開発環境整備Tips
効率的に開発するための環境整備に関するTipsをまとめる。
Tipsを実践することで、人にとってもAIにとってもより良い開発体験となるはず。
言語サーバー
言語サーバーはコード補完機能や変数・関数定義(シンボル)の参照、利用箇所の検出などをやってくれる。これにより、シンボルにカーソルを当てると定義がポップアップで表示されたり、cmd+Tで定義にジャンプしたりといった便利機能を享受できる。
上記のような嬉しい仕組みは、かつてエディタやIDE毎に拡張機能のような形で独自に実装されていた。
しかし、各エディタごとに同じような仕組みを独自に実装するのは非効率。
そのような状況を改善すべくMicrosoftが2016年に提唱したのがLanguage Server Protocol(LSP)というプロトコル。
このプロトコルでは、コード補完やシンボル検索などの言語に関する機能を提供するサーバーとしての言語サーバーと、その機能を享受してエンドユーザーが使えるようにするクライアントとしてのエディタ・IDEの間の通信の仕様が定義される。
代表的なエディタであるVSCodeでも、LSPを介して言語サーバーとやり取りすることで我々は便利な機能を享受できている。
例
言語サーバーとして代表的なものに、PythonのPylanceがある。
PylanceはPyrightを取り込んでさらに拡張した言語サーバーで、VSCode上のPythonの言語サーバーとしては基本的にPylanceを選択することが推奨されている。
Python拡張機能をインストールするとPylanceも自動でインストールされるようになっているので、気付かないうちに利用している人もいると思う。
Pylanceをインストールすることで、例えば以下のような機能が使えるようになる:
型チェック機能のモードを設定することで、型情報に関する記述が抜けている場合に指摘してくれるしてくれる。

以下の例では、引数と関数の戻り値のアノテーションが定義されていない。
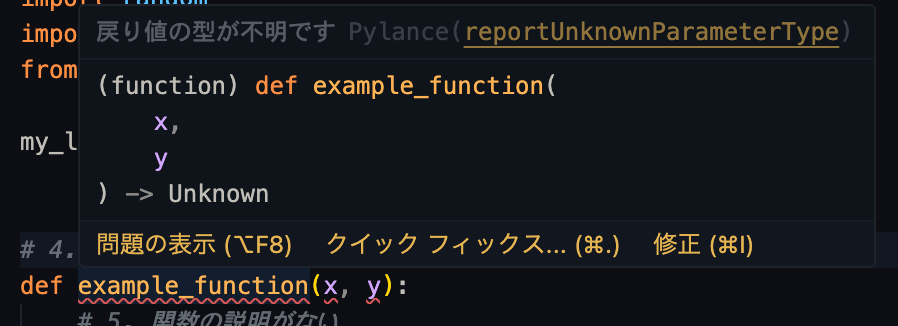
このように、それぞれアノテーションを定義してやることでエラーが解消する。

注意すべき点として、PylanceはVSCode専用のPython言語サーバーなので、他のエディタでは利用できない。例えば、CursorではPylanceが利用できないので、代わりにPyrightを選択することになる。
まとめ
このように、言語サーバーを導入することで開発時に様々な恩恵を受けられる。
Pylanceのようにクローズドで開発・運用される言語サーバーを除き、実装が公開されていればLSPに対応したエディタであれば等しく恩恵を受けられる。
linter & formatter
linterとformatterのどちらも、コードを美しく保つための支援ツール。
ざっくり区別すると、以下のイメージ:
linterは、構文エラーや良くない記法の指摘といった、コードの内容を整えることにフォーカスしたツール。
formatterは、コードのインデントを整えたり長すぎるコードを改行するといった、コードの内容は問わず見た目を整えることにフォーカスしたツール。
基本的にどの言語にもlinterやformatterは(それを作ってくれる開発者のお陰で)存在している。
使い方は大きく分けて二種類ある。
使い方 その1 拡張機能
開発者が一般にlinterやformatterの恩恵を受ける場合、エディタの拡張機能として用意されているものをインストールして利用することになると思う。
例えばPythonであれば有名なツールとしてRuffがあり、これはlinterとformatterの両方の機能を兼ね備えている。
これもVSCode拡張が存在する。
拡張機能をインストールすると、ツールの設定ファイルを作成し、どのような指摘・フォーマットをしてほしいかを定義する。
すると、以下のようにツールが指摘をしてくれる。

