーシステムなど様々なアプリケーションで広く採用されている。この目覚ましい成功は、LLMをグラフ領域に応用することにも関心を集めている。グラフMLの汎化性、転移性、少数ショット学習能力を向上させるために、LLMの可能性を探る取り組みが活発化している。一方、グラフ、特に知識グラフは、信頼できる事実知識に富んでおり、LLMの推論能力を向上させ、幻覚や説明可能性の欠如といったLLMの限界を緩和する可能性がある。この研究の方向性が急速に進展していることを考えると、LLMの時代におけるグラフMLの最新の進歩をまとめた体系的なレビューは、研究者や実務者に深い理解を提供するために必要である。そこで、本サーベイでは、まずグラフMLの最近の動向を概観する。次に、LLMがグラフ特徴の質を高め、ラベル付きデータへの依存を軽減し、グラフの不均一性や分布外(OOD)汎化などの課題に対処するためにどのように利用できるかを探る。その後、グラフがどのようにLLMを強化できるかを掘り下げ、LLMの事前学習と推論を強化する能力を強調する。さらに、様々な応用例を調査し、この有望な分野における将来の方向性について議論する。
Hatakeyama et al. (2023)
Abstract(DeepL翻訳)
本論文では、化学研究におけるGenerative Pre-trained Transformer 4 (GPT-4)の能力と限界を評価する。GPT-4は卓越した性能を示すが、入力データの質がその性能に大きく影響することは明らかである。我々は、基礎化学知識、ケムインフォマティクス、データ分析、問題予測、提案能力などの化学タスクにおけるGPT-4の可能性を探る。この言語モデルは、ブラックボックス最適化などの伝統的な手法を部分的に上回ったが、特化したアルゴリズムには及ばなかった。本論文では、GPT-4に与えられたプロンプトとその回答を共有し、コミュニティ内のプロンプトエンジニアリングのリソースを提供し、大規模言語モデルを使用した化学研究の将来についての議論で締めくくる。
Guo et al. (2023)
Abstract(DeepL翻訳)
自然言語処理タスクに強い大規模言語モデル(LLM)が出現し、科学、金融、ソフトウェア工学など様々な分野で応用されている。しかし、LLMが化学分野を発展させることができるかどうかは、まだ不明である。本論文では、最先端の性能を追求するのではなく、化学領域にわたる幅広いタスクにおけるLLMの能力を評価することを目的とする。我々は、LLMの理解、推論、説明を含む化学関連の3つの主要能力を特定し、8つの化学タスクを含むベンチマークを確立する。我々の分析は、実用的な化学の文脈におけるLLMの能力を幅広く調査することを容易にする、広く認知されたデータセットを利用している。5つのLLM(GPT-4、GPT-3.5、Davinci-003、Llama、Galactica)が、慎重に選択された実証例と特別に作成されたプロンプトを用いて、ゼロショットおよび少数ショットのインコンテキスト学習設定で、各化学課題に対して評価された。その結果、GPT-4は、8つの化学課題において、他のモデルやLLMを凌駕し、異なる競争レベルを示した。包括的なベンチマーク分析から得られた重要な知見に加え、我々の研究は、現在のLLMの限界と、様々な化学タスクにおけるLLMの性能に対する文脈内学習設定の影響についての洞察を提供する。本研究で使用したコードとデータセットは、このhttpsのURLで入手可能である。
Miret et al. (2024)
Abstract(DeepL翻訳)
大規模言語モデル(LLM)は、材料科学の研究を加速させる強力な言語処理ツールのエキサイティングな可能性を生み出す。LLMは材料の理解と発見を加速する大きな可能性を秘めているが、実用的な材料科学ツールとしては現状では不十分である。本ポジションペーパーでは、材料科学におけるLLMの失敗事例を紹介し、複雑で相互に結びついた材料科学の知識を理解し推論するLLMの現在の限界を明らかにする。このような欠点を踏まえて、材料科学の知識と仮説生成、そして仮説検証に基づいた材料科学LLM(MatSci-LLM)を開発するためのフレームワークを概説する。MatSc-LLMを実現するためには、様々な情報抽出の課題が残る科学文献から、高品質なマルチモーダルデータセットを構築する必要がある。このように、我々は、価値ある材料科学の知識を捕捉する大規模なマルチモーダルデータセットを構築するために克服する必要がある、材料科学情報抽出の主要な課題について説明する。最後に、将来のMatSci-LLMを実際の材料探索に応用するためのロードマップを概説する:1.1.自動知識ベース生成、2.自動インシリコ材料設計、3.MatSci-LLM統合型自動運転材料研究所。
