FireLensでログ転送するときは依存関係とHealthcheckを設定しないとログを取りこぼすことがある
三行で
- FireLens を使うことで ECS で稼働するアプリケーションのログ転送を簡単に実装できる
- しかし、ドキュメントに記載されている設定例をそのまま利用しただけでは実はログの取りこぼしがあった
- ログの取りこぼしを防ぐためにコンテナ間の依存関係とHealthcheckの設定を行った
FireLens とは
FireLens を簡単に言うと、「ECS のタスク定義の記述だけで Fluent Bit / Fluentd を使ったログ転送用のサイドカーコンテナが利用できる機能」でしょうか。 FireLens という個別のサービスやソフトウェアが存在するわけでは無いようです。
詳細は以下を参照ください。
症状
私が関わったとあるサービスでは ECS を使ってアプリケーションを稼働させていて、アプリケーションのログは FireLens により Fluent Bit を使ってログ転送を行っていました。
ログ転送の構成
ログの転送先は Datadog になっていて、ログ監視によって想定している処理が想定している時間帯に ScheduledTask が稼働していることを監視していました。
すると、ときどきログ監視のアラートによって対象のログが検出できていないことが判明しました。しかしECS側のコンテナの稼働状況を見ると想定した時間に ScheduledTask が実行された形跡があり、それによるDB側の更新データも確認できました。そこで、Fluent Bit によるログの取りこぼし説が浮上しました。
原因(と思われるもの)
FireLens を利用したとき、以下の図のように 1つの Task にアプリケーションのコンテナとは別にログ転送用のコンテナが立ち上がるようになります。
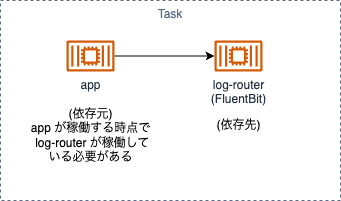
Task内で稼働するコンテナ間の依存関係
Dockerを開発環境で利用したことがある方はご存知かもしれないですが、復数のコンテナ間に依存関係があるときに compose.yml で依存関係を設定し、コンテナ間で起動の順番を制御することがあります。そうしないと、依存元コンテナが立ち上がった段階でその依存先コンテナが立ち上がっていないケースが確率的に発生し、コンテナの起動が不安定な状態となることがあるからです。
これと同じことが ECS 上で発生していると考えられました。
対策
コンテナ間の依存関係を設定する
ECS のタスク定義では dependsOn によってコンテナ間の依存関係を設定することができます。
タスク定義を抜粋すると以下のようになります。 以下で log-router コンテナは Fluent Bit が稼働しているコンテナを指します。
"containerDefinitions": [
{
"name": "app",
"dependsOn": [
{
"condition": "HEALTHY",
"containerName": "log-router"
}
],
... 略
},
{
"name": "log-router",
... 略
}
]
-
appコンテナがlog-routerコンテナに依存していることを宣言している - その際、
log-routerがHEALTHY状態になるまで待機することを示している
これで app コンテナ側の依存関係についての設定は完了しましたが、 今度は log-router コンテナの Healthcheck の設定が必要になります。
Fluent Bit コンテナに Healthcheck を設定する
Fluent Bit の設定
Fluent Bit 側の Healthcheck の設定は少々面倒で設定ファイルを別途用意する必要があります。今回は以下のような設定ファイルを用意して S3 に配置することにしました。 ( ファイル名は何でも良いと思いますが今回は諸々の事情から parse-json.conf という名前としました )
[SERVICE]
Parsers_File /fluent-bit/parsers/parsers.conf
Flush 1
Grace 30
+ HTTP_Server On
+ HTTP_Listen 0.0.0.0
+ HTTP_PORT 2020
HTTP_Server, HTTP_Listen, HTTP_Port が Healthcheck のために追加した設定項目です。
この設定については以下を参考にしました。
log-router コンテナの設定
タスク定義の log-router コンテナ側で以下のように healthCheck の設定を行います。
{
"name": "log-router",
"firelensConfiguration": {
"type": "fluentbit"
},
"environment": [
{
"name": "aws_fluent_bit_init_s3_1",
"value": "arn:aws:s3:::(fluentbitの設定ファイルを配置するS3バケット)/parse-json.conf"
}
],
"healthCheck": {
"command": [
"CMD-SHELL",
"curl -f http://127.0.0.1:2020/api/v1/uptime || exit 1"
],
"interval": 10,
"retries": 3,
"startPeriod": 30,
"timeout": 5
},
... 略
}
-
environmentでは FluentBit の設定が配置されている S3 バケットの位置を示している -
healthCheckでヘルスチェック方法について宣言している ( 設定内容は、公式リポジトリの Example を参考とした )
結果
この設定を追加した結果、いまのところログ監視からのアラートが収まっているように見えるため、この対応によって状況が改善したと思われます。
対応を行ってからまだ日数が経過していないため、この対応による効果なのか偶然なのかはまだ断定できない状況ではありますが... (またしばらくしたらここの状況をアップデートしたいと思います)
さいごに
ログ監視が時々荒ぶる原因はログの取りこぼしであった可能性が高いが、検証まではできていない状況です。しかし、アラートの回数は確実に減ったという状況証拠から、その可能性は高いと思われました。
今回のインフラ構築では FireLens を利用することで、ログ転送方式の実装について事前に考えておくべき点が減ったのですが、実は利用する側で考慮しておくべき点を見逃していたという例だったと思います。
初歩的といえば初歩的なミスでしたが(だからこそ?)、このような記事はあまりネットで見かけないので記事として公開しておきます。
Discussion