ここでは、D103の規約に基づいて、関数のDocstringが存在しないことを指摘してくれている。
linterによる指摘やformatterによるフォーマットは必ずしもこうしなくてはならないというものではなく、どのようなルールに基づいたコードを維持したいかによって設定する。
場合によってはやりすぎだと感じる設定もあるので、設定のon/offはプロジェクトごとに判断する。
このようにlinter/formatterを導入することで、そのコードベースで開発するメンバーによらず、同じコーディング規約・フォーマットに基づいたコーディングができるようになる。
使い方 その2 CLI
拡張機能を追加するまでもなく、ツールはパッケージに追加することで以下のような具合にCLI上で呼び出せる。
uvx ruff check # Lint all files in the current directory.
uvx ruff format # Format all files in the current directory.
開発者がGUI上でコーディングする際にはこのようなコマンドを叩くことは基本ないと思うが、CIを整備する際にこのようなコマンドを実行するワークフローを組むことになる。
そしてもう一つ、最近になって出現した使い方としてAIによる自動コーディング時の使用がある。
人が開発する際には拡張機能を入れるだけで指摘箇所に波線が引かれており、ひと目でどこが問題か特定できる。しかし、AIが読むコードにはそのような波線は含まれず、ツールの指摘を読み取ることができない。
そこで、AIのコーディングルールに「linter/formatterを必ず実行し、指摘事項を修正すること」を組み込むことで、AIによるコーディングにも人と同じルールを適用できる。
AIコーディングではいかにAIに品質の高いコードを生成させるかが重要な課題であるため、linter/formatterの導入は必須であると言える。
まとめ
linterはコードの内容を、formatterはコードの見た目を整えてくれるツール。
コーディング規約・フォーマットをプロジェクト内で統一でき、コードベースの可読性・保守性に寄与する。
エディタの拡張機能としてインストールすることで、開発時に指摘を読み取れるようになる。
リポジトリのパッケージに追加することでAIにもlinter/formatterを利用させることができる。
拡張機能
エディタごとに開発体験を向上させるための拡張機能が用意されている。
必要に応じて追加することで、より効率的に開発できる。
言語毎に便利な拡張機能がバラバラなので、プロジェクトで使用する言語の拡張機能を検索して追加するのがよい。
例として、VSCodeにおいて基本どの開発プロジェクトでも便利な拡張機能をいくつか挙げる。
Code Spell Checker
このような具合に、英字のtypoを指摘してくれる(typo自体はもう一つの語彙として認められており、指摘してくれなかった)

GitLens
コードの各行について、誰がいつ最後にコミットしたのかと、そのコミットの詳細をエディタ上で一発で確認できる。
他にもGitに関する便利な機能が盛り沢山なので、Gitを使う場合は基本的にインストールするのがよい
↓のサイトでわかりやすく紹介してくれているので割愛。
MCPツール
AIコーディング時には、MCPツールを使ってAIがアクセスできるコンテキストを拡張する。
以下に代表的なツールを紹介する。
Serena MCP
特定のLLMやフレームワークによらない、コーディングエージェントの能力を向上させるためのMCPツール。
You can think of Serena as providing IDE-like tools to your LLM/coding agent. With it, the agent no longer needs to read entire files, perform grep-like searches or string replacements to find and edit the right code. Instead, it can use code centered tools like find_symbol, find_referencing_symbols and insert_after_symbol.
(日本語訳)
Serenaは、LLM/コーディングエージェントにIDEのようなツールを提供するものと考えることができます。これにより、エージェントは適切なコードを見つけて編集するために、ファイル全体を読み込んだり、grepのような検索や文字列置換を行ったりする必要がなくなります。代わりに、find_symbol、find_referencing_symbols、insert_after_symbolといったコード中心のツールを利用できるようになります。
↑は公式リポジトリの説明だが、基本的にこれがすべて。
このツールを連携することで、冒頭に説明した言語サーバーによる恩恵をAIも得られるようになる。
linter/formatter節で述べたように、AIはエディタ見るための目がついていないのでCLI等の手段でコンテキストにアクセスさせる必要がある。
linter/formatterはCLI上でコマンドを叩いて実行できるが、言語サーバーの機能を利用するには言語クライアントを実装する必要がある。
Serena MCPでは、ツール内で言語サーバーと言語クライアントを実行し、言語クライアントで取得した結果をAIに返す仕組みを実装している。
これまでAIがファイル全体を読み込んだりgrepコマンドで面倒かつ曖昧な検索・置換を実施していたところを、Serena MCPを利用することでシンボルに関する情報にピンポイントでアクセスできるようになる。
これによって、AIがコードベースに関する調査をより高い精度で実施でき、かつ調査に必要なコンテキストを大幅に削減できるようになる。
↓の記事で詳しい説明をしてくれている。
コーディングエージェントを使う際にはとりあえず入れて損はないMCPツール。
context7

AIにライブラリ等に関する最新ドキュメントを参照した情報をインプットできるMCPツール。
AIが事前知識として持てるのはカットオフ日時までの情報である一方、ライブラリは日々更新される。AIは古くなった情報を元に提案・実装してしまう。
そのため最新の情報にアクセスさせる必要があるが、通常のWeb検索で得られる情報は玉石混交であり、正確な情報が得られない可能性がある。
context7を使って調査させることで必ず公式ドキュメントを参照するので、確実に最新かつ正確な情報に基づいた提案・実装ができるようになる。
こちらも、コーディングエージェントを使う際にはとりあえず入れておいて損はないMCPツール。
総括
いろんなツールを使いこなして、人にとってもAIにとってもよりよい開発体験を目指しましょう。
おしまい!
Discussion