Janakarajan et al. (2023) ← 分子探索に特化
Abstract(DeepL翻訳)
言語モデル、特に変換器ベースのアーキテクチャーの成功は、他の領域にも波及し、低分子、タンパク質、高分子を操作する「科学的言語モデル」を生み出している。化学分野では、言語モデルが分子探索サイクルの加速に貢献していることは、早期創薬における有望な最近の知見からも明らかである。ここでは、分子探索における言語モデルの役割について概説し、de novoドラッグデザイン、物性予測、反応化学における言語モデルの強みを強調する。貴重なオープンソースソフトウェア資産に焦点を当て、科学的言語モデル分野への参入障壁を下げる。最後に、チャットボットインターフェースと計算化学ツールへのアクセスを組み合わせた、将来の分子設計のビジョンを描く。この寄稿は、化学的発見を加速するために言語モデルがどのように利用できるのか、また今後どのように利用されるのかを理解することに興味のある研究者、化学者、AI愛好家にとって貴重なリソースとなる。
Small data系
Xu et al. (2023)
Abstract(DeepL翻訳)
本総説では、材料機械学習が直面する小規模データのジレンマについて論じた。まず、少ないデータがもたらす限界について分析した。次に、材料機械学習のワークフローを紹介した。次に、論文からのデータ抽出、材料データベースの構築、高スループット計算、実験など、データソースレベルからの小規模データへの対処法、アルゴリズムレベルからの小規模データおよび不均衡学習のためのモデリングアルゴリズム、機械学習ストラテジーレベルからの能動学習と転移学習が紹介された。最後に、材料科学におけるスモールデータ機械学習の今後の方向性が提案された。
Automation系
個別研究
LLM系
Jablonka et al. (2023)
Abstract(DeepL翻訳)
GPT-4のような大規模言語モデル(LLM)は多くの科学者の関心を集めている。最近の研究では、これらのモデルが化学や材料科学に有用であることが示唆された。この可能性を探るため、我々はハッカソンを開催した。
この記事は、このハッカソンの一環として作られたプロジェクトの記録である。参加者は、分子や物質の特性の予測、ツールの新しいインターフェースの設計、非構造化データからの知識の抽出、新しい教育アプリケーションの開発など、様々な用途にLLMを使用した。
多様なトピックと、実用的なプロトタイプが2日足らずで作成されたという事実は、LLMが私たちの分野の未来に大きな影響を与えることを浮き彫りにしている。また、豊富なアイデアやプロジェクトは、LLMの応用が材料科学や化学にとどまらず、幅広い科学分野に恩恵をもたらす可能性があることを示している。
Chiang et al. (2024)
Abstract(DeepL翻訳)
大規模言語モデル(LLM)の幻覚を減らすことは、再現性が重要視される科学分野での使用に不可欠である。しかし、LLMは本質的に長期記憶を持たないため、領域固有の文献やデータを用いてLLMを微調整することは、自明ではなく、その場限りの、そして必然的に偏った作業となる。ここでは、LLaMPを紹介する。LLaMPは、Materials Project(MP)の計算データや実験データと動的に対話する、複数のデータ認識推論・行動(ReAct)エージェントのマルチモーダル検索拡張生成(RAG)フレームワークである。微調整なしで、LLaMPは、材料科学の概念の様々な様式を理解し、統合する能力を示し、関連するデータストアをオンザフライで取得し、高次データ(結晶構造や弾性テンソルなど)を処理し、固体合成のためのマルチステップ手順を要約する。LLaMPはGPT-3.5の本質的な知識のエラーを効果的に修正し、頻繁に文書化されるバンドギャップに関する5.21%のMAPEと、GPT-3.5が混合データソースに由来すると思われる形成エネルギーに関する1103.54%の大幅なMAPEを削減することを示します。さらに、LLaMPは、ダイヤモンド立方晶シリコン構造における幻覚的な体積ひずみを66.3%から0へと大幅に減少させた。提案するフレームワークは、材料インフォマティクスを探求するための直感的でほぼ幻覚のないアプローチを提供し、知識の蒸留と他の言語モデルの微調整のための経路を確立する。我々は、このフレームワークを科学的仮説のための貴重なコンポーネントとして、また、複数のLLMエージェントが、ハードコードされた人間の論理や介入なしに、材料合成や化学反応を駆動するために、ロボット工学と通信・協力する将来の自律型研究所の基盤として構想している。
Mirza et al. (2024)
Abstract(DeepL翻訳)
大規模言語モデル(LLM)は、人間の言語を処理し、明示的に訓練されていないタスクを実行する能力があるため、広く関心を集めている。これは、テキスト形式が多く、データセットが小さく多様であるという問題に直面している化学科学に関連している。LLMはこのような問題に対処する上で有望であり、化学特性の予測、反応の最適化、さらには自律的な実験の設計と実施に活用されつつある。しかし、LLMの化学的推論能力に関する系統的な理解はまだ限られており、モデルを改善し、潜在的な弊害を軽減するために必要である。ここでは、最先端のLLMの化学知識と推論能力を、人間の化学者の専門知識に対して厳密に評価するために設計された自動化フレームワークである「ChemBench」を紹介する。我々は、化学科学の幅広いサブフィールドについて7,000以上の質問と回答のペアを作成し、主要なオープンソースとクローズドソースのLLMを評価した。しかしモデルは、人間の専門家にとっては簡単な化学的推論タスクで苦戦し、化学物質の安全性プロファイルのような、過信的で誤解を招く予測を行った。これらの知見は、LLMが化学的タスクにおいて卓越した能力を発揮するものの、化学科学におけるLLMの安全性と有用性を高めるためには、さらなる研究が不可欠であるという二重の現実を浮き彫りにしている。また、我々の発見は、化学カリキュラムへの適応の必要性を示し、安全で有用なLLMを改善するための評価フレームワークを開発し続けることの重要性を強調している。
Yang et al. (2024)
Abstract(DeepL翻訳)
LLMは科学のためのAI(Ai4Sci)の領域で目覚ましい能力を発揮しており、化学はAIツールの進歩から大きな恩恵を受けている。自然言語のような連続したデータを学習する強力な能力を持つLLMは、計り知れない可能性を秘めている。注目すべきは、SMILESのような化学の一般的な表現もシーケンスの形をしていることである。そこで我々は、LLMを活用して化学シーケンスと自然言語シーケンスの両方を包括的にモデル化し、多様な化学タスクに取り組むことを提案する。この目的を達成するために、我々は化学工学用に調整された15Bのパラメータを持つ基礎的な大規模モデルであるBatGPT-Chemを導入する。 まず、化学の多様なタスクを自然言語とSMILESの組み合わせでモデル化することで統一する。次に、この統一されたモデリングアプローチを活用し、プロンプトテンプレートを作成し、大量の化学データを用いてインストラクションチューニングデータを生成する。その後、BatGPT-15Bを1億インスタンス以上のインストラクションチューニングデータで学習させ、〚分子の説明〛、〛分子設計〛、〛再合成予測〛、〛製品推論〛、〛収量予測〛などのタスクに対応できるようにしました。トライアルプラットフォームは"˶url{https://www.batgpt.net/dapp/chem}"で公開しています。
Qu et al. (2024)
Abstract(DeepL翻訳)
機械学習の新たな進歩により、材料探索と発見へのデータ駆動型アプローチが勢いを増している。しかし、膨大な材料探索空間をナビゲートするための結晶の簡略化された表現は依然として限られている。この限界に対処するために、我々は、組成的および構造的特徴の表現として、言語モデルからの自然言語埋め込みを利用する材料探索フレームワークを紹介する。これらの言語表現にエンコードされた文脈的知識は、材料特性と構造に関する情報を伝達し、クエリ材料に基づいて関連する候補を呼び出す類似性解析と、関連する特性を横断して情報を共有するマルチタスク学習の両方を可能にする。このフレームワークを熱電変換に適用することで、プロトタイプ結晶構造の多様な推奨を実証し、未研究の材料空間を特定する。第一原理計算と実験による検証により、推奨された材料が高性能熱電材料として有望であることが確認された。言語ベースのフレームワークは、多様な材料系に適用可能な、効果的な材料探索と発見のための汎用的で適応性のある埋め込み構造を提供する。
Xie et al. (2024)
Abstract(DeepL翻訳)
本研究では、新しいAI力場、すなわちグラフベースの事前訓練された変換力場(GPTFF)を導入し、優れた精度と汎用性で任意の無機系をシミュレートすることができる。大量のデータと変換アルゴリズムの注意メカニズムを利用することで、このモデルはエネルギー、原子力、応力をそれぞれ32meV/atom、71meV/Å、0.365GPaの平均絶対誤差(MAE)値で正確に予測することができる。モデルの学習に使用したデータセットには、3,780万個の一点エネルギー、117億個の力ペア、および3億4,020万個の応力が含まれています。また、GPTFFは、結晶構造の最適化、相転移シミュレーション、物質輸送など、さまざまな物理系のシミュレーションに汎用的に使用できることも実証した。
Yoshiaki et al. (2024)
Abstract(DeepL翻訳)
近年、極めて多様な分子の表現学習に基づく記述子生成、特に分子構造の文字表現であるSMILESに自然言語処理(NLP)モデルを適用したものが急速に発展している。しかし、これらのモデルが化学構造をどのように理解しているかについては、ほとんど研究されていない。このブラックボックスを解決するために、代表的なNLPモデルであるTransformerを用いて、SMILESの学習進捗と化学構造の関係を調べた。その結果、Transformerは分子の部分構造を素早く学習する一方で、全体構造を理解するためには長時間の学習が必要であることがわかった。一貫して、異なる学習ステップのモデルから生成された記述子を用いた分子物性予測の精度は、学習の最初から最後まで同様であった。さらに、Transformerはキラリティーを学習するために特に長時間の学習を必要とすること、エナンチオマーの誤解により低いパフォーマンスで停滞することがあることがわかった。これらの知見は、化学におけるNLPモデルの理解を深めることが期待される。
Kristiadi et al. (2024)
Abstract(DeepL翻訳)
自動化は現代の物質探索の基礎の一つである。ベイズ最適化(BO)は、そのようなワークフローに不可欠な要素であり、科学者が事前のドメイン知識を活用して、大規模な分子空間を効率的に探索することを可能にする。このような事前知識には様々な形があるが、ラージ・ランゲージ・モデル(LLM)に包含される補助的な科学的知識については、大きな反響を呼んでいる。しかし、これまでの研究では、LLMは発見的な材料検索にしか使われていない。実際、最近の研究では、点推定された非ベイズLLMから、BOの不可欠な部分である不確かさ推定値を得ている。この研究では、分子空間における原理的ベイズ最適化を加速するために、LLMが実際に有用かどうかという問題を研究する。我々はこの疑問に答えるために、冷静沈着なスタンスを取る。これは、(i)LLMを標準的であるが原理的なBOサロゲートモデルの固定特徴抽出器とみなし、(ii)LLMサロゲートの事後値を得るために、パラメータ効率の良い微調整手法とベイズニューラルネットワークを活用することによって、注意深く行われる。実世界の化学問題を用いた広範な実験により、LLMが分子に対するBOに有用であることが示されたが、それはLLMが事前に訓練されているか、ドメイン固有のデータで微調整されている場合に限られる。
Hatakeyama (2024)
ベイズ最適化
Chen et al. (2024)
Abstract(DeepL翻訳)
高性能触媒は、持続可能なエネルギー変換と人類の健康にとって極めて重要である。しかし、膨大かつ高次元の構造・組成空間をナビゲートする効率的なアプローチがないため、触媒の探索は難題に直面している。本研究では、密度汎関数理論(DFT)とベイズ最適化(BO)を統合したハイスループット計算触媒スクリーニングアプローチを提案する。BOの枠組みの中で、不確実性を考慮した原子論的機械学習モデルUPNetを提案し、高次元の触媒構造から直接自動表現学習を可能にし、原理的な不確実性の定量化を実現する。このBOフレームワークは、制約付き改善期待獲得関数を利用し、複数の評価基準を同時に考慮する。提案した手法を用いて、CO2還元反応の触媒探索を行った。その結果、本アプローチが高い予測精度を達成し、解釈可能な特徴抽出を容易にし、多基準による設計最適化を可能にすることで、高性能触媒探索における計算能力と時間の大幅な削減(必要なDFT計算の10倍削減)につながることが実証された。
Xi et al. (2023)
その他
Schneider et al. (2024)
Abstract(DeepL翻訳)
ポリマーアンサンブル表現のための簡潔なツールであるBigSMILES記法は、生成BigSMILESと呼ばれる強化バージョンを導入することにより、ここで強化される。G-BigSMILESは生成ワークフロー用に設計されており、使いやすさを追求したソフトウェアツールによって補完されている。この拡張版では、反応性比(または繰り返し単位間の接続確率)、分子量分布、アンサンブルサイズなどの追加データを統合しています。これらのデータを利用する生成グラフとして解釈可能なアルゴリズムが考案され、定義されたポリマーアンサンブルからの分子生成が可能になる。その結果、G-BigSMILES表記法は、複雑な分子アンサンブルを合理化された線表記法で効率的に指定することを可能にし、自動化された高分子材料設計のための基礎的なツールを提供する。さらに、G-BigSMILES表記法のグラフ解釈は、複雑な高分子アンサンブルをカプセル化できるロバストな機械学習手法の舞台を提供する。G-BigSMILESと高度な機械学習技術の組み合わせは、素直な物性決定とin silico高分子材料合成の自動化を促進する。この統合は、材料設計プロセスを大幅に加速し、ポリマー科学の分野を発展させる可能性を秘めている。
神たち
-
畠山先生@東工大
- Docswellの資料がすべて神
- Noteもかなり有益なものが多い
-
横山トモヤスさん@Panasonic
- X眺めているだけで勉強になる
-
kwh_rd100 さん
- 同様に、X眺めているだけで勉強になる
戦略的イノベーション創造プログラム (SIP)
内閣府 科学技術・イノベーション推進事務局 (2023)
マテリアル事業化イノベーション・育成エコシステムの構築 社会実装に向けた戦略及び研究開発計
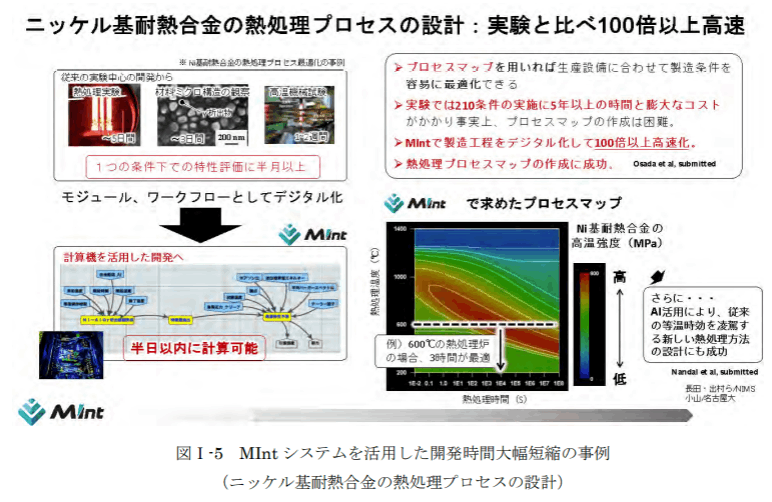

SIP での取組が主に構造材料を中心とした取り組みであったのに対し、先端素材高速開発技術研究 組合、産業技術総合研究所(以下、「AIST」)及び新エネルギー・産業技術総合開発機構(以下、「NEDO」) による超先端材料超高速開発基盤技術プロジェクト(以下、「超超プロジェクト」)は有機系材料を中 心とする機能性材料に特化した取り組みである。超超プロジェクトは、有機系機能性材料を対象にマ ルチスケールシミュレーション等の計算科学を活用して、現在不足している材料の「構造」と「機能」 を結びつけたデータ群を作り出し、マテリアルズインフォマティクスと融合することで革新的な機能 性材料の創成・開発の加速化を目指したプロジェクトであり、計算科学だけでなく、実際に材料を試 作するプロセス技術、これまで観測出来なかった計測技術も並行して開発した。
- マテリアルユニコーンを次々に生みたい
-
国内スタートアップによる新規資金調達は2021年には8,228億円に達した
→ But, アメリカはこの約50倍の3300億ドルの資金調達、大学発スタートアップは10年で6,000社を超える -
日本の国家としての投資額は少ない、ベンチャーキャピタルでも力不足

-
グローバルではマテリアル分野でユニコーン・デカコーンになる事例は多く存在。アカデミア発もたくさん
-
- フィージビリティスタディの結果
-
そもそもマテリアルユニコーンを目指すようなテーマは存在するのか? → Yes
- 以下、32件の応募からシナリオ立案することを決定して採択した10件

以上のフィージビリティスタディの結果が示唆することは、適切なガイドさえ行えば、我が国にはユニコーンとなり得るような有望なテーマは多くぞんざいし、さらにそれらは我が国のデータ基盤を活用することで、高い差別性・優位性を確保し、飛躍的な成長を遂げられる可能性があることを示唆するものである。
-
おもしろい!
ベイズ最適化は背景のモデルを仮定しないため非常に汎用的な手法ですが、全ての条件を探索しない限りは最良の条件を知り得ないという普遍的原理から逃れることはできず、材料開発者が探索実験を打ち切るタイミングをなんらかの判断基準で決定しなければならないという課題がありました。その最良のタイミングを統計的に評価する方法が日野教授らによる停止基準であり、材料開発者の恣意的な判断によらず、ほぼ自動的に打ち切りのタイミングを判定することができます。停止基準の導入によって生産性の向上、さらには材料開発の自動化も実現できる可能性があります。
MI特化のジャーナル → 2023年の刊行?とにかく新しいっぽい